

与英伟达一样,博通无疑也是AI时代的受益者之一。凭借2024财年创纪录的业绩表现,博通的市值成功迈入“万亿美元俱乐部”。
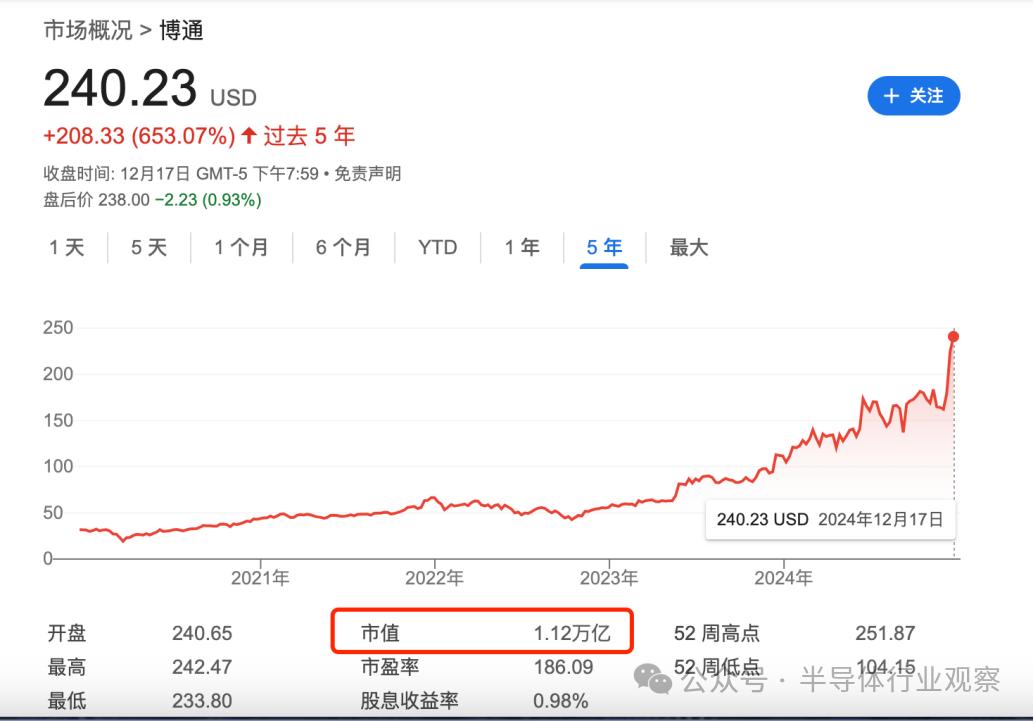
2024财年博通的净收入达516亿美元,毛利率高达76.5%,展现出强劲的盈利能力和运营效率。博通的两大核心业务——半导体技术与基础设施软件齐头并进,表现出色。其中,半导体业务营收创下301亿美元的历史新高;基础设施软件业务营收达到215亿美元,同比大涨196%。
然而,让博通真正成为市场焦点的,是其AI业务的惊人爆发力。在博通301亿美元的半导体业务中,AI收入高达122亿美元,同比增长高达220%。这不仅印证了AI带来的前所未有的市场红利,也使博通一跃成为AI时代最具分量的赢家之一。
虽然从大了说,博通就半导体和基础软件这两大业务,但是在这两大业务之下却包括26个细分类别,展现出极强的多元化与市场统治力。其中,就半导体业务来说,网络芯片与AI定制芯片是两大支柱,持续为博通贡献源源不断的增长动力。
重要的网络芯片
在高性能计算和AI时代,网络I/O已不再是幕后角色,而是决定系统性能的关键要素。
Meta早在2022年OCP全球峰会上便提出观点:“Network I/O is Key for Recommendation Workloads”(网络I/O对推荐工作负载至关重要)。如今,谷歌、微软等超大规模数据中心运营商纷纷投入巨资,部署英伟达GPU,构建万亿级AI集群。而在这一宏大布局中,作为全球最大的网络芯片制造商,博通的网络芯片是不可或缺的基础设施。
博通分析显示,当前网络连接在AI硅芯片中的占比大约为5%-10%,而在50万到100万个XPU组成的超大规模集群中,这一占比可能攀升至15%-20%。网络连接的高带宽与低延迟,是释放这些AI集群性能潜力的决定性因素。
在网络方面,博通凭借其强大的以太网产品线,为AI集群提供了两种系统架构及对应的芯片解决方案。
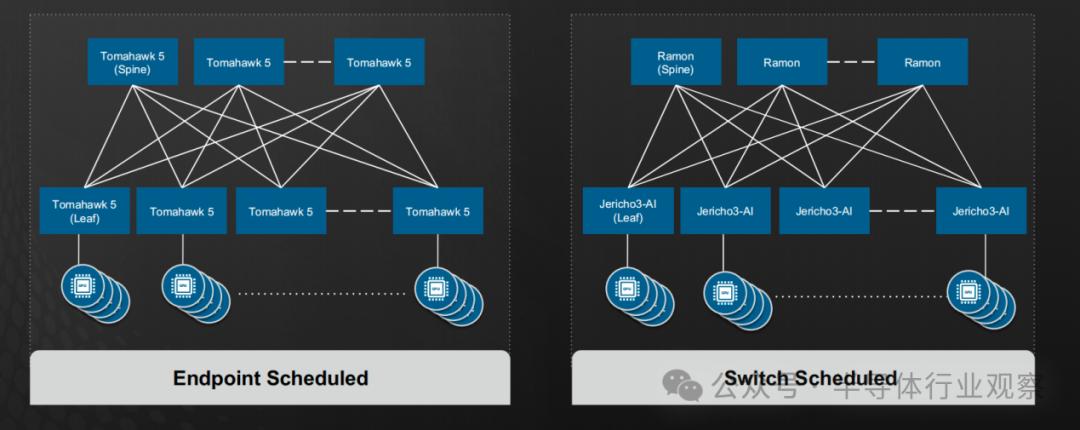
博通的两大以太网架构体系(图源:博通)
- 一类是Endpoint Scheduled系统架构,其主要面向的是小规模AI集群数据调度,各计算节点(如GPU)之间通过Tomahawk 5以太网交换芯片来进行互联。网络的重要性在博通的Tomahawk芯片身上体现的淋漓尽致,从2010年的640Gbps增长到2022年的51.2Tbps(如下图所示),Tomahawk实现了80倍带宽提升,并且实现了超过90%能耗降低。
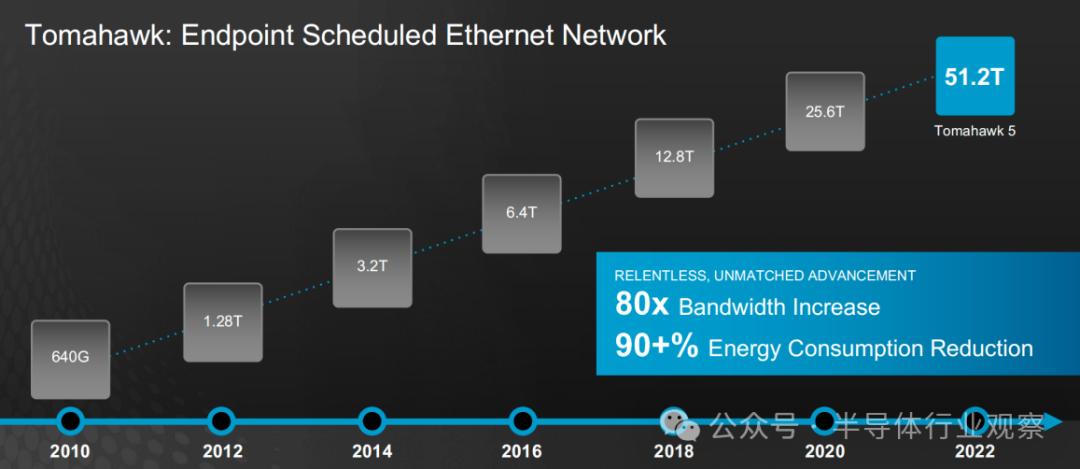
