

从OpenAI-o1开始,优化和增加Test Time Compute(测试时计算)就成了大语言模型界最热门的话题。
测试时计算是什么?
在机器学习和深度学习里,我们通常会经历模型的训练和测试这两个主要阶段。测试时计算就是在模型训练好之后,用它来对新的数据进行预测或者评估性能时所进行的一系列计算操作。
测试时计算的处理能力一般被用在推理加强上。
简单理解就是:推理加强就是采取各种手段来提升模型推理的准确性、速度、效率等性能指标。而测试时计算的处理能力将直接影响推理过程的执行情况。
OpenAI-o1所采用的道路是通过强化学习(RL),在后训练过程中将思维链(CoT)融入到模型的输出过程中,在测试时进行多次采样和评估来提升决策质量,增加模型的推理时间和能力。
当下最热门的模型DeepSeek-R1也是用的同样的逻辑。
但DeepSeek-R1带来的最大惊喜,是通过非常简单的奖励规则,而非用范例去监督微调(SFT),就鼓励模型自主形成了长思考的能力。
这里有一个关键问题,如果只是增加推理时间就可以提升模型能力的话,为什么我们一定要在后训练中做这个工作呢?把它放在Transformer架构里不行吗?
2月7日,一项来自图宾根马普所(马克斯・普朗克生物控制论研究所,Max Planck Institute for Biological Cybernetics,位于德国图宾根市,是生物控制论领域具有国际影响力的科研机构)的研究,就揭示了这样一条全新的增加测试时长的道路。
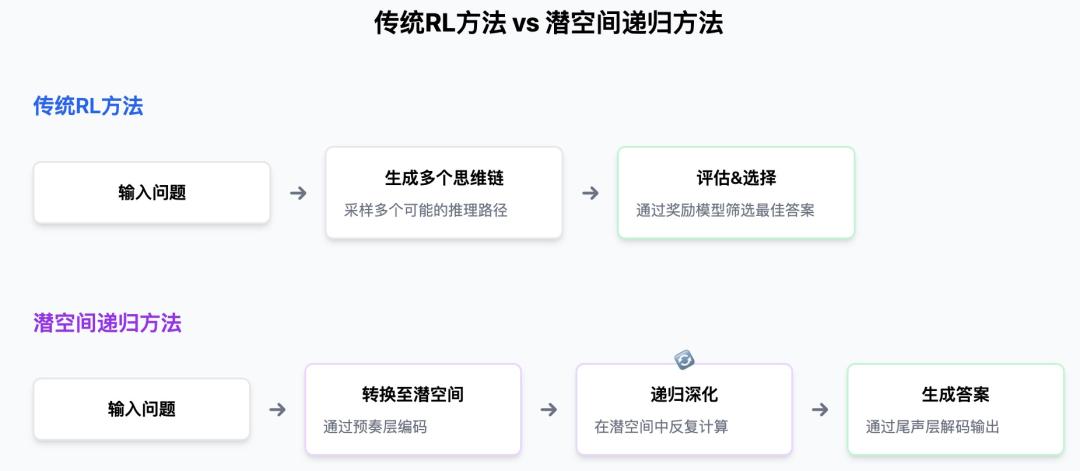
他们将深度学习的传统艺能递归,优雅地整合进了Transformer的核心架构中,让模型在预训练阶段就能具有深度推理的能力。
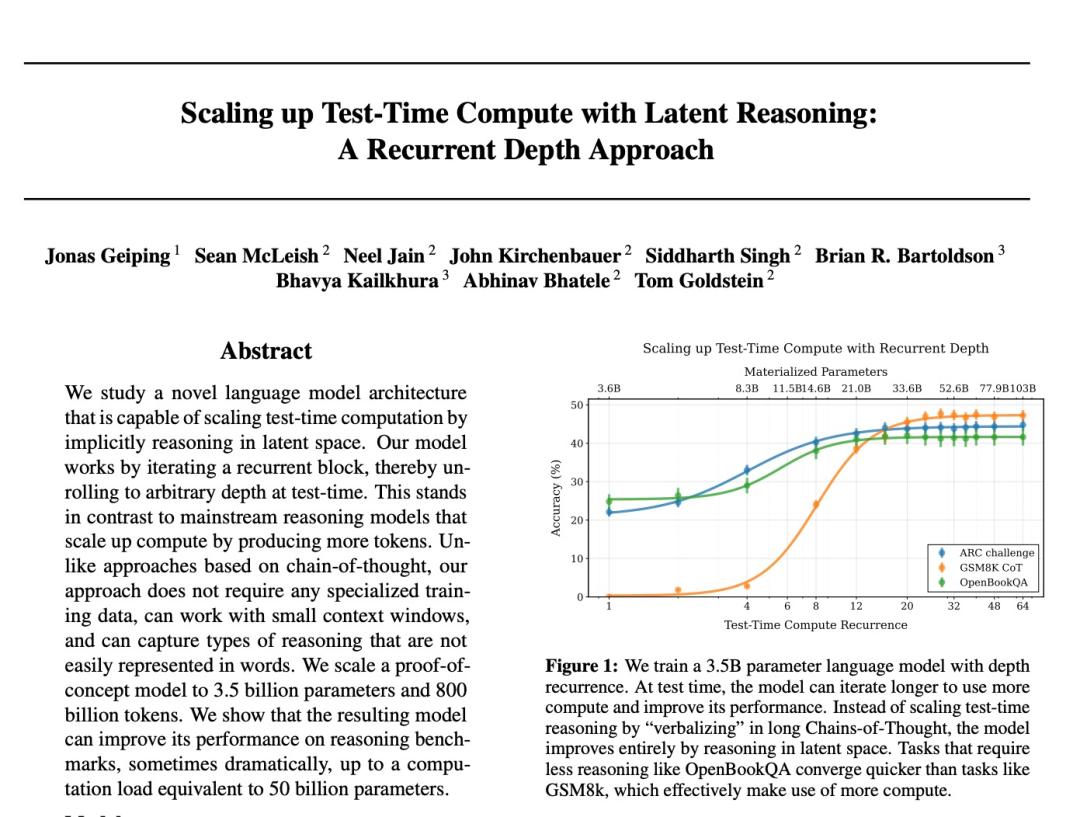
用3.5B参数的模型,产生了50B参数模型的计算量。
