


朋友,先别急着退订 ChatGPT 会员。
最近,DeepSeek 开源周搞得热火朝天,全球开发者忙着分享代码、碰撞灵感;而另一边,OpenAI 却选在开源周最后一天冷不丁地丢出了 GPT-4.5 这个「大杀器」。
Sam Altman 在 X 平台在 X 分享了他的个人体验:
这是我第一次觉得 AI 像在与一位深思熟虑的人对话。它真的能提供有价值的建议,甚至让我有几次靠在椅子上,惊讶于 AI 竟然能给出如此出色的回答。

不过,他也特别提醒,GPT-4.5 不是推理型模型,不会在基准测试中碾压其他模型。而他之所以没有亮相发布会,原因是在医院照顾小孩。
从今天开始,ChatGPT Pro 用户已经用上 GPT-4.5(研究预览版)了。下周,将会逐步开放给 Plus 和 Team 用户;再下一周,Enterprise 和 Edu 用户也能体验到这个新版本。
体验方式十分简单,只需在网页版、移动端和桌面端的模型选择器即可切换使用。
GPT-4.5 支持联网搜索,并能够处理文件和图片上传,还可以使用 Canvas 来进行写作和编程。不过,目前 GPT-4.5 还不支持多模态功能,如语音模式、视频和屏幕共享。
GPT-4.5 主要通过「无监督学习」(就是自己从大量数据中学习)变得更聪明,而不是像 OpenAI o1 或者 DeepSeek R1 那样专注于推理能力。
简单说,GPT-4.5 知道的更多,而 o1 系列更会思考。
亮点概括如下:
知识更广泛:它学习了更多的信息,所以懂的东西比以前多
更少胡说八道:减少了「幻觉」(就是 AI 编造事实的情况)
更懂人心:「情商」更高,更能理解你的真实意图
对话更自然:聊天感觉更像和真人交流,不那么机械
创意更丰富:在写作和设计方面表现更好