Tomahawk 5以太网交换芯片的演进(图源:博通)
- 另一个是对于大规模AI集群、需要由智能交换机负责数据调度的Switch Scheduled架构中,博通使用上层Spine交换机Ramon和下层Leaf交换机Jericho3-AI来实现多路径互联,其中Jericho3-AI也是用来连接各种AI加速器。在高性能计算和大型AI集群中,这种方法越来越受到青睐,因为它能够满足复杂网络环境下的高效通信需求。Jericho3-AI芯片可连接多达32,000个GPU,每个AI加速器能够提供800Gbps的数据带宽,最终能使网络性能提升10%。
除了以太网交换芯片,Thor系列网卡(NIC)也是支撑AI网络的一环,注意这不是英伟达的Thor。博通的Thor是一款专为AI优化的高性能网络接口卡(NIC)。博通制造NIC已有 20 多年,Thor 1 ASIC 于 2010 年初推出,采用台积电16nm工艺,用于插入PCI-Express 4.0服务器插槽的网络适配器。
今年博通又发布了第二代网卡芯片Thor 2,Thor 2是业界首款采用5nm CMOS工艺实现的400千兆以太网(GbE)NIC设备,支持16条PCI Express 5.0通道,每条通道的运行速度为32 Gbps。而且Thor 2还可以直接驱动长达5米的铜缆,而大多数 NIC 竞争对手只能驱动2.5米长的铜缆。Thor 2 芯片还支持 RoCE v2 RDMA,它类似于InfiniBand内置的 RDMA,但运行在以太网之上。与此同时,博通已开始研发 800 Gbps NIC 芯片Thor 3,再往后是1.6Tb。

单端口Thor 2 BCM957608-N1400G 适配器的外观
以太网交换机和网卡(NIC)是推动博通半导体业务增长的重要来源。博通是以太网的坚实拥护者,他们也加入了超级以太网联盟。
全球最大的AI定制芯片服务商
众所周知,博通是全球最大的AI定制芯片服务商,根据博通今年的财报会所述,其在175亿美元的TAM(可服务市场)中占到大约70%的份额,这一部分也是博通快速增长的业务,而且市场潜力巨大。
2014年,博通正式进军定制化AI加速器市场,推出了专为高性能计算设计的XPU(加速处理单元)。在过去十年里,博通与客户深度合作,研发了多代XPU加速器,并已计划在2025年下半年推出基于3nm工艺的下一代XPU,加速迈入高性能计算新纪元。
目前,尽管AI芯片在整体营业收入中的占比仍较小,但这一板块的迅猛增长已成为公司未来最重要的推动力。过去几年,博通来自定制化业务的营收逐年攀升:2019年博通的半导体解决方案中来自AI市场的业务占比5%,到2023年这一来源已经占到15%,而2024财年,博通设定的AI收入占半导体解决方案总收入的目标为35%。
