

1.传小米搭建GPU万卡集群,抢攻AI大模型
2.Chiplet三要素:既要会做也要会拆,还要会拼
3.中美科技对垒加剧美系PC急流勇退淡出中国大陆
4.苹果将加速研发AI芯片 摆脱对英伟达依赖
5.三星整顿先进封装供应链,针对材料、设备供应“从头审视”
6.NVIDIA与AMD急于出货下一代GPU以规避特朗普上台后的关税
1.传小米搭建GPU万卡集群,抢攻AI大模型
陆媒传出小米正在搭建自己的GPU万卡集群,将大力投入AI大模型领域。这项计划已经进行了数个月,而且这么庞大的计划,就像当初造车一样,小米董事长雷军亲自带队。
据了解,小米在去年4月就成立了AI实验室大模型团队,团队成立时已经有6,500张GPU资源。而在成立这个团队前,小米在AI领域其实也已经深耕数年,雷军曾说,对于大模型,我们当然会全力以赴,坚决拥抱。我们正在研发一些有趣的技术和产品,等我们打磨好了,再给大家展示。
到今年5月,小米宣布其大语言模型「MiLM」正式通过大模型备案,米家AI向前迈出了历史性的一步。
上个月,在世界互联网大会乌镇峰会上,小米集团董事长雷军曾表示,2016年小米就All In AI,小米的智慧语音助理小爱同学,月活跃量1.2亿台,目前AI广泛应用在小米的各个业务板块。
去年4月,小米宣布组建AI实验室大模型团队,AI领域相关研发人员超过1,200人。
关于AI大模型,小米集团副总裁、首席财务官林世伟当时透露,已经把业内大模型团队都看过了一遍,小米会采用惯用的打法,也就是战略投资等方式,来实现AI大模型方面的生态合作。
去年8月,小米集团高级副总裁、手机部总裁曾学忠透露,基于和高通、联发科的深度底层技术合作和高频沟通,小米很快会推出端侧AI大模型应用,相信消费者一定不会失望。
随后雷军在同月的2023年年度演讲上宣布,小米已经在手机端跑通了Demo,手机端侧大模型(13亿参数)部分场景效果媲美云端,同时该公司还有一个60亿参数的自研大模型。
雷军表示,小米从2016年组建第一支视觉AI团队,到2023年4月第一时间成立专职大模型团队。 7年,6次扩展,小米人工智能团队已经有3,000多人了。逐步建立了视觉、语音、声学、知识图谱、NLP、机器学习、多模态等AI技术能力。与其他公司不同,小米大模型技术的主力突破方向为轻量化、本地部署。
近日市场消息传出,DeepSeek 开源大模型DeepSeek-V2的关键开发者罗福莉将加入小米,担任小米AI实验室的领导,并负责大模型团队的建设。
有知情人士称,雷军认为小米在大模型领域发力太晚,于是亲自挖人,重金招募能够领军小米大模型的人才,支付的薪酬水准在人民币千万元级别。(经济日报)
2.Chiplet三要素:既要会做也要会拆,还要会拼
3nm、2nm、18A......,艰难向前的先进制程,越来越难以匹配高算力芯片的迭代需求。在摩尔定律摇摇欲坠的共识下,系统级优化正被寄予更多的厚望,尤其是Chiplet这项技术的广泛应用和落地,业界早已迫不及待,因为它既是高端芯片突破制程瓶颈的法宝,也是先进工艺资源有限地区得以四两拨千斤的利器。
Chiplet的优势
实际上,除了芯片层面以外,业界长期以来一直都有尝试在系统层面着手,提升整体性能和降低功耗。从多芯片模块(Multichip Module,MCM)到系统级芯片(System on Chip,SoC),再到系统级封装(System in Package,SiP),这些方案都是通过集成来优化系统表现。
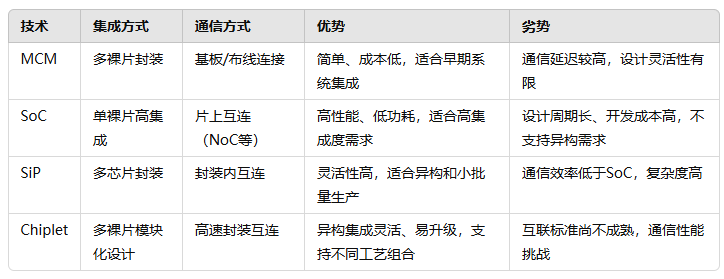
因此,如果将整个系统作为一颗芯片来看,系统层级的摩尔定律仍然可以持续下去。芯原股份创始人、董事长兼总裁戴伟民在提出SiP概念时就指出,SiP是一种广义上的系统级芯片(SoC),因此SiP是一个大规模的芯片,而不是一个小型化的印制电路板(PCB)。