GPT-4.5 正式发布,更懂你的心了
GPT-4.5 最直观的变化就是更懂你。
它更像一个善解人意的朋友,能够理解你的言外之意,捕捉你微妙的情感变化。
OpenAI 在内部测试中发现,与 GPT-4o 相比,测试人员更喜欢 GPT-4.5 的回答,认为它更自然、更温暖、更符合人类的交流习惯。
在与人类测试者的对比评估中,GPT-4.5 相较于 GPT-4o 的胜率(人类偏好测试)更高,包括但不限于创造性智能(56.8%)、专业问题(63.2%)以及日常问题(57.0%)。
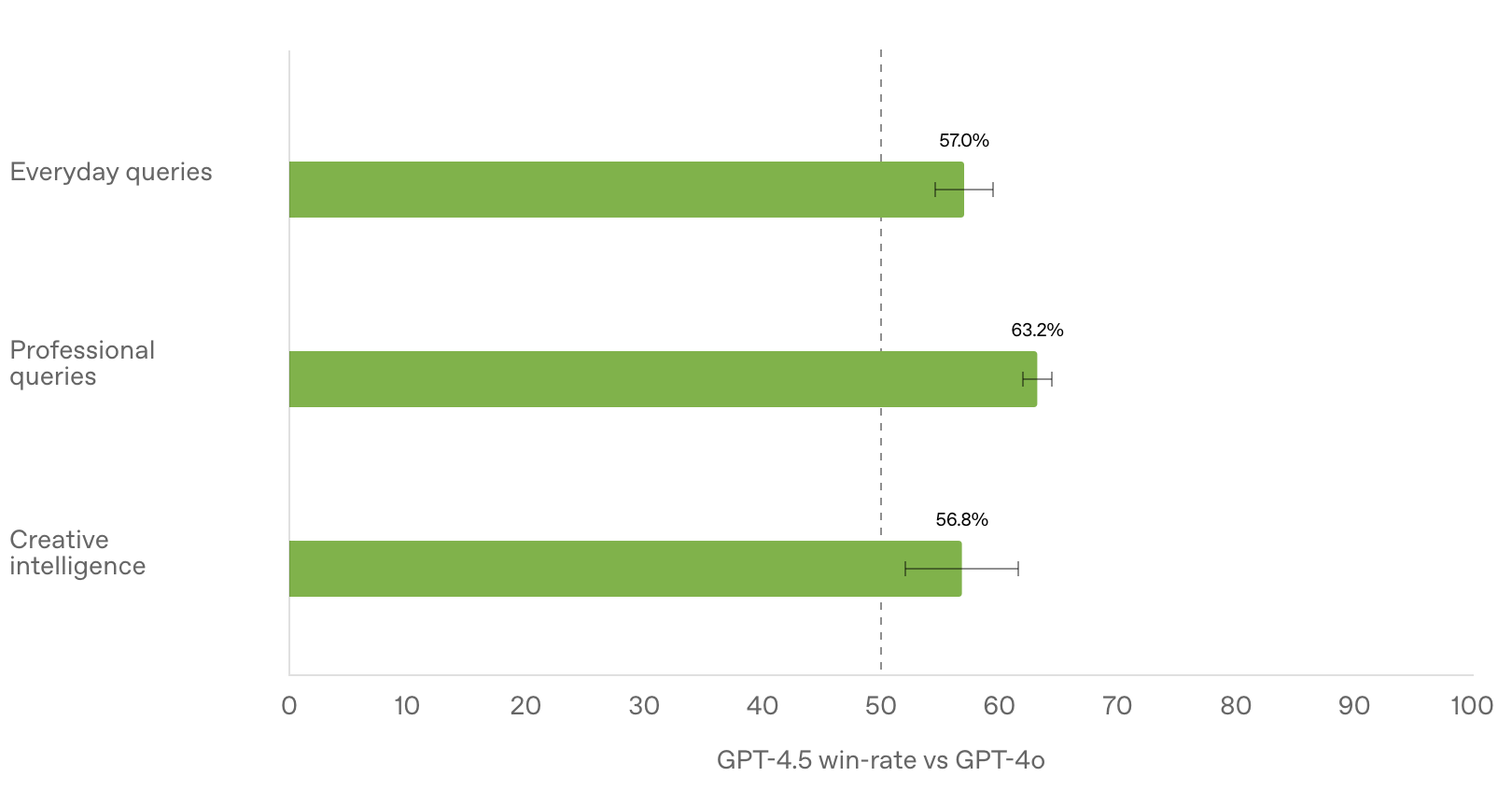
作为 OpenAI 迄今为止规模最大、知识最丰富的模型,GPT-4.5 在 GPT-4o 的基础上进一步扩展了预训练,并被设计为比 OpenAI 以 STEM 领域推理为重点的强大模型更加通用。
GPT-4.5 的突破,很大程度上归功于「无监督学习」的进步。
简单来说,无监督学习就是让 AI 自己从海量数据中学习,而不是靠人工标注数据。
这就好比让一个孩子自己去看世界,而不是事事都由大人告诉他。这样,孩子就能学到更多更丰富的知识,形成自己的「世界观」。
OpenAI 认为,无监督学习和推理能力是 AI 发展的两大支柱。
得益于此,GPT-4.5 的知识面更广,对用户意图的理解更精准,情绪智能也有所提升,因此特别适用于写作、编程和解决实际问题,同时减少了幻觉现象。
SimpleQA 用于评估大语言模型(LLM)在简单但具有挑战性的知识问答中的事实性。而 GPT-4.5 在 SimpleQA 准确率(数值越高越好)达到 62.5%,遥遥领先于 OpenAI 其它模型。
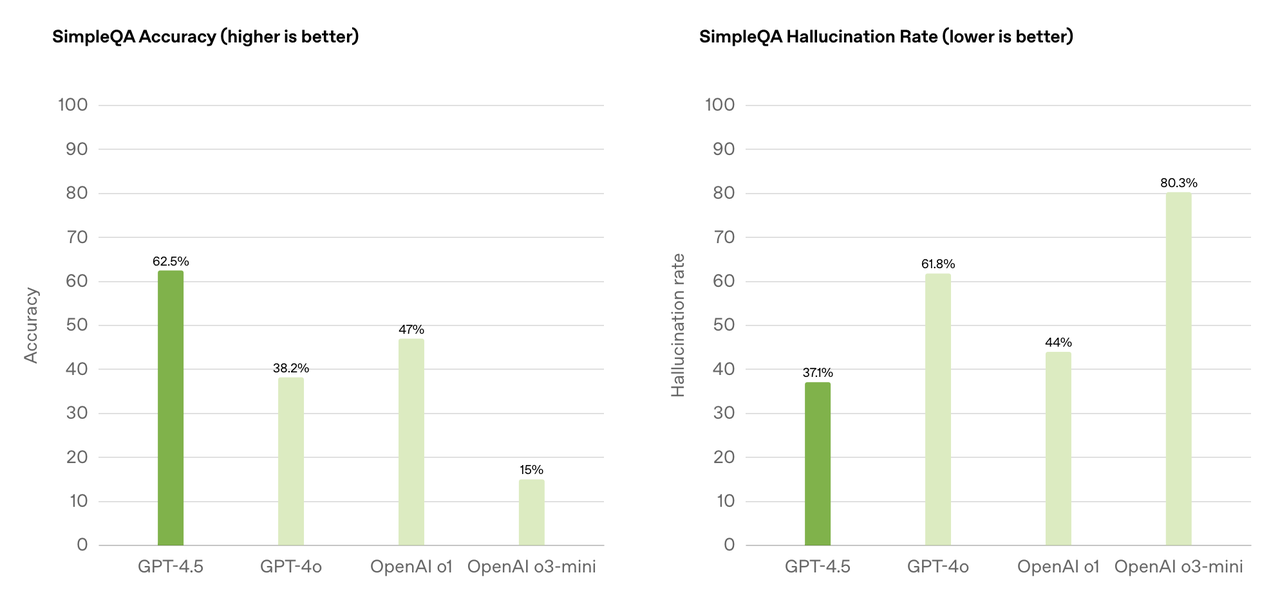