博通的优势还在蔓延,因为AI计算需求呈指数级增长,受BLOOM、Cohere、GPT-4、LLaMA等AI模型的推动,博通预测,客户AI集群的规模将持续扩张:2022年集群规模为4K+ XPUs,2023年增长至10K+ XPUs,2024年预计达到30K+ XPUs。博通预测,到2027年,XPU集群规模有望达到100万个XPUs。
博通有三个大的客户(谷歌、Meta、亚马逊),他们在XPU领域开展多代战略合作。而且博通CEO Hock 还透露,博通已被选中与另外两家超大规模制造商合作,并且正在对其自己的下一代 AI XPU 进行深入开发。
博通CEO Hock Tan表示,随着三家现有的超大规模客户打算使用博通套件构建百万XPU集群,2027年博通的AI ASIC市场的机会将在600亿至900亿美元之间。他还透露,博通正在与另外两家超大规模企业讨论将使用其 IP 的定制加速器,这意味着未来还有更多大机遇。
博通能够在AI定制芯片市场中占据绝对优势,关键在于其在IP投资方面的前瞻性布局。早在XPU设计启动之前多年就对关键组件进行IP投资,截至目前,博通已经大约投资了30亿美元用于 XPU IP 的差异化和创新。博通拥有业界最广泛的IP组合之一,累计约21,000项专利,这其中包括SerDes IP、AI优化的NICs IP、缓存IP、CPO IP软件API等等。这些广泛的IP为其差异化的XPU提供了重要支持。
封装技术也是博通赢下XPU定制化业务的一部分原因,12月5日,博通推出其3.5D eXtreme Dimension 系统级封装 (XDSiP) 平台技术,3.5D XDSiP 在一个封装设备中集成了超过 6000 平方毫米的硅片和多达 12 个高带宽内存 (HBM) 堆栈,可实现大规模 AI 的高效、低功耗计算。与正面对背 (F2B) 方法相比,博通的 3.5D XDSiP 平台在互连密度和功率效率方面取得了显著的改进。这种创新的 F2F 堆叠直接连接顶部和底部芯片的顶部金属层,从而提供密集可靠的连接,同时将电气干扰降至最低,并具有出色的机械强度。
博通目前占据了AI定制芯片市场的绝对优势,随着AI芯片复杂度不断攀升,对计算、网络与内存的要求日益提高,新入局者的技术与成本壁垒将愈加严峻。目前,市场上唯一能够与博通竞争的玩家是Marvell,定制芯片市场正逐步形成博通与Marvell两强争霸的格局。
