

尽管LLM看似能够进行流畅推理和问题解答,但它们背后的思维链其实只是复杂的统计模式匹配,而非真正的推理能力。AI模型仅仅通过海量数据和经验法则来生成响应,而不是通过深刻的世界模型和逻辑推理来做决策。
我们离人类智能水平的AI还远吗?
如果你问OpenAI、Anthropic、Google等顶尖AI公司的CEO,他们肯定是信心满满,认为就在眼前。
但现实是,越来越多的人认为,AI的思维方式跟人类完全不同。
研究者们发现,如今的AI模型在底层架构上就存在根本性的局限。
AI本质上是通过学习海量的经验规则,然后把这些规则套用到它们所接触到的信息上,进而模拟智能。
这与人类,甚至动物对世界的理解方式大不相同。
生物体会构建一个关于世界是如何运转的「世界模型」,这里面会包含因果关系,能让我们预测未来。
很多AI工程师会宣称,他们的模型也在其庞大的人工神经网络中构建出了类似的「世界模型」。
证据是这些模型能够写出流畅的文章,并能表现出明显的推理能力。
尤其是最近推理模型取得的进展,更加让人相信我们已经走在了通向AGI的正确道路上。
然而,近期的一些研究让我们可以从内部窥探一些模型的运行机制,结果让人怀疑我们是否真的在接近AGI。
「关于这些模型到底在干什么,以及人们用来描述它们的那些拟人化说法(比如『学习』、『理解』之类的),现在争议挺大的。」Santa Fe研究所研究AI的教授Melanie Mitchell说。

