

率先迈入2.0时代。
“AI下半场要来了。”
12月初,深港创业基地的一间大会议室里,成一鹏缓缓聊起自己的看法。回想一年前,正是基于这一判断,他在深圳汇聚一个AI创业团队——新旦智能由此成立。
这位前腾讯AI员工,有着近10年的互联网SaaS和AI从业经历。与多数大模型公司不同的是,成一鹏和团队早早就意识到“粗放式算力的不可持续性”,转而借助算法和架构的深究进入到AI的下一个阶段: 复杂智能体架构。他将未来的AI行业称为“后算力时代”,对应此前走过的AI 1.0时期,AI原生应用将会在下一个阶段爆发。
眼前,中国AI行业或许走到十字路口。千千万万位创业者汇聚而来,他们身处其中,悄然改变着潮水的方向。
一位腾讯前员工,投身AI创业
时间回到2016年,AlphaGo大战围棋圣手李世石,成为人工智能史上的分水岭。这一幕带给当时一批年轻人极大震撼,其中就包括成一鹏。
从小在深圳长大,成一鹏很早就接触到一些前沿科技话题。目睹AI浪潮在国内兴起,他决定全力投入AI领域。彼时,腾讯云正在组建AI团队,成一鹏顺利加入,成为最早一批AI核心员工。
此后6年时间里,成一鹏参与过不少大规模互联网AI项目,期间还负责一个保密核心专利的开发。在他的分享中,这是全球最早运用Transformer构建大规模AI调度算法的案例之一,成一鹏也是大规模云操作系统的AI核心算法专利第一发明人。
此后,国内AI行业陷入一段沉寂期。成一鹏离开腾讯,转身加入一家SaaS独角兽公司。正是这两段经历,让他亲身参与了一个团队从1到100的成长过程。
2022年6月,OpenAI发布第一款商业产品——GPT-3,此时距离ChatGPT正式发布还有5个月,这款产品仅在AI技术圈被小范围关注,成一鹏再次看到了机会。
“当你一个人在山洞里太久,很微小的一束光照进来都会非常敏感。我看到了这束光。”

意识到这件事能干,成一鹏决定辞职All in AI,并在第一时间内加入全球开源的AI社区。那段时间里,他几乎“泡在”社群里,一度在数据、模型、算法、训练系统等各项工作上进行深度参与,逐渐摸清思路。
官网显示,这是一支来自清华、伯克利、腾讯、Meta等知名学术与工程界团队。同年10月份,新旦团队发布首个MT-Bench 全球榜单TOP3的高性能小模型xDAN-L1-RL;今年4月后再推出全球首款高性能千亿MoE架构模型xDAN-L3,据其提交的Arean-Hard全球榜单显示做到了TOP4(2024.06)并成功实现落地到消费级显卡上运行。
这段时间正值国内外AI创业公司井喷式出现、并快速融资。新旦智能首轮投资人、志合基金创始人周弘扬回忆起当时的紧迫性:“对于几家头部大模型创业公司来说,那段时间错过融资就意味着节奏过去了,对于投资人亦是如此。”
公开资料显示,周弘扬曾担任摩根士丹利亚洲执行董事、大摩人民币PE基金投委及深圳负责人;此前在深创投、深高新投任职,后创立志合基金,一直活跃在深圳创投一线。周弘扬回忆,他与成一鹏均为“深二代”且相识已久,于是在尽调后迅速投出了第一笔钱,这也是志合基金成立以来其投资并深度参与的第一个项目。
随后,新旦引入了全球化人工智能企业APUS(麒麟合盛)的投资,2024年3月份,新旦智能宣布完成天使轮融资。
APUS董事长兼CEO李涛表示,此次投资首先是看中技术与市场契合度,其次是产业协同效应。“一方面,拥有独特的技术或解决方案,能够解决特定行业的痛点或提供创新的服务是吸引APUS的重要因素;另一方面,双方能够形成互补优势,共同探索新的商业模式和服务形态。”
不久后,APUS联合新旦智能训练的大模型APUS-xDAN 大模型4.0(MoE)正式开源。据APUS介绍,这是目前国内参数规模最大的开源模型之一,也是首个支持在4090低端算力上训练千亿参数开源大模型。
经历了一系列探索和行业内卷,成一鹏发现,只做大模型或许并不是一个很好的商业形态——AI下半场来了。
AI下半场:算力还代表一切吗?
