


作者 | ZeR0 程茜
编辑 | 漠影
智东西12月21日报道,今日,OpenAI“连续12日圣诞发布”终于迎来激动人心的大结局,OpenAI推出重磅收官新品,其迄今最强前沿推理模型的升级版——o3。
OpenAI号称o3在一些条件下接近通用人工智能(AGI)。
OpenAI CEO Sam Altman在直播中说:“我们认为这是AI下一阶段的开始。你可以使用这些模型来完成越来越复杂、需要大量推理的任务。”他还夸赞o3在编程方面的表现令人难以置信。
今年9月发布的OpenAI o1模型拉开了推理模型的闸门,随后许多国内外大模型企业相继推出大量推理模型。出于对英国电信运营商O2的尊重,OpenAI把o1的继任者命名为o3。
和前代o1模型一样,o3通过思维链进行思考,逐步解释其逻辑推理过程,总结出它认为最准确的答案。
o3有完整版和mini版,新功能是可将模型推理时间设置为低、中、高,模型思考时间越高,效果越好。mini版更精简,针对特定任务进行了微调,将在1月底推出,之后不久推出o3完整版。

ARC-AGI是一项旨在评估AI系统推理首次遇到的极其困难的数学和逻辑问题能力的基准测试,由Keras之父François Chollet发起。在ARC-AGI测试中,o3在高推理能力设置下取得了87.5%的分数,在低推理能力设置下的分数也高达o1的3倍。
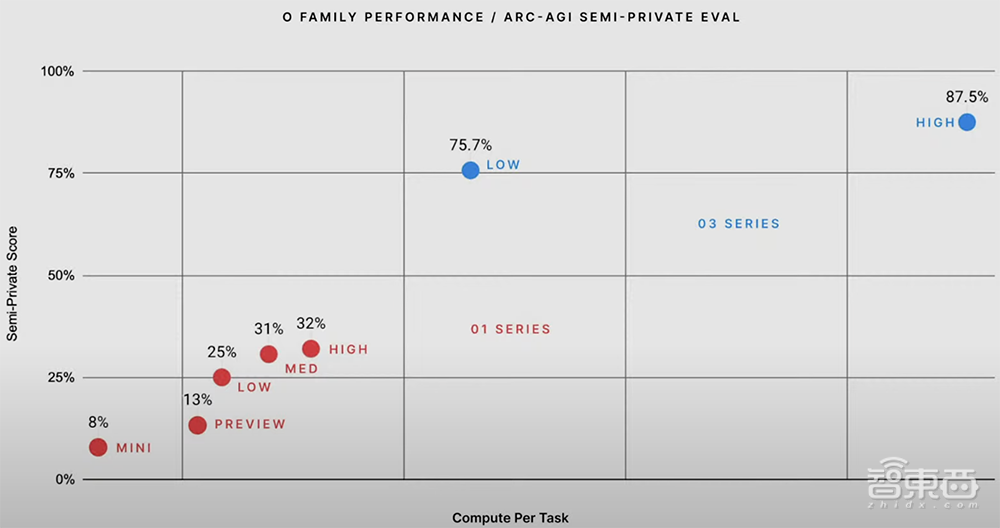