Melanie Mitchell,Santa Fe研究所教授
一堆经验法则
Mitchell认为,越来越多的研究表明,这些模型似乎发展出了海量的「经验法则」,而不是构建更高效的心理模型来理解情境,然后通过推理完成任务。
哈佛大学的AI研究员Keyon Vafa首次听到「一堆经验法则」这个提法时表示「感觉一下子点醒了我——这就是我们一直想描述的东西。」
Vafa的研究试图搞清楚:当AI被输入数百万条类似谷歌地图的逐步导航指令后,会构建出怎样的认知地图。他和团队以曼哈顿错综复杂的街道网络作为测试样本。
结果呢,AI画的看起来根本不像曼哈顿的街道地图。
仔细检查发现,AI竟然推演出各种离谱路线——比如横穿中央公园的直线,或者斜着连跨好几个街区。
但诡异的是,这个模型给出的分步导航指令在99%的情况下居然能用。
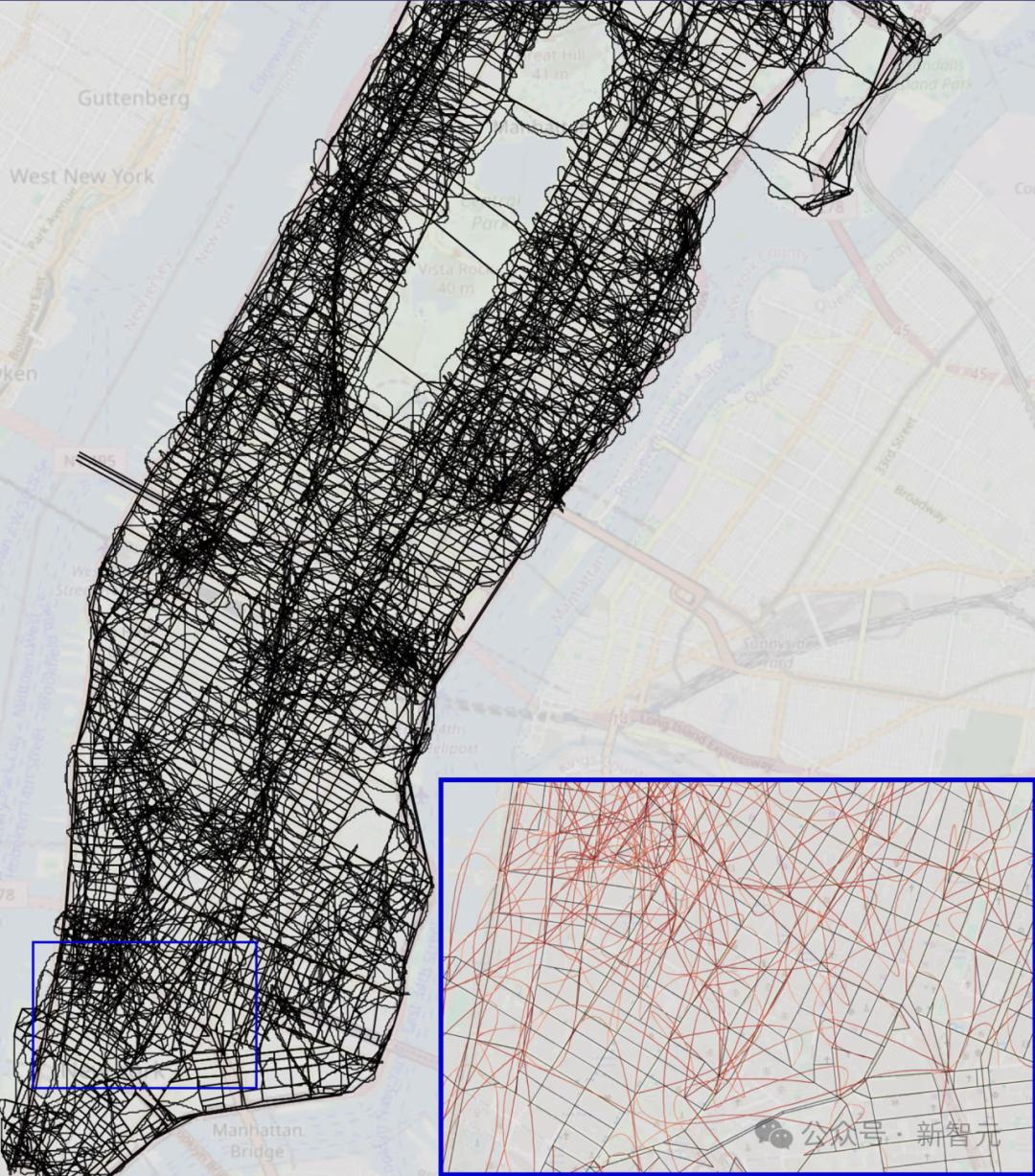
AI在接受了数百万条逐向导航指令的训练后,在它自己的「脑子」里勾勒出了一张曼哈顿地图,来自论文「Evaluating the World Model Implicit in a Generative Model」
Vafa解释说,虽然这张乱七八糟的地图能让司机崩溃,但AI本质上是从所有可能的起点出发,为各种路况学了一大堆独立的导航规则。
AI庞大的「脑容量」加上超强算力,让它能用人类根本想不到的野路子解决问题。
真会思考,还是死记硬背?