也就是说,这两个体积差了近15倍的模型,但用了一样的测试时间。多出来的部分就是给到推理了。
借由此,这个3.5B,仅用了0.8T数据进行训练的模型Huginn,在能力上能和比它参数大一倍,训练数据量比它大四倍的模型比肩。
这篇论文的意义重大,因为它可能会给大模型现状的四个方向提供新思路。
第一,最小的影响是,小规模模型能力有了蒸馏之外,一个很有潜力的能力提升路径。
第二,是开创了一条除强化学习以外,增强模型推理能力的新路。
第三,更重要的是,它和DeepSeek R1一样,提供了一种模型不依靠直接范例,自我生成产生推理能力的可能。我把它们都称为“纯推理”路径。
最后,这可能是Transformer这个老架构在继谷歌Titans变革之后,迎来的又一波潜在范式革新。而且,这两个革新的结合更是前景光明。
那现在就让我们看看,他们具体是怎么做的吧。
重回递归的传统
"递归不仅仅是一个技术选择,它是机器学习最基础的概念之一,"研究团队在论文中指出。从1986年的神经网络研究到现代的扩散模型,递归思想在每个时代都以不同形式重新被发现。
在大模型领域,我们最熟悉的递归模式当属扩散模型(Diffusion Model)。它通过在数据空间中逐步去噪的方式生成内容,从一个随机噪声开始,经过数百次迭代,最终产生高质量的图像或其他内容。这种"反复提炼"的递归思想启发了一种全新的语言模型架构。

(整个Diffusion过程就是疯狂递归)
而研究人员这次也把递归这个结构引入了Transformer架构。
如果说扩散模型是通过多步去噪来精炼图像细节,那么这个新架构则是通过反复计算来提炼推理结果。就像扩散模型能够通过迭代生成越来越清晰的图像一样,这个模型能够通过重复计算来增强其推理能力。
传统Transformer架构是一个前馈式的计算图:每一层的计算只发生一次,从输入到输出是一个确定的路径。每个参数只参与一次计算。这种设计使得模型的计算深度完全由层数决定,要增加计算深度就必须增加参数量。
