

文:吴炳见
Deepseek开了个好头,改变了卷的方向,中国AI正在进入技术外卷。大模型玩家们开始开源、发论文、贡献代码,把核心方法分享出来,这是一次进化。论文如同砌墙,人多才能砖头多,量变会带来质变——即启发式创新,哪天卷出下一个Transformer我也不会惊讶。
中国这片土地,一向不卷则已,一卷惊人。过去二十年,卷已成惯性。
移动互联网的平台型机会,基本在卷三个因素,一是融资体量,弹药多才能火力猛。二是增长,快速抢占市场,突破网络效应的及格线。三是运营效率,一块钱能砸出两块钱还是两毛钱,决定了能否持久。过去的百团大战、打车大战、外卖大战、电商大战都是在卷这三要素,能胜出的都是卷王之王。
还有一条卷到极致的路是硬件,卷功能密度和成本效率,理想汽车首先用上冰箱彩电大沙发,之后全员模仿,成了中国新能源车的标配。小米su7 ultra把高端跑车价格锚定在52.9万,BYD用刀片电池和自研重构了成本曲线。高强度竞争下,中国手机卷出了小米、华为、vivo、oppo,中国汽车卷出了BYD、小米、蔚小理等一众选手。
这揭示着中国式竞争的底层逻辑——在有限成本内实现功能密度最大化。
能在中国式竞争胜出的卷王,去海外也能复用这套方法,这是Tiktok、Temu的故事,也是中国新能源车的故事。
中国式竞争卷了20年,AI浪潮下,是不是可以换种卷法试试?
梁文锋在访谈中说过一段话“以后硬核创新会越来越多。现在可能还不容易被理解,是因为整个社会群体需要被事实教育。当这个社会让硬核创新的人功成名就,群体性想法就会改变。我们只是还需要一堆事实和一个过程。”
没想到事实和过程来的这么快,Deepseek破圈后,社会确实被事实教育了,大家开始卷技术水平了——如何改良Attention,如何提升MoE,如何FP8和FP16混训。再进一步,是卷原创水平——谁能创新出下一代模型架构,谁能发现下一套训模型的方法。
之前两年,大模型公司同时在卷三个事:模型能力、融资体量和用户量。模型能力上,大家在卷谁能率先复现 GPT3.5、GPT4 和 o1,在同样复现的情况下,卷谁的跑分更高。
融资体量代表GPU的数量,也代表能搭建的团队质量。卷用户量是因为大多数创业者和投资人都有移动互联网的惯性思维,以为用户量可以带来数据飞轮,以用户量换竞争力,以用户量换融资。
DS的出圈打破了这种惯性,行业共识开始转向:别卷非核心要素了,大家一起卷模型能力,探索模型能力的天花板,和模型成本的地板。众人明白了,模型的三要素是算力、算法和数据,在算力有限,数据大部分是公开的情况下,可以从算法创新上探索出新东西,也明白了开源是个超级放大器,可以把影响力提升N倍。
于是大家看到,从今年 1 月份开始,开始卷开源和发paper了。MiniMax开源了两个模型Text-01和VL-01,DS和 kimi 在同一时间发布了 R1 和K1.5 的 tech report,写的都是如何复现o1推理模型。最近又在同一时间发布了注意力机制改进的 paper,DS的Native Sparse Attention,kimi的Mixture of Block Attention,MiniMax的Lighting Attention。这仅仅是技术外卷的序幕。
媒体上也更多在报道技术创新了,小宇宙上,晚点和张小珺连续几期带听众读论文,一期解读推理模型 R1 和 k1.5,一期解读注意力机制的改进,这是要把李沐老师的活儿给干了。要知道,读论文是极小众的专业活动,现在竟成了大众科普——“让我尽量用人话告诉你他们创新了什么”。