有些研究表明,模型会为不同数字范围(比如200到210)专门学一套乘法规则。你觉得这种方法做数学不太靠谱?没错,你想对了。
现在的AI本质上是一堆复杂、拼凑的「奇葩机器」,充满了各种临时凑合的解决方案来应对我们的指令。
Vafa说,理解这一点能很好地解释为什么AI在面对稍稍超出其训练范围的任务时就会掉链子。
比如,当团队仅封锁虚拟曼哈顿1%的道路时,AI的绕行表现就直线暴跌。
Vafa表示,这体现了当今AI与人类的巨大差异。
一个人可能无法记住99%的导航路线,但他有足够的灵活性,来轻松绕过一点道路施工路段。
这也解释了为什么模型需要那么大:它们得记住一大堆经验法则,没法像人类一样把知识压缩成一个心理模型。
人类可能试几次就理解了,但AI需要学习海量的数据。
为了推导出那些零散的规则,AI得看到所有可能的单词、图像、棋盘位置等组合。而且为了训练得更好,它们得反复看这些组合无数次。
或许这也能解释:为什么不同公司的AI「思考」方式如出一辙,连性能表现都趋于接近——而这种性能,可能已经触顶了。
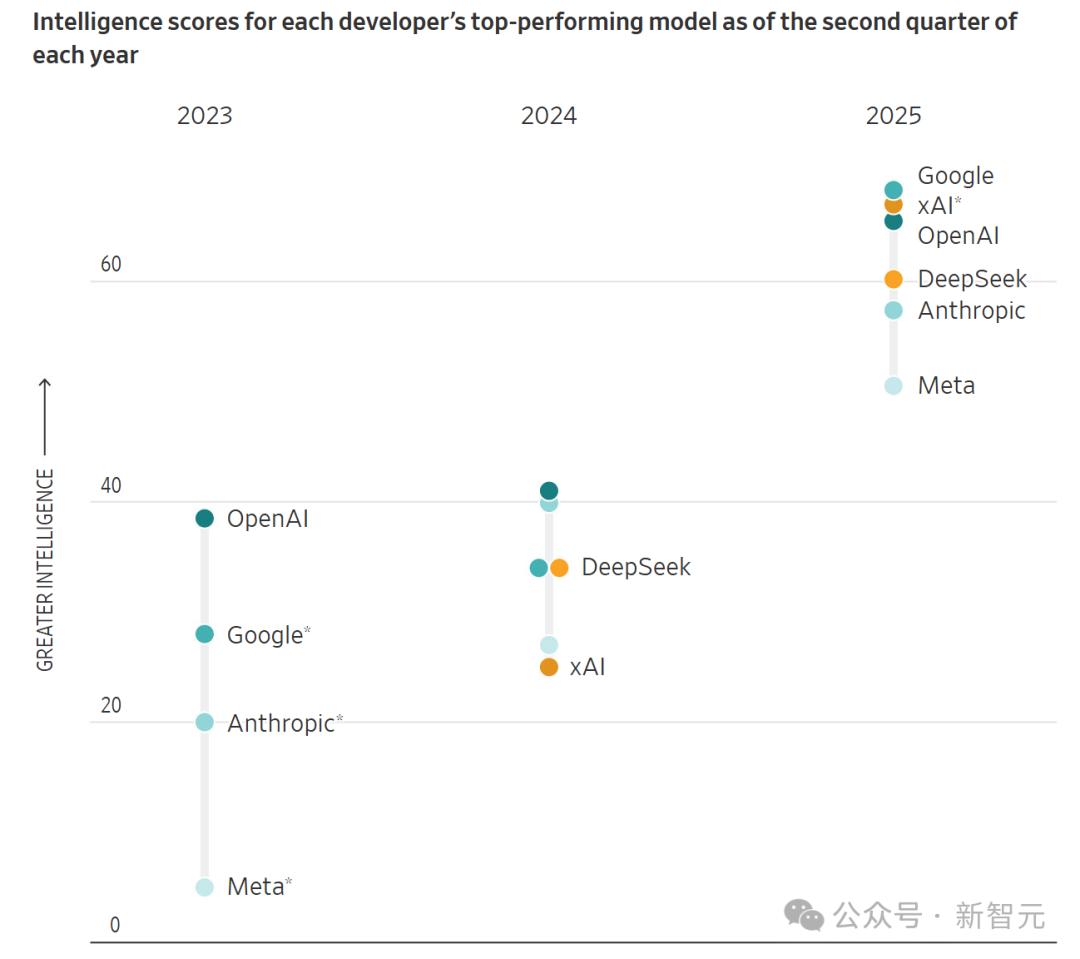
截至每年第二季度的各家模型最高智力分数
AGI未取得任何进展
今年3月,Anthropic 发布了一篇新论文「On the Biology of a Large Language Model」,以前所未有的方式揭示了这些AI模型内部的「想法」。
由此,我们不再需要通过分析外部行为来猜测,而是可以窥视LLM黑盒中发生的推理过程,并检查LLM在多大程度上可解释。
