

神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:当搜索引擎时代渐入尾声,AI研究革命正拉开帷幕。本文深入剖析了人工智能领域两大技术支柱——推理模型与智能体的协同进化,揭示出AI研究能力已跨过分水岭。文章来自编译。
未来的曙光已悄然降临。 长期以来,我一直在探讨正在并行展开的两场AI革命:自OpenAI推出o1模型以来,自主智能体的崛起与强大推理模型的涌现。这两股技术浪潮终于汇聚成令人惊叹的成果——能以人类专家的深度与细致程度开展研究、却具备机器速度的AI系统。OpenAI的"Deep Research 展现了这种融合,让我们得以窥见未来。但要理解个中意义,需从两大基石说起:那就是推理模型与智能体。
推理模型
过去几年间,聊天机器人始终都是这么的简单直白:输入问题,系统即逐字(或更专业地说,逐token)地生成回应。AI只能在输出token时"思考",于是研究人员开发出提升推理能力的技巧——比如要求它"在回答前逐步思考"。这种所谓的"思维链提示"法显著提升了AI表现。
推理模型本质上是将这一过程自动化了,在输出答案前生成"思考token"。这个突破至少体现在两方面:
首先,AI公司现在能让模型通过优秀解题案例学习推理,使其"思考"更高效。这种训练产生的思维链质量远超人工提示,意味着推理模型能攻克传统聊天机器人无法解决的数学、逻辑等复杂领域难题。
其次,推理模型的"思考"时间越长,答案质量越高(尽管边际效益递减)。这具有重大意义——过去提升AI性能只能依赖训练更庞大的模型(成本极高且需海量数据),而推理模型证明:仅通过增加输出答案时的计算资源(即推理阶段算力),就能让AI生成更多思考token从而变强。
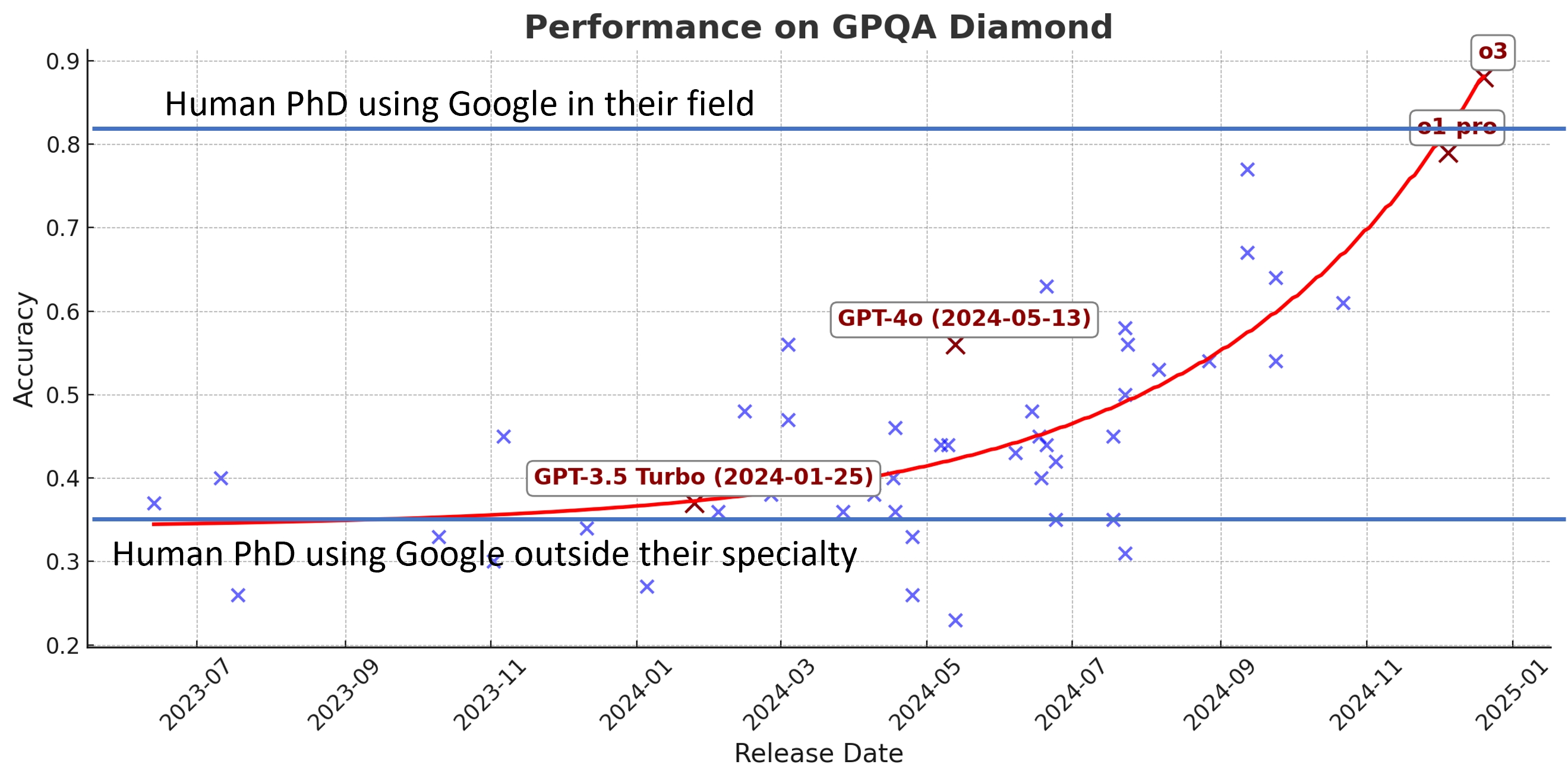
研究生水平的谷歌抗性问答测试(GPQA)包含了一系列的选择题,哪怕是博士生用网络搜索,跨专业答题的正确率也仅34%,本专业做答正确率为81%。这一测试印证了推理模型是如何加速AI能力跃升的。
由于推理模型尚处萌芽期,其能力正快速进化。仅数月间,OpenAI实现了从o1到o3系列的质的飞跃;DeepSeek的r1模型在降本增效方面取得突破;谷歌也推出首款推理模型。这仅是开端,更强大的系统即将涌现。
智能体