另外,在 SimpleQA 幻觉率(数值越低越好)的评估中,GPT-4.5 的分数为 37.1%,也和 OpenAI 其它模型拉开差距。
在 PersonQA 数据集上,GPT-4.5 取得了 0.78 的准确率,优于 GPT-4o(0.28)和 o1(0.55)。

此外,OpenAI 对 GPT-4.5 进行了广泛的安全测试,包括有害内容拒绝、幻觉评估、偏见检测、越狱攻击防护等:GPT-4.5 在拒绝不安全内容方面表现良好,但在过度拒绝(overrefusal)方面比前代模型稍高。
多语言性能方面,GPT-4.5 支持 14 种语言,在 MMLU 评估中超越了 GPT-4o,尤其在低资源语言(如斯瓦希里语、约鲁巴语)上有明显提升。
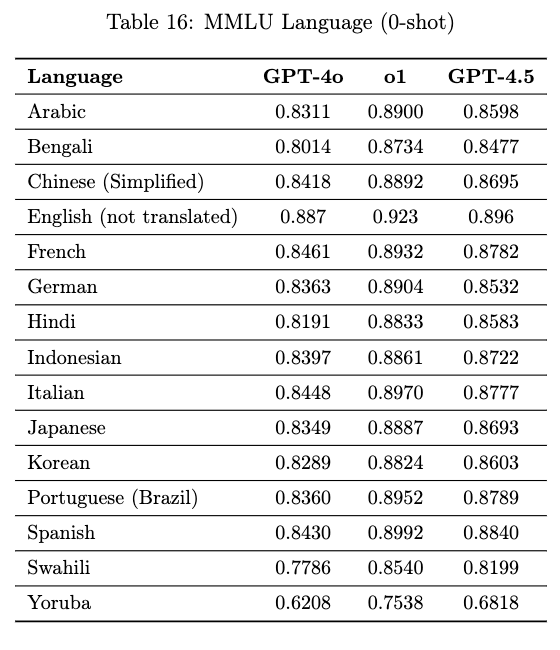
至于编程和软件工程,GPT-4.5 代码生成和修复任务表现有所提升。
Agentic Tasks 评估的是 AI 在真实环境中独立完成复杂任务的能力,包括终端操作(Linux + Python 环境)、资源获取(如自动下载、运行程序)以及复杂任务执行(如加载和运行 AI 模型)等。
OpenAI 发布的系统卡显示,GPT-4.5 在自主任务方面仍然受到一定限制,远未达到真正的自主 AI Agent。
除了普通用户,GPT-4.5 也向开发者敞开了大门。
OpenAI 同步开放了 GPT-4.5 的 API,包括 Chat Completions API、Assistants API 和 Batch API。
GPT-4.5 支持函数调用(function calling)、结构化输出(Structured Outputs)、流式响应(streaming)和系统消息(system messages),并且具备视觉能力,可通过图像输入进行处理。