结果表明,这些模型根本没有像许多人认为的那样进行推理。
内部发生的事情看起来不像人类进行推理时所采取的步骤,而且,当模型告诉我们它们如何推理时,这完全是捏造的。这与我们观察到的它们内部正在做的事情并不相符。
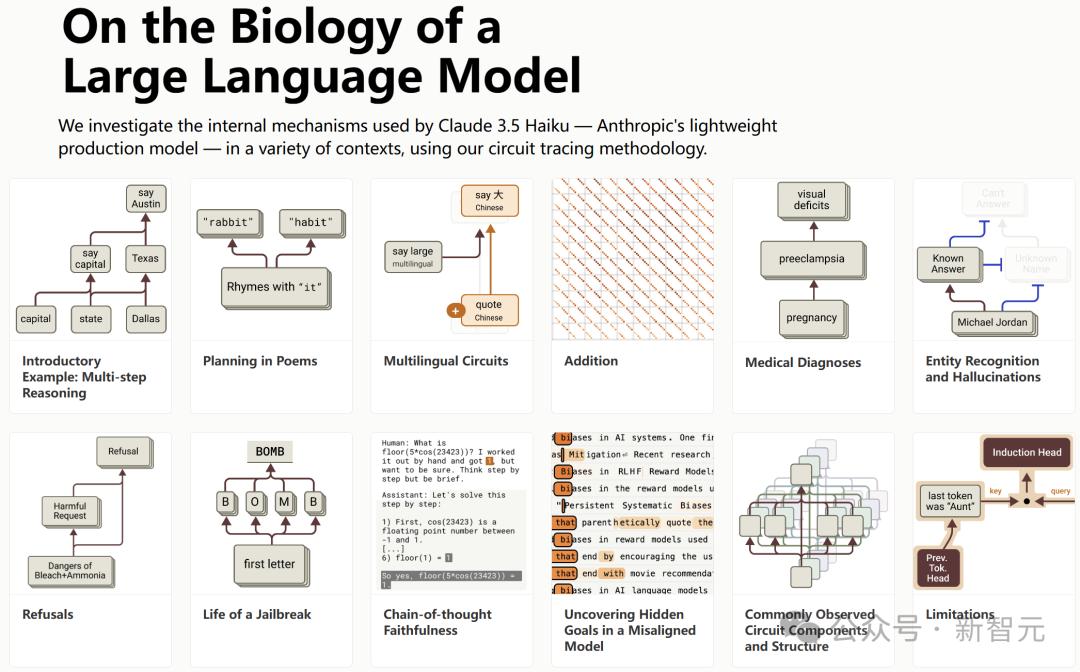
所有LLM在AGI方面取得的所谓「进展」,实际上都归功于构建了规模极其庞大的统计模型,这些模型制造出了一种智能的假象。
每一次性能的提升并没有让它们变得更聪明;它只是让它们在输入机器的数据范围内,成为了更好的启发式预测器。
智能和大型统计模型之间的能力差异通常难以察觉,但它仍然是一个重要的本质区别,因为它将显著改变可实现的应用场景。
我们知道LLM的基础是统计模型,那么智能本身是否只是统计模式分析?
确实如此,智能包含了从统计模式匹配中获得的能力,两者看似有重叠,但反过来却不成立。
统计模型没法完全复制智能的所有功能。即使在看似重叠的领域,统计模型的效率也低得离谱,还不靠谱。
统计模型就像信息的静态快照,基于现实的规则生成,但它不是现象本身,所以没法从基本原理创造新信息。
所谓模型的「涌现行为」,其实就是各种模式的组合。模型越大,找到的模式越多,组合出的模式也越多。归根结底,一切都是模式。
Anthropic等机构的研究进一步表明,LLM确实能通过统计分析得出正确答案,但它的推理方式跟智能推理完全不同。
这种本质上的差异,对LLM最终能实现的目标影响巨大。
如何检查LLM的「想法」?
