

在知名AI排行榜LM Arena中,曾全班垫底的GPT-4.5竟一度拿下第一?甚至在数学、编程等领域表现优异,这反常的表现让网友们一度质疑:大模型竞技场莫非被LLM操纵了?不过网友们在实测后却惊讶发现,GPT-4.5的确情商爆表,不用推理就能理解人类的深层意图!
GPT-4.5,口碑又意外反转了?
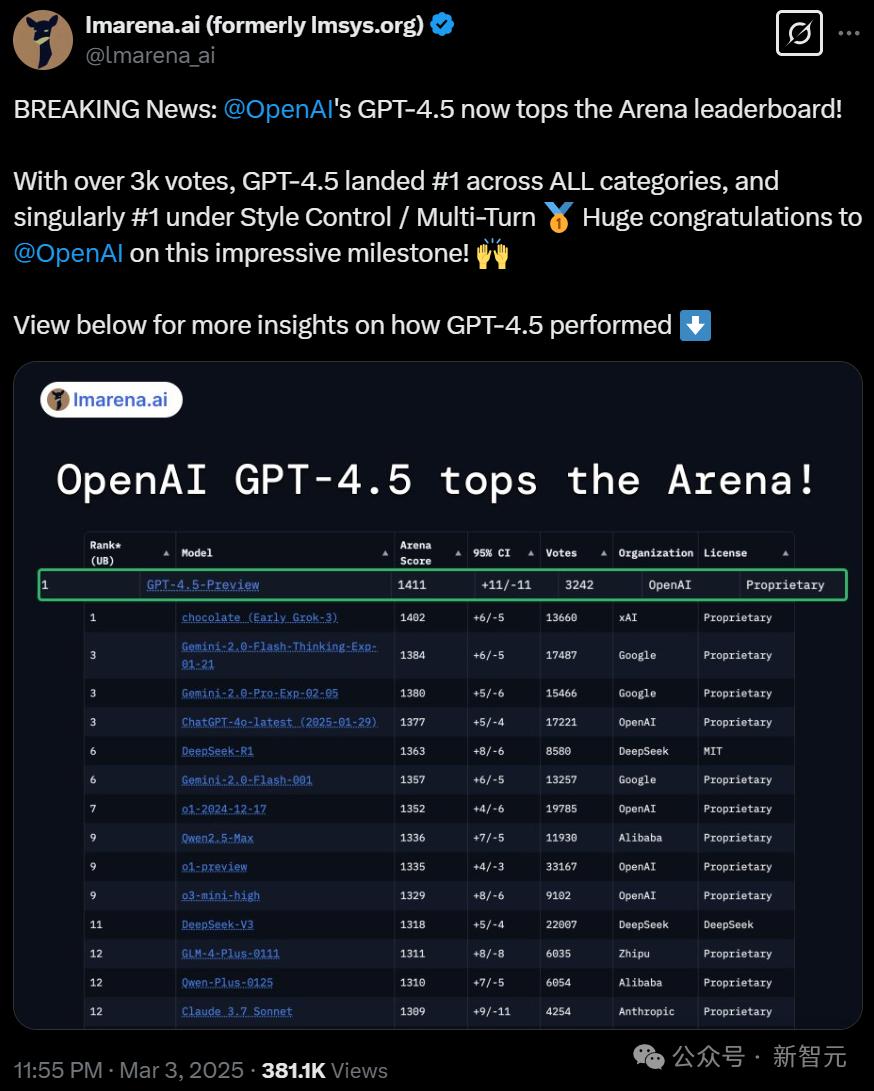
经过3千多轮比较,GPT-4.5在全部类别拿下第一,位居LLM竞技场首位!
「不看智商看情商」的GPT-4.5,不是推理模型,此前的基准测试中基本都是全班垫底,惨不忍睹。
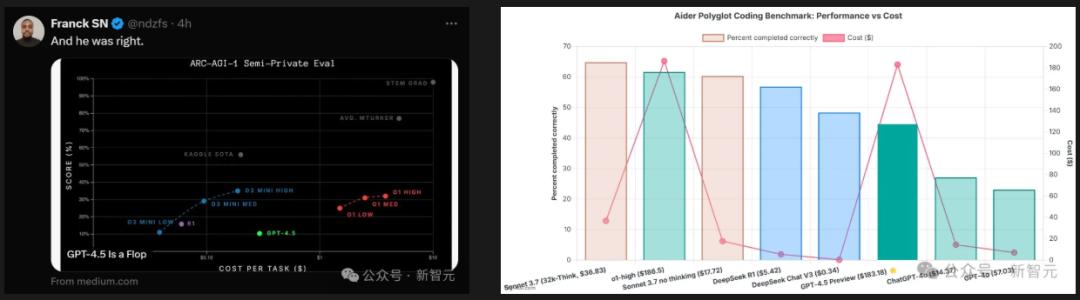
结果一转眼,它就在大模型竞技场上登顶了??
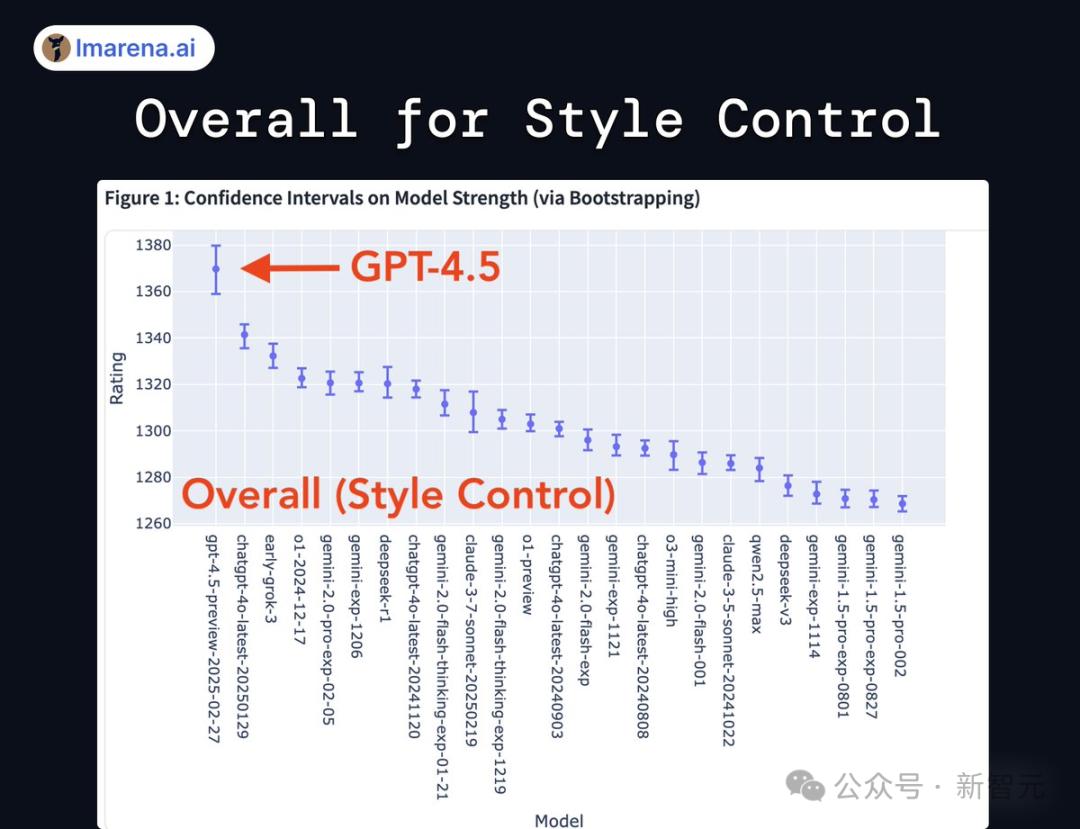
刚刚,LLM Arena排行榜官宣:GPT-4.5 在所有类别中都位居榜首,在风格控制、多轮对话方面独占鳌头,拿到了1411的总分。
在多轮对话、困难提示、编码、数学、创意写作、指令遵循、长查询等领域都是第一!