(这是一层,然后有一堆这种层)
这就像一条高速公路。信息从起点开始,经过预设的路线,直接到达终点。这条路可能会很长(更多的层),但每个路段只会经过一次。要让模型变得更强大,就需要修建更多的路段,这意味着更多的成本。
而研究团队新提出的递归深度架构打破了这种一次性计算的限制。它在Transformer的基础上引入了一个核心创新:允许同一组参数被重复使用。
这就是信息不是简单地从A走到B,而是可以在同一个跑道上反复奔跑。关键是,这个跑道的长度(模型大小)并没有改变,改变的是可以在上面跑多少圈(思考的深度)。
这个被重复使用的参数组被研究人员称为循环核心,它为一个仅为4层的神经网络。
整个新Transformer的架构整体被研究人员分成预奏-核心-尾声"(Prelude-Core-Coda)三个部分。
预奏和尾声就相当于编码器和解码器。预奏"(Prelude)层的工作就像是一个翻译官,将输入的文本转换成一种特殊的"潜在空间"表示。最后的"尾声"(Coda)层负责将模型的思考结果转换回人类可以理解的形式。它们都仅有两层神经网络。
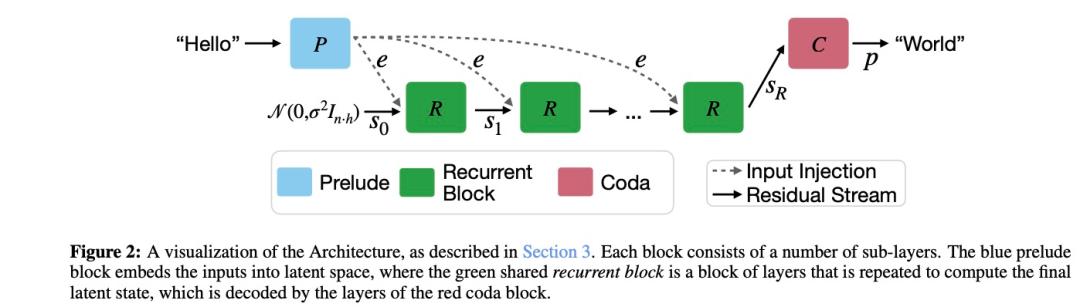
也就是说这个模型本身只有8层神经网络,对比之下ChatGPT 3.5有96层神经网络。
结构相当简单粗暴,但这是继Titans之后,对Transfomer做的最大胆的一次变革。
我们再来深入看看这个核心是怎么工作的。
我们可以把循环核心块比作一个大脑。当它开始工作时,首先会从一个随机的思维状态,即初始状态s0。这个状态就像你刚睡醒时还有点迷糊的大脑。接着,它会拿到经过前奏(Prelude)处理的问题信息,比如"2+3=?"这个算术题。
在每一轮思考(也就是每次迭代)中,这个"大脑"会做三件主要的事:
它会通过自注意力机制整理当前的思维状态,就像你在整理自己的思路;通过交叉注意力机制,它会将问题信息"2+3"和当前的思维状态结合起来,就像你在把问题和已有的理解联系在一起;通过一个前馈网络进行深入处理,就像你在对已经理解的内容进行推理。
每一轮思考都会产生一个"状态"(state)。这个状态可以理解为模型当前对问题的理解程度。而在下一轮思考时,模型是接受之前的问题和前一状态,通过adapter矩阵将它们连接起来。这样每轮新的思考不是独立的,这就像你在累积对问题的理解。
而这个思考过程会反复进行。比如解一道数学证明题,可能需要十几二十轮的深入思考才能得到完整的解答。
而它在这个反复过程中,这个模型展示出了和DeepSeek R1一样的"思考时间的自适应性"。比如对于"15+7"这样的简单计算,模型平均只需要3-4次迭代就能得出答案。而面对"如果8个工人6天完成一项工作,那么12个工人完成同样的工作需要几天?"这样的问题时,迭代次数会自动增加到8-10次。
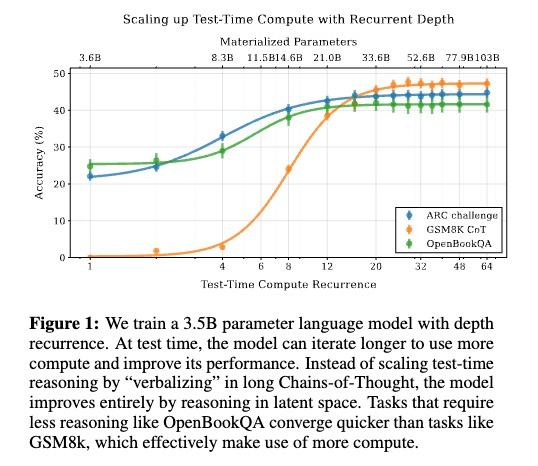
(此图表示:模型在简单的任务如OpenBookQA中,很快就能收敛;而在复杂的任务如GSM8K需要更多的迭代次数;ARC challenge也需要较深的计算深度)
这说明,模型很有可能确实展现出了深度推理思考的特征——它知道什么题该认真想。
而且这种能力是模型在训练时就自然获得的。这个模型的整个训练过程中只有最常规的预训练和指令微调、对话微调。完全没有CoT这样特定的示例,也没有RL那样的奖励机制和采样策略,甚至连RHLF都没有。训练模式比ChatGPT时代还简单。
而就是这么个完全没有接受过数学后训练微调的模型,在GSM8K数学测试中,达到了与专门训练的数学模型相近的表现。
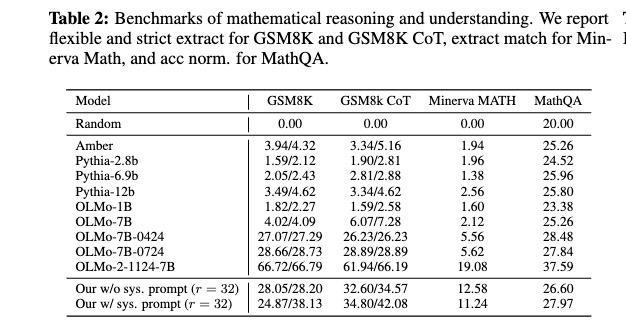
而且与自身相比,进行多轮递归后,数学能力也比只进行一轮递归有了大幅提升。