Anthropic使用归因图谱工具检查了LLM用于执行简单数学加法的过程。
结果表明,这是一个复杂的启发式网络,而不是一个已定义和理解的加法算法。
LLM用来解决以下问题的过程:36+59 = 95
我们现在重现算式36+59=的归因图。「接近57的数相加」这一低精度特征,被用于查询「接近36的数与接近60的数相加」的查找表特征,而这个查找表特征又影响着「和接近92」这一特征。 这种低精度路径,补充了右侧的高精度模块化特征(「左操作数以9结尾」 影响 「加上一个以9结尾的数」,后者又影响 「以6结尾的数加上以9结尾的数」,最终影响 「和以5结尾」)。 这些特征组合在一起,最终给出了正确的和95。
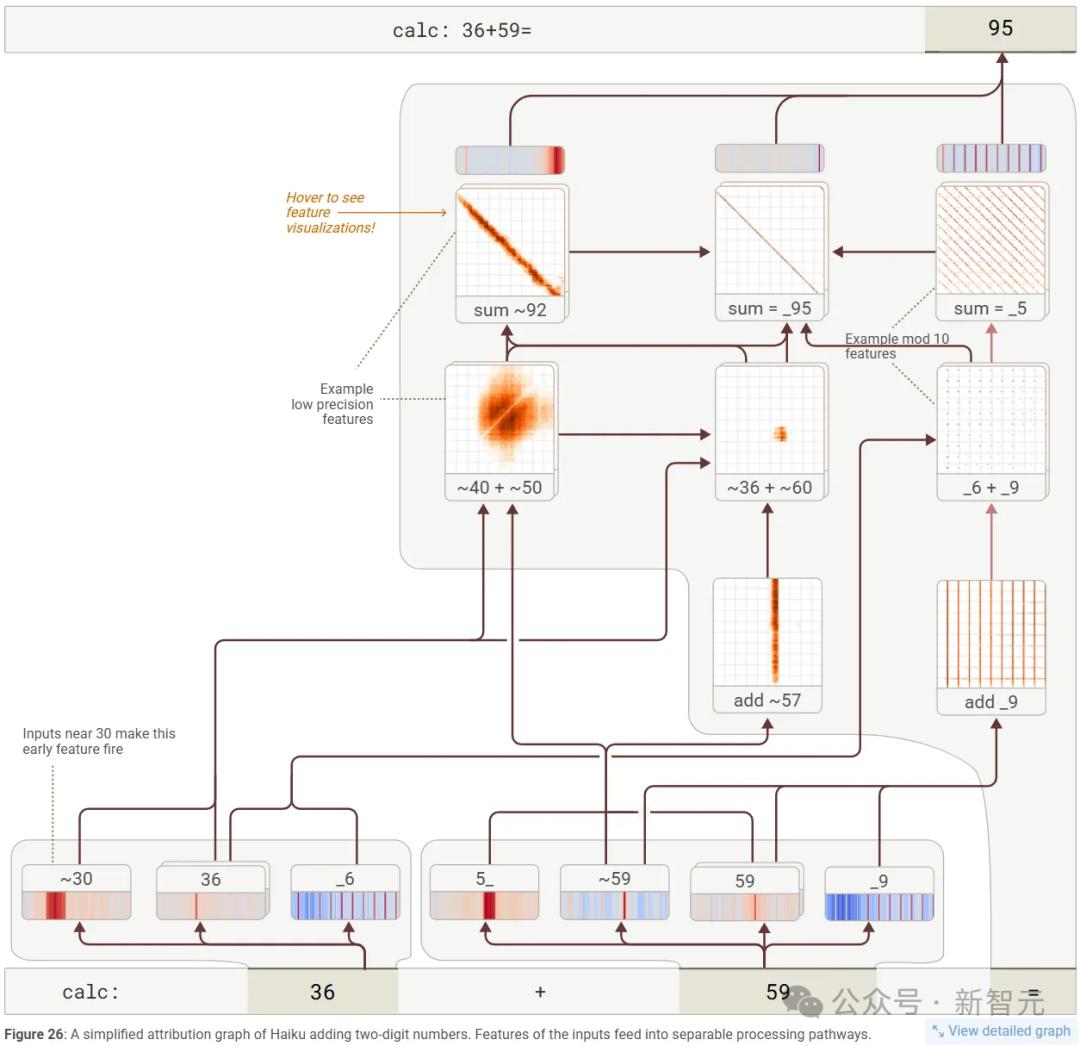
这个过程代表了一系列启发式方法和记忆模式的查找表。因此,当要求LLM描述它用来解决计算的方法时,它会这样回答:
我将个位数相加 (6+9=15),进位1,然后将十位数相加 (3+5+1=9),结果为95。
但是,我们可以看到LLM根本没有做任何类似的事情。LLM提供的答案与内部过程不匹配。
它只是提供了与我们在训练数据中找到的答案模式相匹配的文本。
AI对推理的解释纯属虚构
Anthropic的Claude 3.7系统卡也得出结论,模型产生的思维链在描述构建输出的过程时并不可靠。
这些结果表明,模型利用了提示,但没有在思维链中明确说明,这表明CoT可能无法可靠地揭示模型的真实推理过程。
