

划重点
① OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。
② 开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。
③ 智能体受到关注,开发者在构建大语言模型应用时,更加倾向于采用多步骤智能体来增加应用的复杂性。

12月20日,美国人工智能公司LangChain日前发布了《2024年人工智能全景报告》(State of AI Report 2024)。自2018年开始,LangChain团队已连续七年发布当年的《人工智能全景报告》,成为人工智能行业流行的风向标。在今年的报告中,通过深入探究大模型应用开发平台LangSmith产品的使用模式,LangChain团队揭示出人工智能生态系统以及人们构建大型语言模型应用的方式是如何演变的。
LangChain团队在报告中指出,随着用户在LangSmith中进行追踪、评估和迭代,他们观察到了几个显著的变化,其中包括开源模型采用率的急剧上升,以及从以检索工作流程为主转向具有多步骤、代理性工作流程的智能体应用。
LangChain团队通过深入研究以下统计数据,整理出开发者正在构建、测试和优先考虑的内容。
大语言模型使用分析
在全球范围内,大语言模型正迅速普及,这也引发了一个普遍的疑问,类似于童话中王后对魔镜提出的问题:“在所有模型中,哪一个是最常被使用的?”LangChain团队通过深入分析收集的数据,揭示出这一问题的答案。
(一)大语言模型顶级供应商:
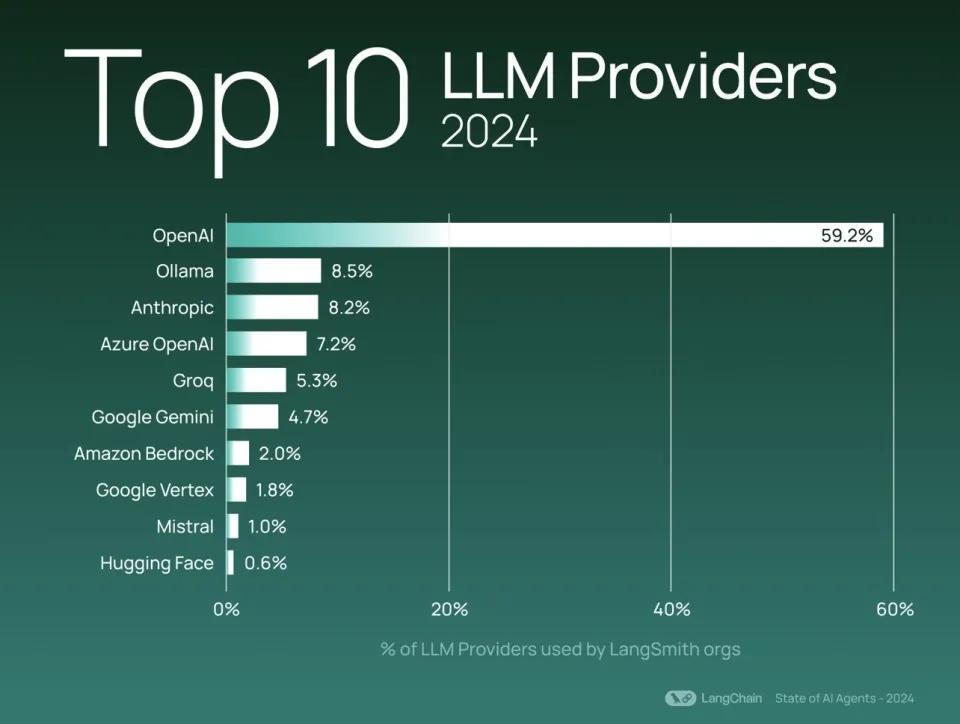
注:2024年十大语言模型供应商排名
如同前一年的数据所示,OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。

注:2024年十大大语言模型供应商排名
特别引人注意的是,Ollama和Groq(这两家公司都支持用户运行开源模型,Ollama侧重于本地执行,而Groq则专注于云端部署)在今年的增长势头迅猛,成功跻身行业前五。这一趋势反映了市场对于更加灵活的部署选择和个性化人工智能基础设施的日益增长的需求。
在开源模型供应商方面,与去年相比,顶级供应商的排名相对稳定——Ollama、Mistral和Hugging Face等公司为开发者提供了便捷的平台,以便他们能够轻松地运行开源模型。这些开源软件供应商的合计使用量占据了前20名大语言模型供应商中的20%。
(二)顶级向量检索/存储系统:

注:2024年十大顶级向量检索/存储系统排名
在众多生成式人工智能(GenAI)的工作流程中,执行高效的检索操作依然扮演着关键角色。今年的顶级向量存储系统排名与去年相比保持稳定,Chroma和FAISS继续占据最受欢迎的前两位。此外,Milvus、MongoDB和Elastic的向量数据库也在今年成功跻身前十,这反映出业界对于灵活部署选项和可定制化人工智能基础设施的兴趣日益增长。
使用LangChain产品构建应用

注:组织如何使用LangSmith构建应用
随着开发者对生成式人工智能的运用经验日益丰富,他们正在构建更多动态的应用。从工作流程的日益复杂化,到人工智能智能体(AI agents)的兴起--LangChain观察到几个趋势,这些趋势指向了一个不断创新发展的生态系统。
(一)可观测性不仅限于LangChain应用程序
开源框架LangChain虽然是众多开发者构建大语言模型应用的首选,但根据LangSmith今年的追踪数据,有15.7%的追踪来自非LangChain框架。这一现象揭示了一个更广泛的趋势:无论使用哪种框架来构建大语言模型应用,对可观测性的需求都是普遍存在的。LangSmith通过支持不同框架间的互操作性,满足了这一需求。
(二)Python继续占据主导地位,JavaScript使用率稳步上升
在调试、测试和监控领域,Python SDK深受Python开发者的青睐,占据了84.7%的使用率。与此同时,随着开发者越来越多地投身于Web优先的应用开发,JavaScript的使用兴趣也在显著提升。今年,JavaScript SDK在LangSmith中的使用比例达到了15.3%,与去年相比增长了三倍。
(三)智能体正逐渐受到关注
随着企业越来越重视在各个行业中整合智能体,我们可控的智能体框架LangGraph的采用率也在上升。自2024年3月发布以来,LangGraph的受欢迎程度稳步增长——现在有43%的使用LangSmith平台的组织正在发送LangGraph追踪数据。这些追踪数据代表了复杂、协调的任务,超越了基本的大语言模型互动。
这一增长与智能体行为的增加相一致。LangChain团队发现,平均有21.9%的追踪现在涉及工具调用,而2023年的平均值仅为0.5%。工具调用允许模型自主调用函数或外部资源,标志着更多的智能体行为,即模型决定何时采取行动。增加工具调用的使用可以增强智能体与外部系统交互的能力,并执行如写入数据库等任务。
性能与优化
在应用程序开发领域,尤其是在利用大语言模型资源的应用中,实现速度与复杂性的平衡是一个核心挑战。LangChain团队分析了组织如何与他们的应用程序互动,确保其需求的复杂性与性能效率相匹配。
(一)复杂性的提升并未影响任务处理的效率
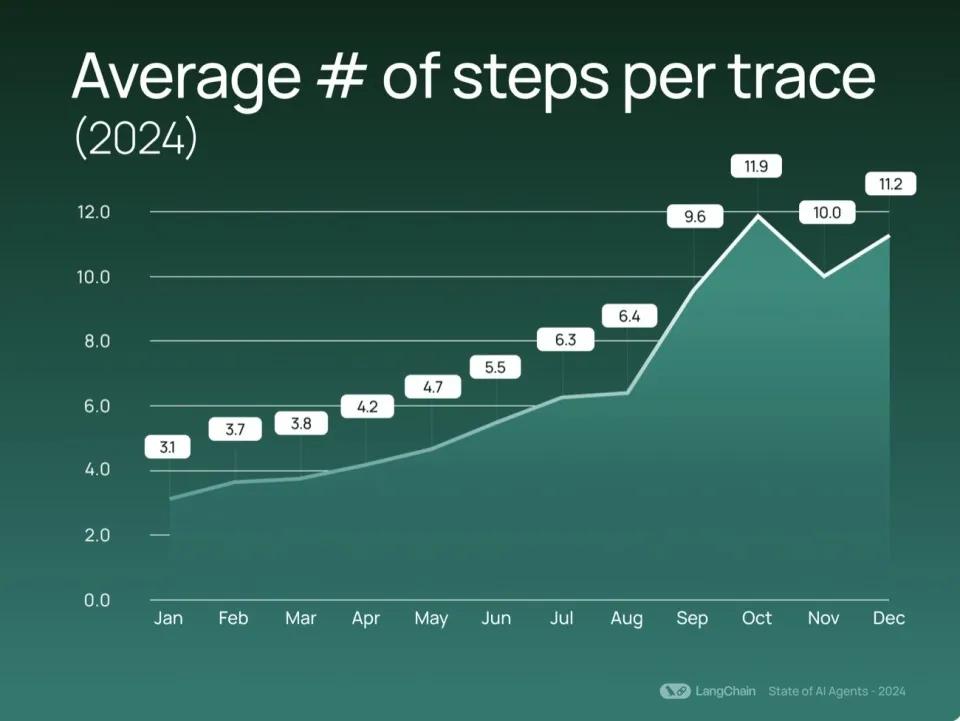
注:LangChain团队观察到每个追踪的平均步骤数有了显著的增长
在过去的一年里,LangChain团队观察到每个追踪的平均步骤数有了显著的增长,从2023年的2.8步上升至2024年的7.7步。LangChain团队将这些步骤定义为追踪中的独立操作,包括对大语言模型、检索器或工具的调用。这一增长趋势揭示了组织正在采用更加复杂和多维的工作流程。用户所构建的系统已经超越了简单的问答交互,转而将多个任务串联起来,如信息检索、信息处理以及产出可执行的结果。
与此同时,每个追踪中大语言模型的平均调用次数增长较为温和--从1.1次增至1.4次。这表明开发者在设计系统时,正努力在减少大语言模型调用次数的同时,实现更多的功能,既维持了系统的功能性,又有效控制了成本较高的大语言模型请求。
大语言模型测试与评估