SiP在封装内的芯片互联速度较低,难以满足高性能计算的需求,Chiplet技术则进一步发展了这一理念,其核心在于将单颗芯片拆分为多个功能模块(芯粒),每个芯粒可以采用最适合其功能的制程工艺独立制造,再通过先进封装技术集成到一起。
通过这种模块化的设计方式,Chiplet技术显著降低了生产成本,同时提升了性能和功耗效率。例如,逻辑核心可以采用最先进的制程工艺,而接口(I/O)模块则使用相对成熟的工艺,因为移植模拟电路需要较长时间,从而缩短了设计周期,提高了芯片设计与迭代的灵活性,最终更好地平衡了芯片设计周期、成本和性能。
Chiplet技术的三大关键要素与难点
Chiplet的成功落地,不能只靠某一个环节,这是一个庞大的系统工程。戴伟民认为,Chiplet的三要素包含IP、芯片设计,以及互联封装,这三要素缺一不可。
毫无疑问,Chiplet技术发展的基石便是优质可靠且完善的IP储备,推动IP向芯片化的芯粒去进阶。此外,每个芯粒的功能模块都需要独立性和高效互联性,这要求IP模块具备高度的标准化和复用性。例如,不同种类的IP(如处理器核心、存储单元和I/O模块)之间的无缝整合能力,以及与不同厂商IP间的互操作性,是实现高效Chiplet设计的关键。此外,推动通用标准如UCIe(Universal Chiplet Interconnect Express)对增强芯粒间的兼容性和扩展性起到了重要作用。作为中国大陆第一批加入UCIe联盟的企业,芯原股份积极参与相关标准制定工作,并已经完成了UCIe/BoW兼容的物理层接口等设计案例。
而作为国内领先的IP提供商,芯原股份已建立起强大的IP储备体系,包括6大数字处理器IP(GPU、NPU、VPU、DSP、ISP、显示处理器)和超过1600个数模混合及射频IP。这些已经获得市场验证的丰富的IP组合为Chiplet设计提供了灵活性和可复用性,确保了系统级性能优化和开发周期缩短。
芯粒化设计对芯片设计能力提出了更高要求,设计者需要将不同的IP组合形成完整的解决方案,同时也要有能力通过模块化设计将大芯片功能拆解为多个高效协作的小芯粒。在这一过程中,必须充分考虑到模块间的功耗管理、性能优化以及高速通信的需求,所有因素都需要在芯片设计端拥有相当高的技术深度。
芯原股份凭借其一站式芯片设计服务,已为全球客户设计了数千款芯片产品,覆盖从先进的4nm/5nm FinFET到成熟的逻辑工艺节点,以及28nm/22nm FD-SOI工艺节点,积累了丰富的模块化设计和拆分整合量产经验。此外,芯原也已经为客户成功设计并量产了基于Chiplet架构的高性能计算芯片,面向数据中心和汽车应用。这使芯原能够根据客户需求,灵活配置不同工艺或产线的IP组合,完成复杂的Chiplet设计。
最后,互联与封装是Chiplet技术最终实现的关键步骤,其难点在于如何将多个小芯粒“拼”成一个高效整体。小芯片间的互联需要解决信号完整性、功耗分布以及热管理等问题。此外,拼接过程中还需考虑良率与成本之间的平衡,特别是在复杂封装环境下维持系统的可靠性。
芯原股份在封装集成方面具备丰富经验,其一站式设计服务贯穿从IP设计、芯片设计到封装的全流程,积累了大量的先进封装技术实践,包括先进的CoWoS封装技术。
在ICCAD 2024期间,戴伟民特别提到,面板级封装(PLP)技术方案,能够在更大的基板上实现高密度集成,不仅降低了封装成本,还显著提升散热性能和系统可靠性。此外,玻璃基板技术凭借其尺寸稳定性、低热膨胀系数和更高的精度,已成为下一代封装技术的重要发展方向。
Chiplet的两大着陆点:高端智驾和云侧数据中心