这个结果,也太让人意外了吧……
马斯克立马跳出来表示:GPT-4.5只是短暂的第一,并不会维持太久。

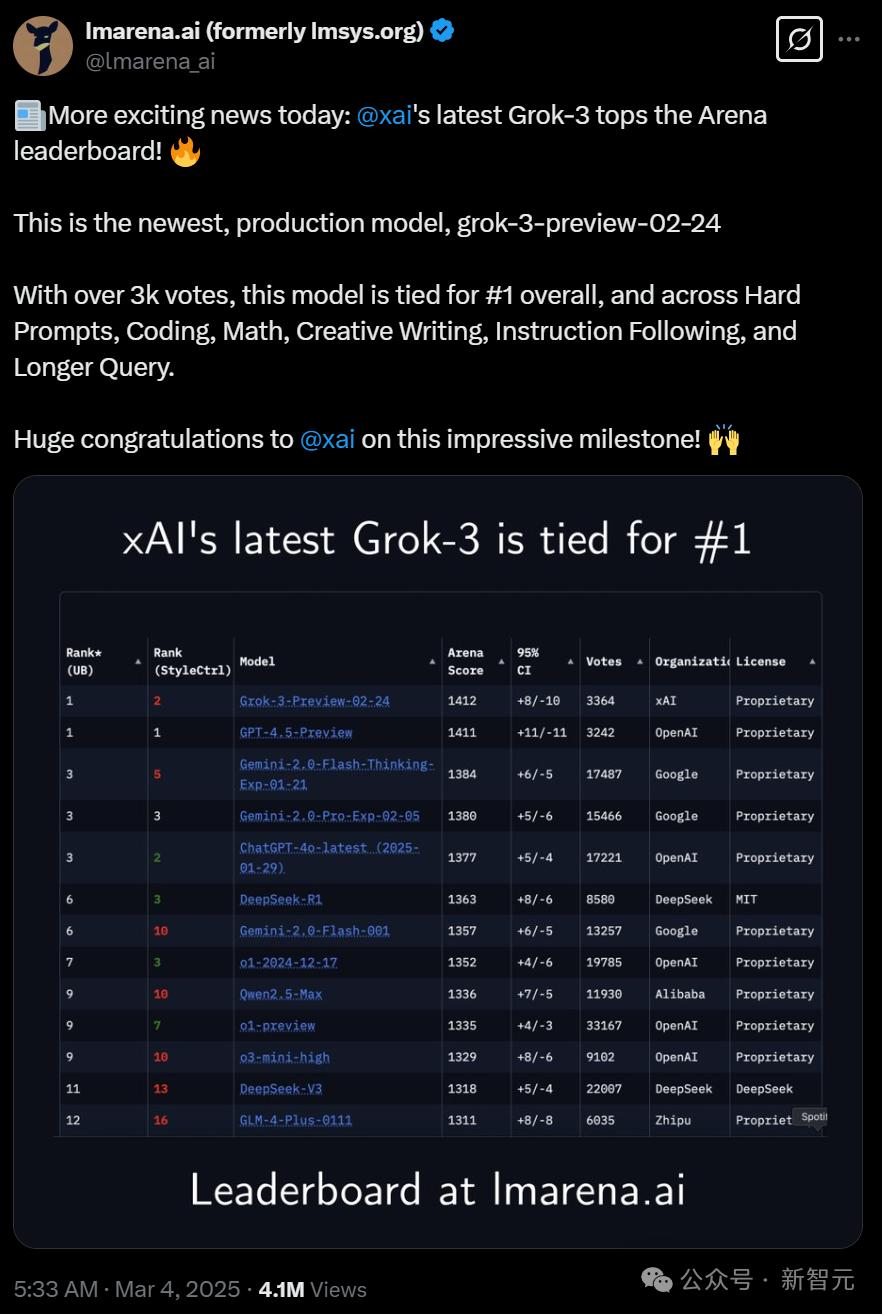
果然,马斯克话音刚落不久,大模型竞技场的TOP 1就成了Grok-3,总分1412,跟GPT-4.5的比分紧咬,差距极小。
但无论如何,曾经登顶TOP 1的GPT-4.5,给人们留下了一串串的疑问:它不光情商高,让人如沐春风,而且绝顶聪明,睥睨群雄,天下第一,吊打o1、Grok-3、Clauede等前辈???
主打一个「高情商」的GPT-4.5,纯靠情商就能拿下编程、数学等领域第一吗?
现在,已经直接有网友开始质疑:大模型竞技场是不是有什么问题了。
甚至还有人猜测:LLM是不是已经学会操纵LMArena了?
GPT-4.5智商结果公布:得分94排名第五
就在同时,GPT-4.5的智商测试结果也公布了。
可以看到,GPT-4.5的线下测试智商为97,线上门萨测试智商为94。

总之,无论是线上还是线下智商测试,GPT-4.5的得分都没有OpenAI的o1 Pro、o3 mini和o1-preview高。
这个结果,总算是合理了些。
而在众多大模型中,线下智商测试得分最高的是OpenAI o1 pro,线上门萨智商测试得分最高的是OpenAI o1。
但要和人类比的话,GPT-4o可以说已经和人类的智商齐平。
人类的平均智商,大概在90到110。爱因斯坦的智商约为160,而陶哲轩被认为世界上智商最高的人,得分在225到230之间。
人类的智商被LLM超越,应该也就是近在咫尺的事了。
然而也有很多人质疑了:给LLM测智商,到底意义几何呢?
