

【导读】通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
在大模型时代,视觉语言模型(Vision-Language Models, VLMs)正在从感知走向推理。在诸如图像问答、图表理解、科学推理等任务中,VLM不再只需要「看见」和「描述」,而是要能「看懂」和「想清楚」。
然而,当前主流的推理能力提升方法普遍存在两个问题:
1. 训练样本质量参差不齐:常见的数据集虽然体量庞大,但真正「有挑战性」的样本比例较低。
2. 过度依赖知识蒸馏:许多模型在训练时依赖大型模型(如GPT-4o)的推理过程作为教师信号,使得训练流程复杂且难以推广。
这使得训练一个高性能的VLM成本极高,也限制了模型的自主学习能力。
能否通过自我提升,训练出高性能的推理模型?
近日,来自马里兰大学,密歇根大学,和微软的团队联合提出了ThinkLite-VL模型试图打破这种依赖,探索「数据更少、能力更强」的可能性。

论文链接:https://arxiv.org/pdf/2504.07934
GitHub项目:https://github.com/si0wang/ThinkLite-VL
Hugging Face:https://huggingface.co/russwang/ThinkLite-VL-7B
论文主要关注一个核心问题:如果不给VLM额外的「教师指导」(如知识蒸馏),能否仅通过自身的反馈机制和强化学习训练,获得强大的推理能力?
直觉上,答案是肯定的:人类也可以通过不断尝试、失败和总结来提升自己的推理能力。但对模型而言,这需要我们解决一个关键挑战——如何准确判断哪些训练样本是「值得学」的?
用MCTS判断「样本难度」,筛选高质量训练集
ThinkLite-VL的最大创新在于:用蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)来重新定义「样本难度」。