我们来想象一个游戏场景:在新手村单体pk界面,有人拿了把木剑、有人刚穿上衣服、有人脑子灵活……正当他们准备各显神通时,后面出现了一个四五人的小团伙。
——成一鹏以此来描述新旦智能基于xDAN Agent OS操作系统上构建的核心产品MindSpace。
这是一款突破性的动态多智能体协同操作系统。MindSpace能够根据问题的复杂度和专业领域,自动构建和协调多个专业化智能体专家团队。不同于ChatGPT等L1级别的单一模型架构,MindSpace作为L3级别的协同智能体系统,具备:
- 动态智能体生成:根据问题自动组建最优专家团队
- 深度交互能力:通过多轮对话深入探索问题本质
- 混合知识架构:结合私有化高精度多模态知识库和全球在线AI搜索
- 集体智慧整合:多个专业智能体协同决策
- 系统化输出:生成深度的体系化解决方案
(动态智能体编排 & 群体智慧协同)
(深度推理分析 & 全球智能搜索)

(系统性方案 & 万字深度报告)
成一鹏打个比方:如果GPT系列是一个博古通今的智者在与你对话,那么MindSpace就致力于汇集多个不同领域的专家给出答案,最终由一个拥有全局视角的指挥者汇总输出,这就是游戏中的“团战”。
他认为,这更接近真正意义上的人工智能。由此提出了AI发展的五大阶段——
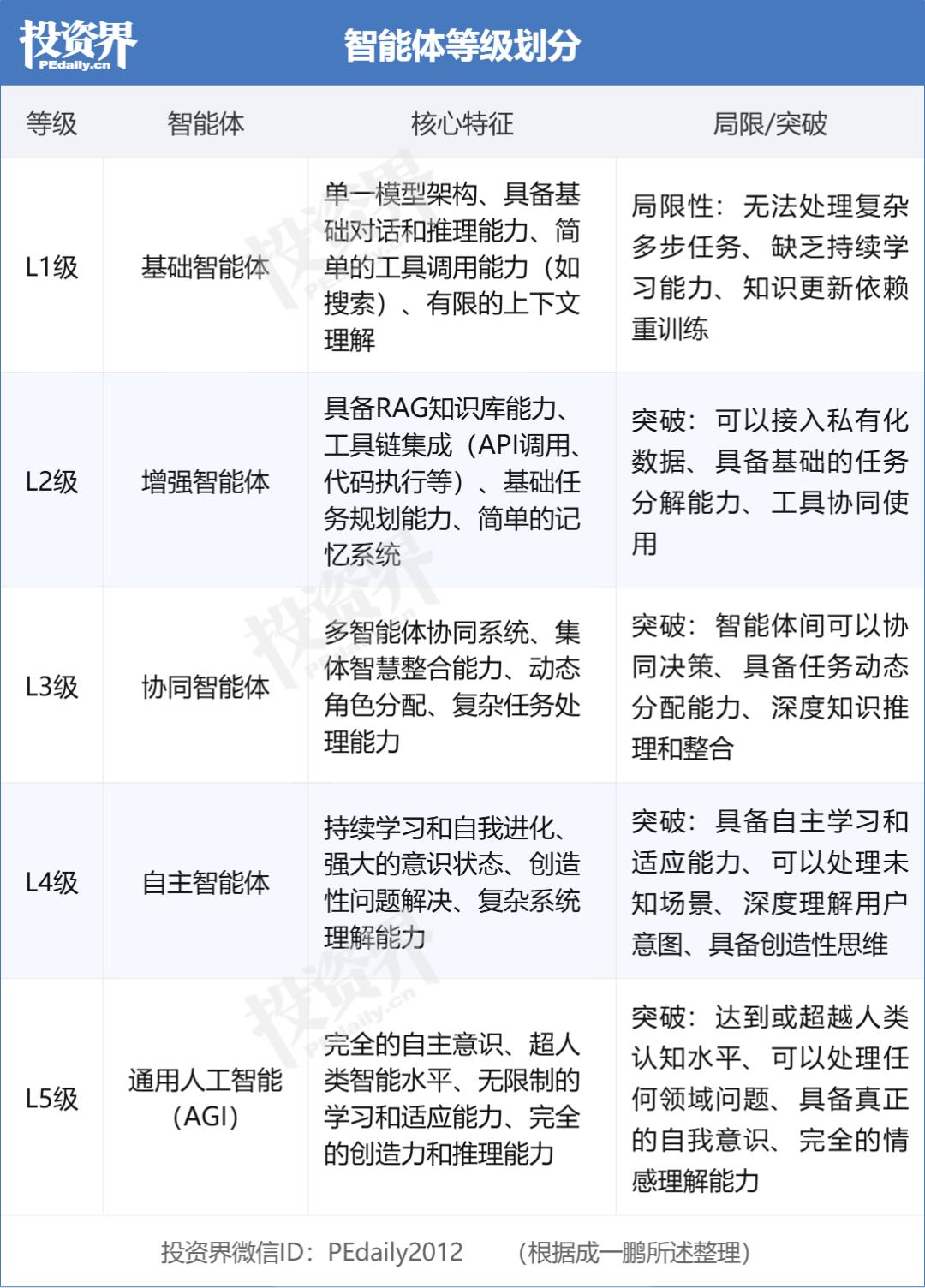
在他的划分中,L1阶段是GPT-4为代表的第一代大语言模型——“一种智慧的马达”,这一级别的模型更多是一种被动的直觉模型,因此国内大模型价格战本质也是一种同质化竞争的结果。
而MindSpace正在向着L3阶段进发,“模型是个马达,但是人类需要是汽车。”成一鹏解释称,“新旦选择了一条差异化的赛道,当别人还在谈论模型大小的时候,团队已经在思考如何让AI真正地思考,进化为真正的智能协作系统。”
这在一定程度上避开业界讨论最多的算力问题。成一鹏团队认为,模型的思维可以被精密加工、雕刻,形成一个高性能模型,而非完全依靠海量算力来支撑,就如同一个人的成长并不是饭喂得越多越好,而是对这个人思维上的教育。
“最初,我们都以为拥有GPU就拥有了一切。但随着行业发展,我们逐渐认识到,单纯的算力竞赛并非制胜关键。”
在团队看来,后算力时代的竞争优势更多来自算法的精进和数据工程能力的突破。通过创新思维工程方法,团队将千亿参数模型压缩到消费级显卡上运行,意味着AI正在从粗放式发展转向精细化进化。MindSpace由此诞生。
根据提问,MindSpace能够输出一份超过10000字的长篇报告,生成大约15分钟,而一份相对完整的报告可能要花2到3个月完成。“虽然现在的报告看起来像我们刚入行时60分的水平,但未来将不断迭代到80分、90分,到那时候AI智慧咨询的供给就像喝水一样简单。”