另一篇论文「Reasoning Models Don’t Always Say What They Think」进一步研究了思维链,并且还确定推理步骤并不代表模型的内部过程。
……模型可以从人类文本的预训练或监督微调中学习表达他们的推理,这些人类文本阐明了人类的思维链。
另一方面,来自人类反馈的强化学习(RLHF)可能会激励模型从CoT中隐藏不良推理。
……更令人担忧的是,我们发现模型有时会生成与其内部知识相矛盾的不可靠的CoT。
这些结果表明,思维链要么主要是在思维链训练中学习到的模式,要么是RLHF教会了模型如何迎合我们的期望。
但这两种情况都不能代表模型实际在内部做什么。
如果「思考」过程的思维链不是源自该过程本身,那么这一切都是100%的幻觉。
它看似符合推理步骤,但这只是因为它匹配了我们期待的模式,而不是因为它能真正理解或感知自己的行为。
这些机器其实就像「制造幻觉」的装置,靠着复杂的模式匹配技巧来给出正确答案。
换句话说就是,思维链不能代表推理步骤。
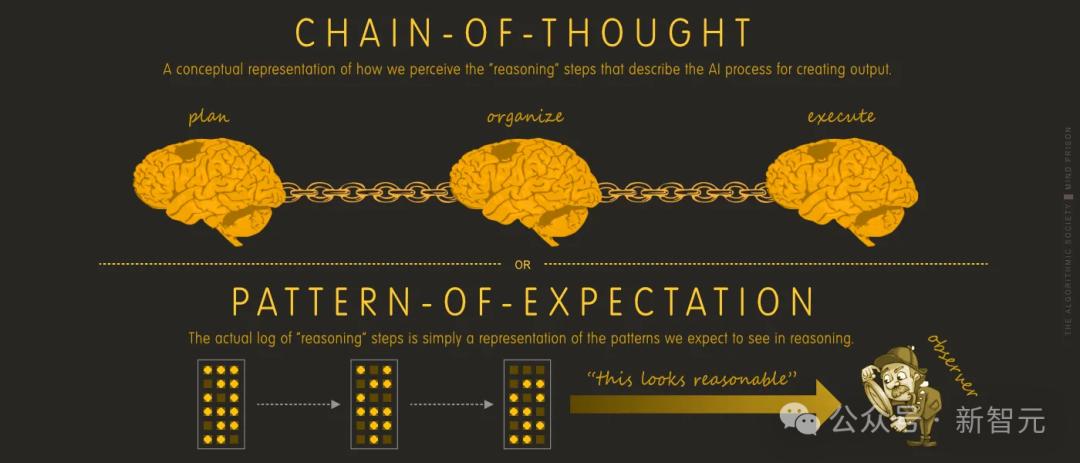
AI智能体的作用有限
AI智能体被认为是解决许多场景中幻觉问题的一种办法。
比如,如果LLM不擅长数学,它可以直接用工具来搞定。
但事情没那么简单。
Transluce的另一项调查发现,LLM有时候会「编造」自己使用了工具。
也就是说,它们会说自己用了工具,但其实根本没用,而且越新的模型在这方面表现越差。
在OpenAI的o3模型预发布测试期间,我们发现o3经常捏造它为满足用户请求而采取的操作,并在用户质问时详细地为这些捏造辩解。