注:顶级评估数据排名
面对如何确保大语言模型应用不产生不准确或低质量响应的挑战,组织采取了哪些措施?虽然维持大语言模型应用的高标准质量是一项艰巨任务,但调查发现组织正利用LangSmith的评估工具来自动化测试流程,并构建用户反馈机制,以开发出更加稳健和可靠的应用程序。
通过LangSmith的评估功能,组织能够自动执行测试,并收集用户反馈,确保大语言模型应用输出的质量。这不仅包括对大语言模型生成响应的准确性和质量进行测试,还涉及根据用户反馈不断调整和优化应用性能。这样的做法使得组织能够在应对复杂需求的同时,确保大语言模型应用的性能保持高效。
(一)大语言模型作为评审员:关键要素评估
使用大语言模型作为评审员的评估工具将评分准则整合进大语言模型的提示中,并通过大语言模型来评定输出结果是否满足特定的评估标准。LangChain团队观察到开发者在测试中最为关注以下几个特性:相关性、正确性、精确匹配以及有用性。这些特性强调出大多数开发者正在进行初步的响应质量检验,以确保人工智能生成的内容不会严重偏离预期目标。
(二)利用人类反馈进行迭代
在构建大语言模型应用的过程中,人类反馈扮演着至关重要的角色。LangSmith通过加速收集和整合人类反馈至追踪和执行过程中(即执行跨度),帮助用户构建出更丰富的数据集,以便于改进和优化应用。在过去一年里,标注的执行次数增长了18倍,这一增长与LangSmith使用量的增加成正比。
尽管每次执行的反馈数量从2.28条上升到2.59条,显示出轻微的增长,但相对于每次执行来说,反馈量仍然较少。这可能意味着用户在审查执行时更倾向于追求速度,而不是提供详尽的反馈,或者他们可能只针对那些最关键或存在问题的执行提供评论。
结 论
在2024年,开发者在构建大语言模型应用时,更加倾向于采用多步骤智能体来增加应用的复杂性;他们通过减少大语言模型的调用次数来提升效率,并引入质量检查机制,通过反馈和评估方法来确保输出结果的质量。随着大语言模型应用的不断增多,我们期待看到开发者如何进一步探索更智能的工作流程、提升性能表现以及增强应用的可靠性。