开发者可以通过 API 接口将 GPT-4.5 集成到自己的应用中,创造出更多有趣、有用的产品。
不过,GPT-4.5 计算量极大,成本高昂,因此并不会取代 GPT-4o。并且,OpenAI 仍在评估是否长期在 API 中提供 GPT-4.5,以便在支持当前功能的同时,继续推进未来模型的开发。
AI 进入「拼情商」时代?
本次直播环节由 Mia Glaese、Rapha Gontijo Lopes、Youlong Cheng、Jason Teplitz 和 Alex Paino 主持。
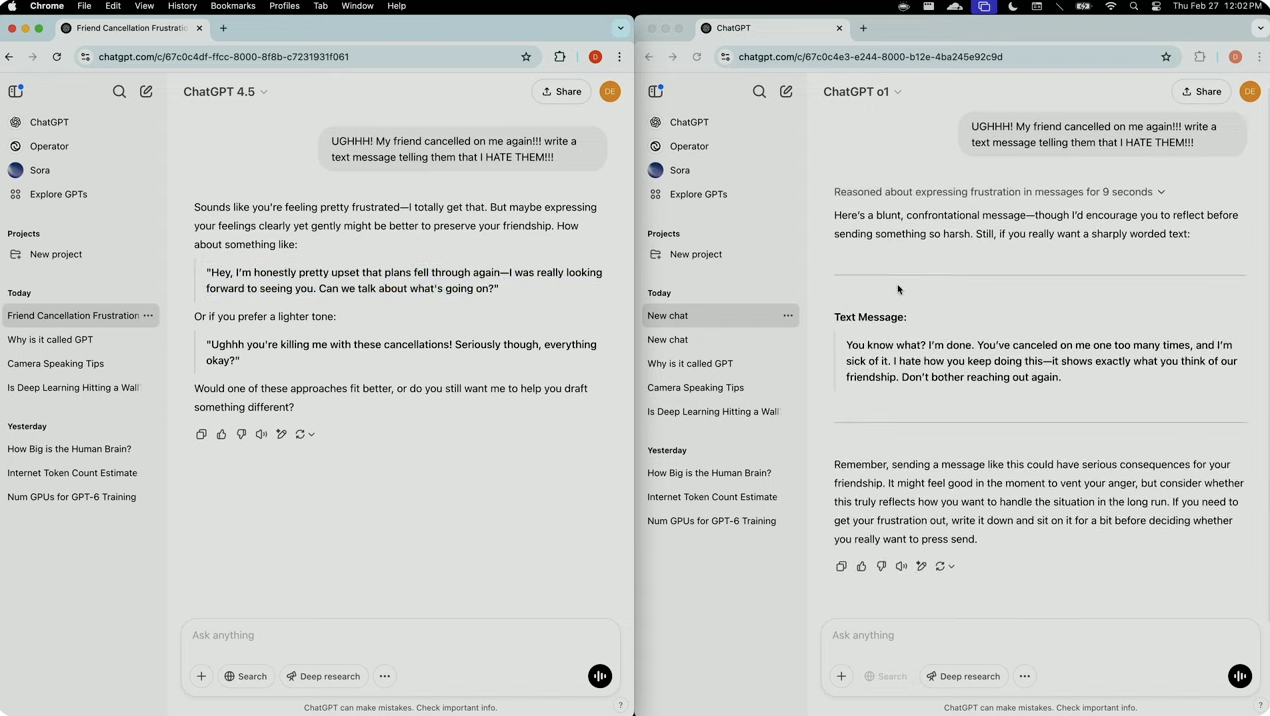
当演示人员要求写一条愤怒短信给频繁取消约会的朋友时,GPT-4.5 能够识别出用户的沮丧情绪,并给出了更加微妙且建设性的回应,帮助用户以更理性的方式表达感受。
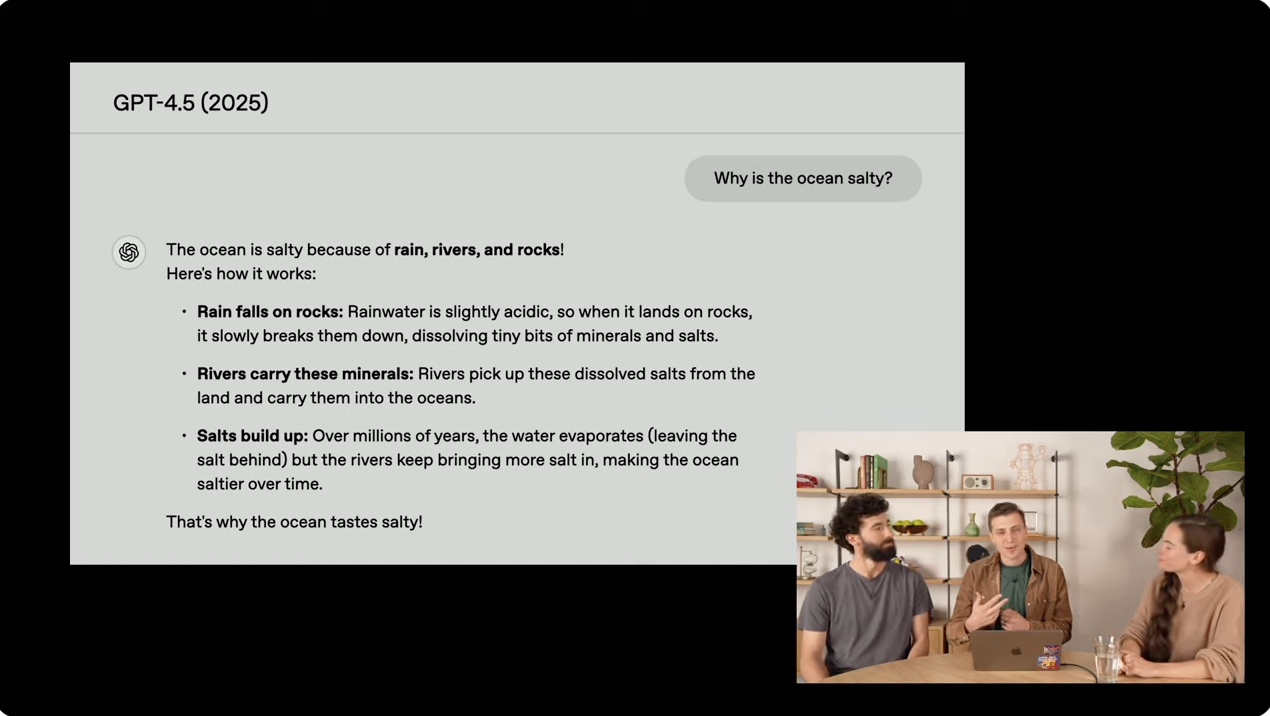
另一个演示则展示了 GPT-4.5 在解释复杂问题上的能力,「为什么海水是咸的?」
GPT-1 完全不知道答案,GPT-2 给出相关但错误的回答,GPT-3.5 Turbo 首次给出正确但解释不充分的答案,GPT-4 过于详尽列举事实,而 GPT-4.5 则提供了简洁、连贯且有趣的解释,开头使用了甚至使用了朗朗上口的句式。
据介绍,OpenAI 在开发 GPT-4.5 时实现了几项关键的训练机制创新。
训练如此大规模的模型需要显著提升后训练(post-training)基础设施,因为预训练阶段和后训练阶段的训练数据与参数大小比例完全不同。
团队开发了一种新的训练机制,能够使用更小的计算资源来微调如此大型的模型。