尽管学界对AI智能体的精确定义尚有争议,我们可将其简化为"被赋予目标后能自主追求实现目标的AI"。当前,AI实验室正展开通用智能体军备竞赛——打造能处理任意任务的系统。我曾撰文介绍Devin、Claude等早期案例,而OpenAI最新推出的Operator可能是目前最成熟的通用智能体。
下面这个视频展现了通用智能体的潜力与缺陷。 我要求Operator执行任务:阅读我发布的最新专栏文章,通过Google ImageFX生成配图并下载供我发布。过程极具启发性——Operator起一开始的操作十分精准:定位网站、阅读内容、登陆ImageFX、生成图片。随后问题接踵而至:OpenAI的文件下载安全限制阻挠了操作,智能体自身对任务执行也开始感到困惑。智能体开始系统性地尝试所有可能方案:复制到剪贴板、生成直链、甚至解析网站源代码,却都因为浏览器限制或自身逻辑混乱而失败。这场坚定却徒劳的问题解决陷入了死循环,既暴露出当前系统的局限,也引发思考:当智能体在现实世界遇阻时会如何应对?
Operator的困境凸显通用智能体目前的局限,但并不意味着智能体无用武之地。 专注于特定任务的经济价值型专业智能体已然可行。依托现有大语言模型技术的专家系统,能在其领域取得惊人成果。OpenAI的Deep Research正是明证,彰显专注型AI智能体的强大潜能。
Deep Research
OpenAI的Deep Research(勿与谷歌同名产品混淆)本质上是专业研究型智能体,基于尚未发布的o3推理模型,配备了专属工具与能力。这是我近期所见的,最令人印象深刻的AI应用之一。为理解其强大之处,我们来设定一个课题:我特意选择研究领域内高度技术化且具争议性的议题——初创企业什么时候该停止探索、开始扩张?要求系统检视该主题的学术研究,聚焦高质量论文与随机对照试验,处理模糊定义并调和常识与研究的冲突,最终呈现出研究生级别的讨论成果。

AI提出了若干犀利问题,经我澄清需求后,o3模型开始干活了。 其进展与"思考"过程清晰可见。下方流程片段值得仔细揣摩:AI如研究员般探索发现、深挖"兴趣点"、解决问题(如寻找付费墙论文的获取替代方案)。整个流程持续了五分钟。
好好看看其"思维"过程的三个片段
最终我得到了一份13页3778字的草案,内含6条引注与若干参考文献。 说实话,尽管我期待有更多信源,但表现已非常优秀:里面整合了很复杂很矛盾的一些概念,发现了意料之外的关联,仅引用了高质量的文献并准确引述。虽无法保证绝对正确(尽管未见错误),但这份成果足以媲美博士生初期的水平。下方节选足以说明我的震撼。