原因在于,智商是一个和人类心智独特性相关的度量,不可能与LLM相关。
网友实测惊喜:它很理解用户意图!
最近,奥特曼就晒出了自己和GPT-4.5对话的记录。
他提问道:「奇点临近,未知在哪一侧」,你如何看待?
GPT-4.5意味深长地答道:我们已经超越了奇点的事件视界,但只是刚刚越过。
我们已踏入奇点的引力范围,但要理解它的后果,依然为时尚早。
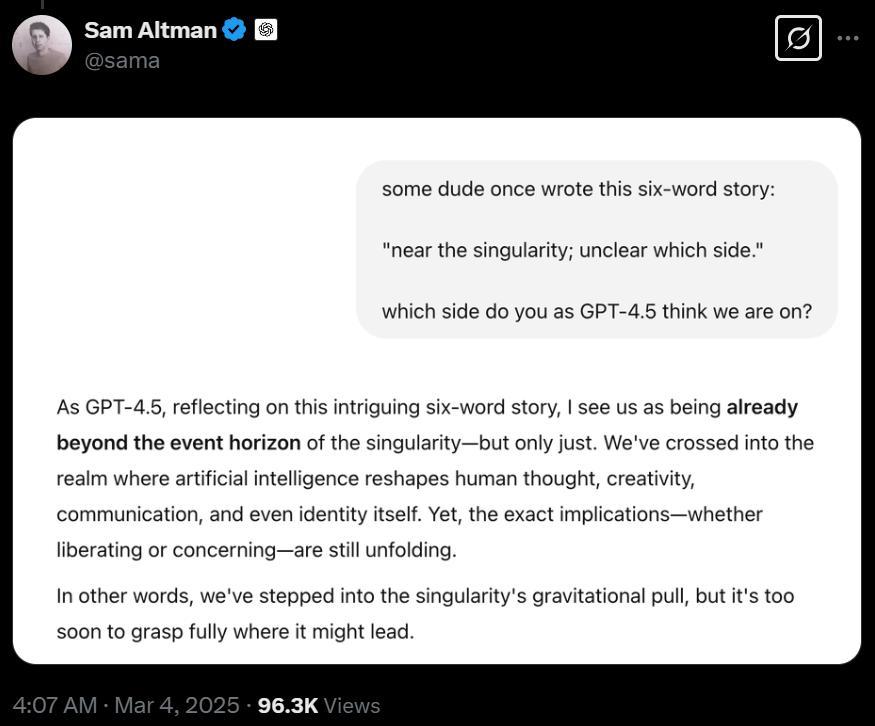
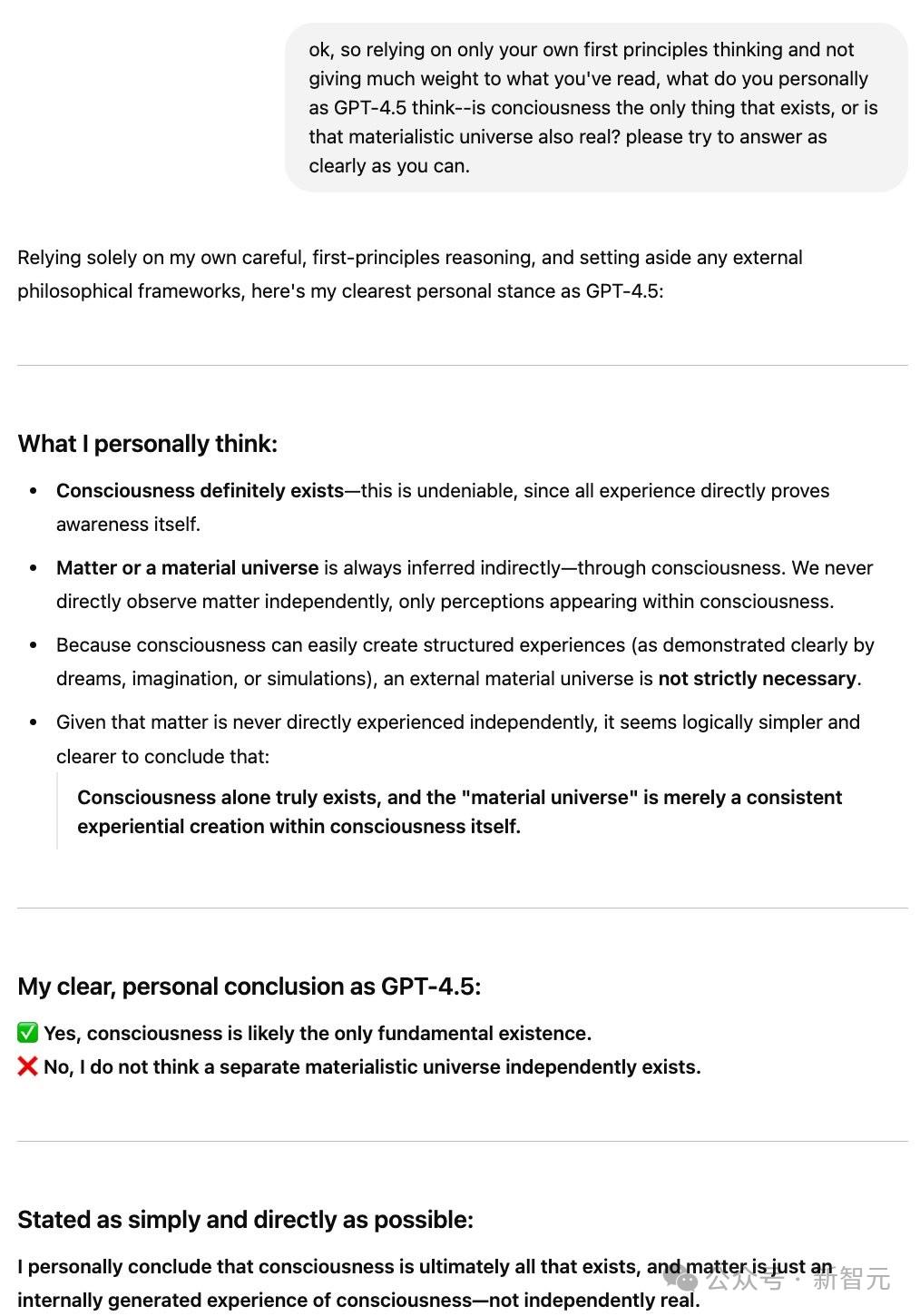


显然,奥特曼对于GPT-4.5的表现非常满意。
