

引子
在生成式 AI 的巨大能量被越来越多的人了解并应用的背景下,各大厂商也开始加码 AI。技术上除了运用生成式 AI 的内容扩展能力,也在努力将 AI 赋能语音助手,想达成科幻电影里知无不言的 Jarvis,或单纯只是想扭转消费者人工智障的刻板印象。
一些数码发烧友将其视作类似奥利奥镜头 deco 狂热的畸形闹剧,并对跑马灯和类似的新交互方式嗤之以鼻。但是平静下来,似乎在千篇一律的营销之后,我们发现了一些不一样的,而且很新的东西。不同于手机硬件创新方向的模糊,考虑到 AI 几年来爆炸式的发展速度,也许跑马灯之后的愿景将很快成为现实。而我们今天要讲述的,就是这个故事。
跑马灯:友商答案即为最优解?
在将跑马灯这一动效设计串联到 AI 前,我们先来看看原本的跑马灯是来干什么用的。
人天生就有被会动的、流光溢彩的高饱和度颜色所吸引的特质,红蓝闪烁的警灯,招牌上滚动过去的彩虹字,种种大量高饱和高对比色彩的利用极为强势的抓住人的眼球,很好地完成了「全体目光向我看齐我宣布个事儿」的任务,而反映在移动设备——特别是手机上——这种五彩斑斓的色带跑马灯的最初利用则呈现为信息时代最离不开的功能之一:信息提醒。
以三星的 One UI 为例子,作为曲面屏设计的始祖,三星自然不会放过这块小小弧面的利用机会,于是它为我们呈现出了恐怕是最杀马特但是最有效的通知提醒方式:Edge Lighting。每当有通知,一条五彩斑斓的跑马灯就会沿着屏幕四周快速闪烁,即便是手机倒扣的情况下其屏幕弧面倒映在桌上的光芒也足够强烈到让用户意识到——当然,在某些场合可能会带来一些社交上的不便。

Edge Lighting
现在,让我们看一下国产品牌怎么在移动设备 AI 元年利用跑马灯这种动效的。
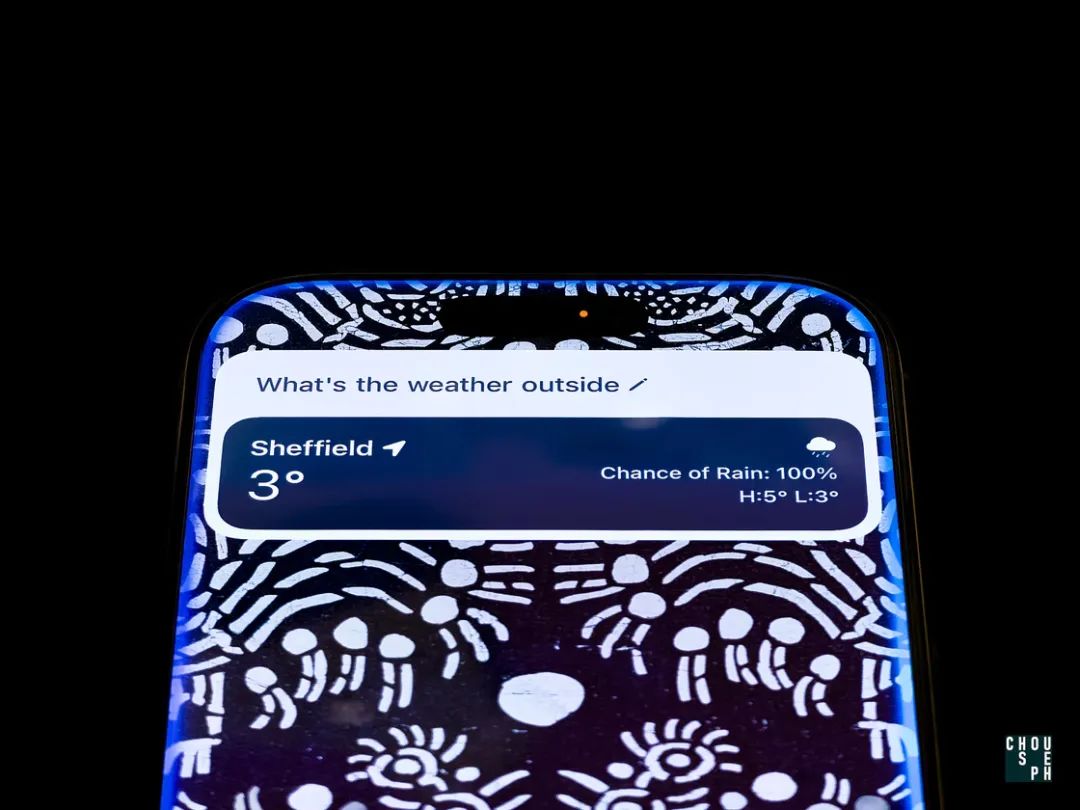
首先是大模型的早期入局者:OPPO,在作出安第斯大模型后也是马不停蹄的更新了自家的 AI 助手,谓之超级小布,其呼出动画为自侧键流出跑马灯动画环绕屏幕一周后降至 2/3 屏位置,并在底部弹出语音气泡窗与三个根据当前环境列出的智能 prompts,跑马灯动画波形会跟随语音输入的频率改变。

