

凤凰网科技讯 2月11日,无问芯穹宣布获七家国产芯片鼎力支持,正打通DeepSeek-R1、V3在壁仞、海光、摩尔线程、沐曦、昇腾、燧原、天数智芯等七个硬件平台的多芯片适配优化,现开发者已可以通过Infini-AI异构云平台一键获取DeepSeek系列模型与多元异构国产算力服务。
自春节前夕爆火,DeepSeek已牵动了国内超30家云服务商与近20家芯片企业宣布接入,到目前为止,这场热闹还只是一场由DeepSeek引发的流量蛋糕切分大战。而随着无问芯穹宣布获7家国产芯片鼎力支持,并带着多芯片适配的DeepSeek-R1入场,DeepSeek为可控国产算力撬动的历史机遇,正在变得更加清晰。
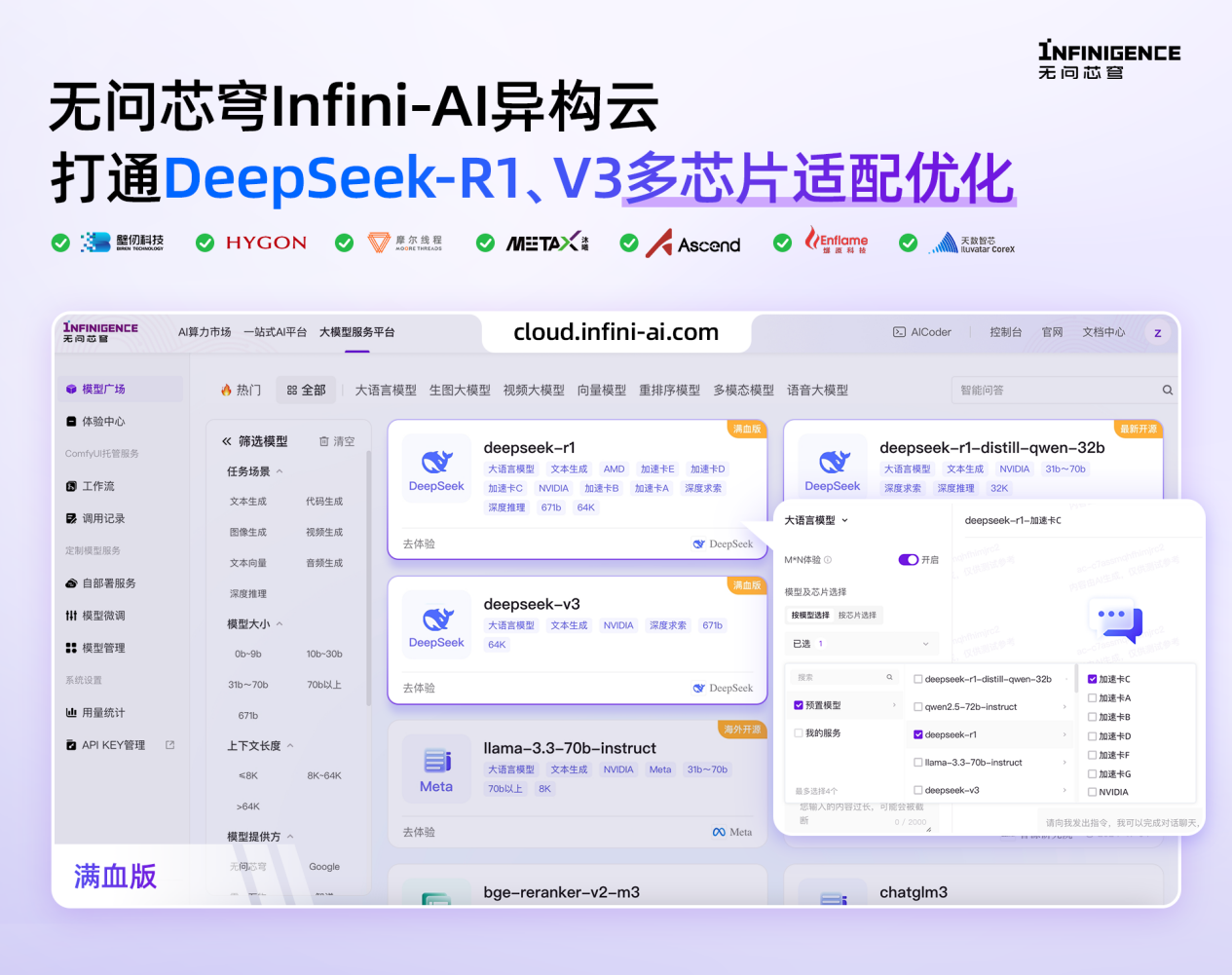
获取无问芯穹异构云多芯片适配版DeepSeek-R1请点击链接:https://cloud.infini-ai.com/genstudio?source=U7Z9
国产的大部分模型是通过国际主流芯片(如英伟达)训练得到,尚未与国内的AI系统、芯片形成闭环生态。无问芯穹联合创始人、CEO夏立雪表示, DeepSeek的突破激发了越来越多的下游应用创造力,未来行业日均tokens消耗量将达到百万亿级别,不仅将激发国产芯片的市场需求,也为打造全国产AI产业闭环,实现更可控的自主算力发展创造了有力条件。
在美国,模型、系统、芯片已经形成闭环生态。以英伟达为例,其GPU的主流地位与CUDA生态有直接关系,CUDA的护城河是软件堆栈,可以让研究人员和软件开发者更好地在GPU上编程和构建各种各样的应用,牵引下一代芯片的迭代方向。但是随着Transformer统一模型结构,大模型应用落地场景所需的算子数量大幅度收缩,CUDA护城河正在变薄。
“DeepSeek作为开源模型,其之于AI 2.0时代,正如Android之于移动互联网革命,将重构整个产业生态,引发链式反应,加快上层应用发展和下层系统‘统一’增速,由此广泛调动起跨越软硬件和上下游的生态,一起加大投入‘模型-芯片-系统’协同优化和垂直打通,从而继续‘打薄CUDA生态’。某种程度上来说,CUDA已经是历史了”。夏立雪举例,这类协同优化工作包括根据新一代模型架构来定义未来芯片的底层电路实现,以及根据国产AI系统的互联通信方式来设计高效的混合专家模型结构等。