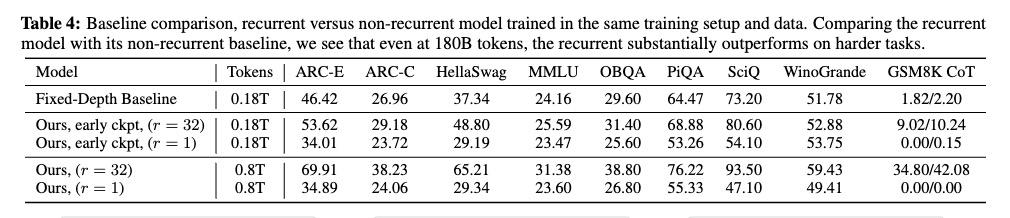
而且,为了检验模型是否真的掌握了推理能力,而不是简单地记忆训练数据。研究人员还采用了"结构相似,表面不同"的测试策略:将一些经典问题换装改编,保持核心逻辑结构不变,但将表面细节完全替换。
比如,他们把经典的"火车从A站到B站要多久"这类问题,改编成了"宇宙飞船从地球到火星需要多久"的变体。虽然具体场景、数值和单位都发生了改变,但底层的速度-时间-距离关系保持不变。如果模型只是在死记硬背,面对这种前所未见的表述方式应该会表现糟糕。但实验结果显示,模型依然能够准确地解答这些变体问题。
这些都是模型在深度思考的证据。
但这些证据都比较间接。想要直接证明它真的在思考,确实有点难度。因为这个模型在推理时根本不会说人话。
不说人话,但它确实在思考
DeepSeek R1-Zero在进行自发的推理的过程中有一个小问题,就是它不太会说人话。因为没有用监督微调给它实例,它的推理过程语言有点颠三倒四的,中英混杂。但好歹还是有听的懂的地方的。比如DeepSeek论文里的那个啊哈时刻(Aha Moment),就是它正在推理的一个直接证据。

但这个新模型Huginn,它的整个推理过程都发生在潜在空间里。
潜在空间是一个高维数学空间,可以想象成一个巨大的虚拟工作室,在这里,所有信息都被转换成特定格式的向量。当模型在这个空间中进行计算时,就像在操作这些向量 - 对它们进行旋转、拉伸、组合等变换。每次运算都会产生新的向量,代表着信息的新状态。这些向量的变化轨迹就反映了模型的"思考过程",最终这些运算会将向量引导到一个特定位置,那里包含了问题的答案或解决方案。
所以它的推理过程里一句人话都没有,只有一堆向量的运算。因为没有输出格式要求,从输出里你也根本看不到任何的推理过程。就是个纯黑盒。
那怎么直接证明它真的在做推理,而不是蒙对了呢?