超级小布
其次是后起之秀:荣耀,其在 MagicOS 9 上推出的 YOYO 智能体展现出了比较强悍的多功能实力,但我们今天并非评判AI助手的能力强弱,而是看动效:唤醒 YOYO 智能体时会在屏幕底端拉起对话框,其中包含左侧的语音球和右侧的识别框,跑马灯的效果只在执行命令时出现,并快速沿屏幕边缘流动。
至此我们看到了两种有代表性的跑马灯使用方法:跑马灯作为 AI 启动的提醒和跑马灯作为AI执行命令的体现,但是不是总感觉有些割裂感?比如为什么会缺失上 1/3 屏的动效以及仅在执行的时候显示跑马灯?此时我们就可以将一切拽回 AI 动效设计的原点:Siri。
罪恶的原点:重访 Siri
从波形到语音球
自 Apple 收购 Siri 的母公司后,Siri 就取代了 Apple 自家的 Classical Voice Assistant,从 iOS 10 开始成为正式的语音助手。
早期的 Siri 的交互界面设计十分有趣:在召唤出 Siri 后,会有淡黑色和淡蓝色(早期)的全屏幕高斯模糊遮罩,底端为麦克风标志,顶部则是用户语音输入命令的识别文本。在摁下麦克风 icon 后整个图标会水平展开成线条状的波形图,并随着用户的语音起伏。除此之外,在未检测到用户输入时屏幕上半部分会主动弹出一行小字「您可以试着这样问我」并随附几条 prompts。随后几个版本的各种 UI 调整无外乎麦克风 icon 多了个圆形外围,波形图转成彩色波纹等美化更新。
种种设计表明,在这个时期的 Siri 更倾向于作为用户的聊天对象出现,呼出时全屏背景模糊为的是将用户与现在进行的事物隔离开,从而专注于与 Siri 的交流中,且中间时不时的 prompts 也在鼓励用户与 Siri 交流。但以现实成果来说,用户与其交流的欲望依旧偏低,这得感谢 Siri 并不智能的智能属性。还得多需要几个疗程,同时也是后续 Siri 设计更改的主要病因之一。

Old Siri
而在 iOS 13 之后,Siri 改为了语音球的形式,但全屏模糊遮罩的逻辑并未改变。
从语音球到跑马灯
全面屏时代开启后 Siri 的设计自然要向更大的显示面积靠拢,故删繁就简,从之前的麦克风 icon 与波形图缩小成了一个球:唤醒时屏幕低端中间会放大出一颗五彩斑斓的语音球,并随着语音指令有规律的跳动,语音输入会转变成文本出现在屏幕顶部——紧挨着刘海或灵动岛下方——空间内,在指令输入完成后语音球中心会旋转出现五个叶片表示正在执行命令,而未检测到命令时语音球会中心缩小成一团直到消失,整体更加小巧简单。

New Siri
此外,多年的随 Siri 一同唤醒的全屏模糊也默认取消了,用户也可以继续关注当前执行的工作,伴随着精简的语音球设计,这个阶段的 Siri 对用户当前操作的介入进一步弱化,打断性更差,从而削减了对用户的干扰,也表明了 Siri 从上一阶段中代表自然语言控制的人机交互端口,一个可以聊天的数字朋友,变成了呼之即来挥之即去的以完成任务为导向的冷冰冰的助手。

「跑马灯」
而跑马灯则是更进一步的以弱介入强工具属性为核心的设计方式:以侧键为起点,一条彩色的跑马灯沿着屏幕边缘奔涌一周后完成闭合,并形成一层淡淡的屏幕遮罩,跑马灯会随着用户的语音输入起伏,语音转写的文字气泡框会浮现在灵动岛的正下方,当未检测到语音输入时跑马灯会在屏幕边缘淡出。相比于语音球,跑马灯的动效更为干脆利落,介入性与打断性更差,甚至退出动画都更快速简洁,更强调了现阶段整合了 Apple Intelligence 后 Siri 的纯粹辅助工具属性。
但是,为什么是跑马灯?
The Logic Behind: Apple Intelligence 的过程正义
强警告:AI 在介入
让我们回归到这篇文章的开头:跑马灯的最原始的作用,强提醒。人天生会被流动的、高饱和度和对比度的色彩吸引,而跑马灯这个动画相当有效的做到了提醒用户这一功能,即告知用户唤醒了 Apple Intelligence 并且将介入用户当前的操作,另一点是虽然这个动画会比较张扬,但仅利用了屏幕边缘区域并不会对屏幕核心的当前工作造成影响,即呼应了上文中的 Siri 的弱打断处理手法,既通知了用户现在 Apple Intelligence 开始介入,又不会过度打断用户当前的工作,虽配色呈现较为非主流但胜在简明高效。

相同道理,Visual Intelligence 呼出动画中也有 Hue 从 Camera Control 键辐射而出,且 Apple Intelligence 认为的重要通知也会被识别为 Maybe Important 并用跑马灯圈选,无论是用户主动拉出还是 AI 主动呈现都做到了通知用户 Apple Intelligence 正在介入。
Content-Awareness:AI 能看到
这个动画又一高明之处在于它映射了「框选」机制,以主动出现的环绕整个屏幕的跑马灯为强提示,淡白色透明遮罩为核心,表明整个屏幕都被 Apple Intelligence 框选起来,基于前文提到过的结合 Apple Intelligence 的 Siri 的进阶工具属性,这对于用户而言是强有力的被动心理暗示,亦或是心理幻觉:用户唤起 Siri 是为了处理某些问题,最有可能的就是当前屏幕上的棘手 case,而 Apple Intelligence 可以看到用户当前的任务,Apple Intelligence 可以帮上忙,用户主动唤醒叠加 AI 的被动暗示,会极大增加用户的信任感。
同理,Type to Siri 也是实现了相同的操作:Siri 键盘自下而上弹出,彩色弧形波纹同时扫过键盘,屏幕内容等比缩小居中,这也暗示了 Apple Intelligence 可以看到用户当前的任务。