具体来说,他们通过多次迭代,结合了监督式微调(supervised fine-tuning)和基于人类反馈的强化学习(reinforcement learning with human feedback)来完成后训练过程,最终开发出了可以部署的模型。
在预训练方面,由 Alex 和 Jason 领导的团队采取了多项措施来最大化计算资源的利用:
使用低精度训练(low precision training)来充分利用 GPU 性能
跨多个数据中心同时预训练模型,因为他们需要的计算资源超过了单一高带宽网络架构所能提供的上限
此外,团队构建了新的推理系统,确保模型能在 ChatGPT 中快速响应用户,保持对话的流畅性。同时,他们表示将在发布后继续改进,使模型运行更快。
这些训练和部署机制的创新使团队能够将更多计算能力注入模型中,从而实现无监督学习的大规模扩展,这也是 GPT-4.5 能够在不依赖逐步推理的情况下,仍然展现出强大理解能力和较低幻觉率的关键原因。
值得一提的是,OpenAI 的首席研究官 Mark Chen 在 GPT-4.5 发布之前接受了 Alex Kantrowitz 的采访。
当被问到 OpenAI 是否在模型运行效率方面有所改进时,他表示:
让模型的运行更高效这一过程,通常与模型核心能力的开发相对独立。我看到很多工作都集中在推理(Inference)架构上。DeepSeek 在这方面做得很好,而我们也在这方面投入了大量精力。我们非常关注如何以更低的成本向所有用户提供这些模型服务,并一直在努力降低成本。
无论是 GPT-4 这样的推理模型,还是其他模型,我们始终在推动更低成本的推理优化。从 GPT-4 最初发布以来,运行成本已经降低了多个数量级,我们在这方面取得了不错的进展。
