


图片来源:Google DeepMind
Google旗下的顶尖AI研究机构Google DeepMind正致力于在视频生成领域超越OpenAI,至少从目前来看,这一目标有望达成。
周一,DeepMind宣布推出Veo 2,这是其视频生成AI的下一代产品,也是Veo的升级版,目前已支持Google旗下的众多产品。Veo 2能够生成超过两分钟、分辨率高达4k(4096 x 2160像素)的视频片段。
值得注意的是,这一分辨率是OpenAI的Sora的4倍,且持续时间超过6倍。
当然,这仅是理论上的优势。目前,Veo 2仅在Google的实验性视频创作工具VideoFX中独家可用,但视频的最大分辨率限制为720p,时长不超过8秒。(Sora则能生成最高达1080p分辨率、时长20秒的视频片段。)
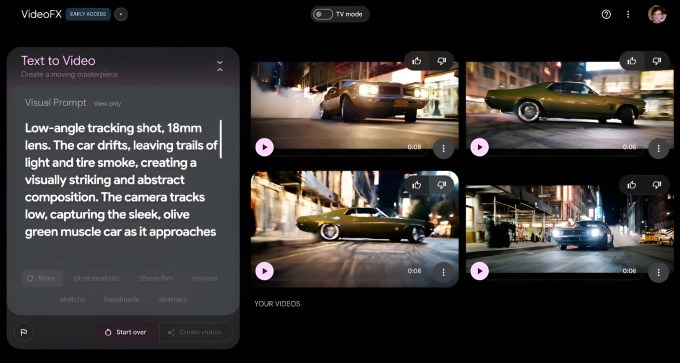
VideoFX中的Veo 2。图片来源:Google
VideoFX目前处于预约阶段,但Google表示,本周将扩大该工具的访问范围。
DeepMind产品副总裁Eli Collins还向TechCrunch透露,Google将通过其Vertex AI开发者平台提供Veo 2,“一旦该模型准备好大规模应用”。
“在未来几个月里,我们将继续根据用户反馈进行迭代,”Collins表示,“并将Veo 2的新功能融入Google生态系统中,探索更多应用场景……我们期待明年分享更多进展。”
更精细的控制
与Veo类似,Veo 2能够根据文本提示(如“一辆汽车在高速公路上疾驰”)或结合文本与参考图像生成视频。
那么Veo 2有哪些新特性呢?DeepMind表示,该模型能生成多种风格的视频片段,对物理和相机控制的“理解”有所增强,并呈现“更清晰”的画面。
DeepMind所说的“更清晰”指的是视频片段中的纹理和图像更加锐利,特别是在动态场景中。至于改进的相机控制,它们使Veo 2能够更精确地定位虚拟“相机”,并移动相机以从不同角度捕捉物体和人。
DeepMind还声称,Veo 2能更逼真地模拟运动、流体动力学(如咖啡倒入杯子)和光学特性(如阴影和反射),包括不同的镜头和电影效果,甚至“微妙”的人类表情。

Google Veo 2示例。请注意,将片段转换为GIF时引入了压缩伪影。图片来源:Google
上周,DeepMind与TechCrunch分享了几个精心挑选的Veo 2样本。对于AI生成的视频而言,它们的效果相当出色。Veo 2似乎对折射和复杂液体(如枫糖浆)有很好的理解,并且擅长模仿皮克斯风格的动画。
但尽管DeepMind坚称该模型不太可能产生如多余手指或“意外物体”等幻觉元素,Veo 2仍难以完全摆脱恐怖谷效应。
请注意这只卡通狗状生物无神的眼睛:

图片来源:Google
还有这段视频中奇怪湿滑的道路——以及背景中融合在一起的行人和看似不可能的建筑:

图片来源:Google
Collins承认还有改进空间。
“连贯性和一致性是我们努力的方向,”他说,“Veo可以在几分钟内持续遵循提示,但[尚无法在更长时间内]处理复杂提示。同样,角色一致性也可能是一个挑战。在生成复杂细节、快速和复杂的动作以及继续推动现实主义的界限方面,我们仍有提升空间。”
Collins补充说,DeepMind继续与艺术家和制作人合作,以完善其视频生成模型和工具。
“自Veo开发之初,我们就与Donald Glover、The Weeknd、d4vd等创意人员合作,深入了解他们的创作过程以及技术如何助力他们实现愿景,”Collins说,“我们在Veo 1上与创作者的合作为Veo 2的开发提供了宝贵信息,我们期待与受信任的测试人员和创作者合作,获取有关这一新模型的反馈。”
安全性与训练
Veo 2基于大量视频进行训练。这是AI模型的常见工作方式:通过提供一系列数据示例,模型能够捕捉到数据中的模式,从而生成新数据。
DeepMind不愿透露视频训练数据的来源,但YouTube是一个可能的渠道;Google拥有YouTube,且DeepMind之前曾向TechCrunch透露,像Veo这样的Google模型“可能”在一些YouTube内容上进行过训练。
“Veo已经在高质量的视频描述对上进行了训练,”Collins说,“视频描述对包括一个视频及其相关描述,概述视频中发生的事情。”

图片来源:Google
虽然Google通过DeepMind提供了工具,允许网站管理员阻止实验室的机器人从其网站中提取训练数据,但DeepMind并未提供机制让创作者从其现有训练集中删除作品。该实验室及其母公司认为,使用公共数据进行模型训练是合理使用,意味着DeepMind认为自己无需征求数据所有者的许可。
并非所有创作者都认同这一观点——特别是考虑到有研究表明,未来几年内,数万名电影和电视工作者可能因AI而失业。包括热门AI艺术应用Midjourney背后的同名初创公司在内的多家AI公司正面临诉讼,被指控未经许可对内容进行训练,侵犯了艺术家的权利。
“我们致力于与创作者和合作伙伴合作,实现共同目标,”Collins说,“我们继续与创意社区和更广泛的行业人士合作,收集见解并听取反馈,包括使用VideoFX的用户。”
由于当今的生成模型在训练时可能再生训练数据的镜像副本,存在一定风险。DeepMind的解决方案是提供针对暴力、图形和露骨内容的提示级别过滤器。
Google的赔偿政策为某些客户因使用其产品而引发的版权侵权指控提供辩护,但在Veo 2普遍可用之前,该政策不适用于Veo 2,Collins表示。

图片来源:Google
为减轻深度伪造的风险,DeepMind表示正在使用其专有的水印技术SynthID,在Veo 2生成的帧中嵌入不可见的标记。然而,与所有水印技术一样,SynthID并非万无一失。
Imagen升级
除了Veo 2,Google DeepMind今早还宣布了对Imagen 3(其商业图像生成模型)的升级。
从今天起,ImageFX(Google的图像生成工具)的用户将可体验Imagen 3的新版本。据DeepMind介绍,它能创建“更明亮、构图更佳”的图像和照片,涵盖现实主义、印象派、动漫等多种风格。
“此次对Imagen 3的升级能更忠实地遵循提示,并呈现更丰富的细节和纹理,”DeepMind在提供给TechCrunch的博客文章中写道。
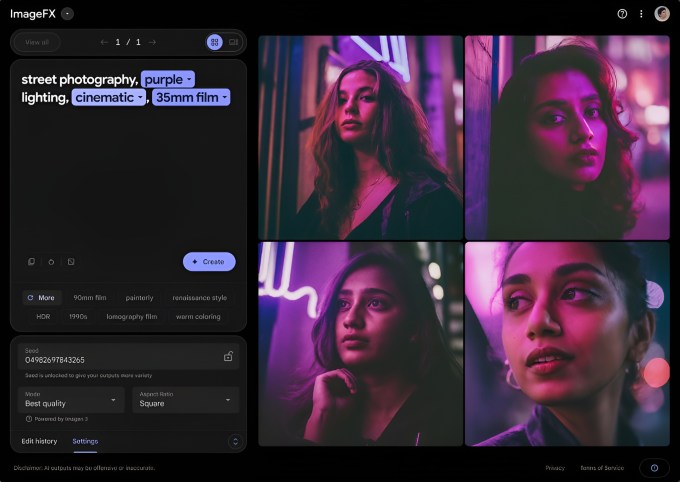
图片来源:Google
与该模型一同推出的是ImageFX的用户界面更新。现在,当用户输入提示时,关键词将变为带有下拉菜单的“芯片”,其中包含建议的相关单词。用户可利用这些芯片迭代所写内容,或从提示下方的自动生成描述符行中进行选择。