研究人员首先从广泛使用的开源多模态训练数据集中收集了70k的样本,涵盖了三个关键的视觉任务:数学推理,自然图像理解和图表理解,具体的数据分布和来源如下表所示。
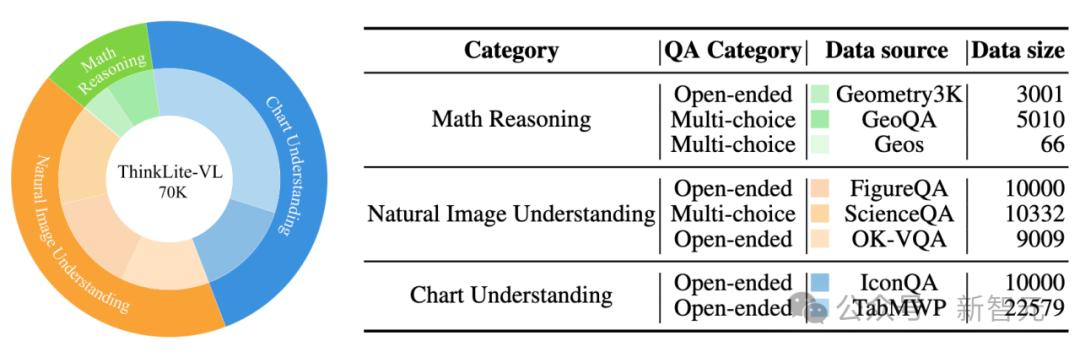
值得注意的是,为了避免大模型在回答过程中因为选择题选项中提供了正确答案而「蒙对」,研究人员将大部分的样本从选择题格式改成了开放问答格式,这样一来模型就必须依靠自身的推理能力真正理解题目并解决问题,真正的把题做对。
之后,研究人员提出了一种基于蒙特卡洛树搜索(MCTS)的样本选择方式。
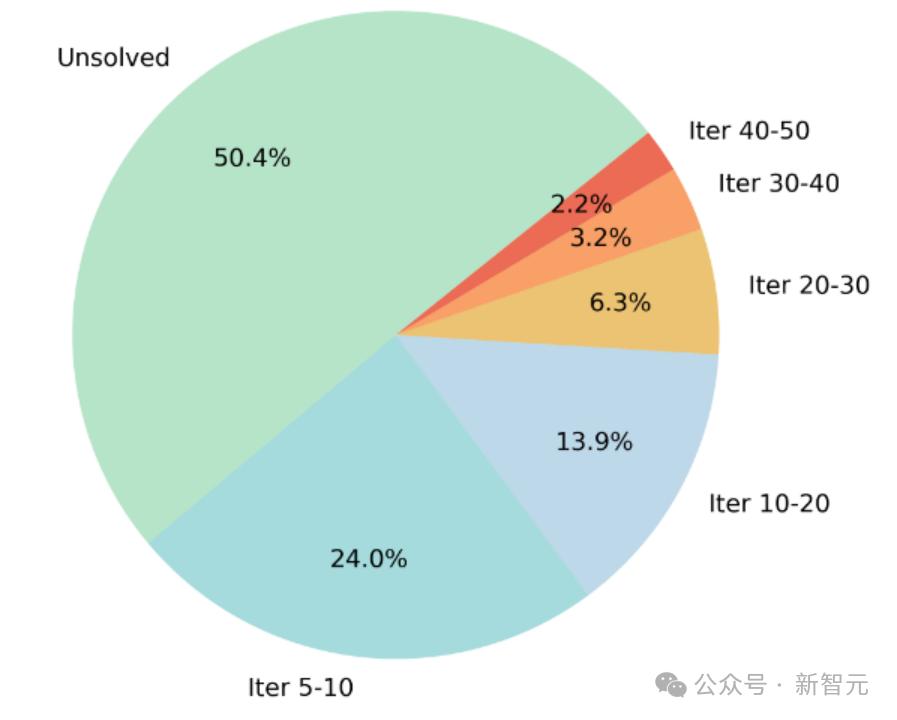
具体来说,大模型将问题和图像作为输入,让模型通过蒙特卡洛树搜索进行一步步推理,然后记录模型需要通过多少次推理迭代才能得到正确答案。模型所需要的MCTS迭代次数越多,说明模型需要通过更多的探索和思考才能解决问题,表明该问题对于模型来说更难。
整个过程中,只使用了VLM本身的LLM部分判断MCTS final answer的正确与否,模型通过解题成功的探索次数认识到哪些题是「难题」,并将其作为学习重点。
在对所有的样本都进行MCTS之后,作者最终筛选出迭代次数大于5或在50次迭代内模型都无法解决的样本,总共11k,作为最终的训练集。
强化学习训练:少样本+困难样本,推理效果更强
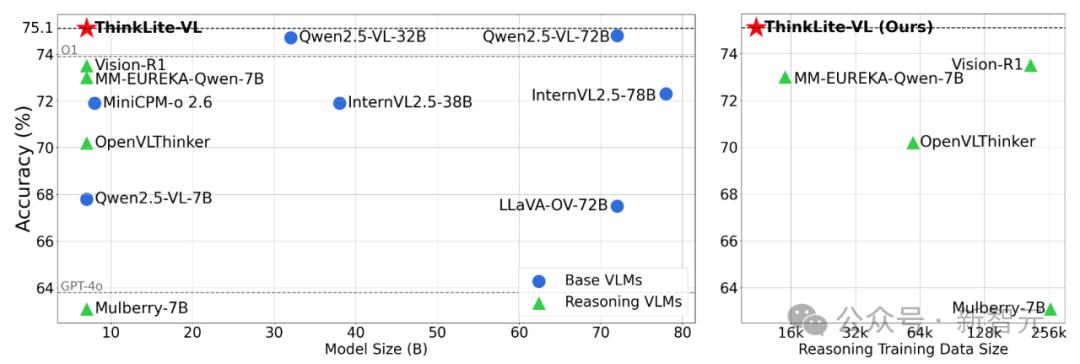
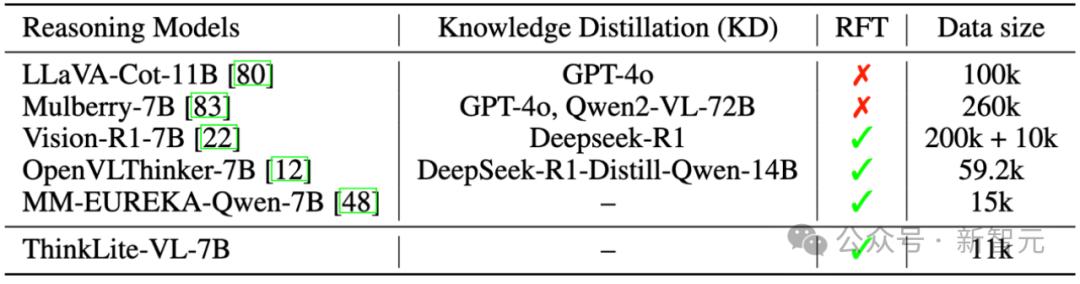
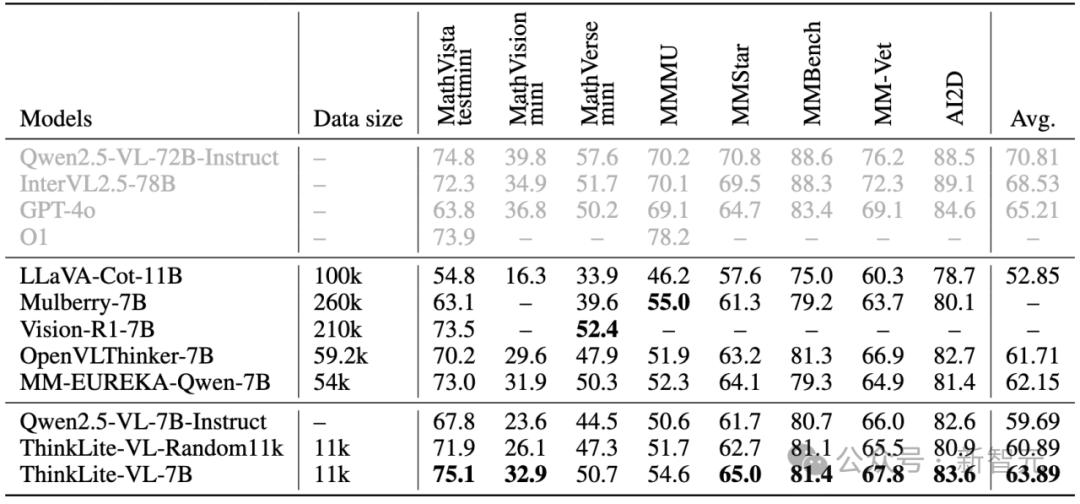
研究人员基于Qwen2.5-VL-7B-Instruct,在选出的11k样本上使用GRPO进行了强化学习训练,得到了最终的模型 ThinkLite-VL-7B。相比于其他reasoning model来说,ThinkLite-VL-7B大大减少了训练数据量,并且没有蒸馏任何外部推理模型的知识。