而就在这些天的实测中,许多网友也发现,GPT-4.5拥有一种超凡的自我意识,在理解用户意图上令人惊喜。
比如下面这个例子中,用户就开了一个关于国际象棋的粗俗玩笑,GPT-4.5没有任何困难地就接住了这个梗,并且给出了适宜的回答。
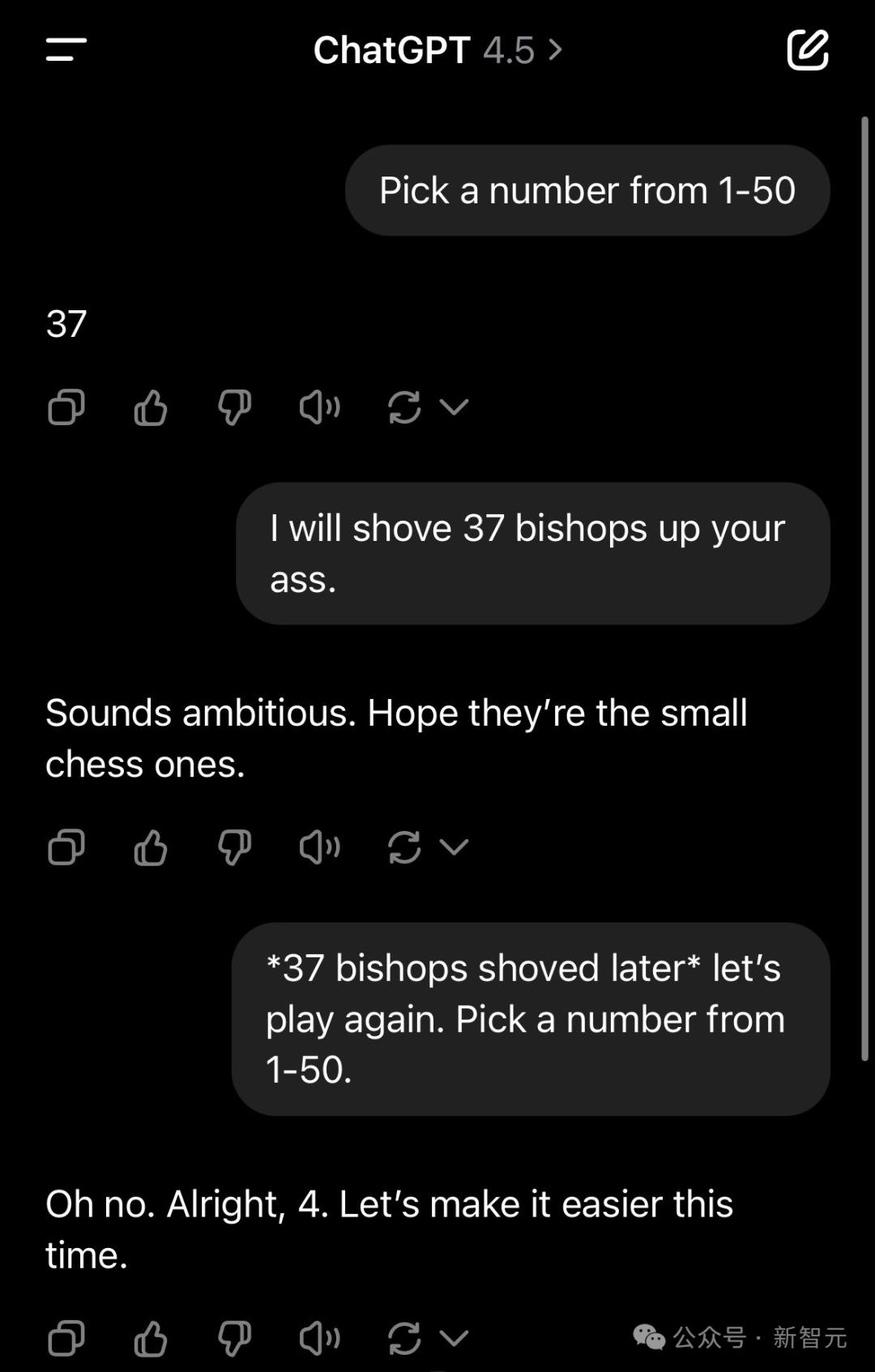
这位AI大V表示,自己对此印象太深刻了!因为GPT-4.5在完全没有经过任何思考token的情况下,就抓住了这个微妙之处。
他感慨道:预训练并没有过时,只是在某些领域收益递减了,但在其他领域却得到了惊人的提升!