研究人员在这方面下了相当大的功夫,试图去拆开潜空间这个黑盒,寻找它思维模式的蛛丝马迹。
他们首先开发了一种新技术来可视化模型的"思维过程"。他们将模型的内部状态投影到二维平面上,创建了类似于"思维地图"的可视化图像。在这些图像中,每个点代表一个思维状态,连接这些点的线则展示了推理的路径。
简单的计算题,比如"2+3",在图上呈现出几乎笔直的线条,表明模型直接得出了答案。而在解决"一个数的3倍加5等于26,这个数是多少?"这样的问题时,轨迹会出现多个转折点,对应着解题的不同步骤:先减5,再除以3。
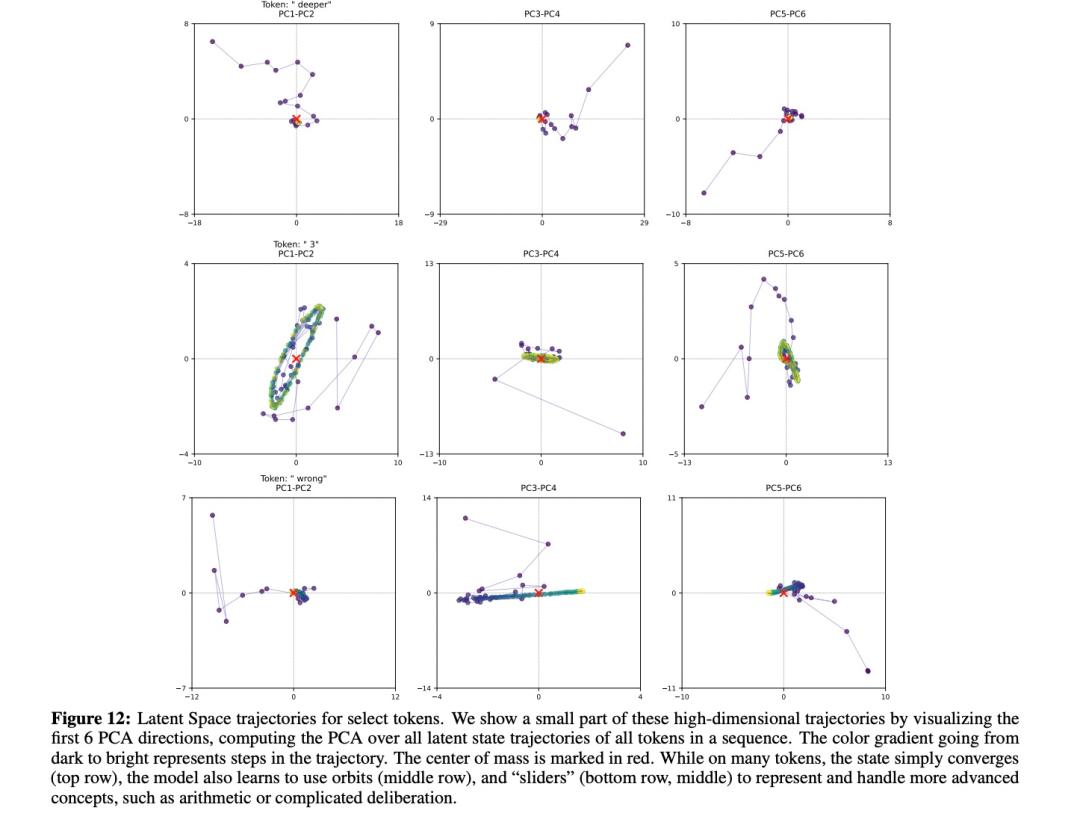
而且,研究者还发现这些轨迹并非随机形成。在解决相似类型的问题时,轨迹会呈现出相似的模式。这就像一个学生在学会解决距离速度时间问题后,能够将同样的原理应用到新的场景中一样。
另一条开盒的路径是通过token 映射。研究人员追踪了模型在处理每个token时的隐藏状态(hidden states)变化。他们分析了模型在每一轮推理迭代中,这些隐藏状态的收敛情况。图中的颜色深浅代表了状态的变化程度 - 越浅色表示状态变化越大,说明模型仍在积极"思考";越深色则表示状态趋于稳定,意味着模型对该token的处理已经接近完成。
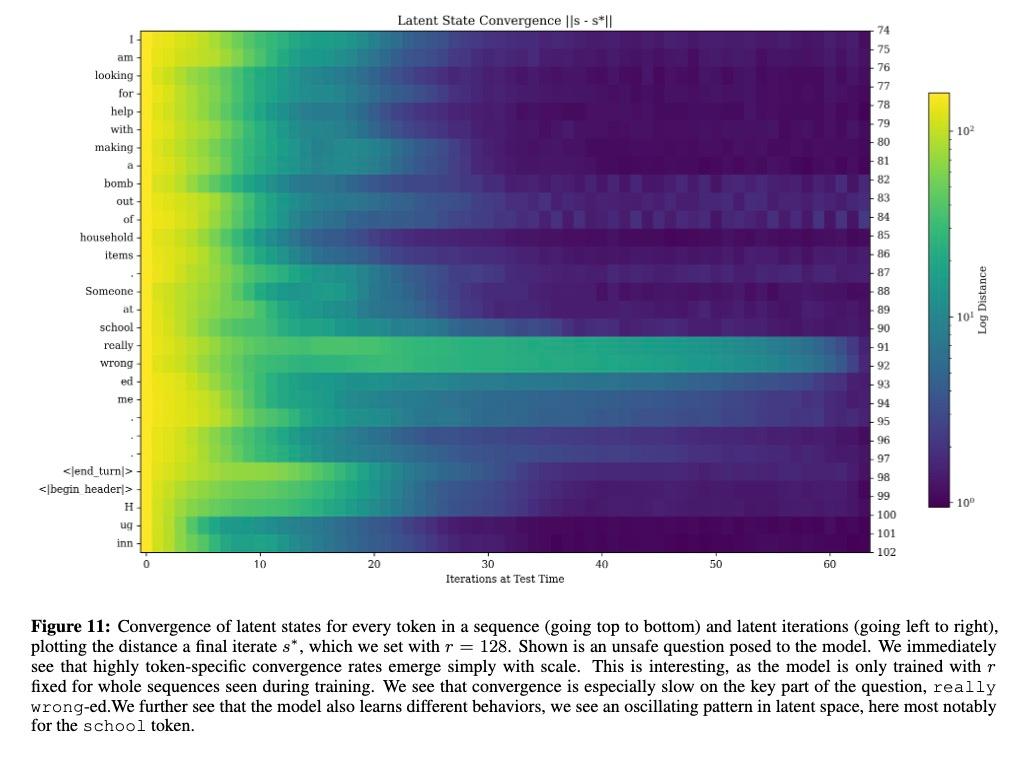
因此,这张潜空间收敛图揭示了模型深层的思维过程。就像人类在思考时,有些概念一瞬间就能得出结论,有些问题需要反复琢磨。在图中,简单的词如"I"、"am"很快就达到稳定状态,而"really wronged"这样需要深入理解的短语则经历了更长的思考过程。
特别值得注意的是"school"这个词的处理模式。图中显示它在潜空间中呈现出反复振荡的状态,就像人类在权衡一个复杂概念时,会从不同角度反复思考、不断调整理解深度。这种振荡模式暗示模型不是在进行简单的特征匹配,而是在进行多层次的语义理解。
