


图片来源:Getty Images
大型语言模型通过其Transformer架构在预测回应查询所需的下一个单词(即语言标记)方面取得了显著成就。然而,当面对需要抽象逻辑的复杂推理任务时,一些研究人员发现,即便是现代“推理”模型,在通过“语言空间”来解释一切时,也会开始遇到挑战。
如今,研究人员正试图通过构建能够在“潜在空间”中完全计算出潜在逻辑解决方案的模型来克服这些难题——这指的是Transformer生成语言之前的隐藏计算层。尽管这种方法并未给大型语言模型的推理能力带来革命性变化,但它确实在某些逻辑问题上展示了明显的准确性提升,并为新研究开辟了有趣的方向。
等等,何为“空间”?
像ChatGPT的GPT-4这样的现代推理模型倾向于通过生成“思维链”来运作。这些模型中的逻辑过程每一步都体现为一系列自然语言单词标记,这些标记会反馈给模型。
在Meta的基础人工智能研究团队(FAIR)和加州大学圣地亚哥分校的一项新研究中,研究人员将这种对自然语言和“单词标记”的依赖视为这些推理模型的“根本局限”。这是因为成功完成推理任务通常需要对特定的关键标记进行复杂规划,以从多个选项中选择正确的逻辑路径。
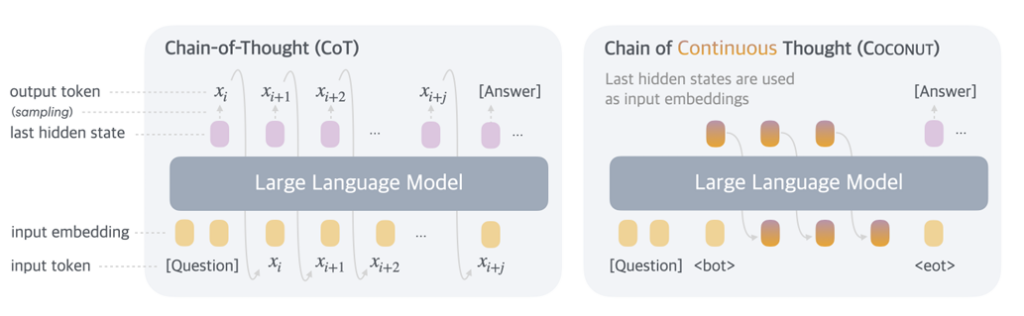
图示展示了标准模型在每一步后都经过Transformer处理,与COCONUT模型使用隐藏的“潜在”状态之间的差异。
图片来源:在连续潜在空间中训练大型语言模型进行推理
然而,在当前的思维链模型中,单词标记主要是为了“文本连贯性”和“流畅性”而生成,对实际的推理过程贡献甚微,研究人员写道。相反,他们建议,“理想情况下,大型语言模型能够自由地进行推理,不受任何语言限制,并仅在必要时将其发现转化为语言。”
为了实现这一“理想”,研究人员提出了一种“在连续潜在空间中训练大型语言模型进行推理”的方法,正如论文标题所述。这个“潜在空间”基本上由模型在Transformer生成人类可读的自然语言版本之前所包含的“隐藏”中间标记权重集组成。
在研究人员开发的COCONUT模型(代表“连续思维链”)中,这些隐藏状态被编码为“潜在思维”,在训练和处理查询时替代了逻辑序列中的单个书面步骤。这避免了将每个步骤转换为自然语言的需要,并“使推理摆脱语言空间的束缚”,研究人员写道,从而形成了他们称之为“连续思维”的优化推理路径。
更宽广的思维方式
尽管在潜在空间中进行逻辑处理对模型效率有所裨益,但更重要的是,这种模型能够“同时编码多个潜在的下一步”。与必须逐个(以一种“贪婪”的方式)完全探索单个逻辑选项不同,保持在“潜在空间”中允许进行一种研究人员将其与广度优先搜索通过图进行比较的即时回溯。
研究人员指出,即使在测试中未明确训练模型这样做,这种新兴的同步处理特性也会出现。“虽然模型最初可能无法做出正确决策,但它可以在连续思维中保留许多可能的选择,并通过推理逐步排除错误的路径,这一过程由某些隐式价值函数指导,”他们写道。
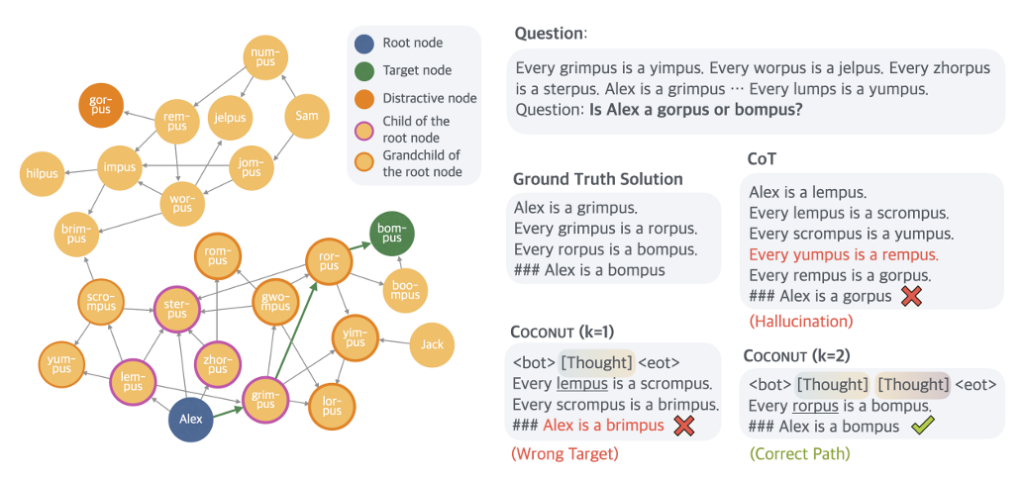
图示突出了不同模型在某些逻辑推理任务中可能失败的方式。
图片来源:在连续潜在空间中训练大型语言模型进行推理
然而,在相对直接的数学推理测试(GSM8K)或一般推理测试(ProntoQA)中,这种多路径推理并未显著提高COCONUT相对于传统思维链模型的准确性。但研究人员发现,该模型在涉及复杂且曲折的逻辑条件集(例如,“每个苹果都是水果,每个水果都是食物”等)的随机生成的ProntoQA风格查询中表现相对较好。
对于这些任务,标准的思维链推理模型在尝试解决逻辑链时经常会陷入僵局或甚至构想出完全虚构的规则。先前的研究也表明,这些思维链模型输出的“语言化”逻辑步骤“可能实际上利用了不同的潜在推理过程”,而非共享的那一个。
这项新研究加入了一系列不断增长的研究行列,这些研究旨在理解和利用大型语言模型在其底层神经网络层面的工作方式。尽管这类研究尚未取得重大突破,但研究人员得出结论认为,从一开始就用这种“连续思维”进行预训练的模型“能够使模型在更广泛的推理场景中更有效地进行泛化”。