文献引用质量标志着实质性进步。 里面不是常见的AI幻觉或错误引用,而是含我同事Saerom Lee与Daniel Kim开创性研究在内的高质量学术资源。点击链接不仅可导向论文,而且往往还直接定位到重点引文。尽管仍受限于数分钟内可获取的开放资源(付费论文尚难触及),但这标志着AI与学术文献互动方式的根本转变——AI能做的不止于总结研究,还包括以近乎人类学者的深度主动参与学术对话,这是有史以来的第一次。
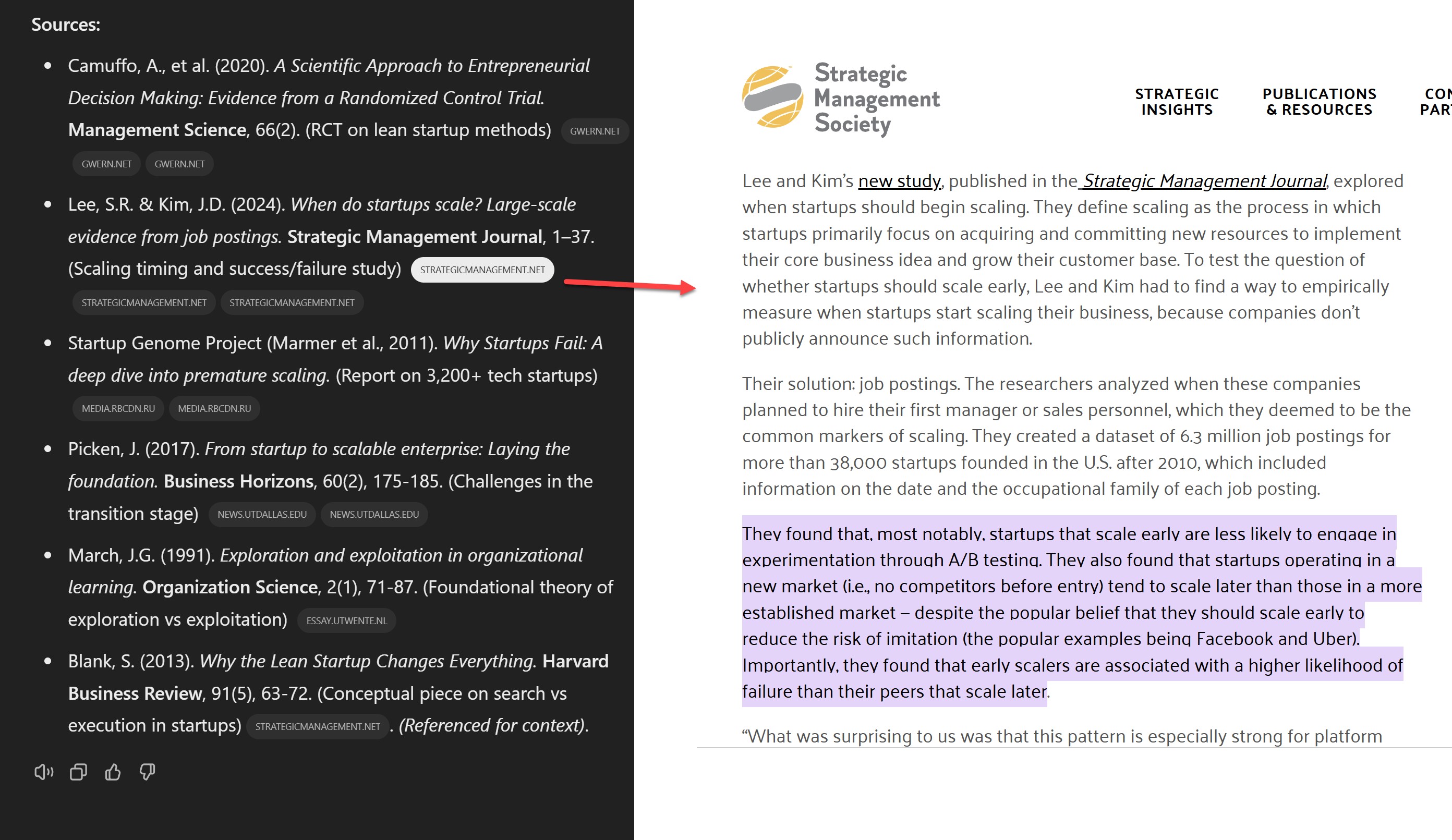
谷歌上月推出的同名产品Deep Research 值得拿来对比一下。 谷歌系统提供了更多引注,但里面混杂了质量参差不齐的网络资源(付费信息与书籍的缺失制约着所有智能体)。其文档搜集方式呈批量抓取特征,与OpenAI研究型智能体好奇心驱动的探索截然不同。且由于当前仍依赖非推理型的旧版Gemini 1.5模型,总体摘要更流于表面(尽管扎实无误),如同优秀本科生作品。阅读下方节选即可感知差异。

客观评估: 二者产出均相当于人类数小时工作量——OpenAI系统接近博士生水平,谷歌则似优秀本科生。OpenAI在公告中提出大胆主张,用图表显示其智能体能处理15% 高经济价值研究项目与9% 极高价值项目。尽管这些数字因方法论不明而需存疑,但实测表明其并非空谈。Deep Research确能在数分钟内生成精妙分析。鉴于发展速度,谷歌不会容忍这种能力差距长期存在,未来数月研究型智能体将快速进化。
拼图已逐渐成形
可见AI实验室构建的组件不仅相互契合,更能产生协同效应。 推理模型提供智力引擎,智能体系统赋予行动能力。当前我们处在Deep Research等专业智能体时代,因为即便最先进的推理模型也还没做好实现通用自主的准备。但"专业"并非局限——这些系统已能完成曾经需要高薪专家团队或专业咨询机构的工作。
专家与咨询机构不会消失——相反,随着其角色从执行者转变为AI系统工作的统筹人与验证者,他们的判断力将愈发关键。 但实验室相信这只是起点。他们押注更好的模型将破解通用智能体密码,然后就能突破专业任务的边界,成为能浏览网络、处理多模态信息、在现实世界采取有效行动的自主数字劳工。Operator表明我们尚未抵达终点,但Deep Research暗示我们正行进在正确的道路上。
译者:boxi。