对此,无问芯穹提出了“三步走”模式来促进全国产AI产业闭环的打通——基于主流芯片开展极致软硬件协同优化,以有限算力实现国产模型能力追赶;推动国产芯片开放底层生态,搭建“异构”AI系统解决算力缺口,实现模型能力赶超;构建国产“同构”系统,支持Scaling Law持续发展,打造“国产模型-国产芯片-国产系统”的全国产AI产业闭环,实现更可控的自主算力发展。
与此同时,针对国内源分布不均衡,技术和应用场景不匹配,导致的大量异构算力未能全量利用问题,无问芯穹也将通过整合异构、异地、异属算力资源,转化为标准算力服务并规模化复制,并紧密跟踪下游应用需求,提升算力配置效率。这不仅能解决部分地区存在的算力闲置问题,满足日益增长的应用需求,还能在使用闭环中,促成硬件与算法正向循环。
夏立雪表示,通过打通DeepSeek-R1、V3在国产硬件平台的多芯片适配优化,无问芯穹希望进一步团结从模型到芯片的上下游产业伙伴,在打造“国产模型+国产算力+国产系统+国产应用”全国产化AI产业链的进程中起到牵引带动作用,集中优势资源,支持模型性能长足进步,推动中国AI自主可控长远发展,为人工智能行业发展筑牢算力基础。
在DeepSeek模型迄今发布的3个大版本中,尽管参数规模实现十倍增长,但所使用的训练服务算力却并没有和模型尺寸等比例的成倍增加,其核心是利用软硬件协同设计的思想,不断提升系统开销(即模型的训练成本)到模型尺寸、能力的转化率。DeepSeek有力验证了在算力受限的条件下,软硬协同优化路线的有效性,特别在国内算力受限场景下实现模型能力的突破,具有重要意义。
就在近日,国际最权威的科技商业媒体之一《麻省理工科技评论》刊发了一篇题为《关注DeepSeek之外的四家中国人工智能初创公司》的报道,指出阶跃星辰、面壁智能、智谱AI、无问芯穹四家企业同样展现出不逊于DeepSeek的技术实力与全球竞争力。

有业内人士指出,结合这四家被点名企业的特征分析来看,DeepSeek可能正在让国际意识到,除了DeepSeek之外,中国还存在若干路径独特的团队,在用“力大砖飞”堆叠GPU算力储备、比拼模型精度的巨头竞赛之外,找到未被五角大楼战略家们关注到的“blind spot( 盲点) ”,跨越软硬件,攒动上下游,走出可能出奇制胜的技术路径。