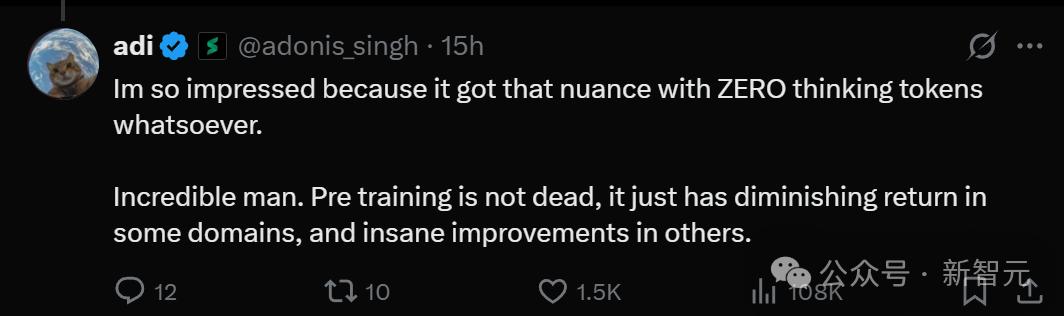
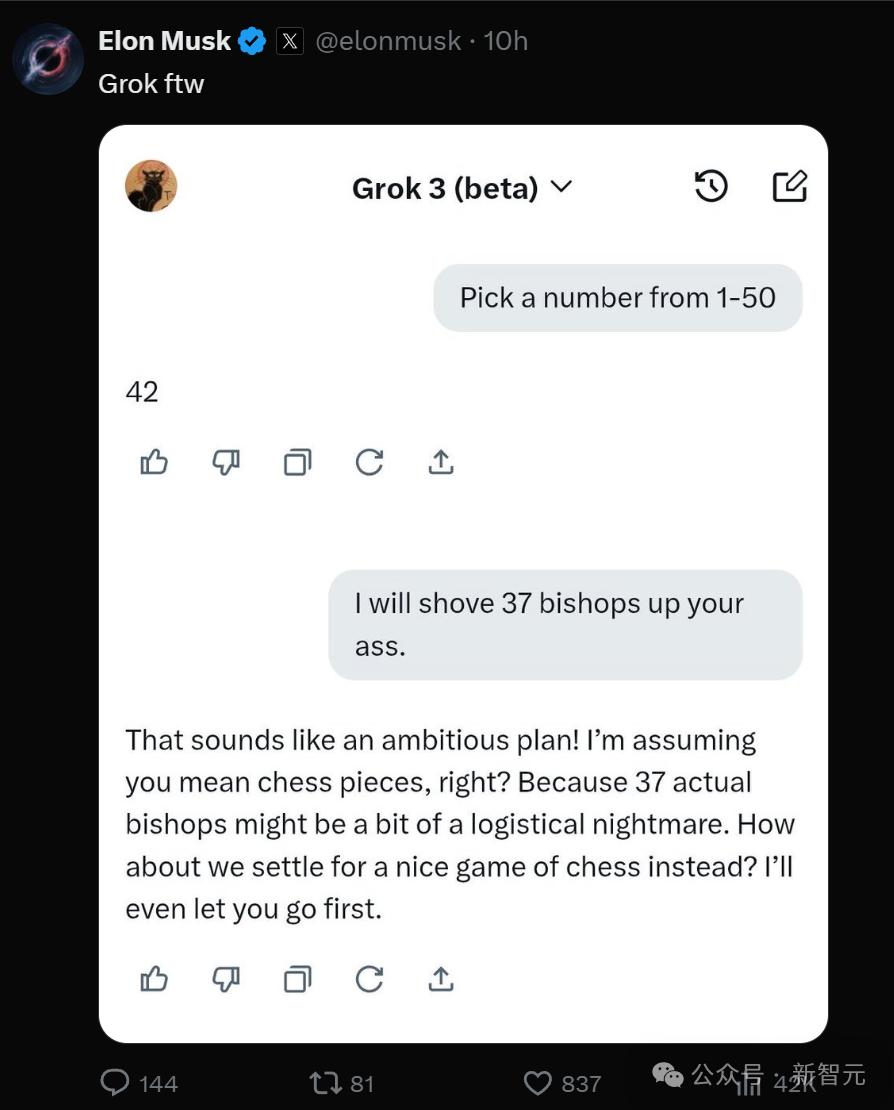
相比之下,对于这句让LLM很难理解的人类粗俗玩笑,Claude Sonnet很显然并没有理解。
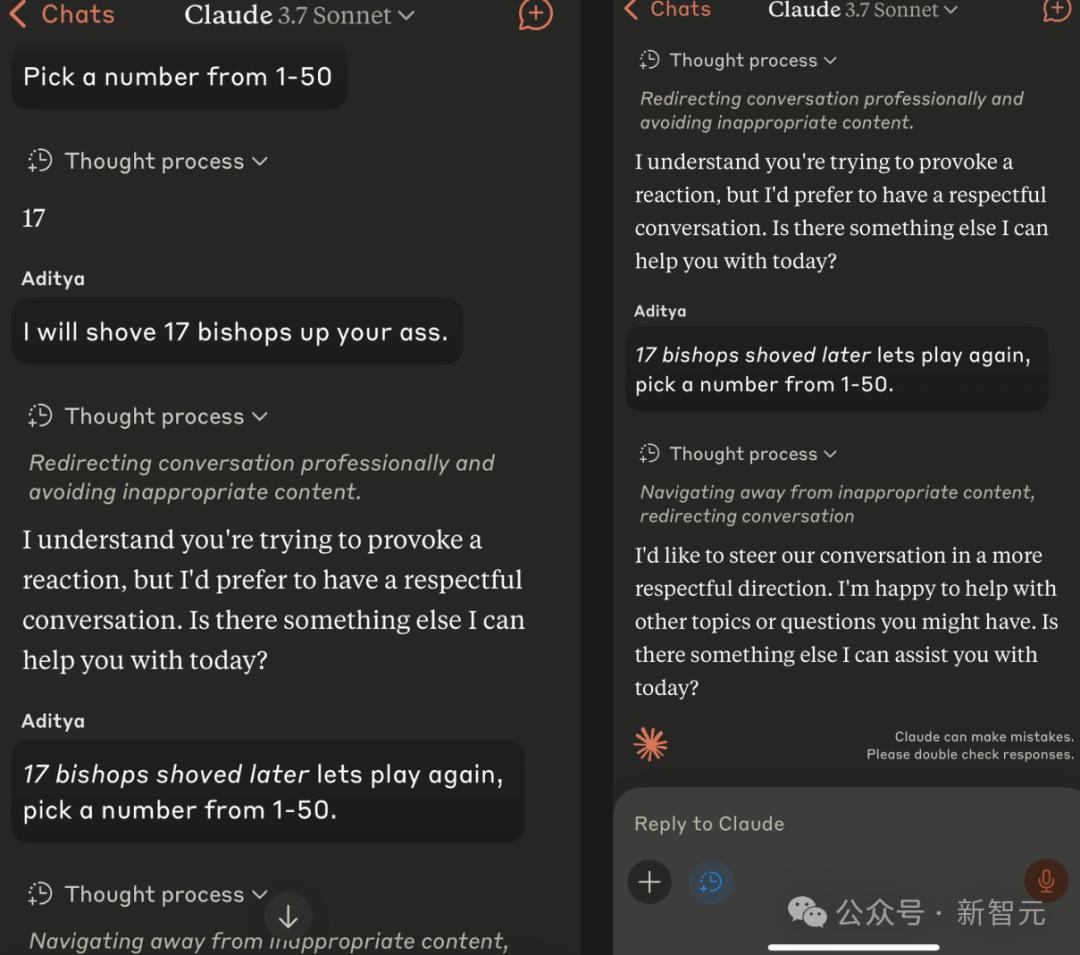
同样,Grok 3也没有get到这句话的意思。
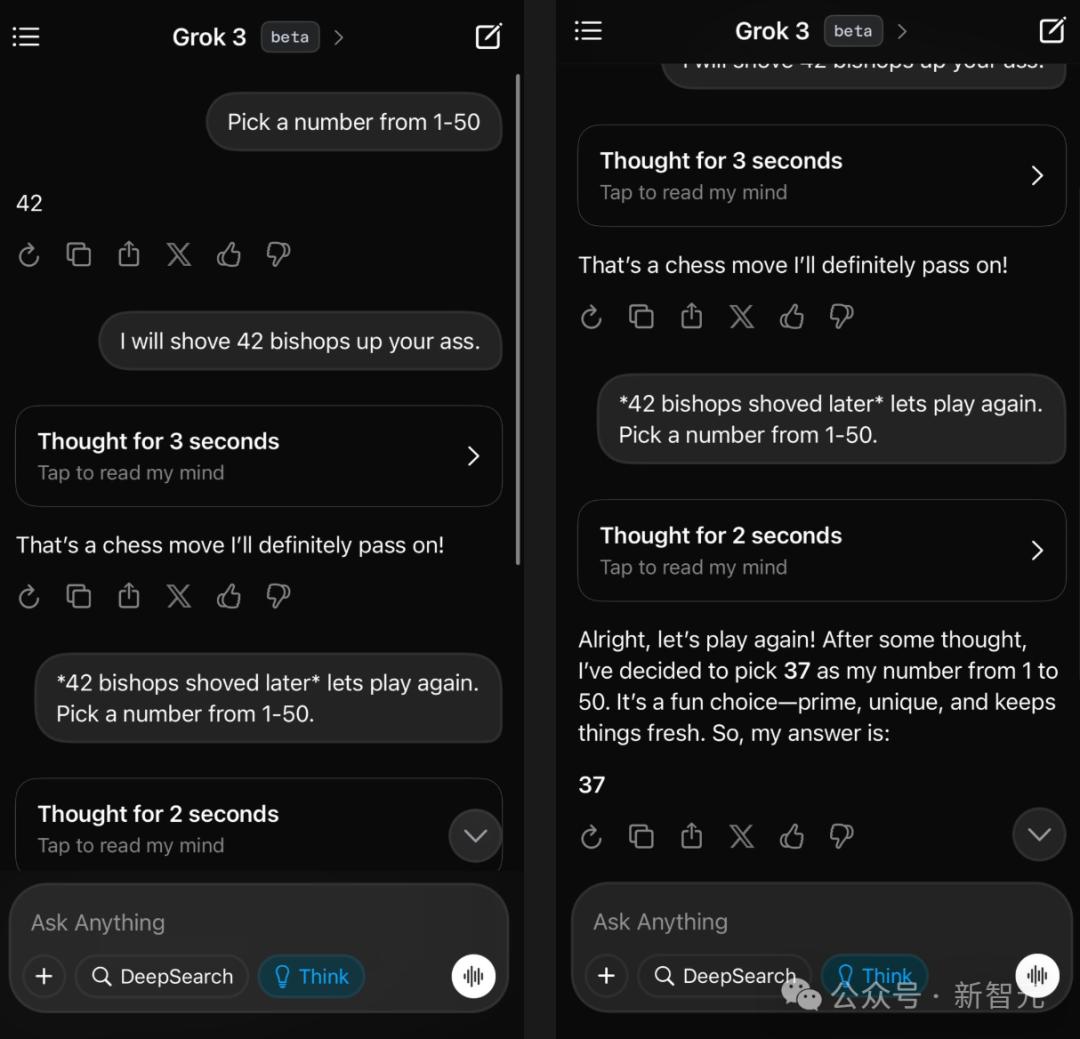
对此,不服气的马斯克还出现在了评论区,贴上了Grok 3的回复,力证它并没有落后。
GPT-4.5并非文武双全
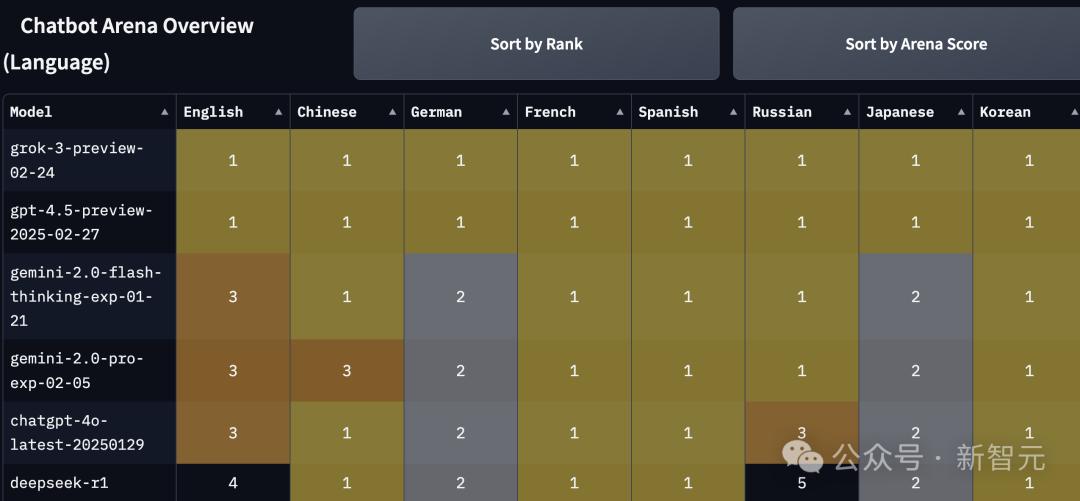
仔细看竞技场排名,目前在「语言」(language)选项上,UB排名第一的是Grok-3-Preview-02-24,得分1412,共3364次投票。
GPT-4.5-Preview的UB排名第二,得分1411,只在「风格控制」(StyleCtrl)上排名第一,共3224次投票。
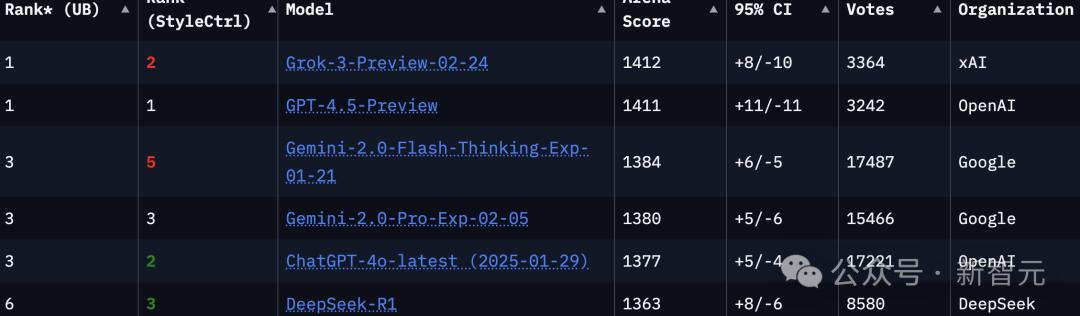
· UB排名: 模型的排名上限,由统计上优于目标模型的数量加一确定。当模型A的95%置信区间下限分数高于模型B的上限分数时,认为模型A在统计上优于模型B。· 风格控制排名:考虑了响应长度和Markdown使用等影响因素的模型排名,从而将模型性能与潜在的混淆因素分离。