虽然Chiplet作为一项系统级的概念,能够应用于大多数芯片,但也无法在所有应用领域内快速落地。在戴伟民看来,当前Chiplet技术将率先实现应用落地的,莫过于高端智驾和云侧数据中心这两个领域,这两个场景的高算力需求和设计复杂性使得Chiplet成为理想选择。
高端自动驾驶芯片需要同时满足高性能计算、低延迟、低功耗和高可靠性的综合需求。传统的大芯片设计虽能提供算力支持,但随着汽车智能化程度越来越高,智驾系统的单芯片面积也越来越大,成本和良率,以及散热、功耗管理和系统可靠性方面均存在显著挑战,而Chiplet技术能够通过模块化设计巧妙化解这些难题。例如,将传感器数据处理、AI计算和控制功能分解为独立芯粒,各自采用最优制程工艺,既提升了整体性能,又优化了散热效率。
此外,近年来,越来越多车企开始尝试自研芯片,但完整开发一款高性能SoC成本极为高昂,研发周期也显著拉长。Chiplet技术为车企提供了更高效的解决方案:通过复用已有较为通用的Chiplet颗粒,仅需设计核心模块,车企便可快速推出高性能芯片。这种方式不仅大幅降低了研发和生产投入,还能实现更快的产品迭代。目前,Chiplet模式已在汽车产业链中形成共识,博世、瑞萨等头部企业都已公布了相关布局。未来,随着Chiplet生态的完善,预计更多车企将基于Chiplet技术开发自研芯片,打造针对不同车型和应用场景的定制化解决方案。
云侧数据中心作为高性能计算的核心领域,对芯片的需求集中在计算密度、性能效率和能耗优化。当前,主流服务器芯片几乎都采用了Chiplet架构,通过系统级优化显著提升性能。比如,Chiplet的模块化特性使得每个功能模块可以选择最优工艺节点,这种灵活组合在提高整体性能的同时,还降低了成本。
在人工智能浪潮下,云侧数据中心需要处理大量复杂计算任务,而我国在先进制程获取上的受限问题更加凸显。Chiplet技术通过协同多工艺节点,最大化利用现有资源,为国内高性能计算芯片提供了重要路径。正如魏少军教授在ICCAD 2024所言:“现在情况变了,需要我们在技术创新上更为关注不依赖先进工艺的设计技术,一是架构的创新,二是微系统集成。”
这表明,Chiplet技术不仅是系统优化的利器,更是弥合工艺鸿沟的重要选择。
此外,Chiplet的高度模块化还让云侧数据中心可以根据实际需求灵活调整芯粒配置。例如,针对不同负载需求调整计算模块的规模或种类,使得系统更具可定制性和能效比,这种优势为我国云侧数据中心行业实现自主可控的高性能计算芯片奠定了坚实基础。
结语
Chiplet的三大要素——优质且丰富的IP储备、强大的芯片设计能力与互联封装技术创新,是推动半导体行业变革的重要基石。丰富的优质IP让模块化成为可能,芯片设计能力将繁杂的功能拆解并重组,而封装技术则将这些芯粒“拼接”成一个有机整体。未来,随着这些要素的协同推进,Chiplet将持续突破传统的边界,为芯片行业注入无尽可能。
每当仰望夜空,闪耀的星辰各自独立却又交相辉映,Chiplet的未来亦是如此。每一个独立的芯粒在技术的天穹中熠熠生辉,共同织就一个更高效、更智能、更可控的芯片生态。
3.中美科技对垒加剧美系PC急流勇退淡出中国大陆
在中美科技对垒情况加剧下,美系PC近一年多来正快速淡出中国大陆市场,过往由D、H、L(Dell戴尔、HP惠普及Lenovo联想)霸榜前三大的市占排行,今年已不复见,由陆系品牌取而代之,台品牌厂华硕(2357)则尚能守稳第四大。
多家研调虽多预期2025年的中国大陆PC市况将进一步回温成长,不过美系品牌届时在该市场的出货量,在中美对阵氛围未降温下,将再明显下滑。
在此同时,美系PC厂的主要ODM台厂伙伴包括广达、仁宝、纬创、英业达及和硕等,近年加速于越南及泰国建置的产能也将逐步到位,以因应客户需求。