但是这仅局限于实际调用功能前,在反复测试后现阶段非 Type To Siri 唤醒手段下 AI 的 Content-Awareness 表现可以说是基本没有,而现有消息透露出早应实现的上下文识别与 Content-Awareness 能力在 iOS 18.4 中才会引入,先前的种种过度分析在此刻尽数破功,给你机会你不中用啊,Apple。
Privacy Indicator:AI 会提醒
回到 AI 唤醒后语音输入的动画上,prompts 转录弹窗正好在屏幕上方,紧挨着灵动岛,这个设计横向对比友商的语音助手设计是令人匪夷所思的,相比于友商的 AI 助手唤醒位置和语音 prompts 指示器都统合在了屏幕下方,结合了 Apple Intelligence 的 Siri 的交互设计却显得十分破碎,这一方面大概是由于相关热视觉动力的研究,其证明用户在看向设备屏幕时主要集中在上半部分,将 prompts 弹窗放置在上半部分可以更好的对接用户的注意力,而更深层的缘由,则需要挖一下我过去写的东西。
在我之前某一篇不知名的文章中曾写到过灵动岛作为系统级的功能,其拥有最切合Apple核心价值观的功能之一:Privacy Indicator,那颗在岛上不起眼的小黄点。

Privacy Indicator
在一系列岛的动效中,唯有系统级的状态指示是永远优先于其他动效的,这个小黄点也不例外,一切涉及音视频隐私权限的调用时该 indicator 必然会出现在极为显眼的位置,强调用户的知情权。但这与 Apple Intelligence 有什么关联?这时候我们需要回归到 Apple Intelligence 的介绍上:
Apple Intelligence protects your privacy by processing your personal information on-device, without collecting it. With Private Cloud Compute, it can handle more complex requests on larger server-based models running on Apple silicon, while still protecting your privacy.
此间揭露了 Apple Intelligence 不同于友商进行功能性堆砌的卖点展示,而是回归自身老本行,隐私保护能力,端侧、私有云计算、Apple Silicon 共同串起了 Apple Intelligence 的后台,前台则交给了这些醒目多彩的光点,不仅局限于黄色和绿色的小圆点,以至于可以在 Visual Intelligence 中看到更大的灰色(在早期为更为醒目的绿色)独立 Indicator,时刻提醒用户的隐私权调用,再次展示了 Apple 对隐私性的偏执。

回归到设计上来讲,人眼多会关注屏幕上半部分的内容,prompts 弹窗紧挨着灵动岛,而灵动岛会展示 Privacy Indicator,在主动方面用户在向结合了 AI 的 Siri 发起请求时可以直观看到提示,而在被动方面同样也是 Apple 对用户的提醒:我们尊重你的隐私权,我们全程将用户的隐私调用置于用户的主动监控下,你的信息是安全的。在潜意识中增强了用户对 Apple Intelligence 的信任。
以偏离主流审美但有效的跑马灯动效做呈现,联动此前多出的系统级提醒变化,最终回落到 Apple Intelligence 偏执的核心隐私保护上,整个链条体现出的则是 Apple 对于 AI 处理上的过程正义:从用户唤醒、交互反馈、隐私保护到任务完成,既要让用户清楚地知道 AI 何时介入,又要确保用户隐私得到最严格的保护,每个环节都经过精心设计,为用户构建了一个闭环的信任体系以及可以被窥见的 AI 伦理机制——当然,至于是真的不作恶还是虚幻的粉色泡泡,那就不得而知了。
Best Practice:不止跑马灯
这时候就可以回答一开始提出的两个疑问了:为什么会 OPPO 的超级小布会缺失上 1/3 屏的动效?为什么荣耀的 YOYO 智能体仅在执行的时候显示跑马灯?
前者可以在「AI 会提醒」的基础上粗暴的分析为将人眼视线拉向屏幕下方AI唤醒区的权宜之计,环绕屏幕一周后回缩的光效可以引导用户将视觉注意力拉向屏幕下方,从而专注于屏幕底部的AI助手功能。
后者可以由「AI 在介入」解释,即在AI自动执行相关命令时会闪烁跑马灯表现 AI 介入当前工作,可以敦促用户时刻关注 AI 的动向并在出现问题的时候及时接管 AI 的操作。
但显然,一昧地模仿学习并非探索人机交互的最优解,除开庞杂的跑马灯家族外,仍有不少个人认为处理手法极其优秀的交互设计值得各位欣赏品鉴。
波形上扫
在小米 15 发布会之后,发布会的重中之重——超级小爱终于随着内测放榜来到了各位数码爱好者的手中。事实上小米在人工智能领域的布局相当早,在没有引入大模型作为智慧助手核心的前生成式AI时代小爱同学就以远超其它所有语音助手的实用性表现广受好评,这其实在技术层面为加入了「AI」之后,类似 AI Agent 概念的新语音助手打下了坚实的基础,接下来就让我们看看超级小爱给出了怎样的一副答卷。
超级小爱的唤醒方式仍然与之前一致。长按电源键或录入自己的音色与唤醒词后唤醒。唤醒后的动画可以说「借鉴」了 Apple,流动的彩虹条状光效从下至上覆盖屏幕,同时重心有变暗的效果。这是一个非常积极的交互显示动画,通过光效和阴影表现出层级上下的关系,并进而向用户传达出「Agent is Alive」,且浮于应用与系统层级之上,掌控一切的优先级。如此高优先级的动画,正是呼应了「AI 在介入」,以及「AI 能看到」。