见微知著,这说明意识变了,大众开始关注底层创新,公司也更愿意分享自己压箱底的家伙了。也许一些公司还在权衡是否开源,但种子已经种下了,开源浪潮只是时间问题,至于什么时候加入开源,开源模型权重还是开源代码,哪些适合发 paper哪些不适合,只是个数字问题了,more or less。
市场开始聚焦技术创新,把各路好想法卷进来,集小成为大成,从方法层面孕育下一次突破,这就是Deepseek带来的改变。
这是种外卷,而非内卷。内卷的根源是同质化,蛋糕大小既定,大家在相同的事情上搞花活,你刚做好的功能创新,第二天对手就抄走。那没办法啊,只能拼运营效率,拼成本,把及格线越抬越高,如果对手过不了及格线,就被熬死了,赢家吃下市场。
外卷是什么?大家在基础创新上下功夫,输出方法论,整体拉高行业水位,共同把蛋糕做大,目的不是熬死谁,而是竞争下一个创新点。DS主动把“壁垒”公开,把 paper和代码放桌面上,大家随便用,先断了自己的后路,逼自己爬更高的山,做出更大的创新。
AI 行业还在萌芽阶段,在技术变动期,理应种下一颗外卷的种子。
卷并不好玩,在既定的游戏规则内,新公司很难刚过卷王。移动互联网最大的卷王之一是字节,在过去两年的AI上,他还是卷王。以 chatbot为例,豆包是全方位的卷,做好chatbot分为新老游戏。
新游戏是训模型,新老公司几乎同时出发,基模不够好,那就招揽优秀的研究员训模型。老游戏是移动互联网的方法,豆包月投放金额过亿,创业公司跟不跟都很为难。产品不够好,那就App、PC 客户端和网页三端一起迭代。快速迭代,大力出奇迹,老药方果然有效。
决定业务质量的还是一号位的认知,张一鸣几乎成了“AI事业部总经理”,我们在接触创业项目时,会听到一些研究员谈及张一鸣跟他聊过多长时间。这说明张一鸣是在一线了解技术,面试候选人的,是在不断预训练自己的。
一个公司的业务价值=行业价值 x 团队执行效率。今天,AI 应用创业者面临一个残酷的现实,字节会尝试进入诸多方向,淘汰所有执行效率不ok的团队,无论你有没有撞大运选到一个好行业。
过去两年,AI应用出了四个有些体量的pmf,字节都干了。
第一个是 chatbot,字节做了豆包。DS破圈前,用户量是国内第一了。
第二个是 Role paly,也就是各路Character.ai 的变形体,字节做了猫箱,猫箱里集合了各种经过验证的role paly的玩法,用feed流给你推荐玩法。
第三个是文生图和文生视频,也就是各路 Midjourney和Sora的变形体,豆包里自带文生图功能,视频模型有即梦。
第四个是 AI coding,也就是各路 Cursor 的变形体,字节有 Mars code和 Trae。
当下模型能力有限,解锁的pmf就这么几个,也不用挑啊,什么共识非共识的,都做了就是了,这造成了赛道拥挤。创业公司如果选的是充分验证的明牌方向,如果方向不够纵深,很容易遇到字节。
这种辛苦的竞争,说明过去两年大多数的pmf是AI enabled App,本质还是个 App,很多因素还是在字节的能力延长线上,还是容易陷入拼投放、拼效率、拼资金的境地。
听说,DS的出圈让字节内部也深有触动,DS 1 月15 日刚发 App,0 投放, 圈了1亿多用户,在全球破了圈。重投放、重运营效率、重融资在他身上都没有,跳出三界之外,根本不在既定的射程之内。
这是因为DS一开始就瞄准 AGI 的基础研究,公司全名叫“杭州深度求索人工智能基础技术研究有限公司”,是个 AI Lab,而非做产品的商业公司,出发点不同,自然不在延长线上。
去年的时候,我问 deepseek的人,你们模型为什么做的好?
那位同志说,因为我们老板在自己读论文,写代码,搞招聘。
这句话还是挺有力量的,确实,时间花在哪里,哪里就容易出效果,听着很简单,但真相就是这么简单。
卷开源、卷论文只是开始,未来会卷什么?