博通对AI市场持乐观态度,并明确表示将把半导体业务分为AI与非AI两大板块。凭借其领先的XPU技术、IP投资与封装工艺,博通正为AI市场的爆发式增长做好充分准备。
手握AI Server的“连接利器”:PCIe+Retimer
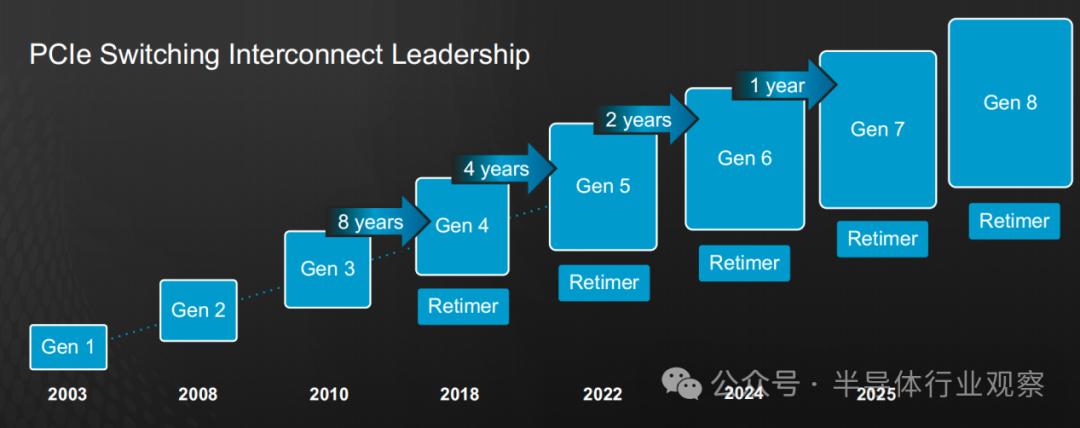
在当下主流的AI服务器配置中,PCIe+Retimer(重定时器)是当下实现高速互连的重要手段。如下图所示,一台15英寸标准AI服务器往往需要配备多个PCIe插槽和网络接口(NIC),用于连接不同组件。PCIe 是用于连接 CPU、AI 加速器、NIC 和存储设备的最关键且广泛采用的协议之一。PCIe Retimer用于延长PCIe信号传输距离并优化信号质量,确保长距离传输稳定。

通过PCIe连接的AI服务器(来源:Broadcomm)
而PCIe交换芯片和Retimer这两者也是博通的强项。自2003年推出第一代PCIe开始,目前博通已经累计出货了超过10亿个PCIe端口。至于Retimer技术是在2018年第四代PCIe开始引入,来解决长距离信号传输问题,而从博通的路线图来看,在后续的几代PCIe中一直到第八代,Retimer已经成为标配了。今年3月份,博通推出全球首款 5nm PCIe Gen 5.0/CXL2.0 和 PCIe Gen 6.0/CXL3.1重定时器。
布局未来互连技术:光互连
随着AI集群规模不断扩大,高速互联链路数量和带宽需求呈现指数级增长。这种增长带来了显著的功耗与成本挑战,光互联成为解决这一挑战的潜力技术之一。
其实在过去几十年里,博通在VCSEL(垂直腔面发射激光器)、EML(电吸收调制激光器)和高线性连续波 (CW) 激光器等光互联技术方面占据领先的地位。VCSEL和EML技术在实现AI和ML系统的高速互连方面发挥着至关重要的作用,他们分别用于短距离和长距离单模光通信,如今已经迭代发展到200Gbps速度。博通每年出货超过5000万个高速光通信激光器,所以这也是一块不小的业务。
在光互连领域,CPO(光电共封装)被视为未来AI网络的突破技术。博通在这一领域持续加大投入,并于今年3月推出了业界首款51.2Tbps CPO以太网交换机——Bailly。它集成了八个基于硅光子的 6.4-Tbps光学引擎和 Tomahawk 5交换机芯片,与可插拔收发器解决方案相比,Bailly使光学互连的运行功耗降低了70%,硅面积效率提高了8倍。下图展示了博通的51.2T TH5-Bailly CPO(共封装光学) 技术及其核心组成部分。博通正在与云服务提供商 (CSP) 和系统集成商共同设计平台,以加速CPO平台的采用。