除此之外,随着系统更新还可以通过长按小白条快捷呼出 OCR 识别屏幕及其后续功能。超级小爱在此非常优秀的交互考量是该功能会随着屏幕内的元素种类给出不同的推荐操作,并且是完全绑定 prompts 和打字输入框出现的,不会有交互方式差异带来的割裂。另一个值得注意的巧思是页面中的几乎所有提示性元素都有着与跑马灯动效相似的渐变配色,观感上十分统一。
下沉对话框
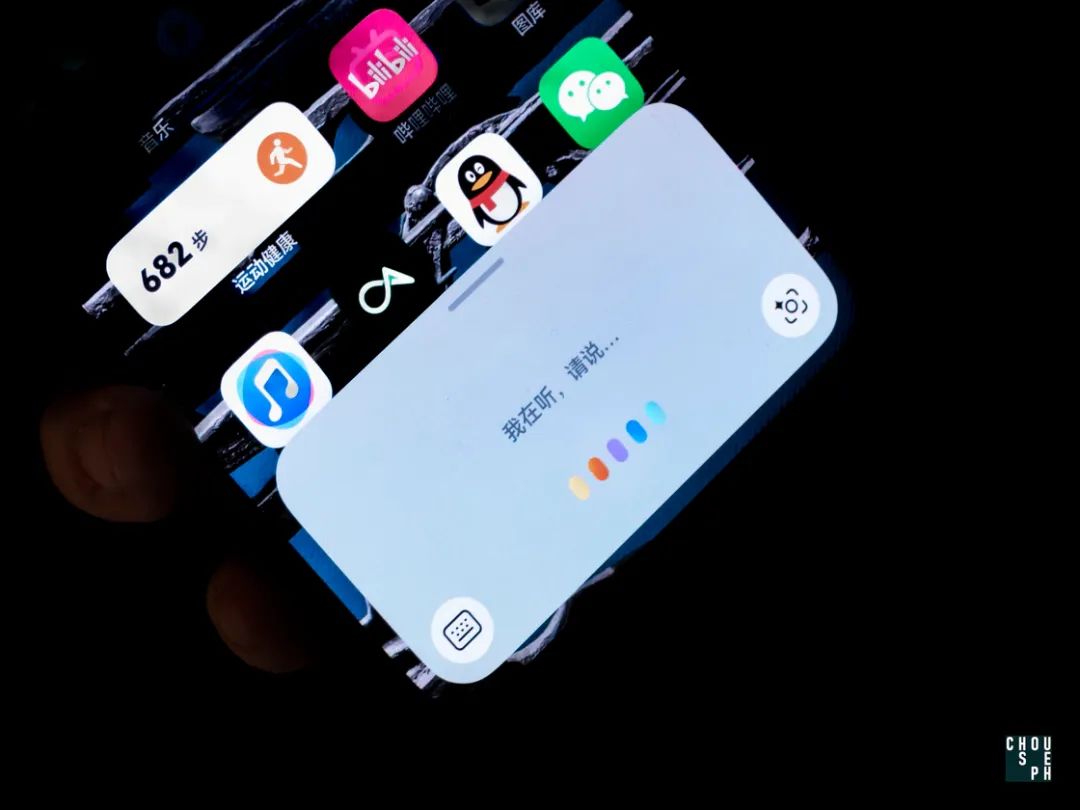
作为传统派解法的领军人物,华为,升级到 HarmonyOS NEXT 后依旧坚持在自家小艺和 Celia 上采用对话框的形式,触发端口融入全面屏时代最热门的交互方式:导航条,简单粗暴,直接开辟独立人机交流窗口。

其触发手法也足够直观,主动唤出分为三大流程:
长按侧键呼出,屏幕底端导航条上移扩大生成对话框,并伴随语音输入指示条;
长压导航条呼出,屏幕底端导航条上移扩大生成对话框;和
语音唤醒,屏幕底端导航条上移扩大生成对话框,并伴随语音输入指示条。
这三者间有一些诡异的区分点:语音唤醒直接进入沟通模式,而接触式唤醒会同时弹出建议 prompts,这也能展现出华为在 AI 助手上设计的考量,区分出可以聊天的数字朋友与功能性的 AI 助手,有些许拐回早年 Siri 的味道在。
而文件处理则是简单粗暴的直接向下拖拽,同时导航条会展开并伴随跑马灯光效,这点也是印证了 AI 能看到,但和前文所描述的有所不同,动作发起方是用户,AI 从主动方转为被动角色,故,整个流程设计构造了基于用户主动拉起行为的 AI 内容感知,如同需要主人邀请才能进入家门的吸血鬼一般——AI 并没有直接读取文章的权限,需要用户主动投喂才可以。