依据Canalys研调统计,中国大陆消费型PC市场今年第三季受惠于政府推行激励措施带动下,以4%年增幅回温,但商用PC市场仍因复苏动能疲软,影响该季整体中国大陆PC市场年减1%、总量微降至1,110万台,来到全年高点,预期第四季还将有年、季双增表现,成长动能并可望延续至2025年,在桌上型电脑及笔电分别以9%、4%年增幅向上。
对台厂而言,电竞及AI PC将在中国大陆PC市场与中系品牌及供应链竞争的重要优势。以第三季中国大陆PC市场成长动能来看,Canalys指出,电竞及AI PC就分别有24%及70%的强劲季增幅,并推升中国大陆整体PC的ASP(产品平均售价)较去年同期上涨4%、达800美元水位。而支援AI功能的PC产品渗透率,更在该季达15%,相对于2023年第四季时的7%,已有翻倍拉升。
自去年中国大陆政府大举推动国产先行的措施下,加速了美系品牌淡出中国大陆市场,过往长踞PC前三大之一的戴尔,今年以来已排不进前五,惠普也从过往单季出货动辄上百万台、具一成以上市占,以双位数年减走势、收敛至第三季时仅有约90万台出货,及9%市占率,位居第五。
取而代之的陆系品牌中,除了依然独大的联想仍有超过三成以上、单季出货两、三百万台以上的规模外,由华为和并购同方PC业务的软通动力(iSoftStone)分食不少市占,第三季两业者亦皆有百万台以上出货规模、10%的市占表现,分居第三及第二大。(工商时报)
4.苹果将加速研发AI芯片 摆脱对英伟达依赖

据报道,苹果正在加速研发自己的人工智能(AI)芯片,以减少对英伟达的依赖,为完全终止与英伟达数十年来不愉快合作关系布局,因为双方早在苹果已故创始人乔布斯担任CEO时,就产生嫌隙。
苹果与英伟达的合作始于 2000 年,苹果Mac电脑中采用英伟达芯片,但当时的关系已出现裂痕。在 2001 年一场会议中,乔布斯向一位英伟达高层表示,英伟达产品含有抄袭自动画工作室Pixar的技术,而当时乔布斯拥有Pixar的控股权。
英伟达高层直接否认,强调英伟达拥有的绘图技术专利比Pixar还多,扬言要控告Pixar,乔布斯后来就无视这位英伟达高层。英伟达后期抱怨苹果的要求过高,尤其是对于一家始终未能成为英伟达十大客户的公司而言,苹果带来的营收并不多。
据前员工称,苹果认为与英伟达合作非常困难。英伟达芯片相当耗能,而且会产生大量热量,这对笔记本电脑来说都是不受欢迎的设计,当苹果向英伟达询问为 MacBook 设计定制化芯片的前景时,英伟达予以否决。
2008 年,当辉达设计的有缺陷的图形晶片进入苹果电脑以及戴尔和惠普生产的电脑时,两家公司的紧张局势加剧,这被称为“Bumpgate”的事件成为苹果转向 AMD 的推动力,最终在苹果开发 Apple Silicon 的过程中发挥作用。
2010 年代,英伟达开始怀疑苹果、三星和高通正在使用其图形技术专利,英伟达将继续向涉嫌违法者索取授权费。
2019 年,苹果停止与英伟达在macOS Mojave 驱动程序方面的合作。这不仅切断多数的未来支持,还使得更多数据卡无法在某些 Mac 上运作。
此前知情人士透露,苹果正与博通(Broadcom)合作开发自家第一款AI服务器芯片,打算采用台积电最先进的N3P制程生产,预计2026年前开始量产。这款AI服务器芯片代号“Baltra”,象征苹果步上其他科技大厂后尘,加紧脚步研发自家AI芯片,企图降低对英伟达芯片的依赖度,也借此节省AI计算成本。
5.三星整顿先进封装供应链,针对材料、设备供应“从头审视”
据报道,三星电子预期将全面整顿其先进半导体封装供应链,针对材料、零组件和设备“从头开始重新审视”,以加强技术竞争力。从开发阶段到采购阶段都将全面改变,预期将对国内外半导体业带来重大影响。
据业内人士近日透露,三星电子近期开始着手重组其尖端封装供应链,旨在通过检查现有供应链并构建新的供应链来增强封装竞争力。
三星首先将设备作为目标,无论现有交易关系或合作与否,都将以“性能”为最优先标准进行选择。