另外,今年9月23日,博通宣布其5nm的Sian 2、每通道 200 Gbps (200G/通道) PAM-4 DSP PHY全面上市。Sian2具有200G/通道电气和光学接口,可增强支持100 Gbps 电气和 200Gbps 光学接口的Sian DSP。
无论是铜缆还是光互连,都很依赖SerDes(串并转换器)技术。博通已经开发了5纳米工艺的112 Gb/s SerDes技术,称为Peregrine。以及3nm的200Gb/s Condor SerDes。这些 SerDes接口不仅能够支持直接连接铜缆(DAC),而且原生支持CPO。此外,该SerDes技术可以跨多个Broadcom产品平台应用,包括:交换机(Switches)、XPU(处理器)、网卡(NICs)、数字信号处理器(DSPs)。
软件属性愈发强的博通
在博通516亿美元的营收中,基础设施软件收入增长至215亿美元,占比高达41.6%,高于2023财年的76亿美元。所以,某种意义上,博通也算是一个软件公司。说到软件,离不开对VMware的战略性收购,博通也将VMware变成了一台比其预想更为丰厚的赚钱机器。
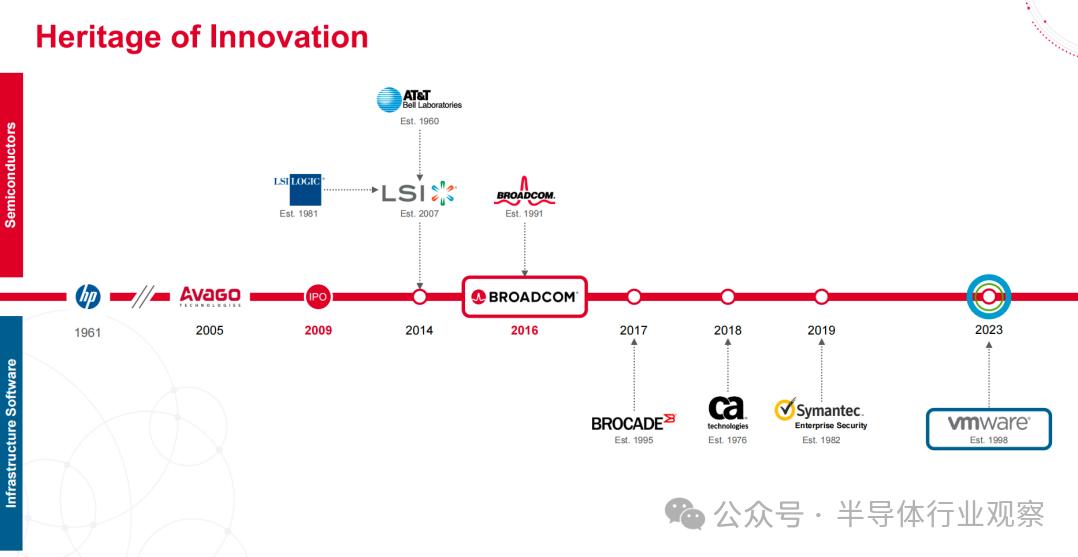
让我们再来回顾下博通悠久的历史渊源。如今的“博通”最早可以追溯到1961年惠普(HP)的根基,博通的现代发展始于2005年Avago Technologies(安华高)的成立,Avago于2009年成功完成IPO。2014年,Avago通过收购LSI Logic等公司扩展了技术版图。2016年,Avago收购Broadcom,并统一品牌为Broadcom。随后,Broadcom继续实施一系列关键并购,包括2017年收购Brocade,2018年收购CA Technologies,2019年收购Symantec企业安全部门,以及2023年收购软件巨头VMware。通过这些并购,Broadcom在半导体技术和基础设施软件市场构建了强大的竞争力。
结语
博通的成功并非偶然。在AI热潮席卷全球的背景下,计算需求呈现出爆炸式增长,推动了高性能芯片与网络架构的迭代升级。一面是高速发展的AI定制芯片业务,一面是高效协同的网络与软件生态,还有PCIe交换机、光学、SerDes、DSP等各种强大的互连技术,博通以强大的“护城河”提供全面的AI解决方案,正在引领AI时代的下一轮增长浪潮。
从网络连接到AI算力,从半导体硬件到软件基础设施,博通的每一块拼图都恰到好处。如今,它不仅是半导体行业的佼佼者,更成为AI时代不可或缺的基石之一。
站在万亿美元的高地上,博通不仅坐拥AI时代的红利,更正在引领半导体行业的未来。