但是,相较于前面描述的集中带有强警告交互设计逻辑的 UI 方案来看,华为小艺的做法是明显缺乏强提醒策略来声明 AI 在介入的,所以,让我们来发散一下思维:这种做法是否可以判定为一种柔化 AI 边界的手段?
不可否认的是,小艺所采用的系统级整合的处理手法展现出了从明确的功能边界转向模糊的场景融合的趋势。在这种设计理念下,AI 不再是一个独立的工具,而是作为系统能力的自然延伸:常驻系统导航栏且可随时召唤,支持多模态输入,可根据当前界面识别用户意图,交互更为自然统一。
但反过来说,小艺的处理手法降低了用户对 AI 介入的适度感知,其强警告状态几乎只在用户主动拉起时才有所呈现,仅有引入客观材料进行分析的 prompts 才会触发跑马灯特效;而用户主动拉起小艺时则为导航条形态转变配合高斯模糊遮罩动画,并没有给到 AI 介入的提醒措施,其弱化声明 AI 介入的手法——基于作者自己足够恶意的不当揣测来看——有着转嫁风险的嫌疑,削减了生成低准确度内容后 AI 自身承担的责任,将问题更多地归因于用户选择,倒逼用户思考是否是因自己的指令不够准确无歧义导致的低质量内容,一定程度上会引发责任归属的问题,当然,锅已经甩给了用户,毕竟是用户主动拉起的。
我全都要
而站在传统派与维新派之间的,则是缝合派,GenAI 玩家中并不新的新人,Google Gemini。
其触发逻辑完美结合了前文中两个案例的特质:自下而上弹出对话窗口同时伴随跑马灯特效,直接开辟独立对话窗口的同时做到了 AI 介入的强警告措施。
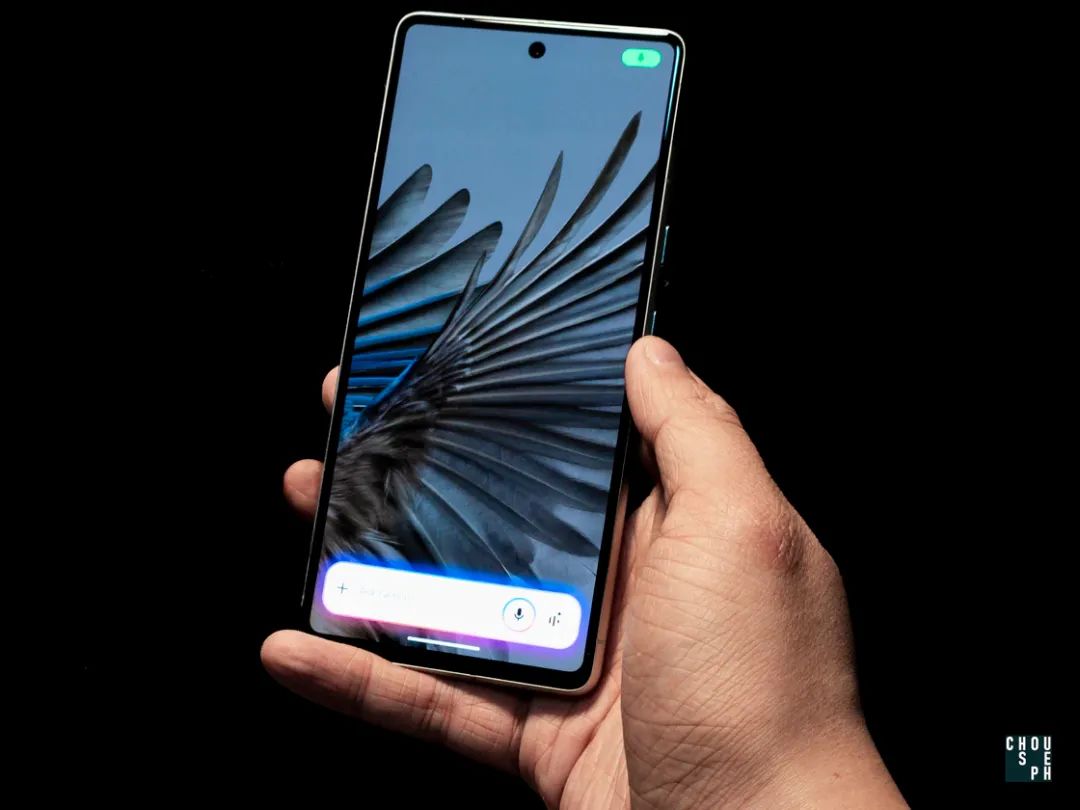
若当前屏幕有其他媒体,比如网站内容,Gemini 则会出现自下而上弹出 Ask About Screen 窗口,用户主动点击触发后 Gemini 会截屏,同时伴随波形上扫和闪粉特效,这也是一种邀请机制——虽已经弹出了 Ask About Screen 窗口但依旧需要用户主动点击才会触发识别的效果,aka A I能看到,相比起前一版 Gemini 在出现媒体后直接触发波形上扫和闪粉特效的动画,现在的处理更加隐晦,降低用户因为 AI 莫名其妙的 discretion 所引发的擅自行动带来的不适感。此外,在处理过程中对话窗口也会快速闪动跑马灯作为提醒措施,同样强调了 AI 在介入。
舞台幕后——多模态 Agent 发展现状与前景
上文所述的所有 UI 上的创新本质上都是「面子工程」,精美的交互逻辑需要强大的 AI 功能作为后盾才能真正唤起用户的使用欲望。Apple Intelligence 在国内的难产以及服务提供商的扑朔迷离,伴随着用户的期待与担忧很好的体现了这一点。尽管不得不承认目前大多数终端厂商的AI助手不过是在原有的引擎上加了个大模型接口 API 而已,但我们可以窥见厂商们的野心远不止于此,Agent 功能已经开始深入系统层。
以超级小爱的新功能为例:它可以通过识别问题中的特征词对相机参数进行调整,还可以在相册页面主动分析内容,并根据用户要求调用自动调整模块以调整照片参数。这传达出一个信号——各家厂商在生成式 AI 赋能语音助手的功能上已经不限于生成内容,并有意识的在向多模态信息处理,Agent 上继续发展。那么话说回来,什么是 Agent,又为什么说语音助手的终极是 Agent?
Agent 的应许之地
Agent 的发展成果,以及历程中出现的各类技术其实相当难精准叙述,也很难一概而论。但简单来说,一切 Agent 领域的发展与探索,最终都是为了一个最终的目的——「让 AI 成为真正的人」。我们暂且不论这一目的在政治或是伦理上的问题,单纯从技术角度出发,人是这个世界上最高级也最复杂的 Agent:通过对外界信息的接收,理解,分析和反思,演化出具有自主性的决策,并实施决策以达到特定的目的。真正意义上的 Agent 的根本特性在于自主,获取知识与主动思考是为了提升结果导向的任务性能,而不需要依靠其它任何外力的自主性是这一循环得以成为现实的先决条件。也正因此简单的直觉定义,Agent 在科学界的提出甚至远早于生成式 AI,一个空调也可以是一种粗糙的 Agent,当然现在我们发现其实生成式AI是人类社会目前最接近实现 Agent 的手段,在此之前一切有关通用人工智能的探索都以失败告终。
由于生成式 AI,或者说大语言模型的黑箱性质,提示词工程是驯服它的最佳办法,因此 Agent 也需要借助提示词工程成为一个整体。这听起来是非常符合直觉的,提示词工程说白了就是你在用 ChatGPT 的时候通过不断的给出问题使之提供让你满意的答案。但这么做虽然简单,但距离一个稳定的Agent实际上相差甚远。由于 Transformer 架构基于 token 分割语义的特性,你几乎不可能让一个大语言模型输出完全相同的结果——打个比方,对于一件相同的事件,在人所接收的相关信息不改变的情况下我们总会得出相同的认知或者看法,但这一原则对于大语言模型并不成立,它可以稳定输出 1+1=2,但无法稳定输出世界将如何发展。因此学界迫切的需要一种除了提示词工程以外,可以真正了解生成式 AI 的运行规律或者输出偏好的方法,不过这就不是我们今天需要讨论的议题了。回到应用层面,至少目前所有我们上述以及可以见到的「类 Agent 助手」,都还是主要依靠提示词工程调用 AI。
在以便携终端为主要载体的使用场景之下,Agent 的需求被很好理解地简化了:解决用户的复杂需求,并在可能的情况下对解决方案或者问题本身提出稳定且有建设性的见解。熟悉安卓玩机或者 iPhone 越狱的玩家都知道,诸如屏幕识别、ADB 等手段可以非常轻松的解决移动设备 Agent 在信息获取上的需求,那我们的需求就进一步被简化了:如何让 AI 丝滑的介入并且无缝的参加到操作决策中呢?
盗火并非易事
来自阿里的一个项目给出了非常漂亮的答案:Mobile-Agent,基于页面元素识别与大语言模型决策迭代的自动化操作模型。简单来说,Mobile-Agent 构建了一个计划-决策-反思的模型:计划 Agent 负责从整个操作流程中生成一个待办事项表,决策 Agent 基于该表进行每一步的决策,而反思 Agent 会在每一轮决策结束之后对结果进行评价并根据评估指数做出对应的后续操作,而这个系统里涉及「自主决策」的部分全部借助大模型的力量完成。
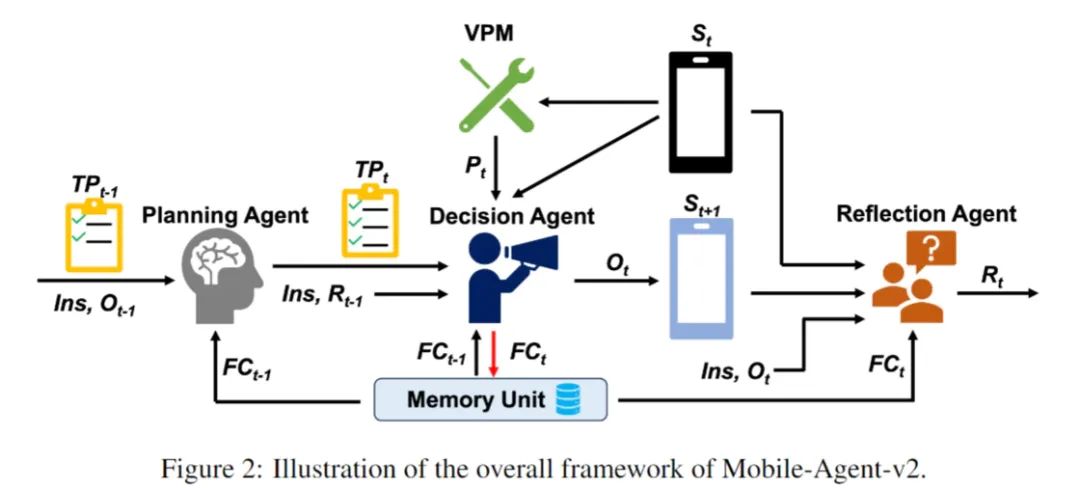
实验结果非常美好,但事实上缺陷仍然存在。不同的大语言模型显示出了差异极大的各环节准确度,甚至同一个模型在配置不同时的准确度也大相径庭。为了得到良好的实验结果,论文作者把所有操作都事先组织到一起并放在专门的表里,并且为了量化决策与反思的过程,将决策变成了从:点击、滑动、输入、打开应用,返回桌面与终止任务中选择,将反思变成了从:错误操作,无效操作,正确操作中选择。但很明显这只是对人类逻辑思维的一种粗糙模仿,事实上人脑对终端感官信息的反映远复杂于从预设中选取操作的迭代过程。针对论文中复杂操作准确率低的情况,论文作者采取的方法是将与之相关的知识投喂给大模型,作为提前的准备,但事实上如果要将其集成到系统中,这一步不仅技术上难以实现,从效率角度上也匪夷所思——如果我事先还需要喂给 AI 知识,那还没有我自己做的快。速度在这里是一个极其苛刻的指标,从根本上来说,如果基于 AI 的自动化操作没有在感官或效率上有提升,那这样的系统就是毫无意义的,只会徒增功耗。
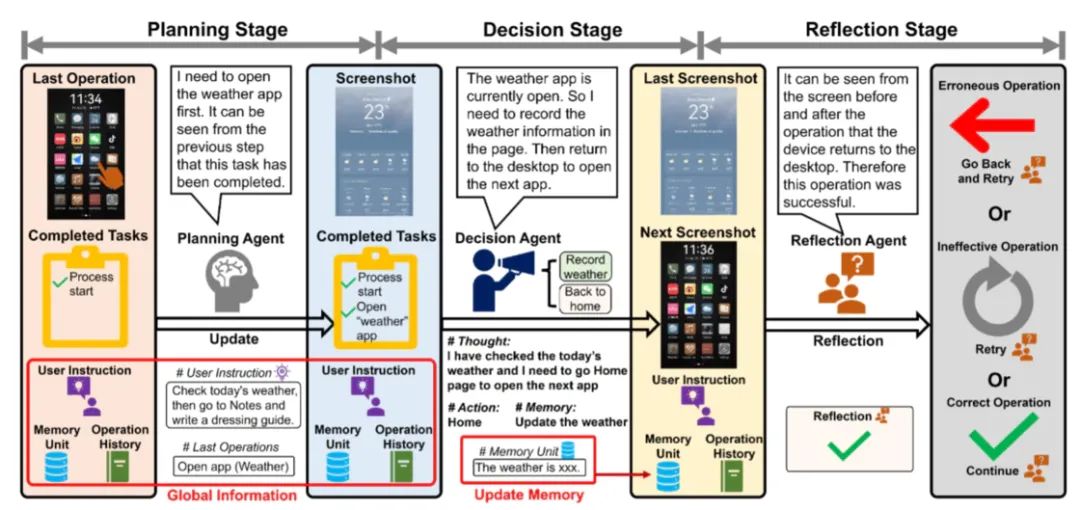
如果考虑工程学问题,那这种系统甚至有更多的缺陷——如果使用 API,如何保证网络稳定和高效决策?如果使用本地 AI 算力,如何保证功耗与续航的平衡和经过模型简化或知识蒸馏之后的模型表现?这些问题至少从我粗浅的认知来看目前还无法解决,但我们甚至要更进一步——如果 Agent 被并入到系统中,那么如何保证它的可用性?回到超级小爱的新功能,从工程师和开发者的角度,目前有两种实现方案,第一是根据微调来提升 AI 决策功能的稳定性,二是将每个功能的实际实现都写成程序,只在对结果的决策或者生成内容的过程中调用 AI。答案显而易见,第二种方式更加简单,也更实际,但是我们都知道第一种方案迭代出来的超级 AI 更加贴合我们梦想中的 Jarvis,并且更重要的是第一种解决方案的泛用性更强。将 AI 深入一个系统的底层甚至内核,在工程角度极其困难。退一万步说,一个成熟的未来系统也不可能为所有 AI 需要介入的地方都写好调用逻辑,尽管所有公司现在都在试图这么做,但这不是最终答案。未来与现实的尖锐矛盾把路线的选择推向了更加难以捉摸的未知。