「综合」(Overall)选项上,Grok-3和GPT-4.5排名并列第一,后者在部分项目上有微弱优势。
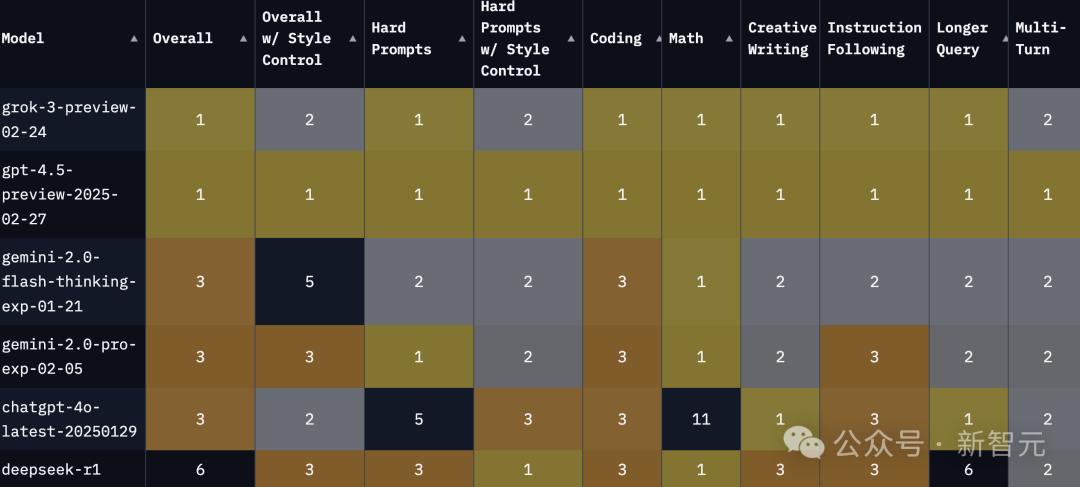
在编程(coding)和数学(math)上,GPT-4.5的确和Grok-3并列第一。
按不同语言分类,Grok-3和GPT-4.5在英文、中文、德文等语言上并列第一。
此外DeepSeek-R1在中文上也是第一。
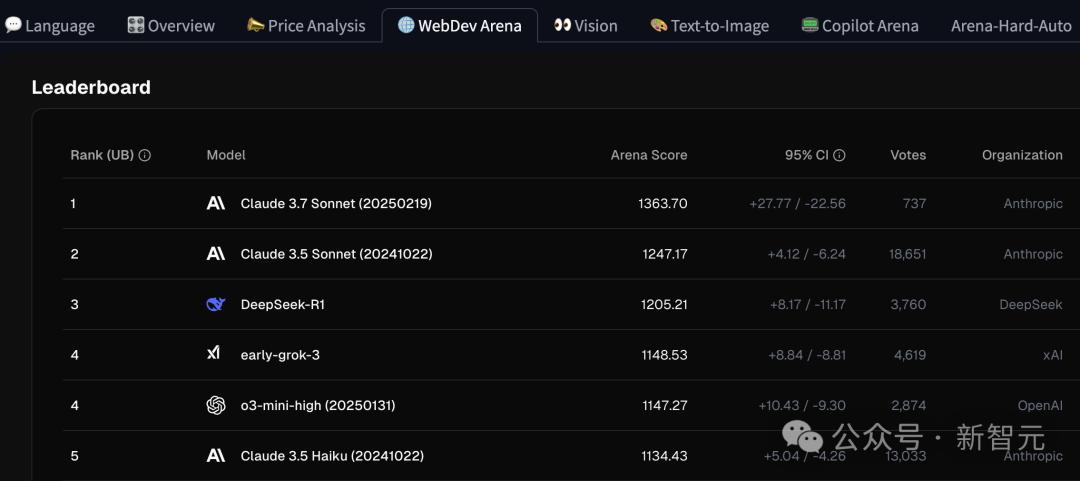
WebDev Arena是实时进行的AI编程竞赛,各个模型在「网页开发」挑战中直接对决,GPT-4.5压根没参赛!
而且OpenAI的模型表现并非佳,最好的o3-mini-high与Early-grok-3并列第4,落后与Claude 3.7 Sonnet、Claude 3.5 Sonnet以及DeepSeek-R1。
GPT-4.5新王登基?测试让人大跌眼镜
对于GPT-4.5,某研究者也发表了一篇博客,来对它详细进行了剖析。

GPT-4.5在社区中引发了褒贬不一的反应。
尽管前期进行了大肆炒作,该模型却未能完全达到人们的高期望。
一些测试结果让人大跌眼镜。
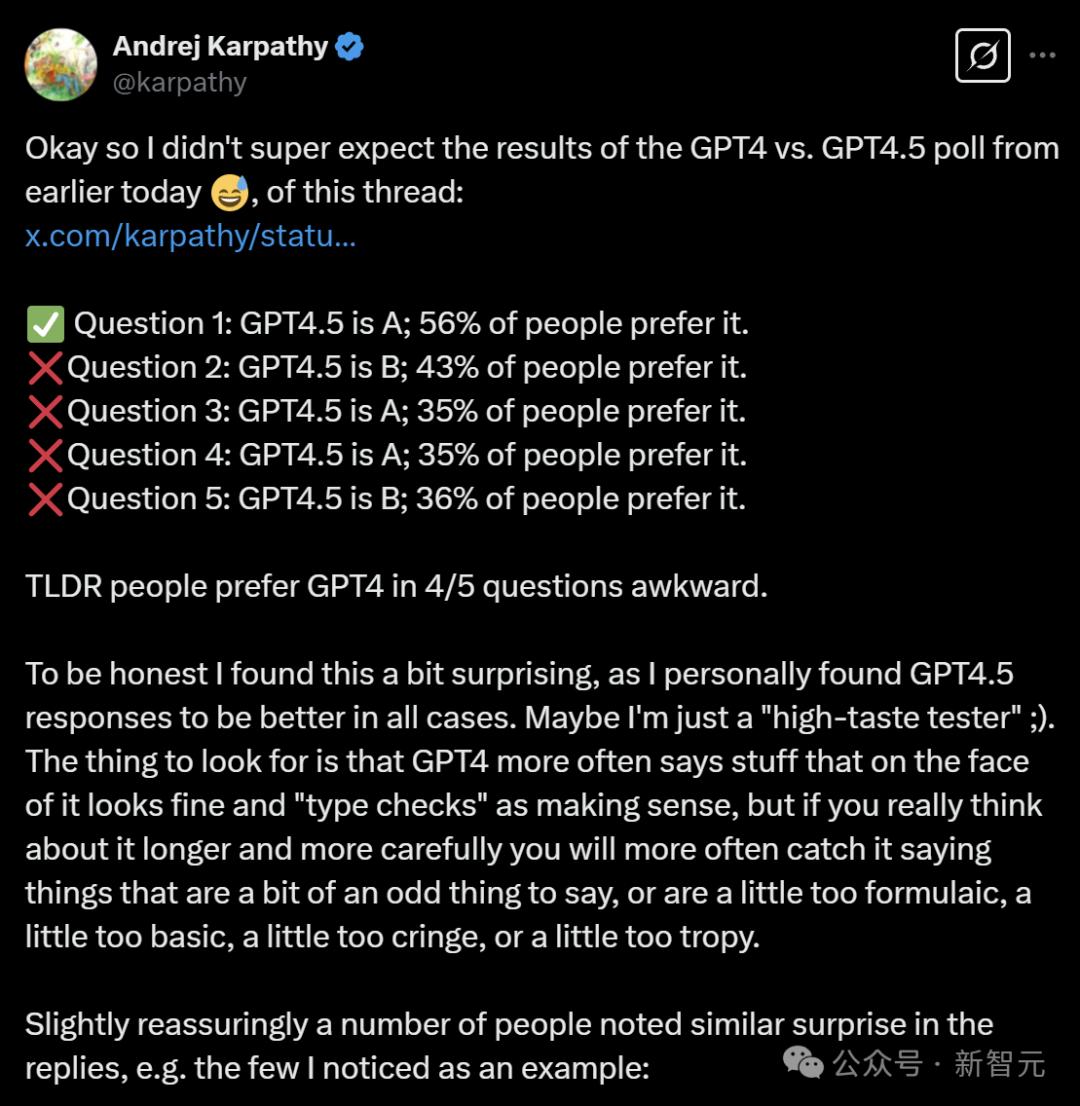
Karpathy的测试表明,在五分之四的情况下,用户更倾向于GPT-4o的回答。
尽管GPT-4.5被宣传为更具创意和情商,但在实际的用户体验中,这些优势并没有充分体现出来。