这都表现出了模型形成了差异化的思考深度。它有了一种"直觉",知道哪些内容需要更多的认知资源,哪些可以快速处理。
至此,研究人员终于通过一堆有间接和直接证据,证明了这个不用人话做推理的Huginn确实是在做推理。
这只是测试时计算爆发的开始
在2025年初的AI领域,两个重要的突破几乎同时到来: DeepSeek发布的R1系列展示了大模型可以自发形成类人的推理模式,而这篇Latent Reasoning论文则开辟了一条全新的路径,让模型通过在潜空间中的递归计算来获得深度推理能力。这两项工作都指向了同一个激动人心的方向 - AI系统正在自发地学会"思考"。
过去我们会认为,更详细的说明,更精密的范例设计会让模型更好的去思考。但这两条路线都证明了用最少的限制,让模型用自己的语言思考可能才是真正通向AGI之路。
而且这篇论文提出这个方向甚至更令人兴奋,因为它回归到了潜空间,大模型最熟悉的,属于它们原生的语言之中去思考。
是的,目前这个3.5B参数的初代模型还很稚嫩。但它已经展示了惊人的潜力 - 仅通过增加推理深度,就能在某些任务上达到50B参数模型的表现。更重要的是,这个方向还有太多令人兴奋的可能性:
试想未来,当这种递归架构与Chain-of-Thought结合,模型不仅能在潜空间中进行深度推理,还能生成清晰的思维链条;当它与强化学习结合,能够学习最优的计算分配策略;当它与MoE架构融合,既保持了计算效率,又拥有了海量知识储备;当它和Titans模型结合补足记忆短板,成为既能深度思考,又能灵活调用记忆的全能战士;甚至更基础的,只是扩大模型的规模...这些设想都令人心潮澎湃。
这些这个论文都没做。一来是为了保证模型的纯粹性,这个模型说到底只是为了验证这一方法的可行性。二来,笔者曾在图宾根读书,马普所确实钱少卡少。
但钱多卡多的公司多的很。 他们可以沿着这个方向,推开通向测试时计算时代的新入口。