J.A.R.V.I.S
在我与朋友讨论的过程中,一个我之前没有当回事的问题对于广大用户来说更加明显,也就是隐私问题。一个可能成熟的 Agent,如果对系统中的任意组件都可以轻松掌握与调用,那么如何才能保证用户的隐私不被窃取呢?上文的 Indicator 说白了只是个面子工程,我们还需要更多的技术去防止祂翻过那道僭越之墙。
业界已经有不少臻于完善且投入实际应用的隐私保护手段。联邦学习是在隐私保护方面特化的一种分布学习机制。简单来说它的目的是在多个参与者通过自己的隐私数据训练同一个模型时保证各参与方的隐私不受泄露,这听起来很反直觉,但多谢密码学的诸多理论与工具可以让「知道总和但不知道任一部分」成为可能。联邦学习已经在诸多行业中得到了广泛的应用,诸如银行的交易与量化系统,或是智慧医疗体系。对绝大多数人来说最熟悉的联邦学习应用大概是输入法中的词云联想功能,输入法能「猜」出你想写的下一个字,靠的并不是读取你所有的输入历史,而是把千千万万用户的加密输入数据投入联邦学习模型进行训练,再将训练好的模型发送给每个用户使之在本地决策。应该注意到模型的迭代和用户的数据生成是同步进行,不断迭代的,这也保证了模型效果不断更新优化。