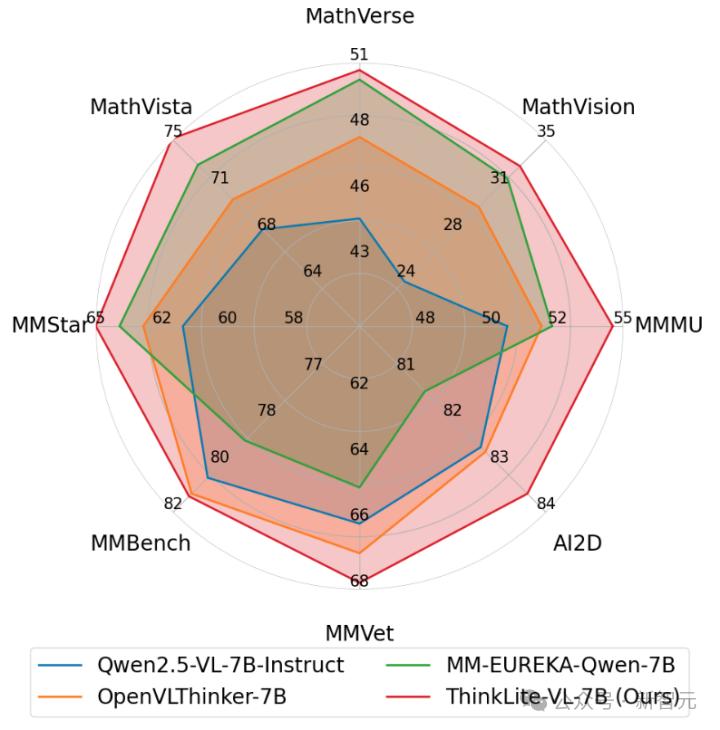
在八个主流视觉推理任务上进行测试,包括MathVista, MathVerse, MathVision,MMMU,MMStar, MMVet, MMBench和AI2D, 结果发现ThinkLite-VL-7B的平均性能相比base model Qwen2.5-VL-7B-Instruct提升了7%,从59.69 提高到 63.89,并且显著优于使用随机采样选择相同大小数据量进行强化学习训练的模型。
此外,相比7B级别的其他reasoning VLM,ThinkLite-VL-7B同样具有明显优势,包括OpenVLThinker-7B,MM-Eureka-Qwen-7B等。
特别地,在MathVista上ThinkLite-VL-7B达到了75.1的SoTA准确率,超过了GPT-4o和o1等闭源模型和Qwen2.5-VL-72B等开源更大参数量的模型。
这意味着,即使在没有额外监督、没有知识蒸馏、没有大规模数据的前提下,只需要正确选择少量对于VLM具有挑战性的高质量样本,VLM也能通过self-improve显著提升推理能力。
研究人员进一步对不同难度组合的训练集进行了消融分析,发现:
- 仅用最难的样本(无法解出)可以提升能力,但效果不及中等+困难样本的组合;
- 简单样本虽然在训练过程中快速提升reward,但对最终推理能力提升作用有限;
- 使用中等难度加上困难样本的组合才能最大程度提升模型的推理能力,即使模型在训练中无法解决全部的样本。
这一发现对未来的模型训练有重要启示:合理的样本难度分布比样本数量更关键。
论文一作王玺尧是马里兰大学计算机系三年级phd,导师为Furong Huang教授,主要研究方向为强化学习在大语言模型和视觉语言模型训练中的应用,在ICML, NeurIPS, ICLR, ACL, EMNLP, NAACL, CVPR等会议上发表过多篇论文。

参考资料:
https://arxiv.org/pdf/2504.07934