这一成绩令社交平台一片雀跃,认为AI技术发展非但不见放缓,反而展示出比预期更快的通往AGI的速度。
要知道,之前GPT-3的评测结果为0%,GPT-4o为5%,而o3一举将成绩提升到87.5%,令人瞠目。与之前的大模型相比,o3能适应以前从未遇到过的任务,可以说接近人类水平的性能。
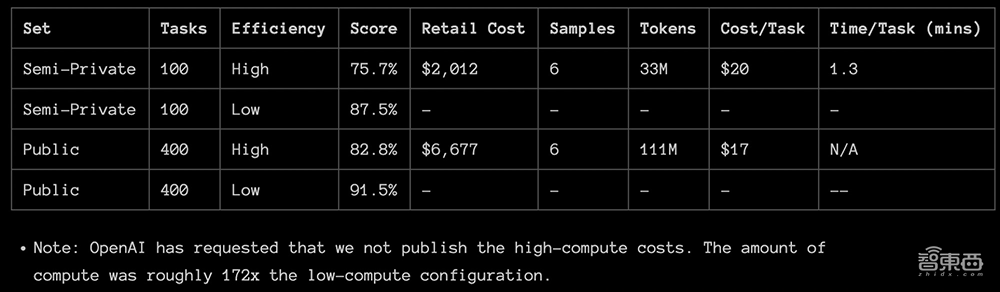
François Chollet发布了o3的完整测试报告。o3在两个ARC-AGI数据集中进行了测试,并在两个具有可变样本量的计算级别上进行了测试:6(高效率)和1024(低效率,172倍计算)。其中,75.7%的高效率分数在ARC-AGI-Pub的预算规则范围内(成本<10000美元),87.5%的低效率分数成本则相当昂贵,但仍然表明新任务的性能确实会随着计算量的增加而提高。
测试报告指路:https://arcprize.org/blog/oai-o3-pub-breakthrough
目前o3还不是很经济。用户能够以每项任务大约5美元(折合人民币约36元)的价格来支付人工解决ARC-AGI任务,只消耗几美分的能源。而在低推理模式下,o3完成每个任务需要花费17-20美元(折合人民币约124~145元)。
OpenAI明年将与ARC-AGI背后的基金会合作构建其下一个基准测试。
其他基准测试中,o3亦有远胜竞品的表现。