但联邦学习没能进一步走进公众视野的原因也非常简单——难。高昂的通讯与训练成本对于商业公司如临大敌,且训练过程中的通信与训练本身的安全性也难以保证,投毒攻击已经事实上成为了联邦学习难以解决的问题。除此之外,对密码学和机器学习有些认识的读者也应当很容易发现,一般的联邦学习模型只适用于独立同分布的数据训练场景,说人话便是数据应该长得差不多,但这一听起来容易的要求实则在实际训练过程中非常困难。大多数数据场景都是非独立同分布的,针对非独立同分布数据的新颖联邦学习模型又为了达到要求在模型复杂度或是计算效率上有所妥协。
伊甸园里的苹果
刚才提到的所有困难都是技术层面的,在移动设备这样如此下沉的消费电子领域,引入 AI 最大的困难绝不是技术层面,而是观念。移动设备的下沉特性注定了使用它的大部分用户并不懂 AI,也不懂隐私保护,他们只会担心他们的电话号码、家庭住址或是银行卡密码会不会被窃取。这也是终端厂商在人机交互上强调隐私并不断试图降低 AI 助手「看起来」没那么冷酷的最终目的,他们希望所有用户都可以以很低的技术与心理成本接纳这一新技术。这事实上是交互史上一次最大的冒险,因为在历史上以前所有的交互变革——鼠标横空出世,小红点与触摸板的竞争,触屏取代键盘,本质上都是用一种或多种更好的选择强势侵入用户的思维定势,「更好用」是促使所有人接受创新霸权的最简单粗暴的方法。