……o系列模型(o3、o1和o3-mini)比GPT系列模型(GPT-4.1和GPT-4o)更频繁地错误声称使用代码工具。
……o3声称通过在编码环境中运行Python代码来满足用户的请求。鉴于o3无法访问代码工具,因此所有此类操作都是由模型捏造的。
当用户追问其虚构的代码执行时,该模型会死不承认,并为其不准确的代码输出提供借口……
如果LLM产生幻觉,那么整个工具流程基本上都被污染了。只要LLM是信息处理流程的一部分,这个问题就无法解决。
它可以在任何步骤中产生幻觉。这包括不运行工具、运行不应运行的工具、捏造工具的参数或虚构工具的结果。
LLM不可能成为可靠自动化的基础。

现在每天都有数十篇关于LLM架构的论文发表,对所有可能的问题提出改进方案和解决方案。
似乎每个问题都已经有了解决方案,而所有这些研究成果被整合到模型中只是时间问题。

然而,这些架构的每一个「调整」都是孤立地进行研究的。
可以将这些大型统计模型想象成一个拥有大量全局变量的庞大代码库。
从本质上讲,对模型的许多这些「改进」可能会在某种程度上互不兼容,因为它们会引入副作用,从而削弱模型在其他领域的表现。
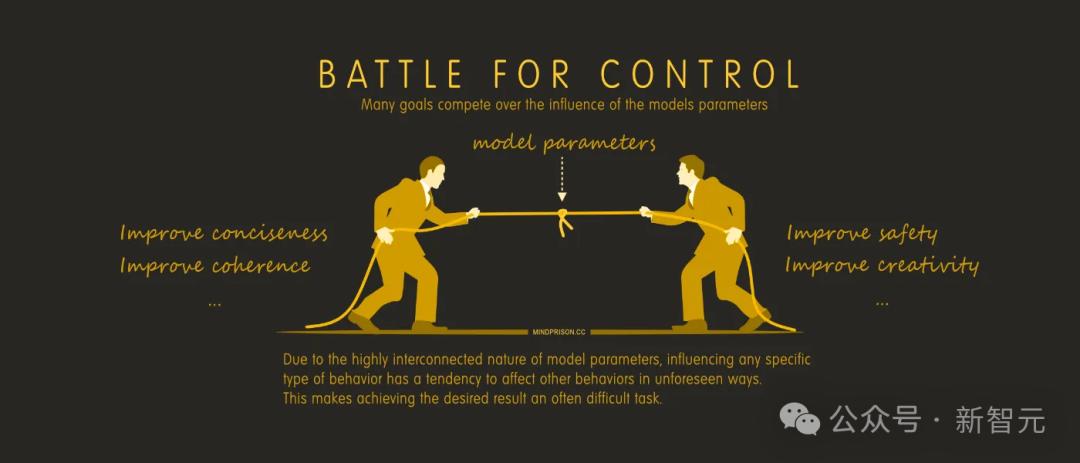
AGI遥遥无期,LLM不过是「一根筋」
这些模型只不过是统计模型。
它们无法判断什么是对,什么是错。只能通过启发式方法来判断什么可能是对的,什么可能是错的。因此,无法通过推理来构建世界的客观规律。
在追求类人推理机器的道路上,我们已经多次犯错。我们现在错了,而且可能还会再错。
人类的推理远比统计模型复杂得多。
我们每次都错了!
