

智谱开源文生图模型 CogView3-Plus,相关功能上线智谱清言 App
2024-10-14 /
阅读约2分钟
来源:IT之家
智谱技术团队今天宣布开源文生图模型 CogView3 以及 CogView3-Plus-3B ,该系列模型的能力已经上线“智谱清言”App。
感谢IT之家网友 有鲫雪狐 的线索投递!
IT之家 10 月 14 日消息,智谱技术团队今天宣布开源文生图模型 CogView3 及 CogView3-Plus-3B ,该系列模型的能力已经上线“智谱清言”App。

据介绍,CogView3 是一个基于级联扩散的 text2img 模型,其包含如下三个阶段:
第一阶段:利用标准扩散过程生成 512x512 低分辨率的图像。
第二阶段:利用中继扩散过程,执行 2 倍的超分辨率生成,从 512x512 输入生成 1024x1024 的图像。
第三阶段:将生成结果再次基于中继扩散迭代,生成 2048×2048 高分辨率的图像。
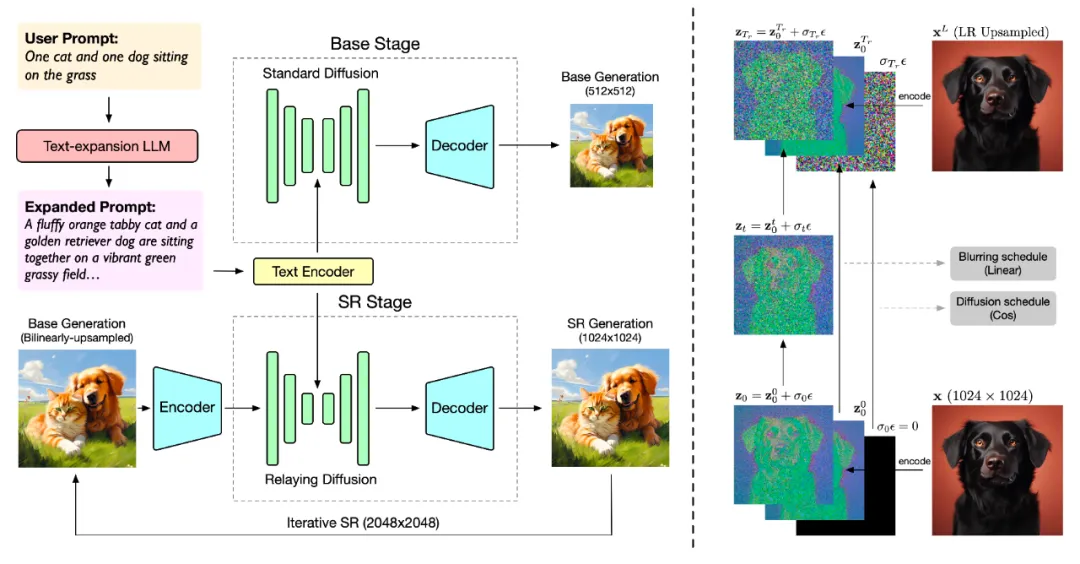
官方表示,在实际效果上,CogView3 在人工评估中比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,同时只需要 SDXL 大约 1/10 的推理时间。
CogView3-Plus 模型则在 CogView3(ECCV'24)的基础上引入了最新的 DiT 框架,以实现整体性能的进一步提升。据介绍,其采用 Zero-SNR 扩散噪声调度,并引入了文本-图像联合注意力机制。与常用的 MMDiT 结构相比,它在保持模型基本能力的同时,有效降低训练和推理成本。CogView-3Plus 使用潜在维度为 16 的 VAE。


IT之家附地址如下:
开源仓库地址:
https://github.com/THUDM/CogView3
Plus 开源模型仓库:
https://huggingface.co/THUDM/CogView3-Plus-3B
https://modelscope.cn/models/ZhipuAI/CogView3-Plus-3B