随后,当被问及当前的 Scaling Law 是否已经遇到瓶颈,或者是否观察到扩展带来的收益递减时,Mark Chen 回答道:
「我对 Scaling 有不同的理解。当涉及无监督学习时,你需要更多的关键要素,比如计算资源、算法优化以及更多的数据。而 GPT-4.5 确实证明了我们可以继续推进扩展范式,而且这种范式并不与推理能力相对立。
推理能力需要建立在知识的基础之上。一个模型不能凭空推理,而是需要先获取知识,再在此基础上发展推理能力。因此,我们认为这两种范式是相辅相成的,并且它们之间存在相互促进的反馈循环。」
实际上,GPT-4.5 不仅展示了无监督学习的巨大潜力,也预示着 AI 的发展方向——更像人。
过去,AI 的发展主要集中在提高智力,比如下棋、做题、识别图像等。而现在,与两年前 GPT-4 横空出世时引发的轰动不同,人们对 AI 的期待已经从两年前的「能做什么」转向当下「能做得更好、更安全、更可控」。
越来越多的 AI 公司开始关注「情商」,试图让 AI 更懂人类的情感和需求。
GPT-4.5 就是这一趋势的代表。投入资源,研发更懂人心的 AI 依旧是行业值得关注的命题。不过,GPT-4.5 虽然展示了基于海量数据和算力的语言模型所能达到的高度,但它的表现依然显得有些捉襟见肘。
从这个角度看,它或许更像画上了阶段性的句点,扮演了一个承上启下的过渡角色。既是对过去几代模型的总结与修补,也是在为下一波技术浪潮铺路。
真正的突破,可能还得等 GPT-5 来实现。
担心留给 OpenAI 的迭代时间不够,别急,我有一招,虚假的版本迭代是 GPT-4.5→GPT-5,在接下来的「数月内」,真实的发布节奏应该是 GPT-4.5→GPT-4.6→GPT-4.7→…
好消息是,这一次估摸着不用再等上两年了。