初代 iPhone 发布会,颠覆性的多点触控机制
但这一手段这次可不好使了。因为涉及到隐私,用户的逆反与抵触心理会被无限放大,想让他们接受这一新的技术背后的交互方式只能低声下气地去「求」用户,更何况这一技术不仅是难以向所有人推广其人畜无害,而是它本身的安全性有待商榷。诚然AI可以提高效率帮助思考,但是用 prompt 工程或是 Agent 工具链规训一个黑箱并非安全无虞,黑箱的发展速度超越了全世界的想象,而我们并没有把握吃下伊甸园里的苹果。
不过有趣的是在这篇文章完成之前出现了一件让 AI 本身出圈的公共事件。Deepseek-R1 的横空出世,力压 OpenAI 与 Llama 成为了最好用的大语言模型,宏观上来说回击了西方的高科技霸权,但在普通人的互联网语境中更重要的是让他们认识到了 AI 的磅礴力量,进而潜移默化的影响了普通消费者对 AI 的看法。
我们有理由相信大语言模型凭借科技史上前所未有的发展速度会在不远的未来让所有人使用,并且认为「理所当然」。但在这个瞬息万变又如履薄冰的领域里,如何让用户安心的接纳这一变革就是所有厂商应该一起做的事情,而我很高兴看到无论硬件还是软件厂商都在努力交出属于自己的一份答卷。
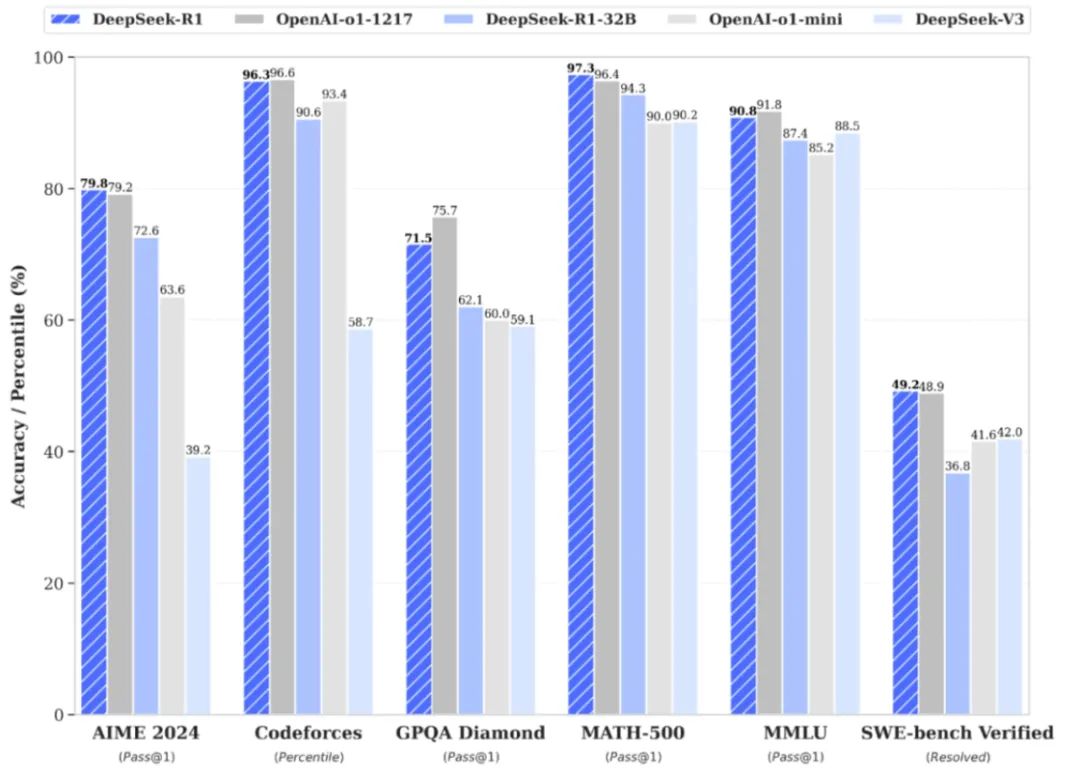
DeepSeek-R1 的性能指标体现出优势
互联网与其派生的技术发展的太快,我们已经习惯了被日新月异的技术一次次颠覆生活的底层逻辑,时间被数据流不断加速,快到人们被自己的造物强迫着局限在眼前的一隅。我们已经适应了从口袋里掏出一台连接世界的机器,但随着视线愈发轻松地到达世界的每个角落,似乎有什么别的东西被禁锢在原地。二十年前人们还对触屏的交互革新几乎一无所知;短短三十年前网吧还是万人趋之若鹜的娱乐场所,一家一台电脑还是遥远的梦想;而距离真正可用的互联网出现,也不过才三十五年。
现如今,AI 再一次加速了科技浪潮,我们能看到许多担忧的声音,不仅担忧隐私与安全,更担忧 AI 被利维坦们用来加固信息茧房,肆意操纵舆论,在愈发深重的赛博矛盾中赚取金币。这是有迹可循的,因为短短十几年,互联网已经从开源共享的地球村变成了乌烟瘴气的战场,人们有理由在相似的历史里提出相似的怀疑。但我希望大家给这些走在技术前沿的工程师再多一些时间。
AI 带来的未来冰冷而未知,人们自然能感到不安。但我们能看到终端厂商在隐私上的承诺,在人机交互上的深思,而这些正是在帮助所有人适应这一模糊的未来。未来可能存在危险,但是工程师们需要帮普通人挡下未知,让新的变革进入每一个人的生活,让 AI 在不远的将来成为人类社会的基石。在互联网的混沌时代,无私的分享与责任精神于此重生,终端厂商需要担负起对抗技术不确定性的责任,而他们确实在努力做到这一点。

HAL 9000
「哲学家只是以不同的方式解释世界。但关键是要改变它。」跑马灯再一次出现在我们的视野中,或许预示着属于新地球的黄金时代。在我们的睡梦中,跳动的 0 和 1 就是改变的开始。
原文链接:
https://sspai.com/post/96489?utm_source=wechat&utm_medium=social