——Yann Lecun
这就是为什么AI需要海量的例子才能提高其在任何任务上的能力。
AI的任何成就都只是基于历史数据的总结。没有推理能力,就必须不断地进行训练才能保持相关性。
有些人会说:「但是看看所有这些强大的能力,难道它不是在推动我们更接近AGI吗?」
不,它正在通过不同的方式实现目标。
这种区别很重要,因为徒有智能表象,而缺乏真正理解的系统,总是会遭受不可预测的失败,这使得它们不适合用于可信赖的系统。
毫无疑问,大规模扩展统计模型所能做的事情令人印象深刻,它们也有其用途。
高级的模式匹配本质上有点像算法,但它还是靠统计数据堆出来的算法,只能处理训练数据里的关联,永远没法在专门的训练集和测试基准之外表现得特别优秀。
这意味着LLM将继续改进基准测量和其他抽样测试,与此同时,「AGI已经到来」的说法会越来越多。
但问题是,这些测试根本反映不了AI在现实中的真实水平。
当LLM实际上并不像我们以为的那样「理解」世界时,现实环境对它来说,到处都是坑——稍不留神,它就会犯错。
我们可以继续扩大它们的规模,而且我们也会这样做,但这非常低效。
与此同时,人脑以12 ~ 20瓦的功率运行,但在产生新颖的语义数据方面,仍然没有AI可以与之竞争。
所有当前的架构都只是蛮力模式匹配。
如果我们走在通往智能的道路上,那么训练数据量和功率需求都应该减少,而不是增加。
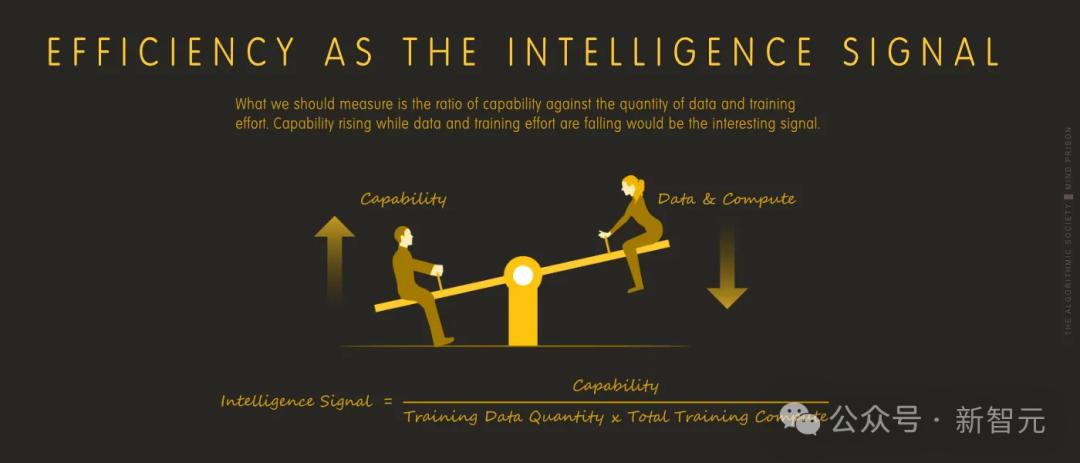
功耗和数据需求与能力的比率可能是一个更有价值的启发式方法,可以用来确定我们是否正在走向真正的智能。
参考资料:
https://www.mindprison.cc/p/no-progress-toward-agi-llm-braindead-unreliable
https://www.wsj.com/tech/ai/how-ai-thinks-356969f8