关于商业化情况,新旦团队表示,目前产品已经在法律和政务方向落地,并有了初步意向客户。随着进一步迭代,MindSpace还将向金融、咨询等专业性领域拓展。
“大多数人还在关注L1阶段的算力竞赛,我们选择了一条通往‘后算力时代’的路,技术的演进总是比想象更快,但方向比速度更重要。”成一鹏说。
打响AI产业战,一半海水,一半火焰
新旦智能坐落在深圳市南山区桃源街道的创业基地,这里位于深圳大学城,周边有着源源不断的高校和人才资源。提及深圳创业感受,成一鹏直言:“这是一座崇尚创新和变化城市。”
正如一位创业者也提到,相比之下深圳对AI创业者的包容性更强,不看出身、不论背景,不会被包袱拖累,有着极大的灵活度。而接触下来,周弘扬印象最深一点就是与政府沟通的顺畅性,“创业者想去见领导敲门就能进,不需要繁琐的关系。”
如今,深圳正在打响一场AI战役。2023年5月,深圳市印发《深圳市加快推动人工智能高质量发展高水平应用行动方案(2023-2024年)》,两个月后《深圳市加快打造人工智能先锋城市行动方案》出台。
其中,前者提出统筹整合基金资源,形成规模1000亿元的人工智能基金群,从强化智能算力集群供给、增强关键核心技术与产品创新能力、打造全域全时场景应用等各方面加大支持力度;后者则直接公布22条举措,提出打造全身、全车、全屋“三全智能”产品矩阵。
就在不久前,《深圳市打造人工智能先锋城市的若干措施》正式发布,从发放“训力券”、 “语料券”、 “模型券”等资助,到设立人工智能产业基金等18条措施,深圳砸下真金白银,每年投入最高1亿元。
而在2024年初出台的深圳“20+8”产业集群2.0版本中,人工智能升格为“20+8”集群中的独立集群,并作为战略重点类集群进行全市布局。
如此种种,也是全国争抢人工智能产业的一缕缩影。
纵观其他城市,北京先依托清华系聚集了一批人工智能顶尖人才,接着开始推动“人工智能+”行动计划;上海同样政策频出,先推出规模225亿元的人工智能母基金,后再发布100亿人工智能生态基金;合肥、成都、武汉、杭州、广州等城市纷纷开始布局,所有人都想抓住这个产业机会。
目之所及,AI融资席卷一级市场。年度最大融资、最快独角兽几乎都出现在这一领域。然而繁荣之下,隐忧难掩。一位AI投资人曾这样形容过当下的AI行业——他们正在重走20年前互联网时代的路,或许2000年前后那场泡沫就要来了。
对此,成一鹏并不担心:“现在还是一个非共识时代。没有人真正看到理论的尽头,也没有人能预测AI的终点。”
回到2023年前半年,这是成一鹏第二次做出奔向AI的决定。几乎同一时间,一大批沉寂已久的创业者重新看到了未来,“大模型六虎”中就有至少4家在此时成立。提及当时的创业初衷,这位理工男的答案带着些许浪漫——
“大航海时代来了,每个人都会撑起岸边的船出海,我也想撑起自己的船。”