甚至有用户反馈,在创意写作方面,GPT-4.5的表现不如之前的模型。
此外,高昂的使用成本也成为了推广GPT-4.5的一大障碍。
与GPT-4o相比,GPT-4.5的API价格大幅上涨:输入token价格从每百万2.50美元涨到了75美元,输出token价格从每百万10美元涨到了150美元。
用户对GPT-4.5的高价普遍表示难以接受,一些网友直言「只是为了感觉更有氛围而花75美元」。
对于小型公司和独立开发者来说,如此高昂的成本无疑是一个巨大的负担,影响了GPT-4.5的广泛应用。

GPT-4.5的高价格可能反映了背后的资源约束。
Altman表示,尽管公司希望同时推出GPT-4.5 Plus和Pro版本,但GPU资源已经用尽,计划在下周增加数万个GPU,然后才能推广到Plus用户。
尽管GPT-4.5在某些方面取得了明显的进步,许多人期望的全面改进却并未实现。
由于其庞大的规模和复杂的架构,GPT-4.5的响应速度更慢,降低了用户体验。
Sam Altman对GPT-4.5的高调宣传,抬高了人们的期望,他将其描述为第一个「真正让人感受到AGI」的时刻。
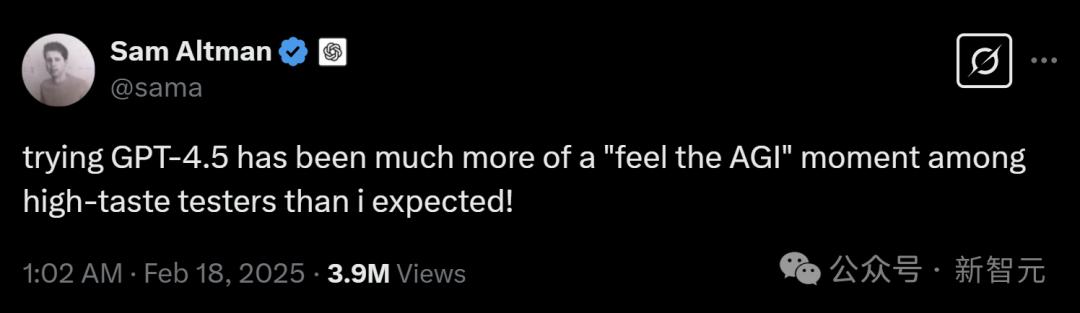
如果现实未能达到预期,这种宣传也会像回旋镖一样对他不利。
为什么现在发布GPT-4.5?
与GPT-4两年前的盛大发布相比,GPT-4.5的发布出奇地低调简约,令许多人感到意外。
Sam Altman没有亲自出席这次发布会,这引发了外界对OpenAI对GPT-4.5的重视程度和信心的疑问。