我们先看 DS 过去做了什么,过去两年,OpenAI负责探路,follow OpenAI的前沿模型,DS 用科学研究的方法复现,从 GPT3.5到o1,通过算法和训练方法的一系列创新,大幅降低训练和推理成本。这种前人探路的红利还能继续吃一段时间,而这也是打基础、补差距的过程。
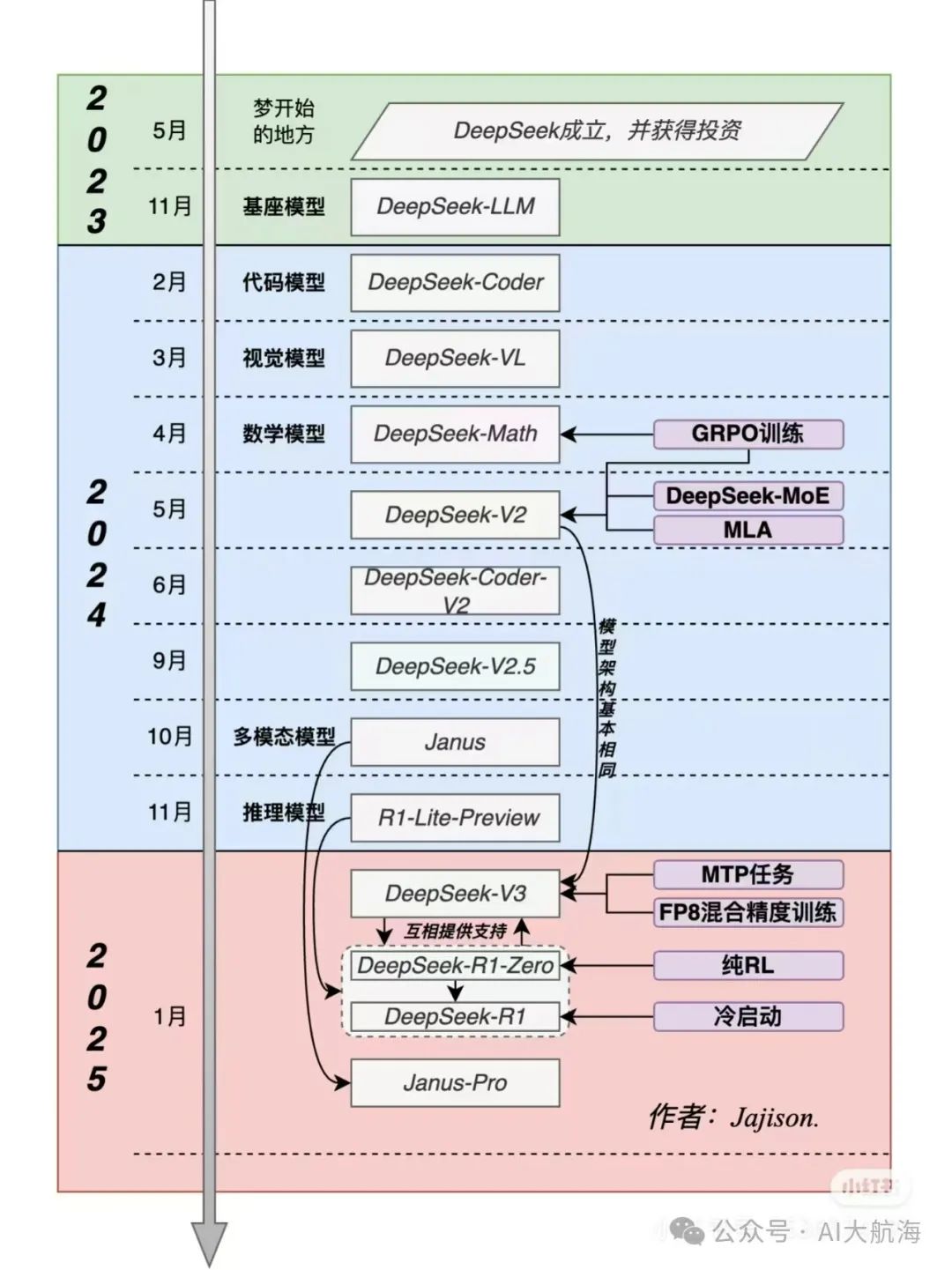
更精彩的叙事会发生在无人区,无人可 follow,更拼原创想法了。预训练之后的范式是 RL,RL 之后的范式又是什么?下一个 transfomer是什么?LLM的底层原理是什么?AGI 是个大一统模型,还是众多模型的化学反应?
这些本属于美国的命题,现在可能中国要一起参与答题了。
Deepseek改变了卷的方向,让技术创新成为新战场,让竞争更有分享精神,这种竞争硬核又高级。
随着这种竞争的加剧,也许会有人跳出三界之外,从技术和场景上开辟另外一条路径,远离拥挤的地方,进入新的无人区开辟第二战场——竞争是为了让探索发生。
作者介绍:吴炳见,心资本Soul Capital合伙人,从事AI相关的风险投资。前某大厂mobile产品经理+战略分析,之前就职于险峰和联想之星。参与投资过多个大模型和AI应用项目。关键词LLM、AI Native、AI基础设施、Robotics。