据悉,按照这一方针,甚至出现了退还已购买设备的情况。虽然三星为了构建封装生产线已经购买了设备,但根据重新审视的方针,正在重新检查设备。
多位知情业内人士表示,“据我了解,他们甚至在考虑退回部分设备”,并补充道,“我们正在重新‘从零考察’,最终的方向是推动供应链多元化,包括更换现有的供应链。”
同时,三星在半导体设备开发和采购策略也出现变化。
三星电子一直在实施“联合开发计划(Joint Development Program,简称JDP)”来开发下一代产品。该计划三星电子规划,其合作伙伴公司会宣布参与意向,三星最终挑选一家供应商共同推动产品商业化。JDP仅从评估后选定的一家公司购买设备。
不过,据悉三星认为这种“一对一”的开发方式存在局限性,正在为“一对多”的开发做准备。另一位业内人士表示,“三星电子正在准备选定多个JDP对象进行推进的方案”,“预计最早从明年开始实施。”
随着半导体技术的高度化和复杂化,寻找前所未有的技术和最尖端设备变得非常困难,单一企业的合作存在局限,因此需要进行变革。
简而言之,三星是要摆脱封闭模式,因此现有设备供应商的竞争对手也有机会向三星供应设备,竞争对手的合作公司也能尝试与三星进行技术开发。也就是说,现有的采购和供应环境将完全改变。
报道指出,三星电子的这些举措是因为提升先进封装竞争力迫在眉睫。高带宽内存(HBM)是通过堆叠多层DRAM,以及HBM还需要与图形处理单元(GPU)联动,能够处理大量数据,其中的关键技术都是先进封装。三星电子认为,要恢复人工智能(AI)时代半导体竞争力,封装至关重要,因此从最初的起点——材料、零组件和设备开始重新审视和准备。
如果未来先进封装供应链重组取得成果,扩展到整个工艺流程的可能性也很大。业界相关人士表示:“整个工艺领域尚未正式进入供应链重新审视阶段,主要是因为目前更集中于技术高度化(技术迁移)等工艺转换,新设备引入不多”,“预计在未来的新投资正式化之前,整个工艺流程也可能进行类似的供应链再检查。”
6.NVIDIA与AMD急于出货下一代GPU以规避特朗普上台后的关税
英伟达& AMD 现在迫使 AIB 合作伙伴比预期更早发货下一代 GPU,以应对高达 40% 的关税。据报道,英伟达(NVIDIA)和 AMD 正采取"绝望"措施,将其下一代 GPU 运往位于中国的仓库,以避免特朗普政府即将到来的关税浪潮。
Ctee 报道称,AMD 和英伟达(NVIDIA)等 GPU 制造商已经开始争取在 1 月 20 日之前将显卡运往美国主流市场,以避免可能会大幅提高价格的关税。 据说,AIB 的合作伙伴现在已经大规模提高了下一代 GPU 的产量,这是一个不寻常的趋势,主要是因为供应在开始时受到限制。
AMD-NVIDIA.jpg
鉴于 AMD 和 NVIDIA 已计划采取严格措施避免供应链"信息"泄露,据传两家公司已于 12 月初启动了下一代 GPU 的生产,以确保在 1 月 20 日总统就职典礼前将设备运抵美国的预期设施。 这是在关税即将提高消费者价格的情况下产生更多利润的又一举措,但制造商将从最初的 GPU 库存中获得更多利润。
鉴于大多数消费级游戏 GPU 都来自中国,预计价格将飙升 40%,甚至更高,因为制造商决定将关税反映到消费价格中。 有趣的是,微软、戴尔和惠普也采取了类似的措施,加快生产流程以应对特朗普的政策。
虽然我们不知道英伟达和 AMD 的下一代 GPU 的建议零售价,但 GeForce RTX 5090 的合理价格可能是 1799 美元。 因此,考虑到 40% 的关税,英伟达的旗舰 GPU 售价可能在 2500 美元左右。 这一关税将撼动消费级 GPU 市场的定价,同时也会刺激对二手 GPU 的需求。
同样,由于该政策尚未"正式"实施,我们无法确定关税后的价格,但肯定会有明显的上涨。(cnbeta)