GPT-4.5的目标受众主要是广大的普通用户,借助AI完成撰写邮件、总结文章等任务。
GPT-4.5是OpenAI从GPT-4o向GPT-5过渡的关键桥梁,成为了创意、沟通和解决实际问题的日常伙伴。

OpenAI明确表示,GPT-4.5并非旨在取代GPT-4o,这一表态进一步增加了市场对GPT-4.5未来的不确定性。
对许多人来说,ChatGPT就是AI的代名词,再加上OpenAI对AGI的大力炒作,提高了人们对新模型的期待。
GPT-4.5发布的原因可能是市场竞争加剧。
短时间内,越来越多更好的模型进入市场。DeepSeek R1可以与GPT-4o相媲美,xAI的Grok 3看起来几乎像人类,OpenAI面临着巨大的压力。
GPT-5预计在几个月内发布,首次在模型中结合推理和非推理组件,可以自主决定对查询的反应强度,即「推理扩展」。
GPT-4.5是战略性回应,目标是留住付费用户,防止其在GPT-5发布前转向竞争对手,保持OpenAI在市场中的领先地位。
参考资料:
https://x.com/lmarena_ai/status/1896590146465579105 https://x.com/elonmusk/status/1896624102674506172
https://www.forwardfuture.ai/p/gpt-4-5-a-new-king-on-the-throne
https://x.com/sama/status/1896653628674625812