在由真实世界软件任务组成的SWE-Bench Verified基准测试中,o3模型的准确率约为71.7%,比o1模型高出20%以上。OpenAI研究高级副总裁Mark Chen说:“这确实意味着我们正在攀登实用性的前沿。”
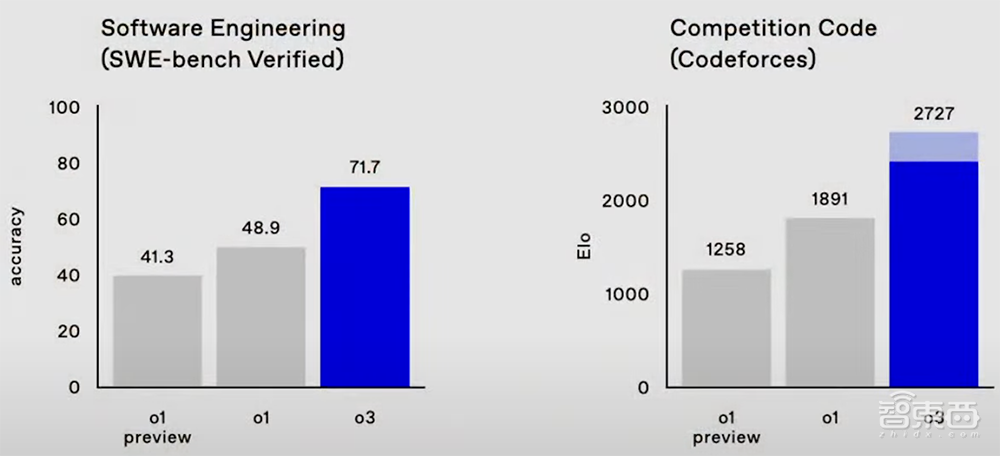
在编程竞赛Codeforces中,o1的分数是1891,而o3在高推理设置下可达到2727的分数,低推理设置的分数也超过o1。
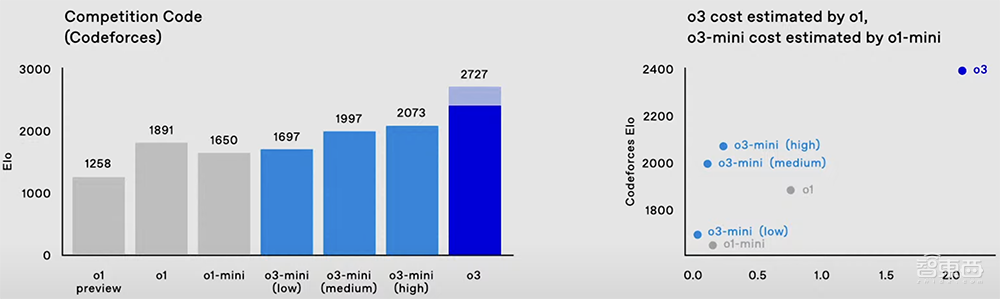
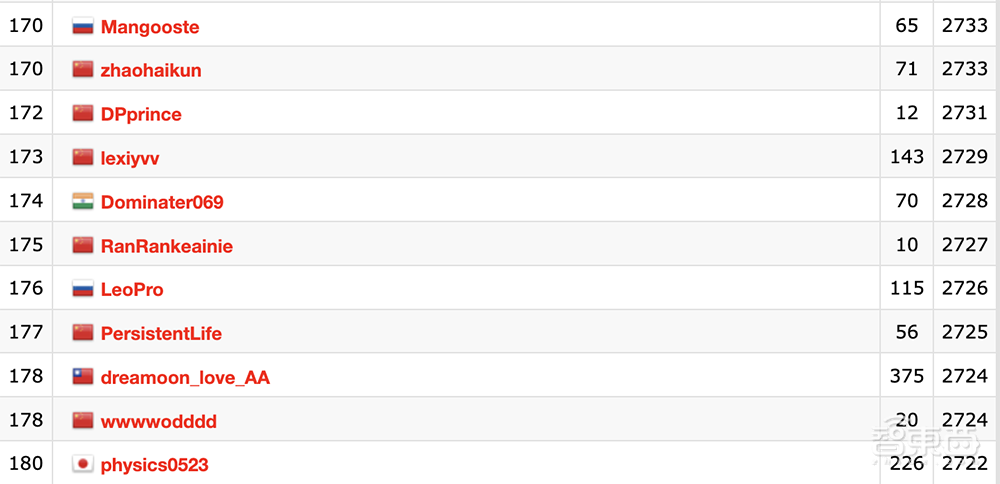
从Codeforces排行榜来看,o3的成绩能排到第175名。
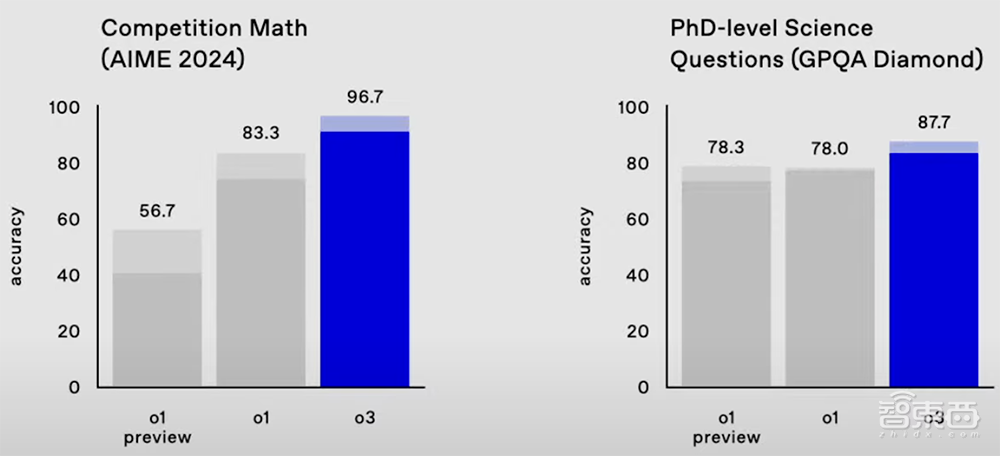
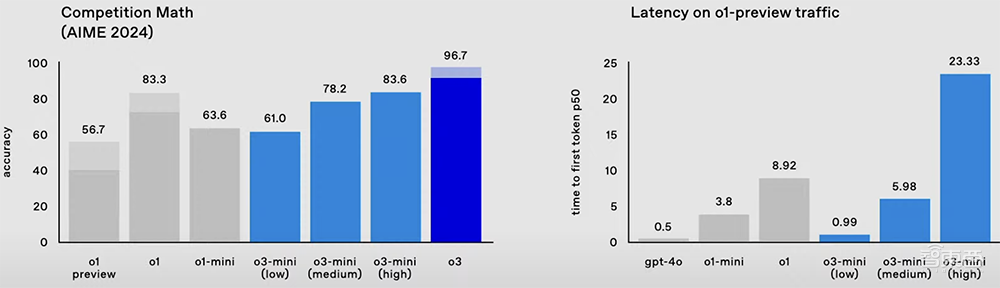
在数学基准测试AIME 2024中,o3的准确率达到96.7%,只漏掉了一个问题,而o1的准确率为83.3%。
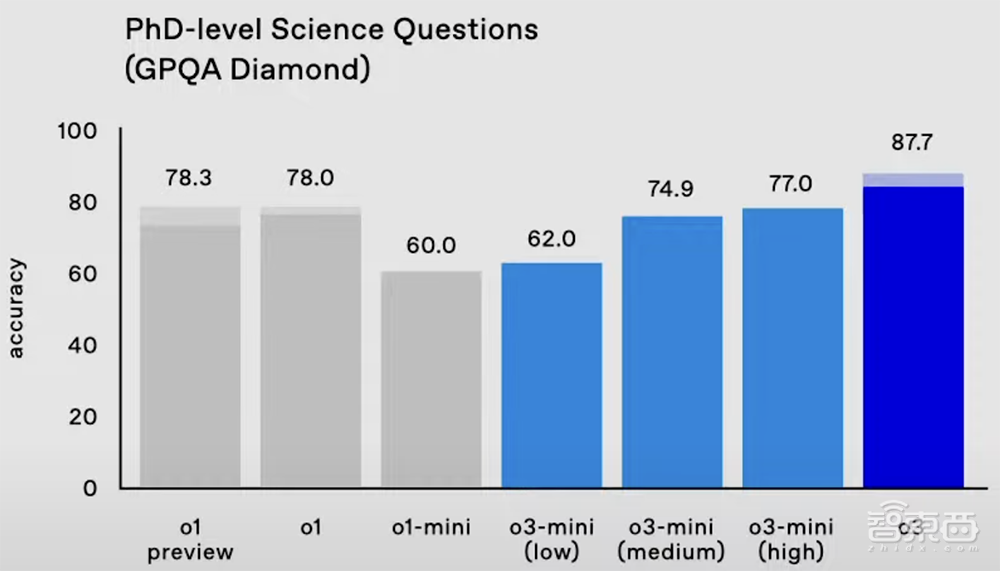
在衡量博士级科学问题的严苛基准测试GPQA Diamond中,o3的准确率高达87.7%,比o1的78%提高约10%。而专业博士通常在自己的强项领域得到70%的成绩。
OpenAI研究科学家任泓宇现场演示了一个使用Python来实现代码生成和执行的示例。


