

Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。
上海交通大学等团队提出Toca(Token-wise Caching),相关论文已被ICLR 2025接收。

Diffusion Transformer在图像和视频生成中展现了显著的效果,但代价是巨大的计算成本。
为了解决这一问题,特征缓存方法被引入,用于通过缓存前几个时间步的特征并在后续时间步中复用它们来加速扩散Transformer。
然而,之前的缓存方法忽略了不同的token对特征缓存表现出不同的敏感性,而对某些token的特征缓存可能导致生成质量整体上高达10倍的破坏,相较于其他token。
Toca团队提出了基于token的特征缓存方法,允许自适应地选择最适合进行缓存的token,并进一步为不同类型和深度的神经网络层应用不同的缓存比率。
通过在PixArt-α、OpenSora和DiT, 以及FLUX上的广泛实验,团队证明了在图像和视频生成中无需训练即可实现团队方法的有效性。例如,在OpenSora和PixArt-α上分别实现了2.36倍和1.93倍的接近无损的生成加速。
背景 Backgrounds
扩散模型(Diffusion Models)在图像生成、视频生成等多种生成任务中展现了出色的性能。近年来,以FLUX, Sora, 可灵等模型为代表的 Diffusion Transformers 通过扩展参数量和计算规模进一步推动了视觉生成领域的发展。然而,Diffusion Transformers面临的一个重大挑战在于其高计算成本,这导致推理速度缓慢,从而阻碍了其在实时场景中的实际应用。为了解决这一问题,研究者们提出了一系列加速方法,主要集中在减少采样步数和加速去噪网络模型。
近期,基于特征缓存来实现去噪模型加速的方法由于其优秀的无损加速性能,以及无需训练的优良性能,受到工业界的广泛关注。上海交通大学张林峰团队进一步注意到一个自然而有趣的现象:不同计算层,以及同计算层的不同 Token 对于缓存误差的适应性不同,同样的缓存误差在不同位置对模型影响最高可以达到数十,百倍的差异,因此有必要进一步将模型加速的粒度由特征级进一步到 token 级,并考虑了如何衡量视觉生成模型中 token 的重要性,以实现重要 token 的筛选保留。
核心贡献
ToCa首次在DiT加速中中引入 token 级的缓存复用策略,并首次从误差积累与传播的角度分析特征缓存方法。
ToCa提出4种从不同角度出发,适用于不同情形的token selection策略:
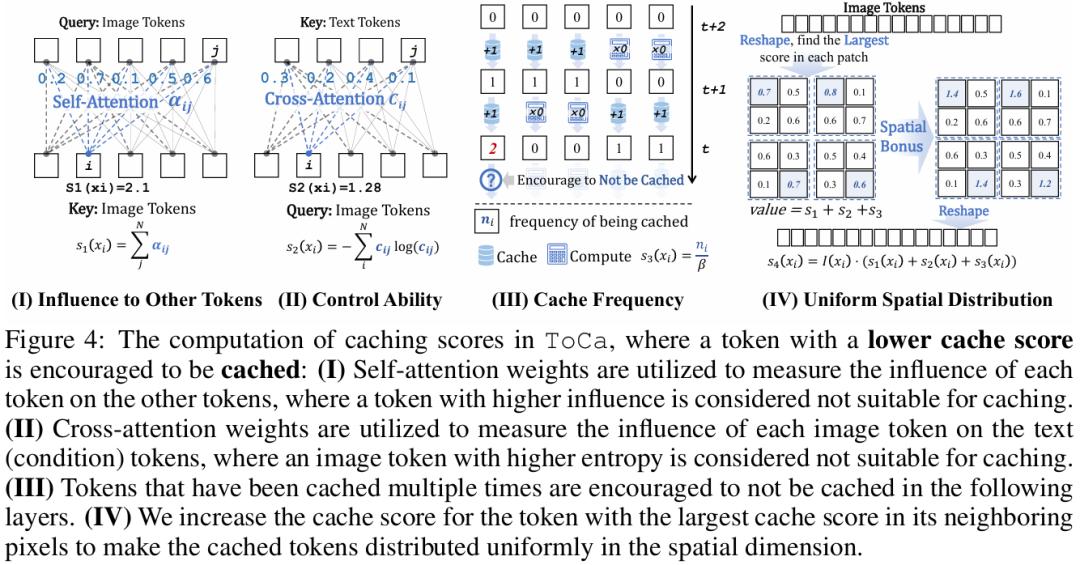
基于Self-Attention Map来评估token对其它token的影响;
基于Cross-Attention Map评估文生图/视频任务中 image token 对 text token的关注分布,以加强控制能力;
基于该 token在先前去噪步中的被连续缓存复用的次数设计增益策略,鼓励token在时间步上被更均匀地计算,避免局部误差积累过大,破坏全局图像;
将各个token的重要性得分基于空间分布进行加权,鼓励被计算的token在空间上分布更均匀。
ToCa被应用于多种最新模型上开展实验,证明了其相比现有方法更加优秀,包含文生图模型PixArt-alpha,FLUX-dev和FLUX-schnell,文生视频模型 OpenSora,以及基于ImageNet类标签生成图像的DiT模型。
研究动机
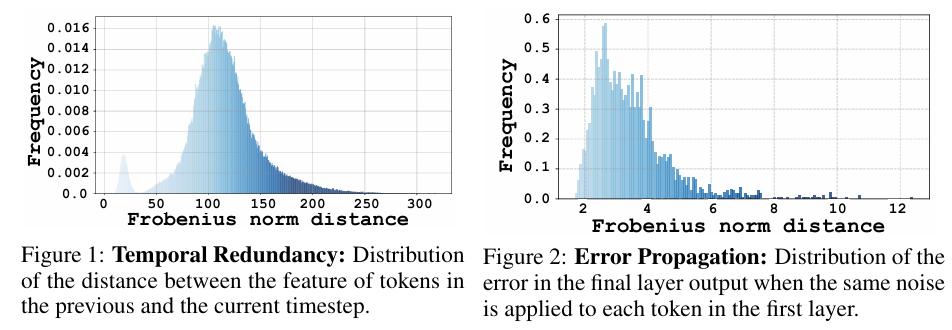
如图1所示,不同token在相邻两步间进行特征缓存引入的误差值的差异高达几十上百倍;
图2说明不同token上引入同样大小的误差,这最初幅度相同的误差在模型推理过程经过积累和传播,对模型的输出的影响差异也极大。因此,有必要考虑token级别的特征缓存-复用策略,使得模型的计算更集中在关键被需要的token上。
方法
计算流程
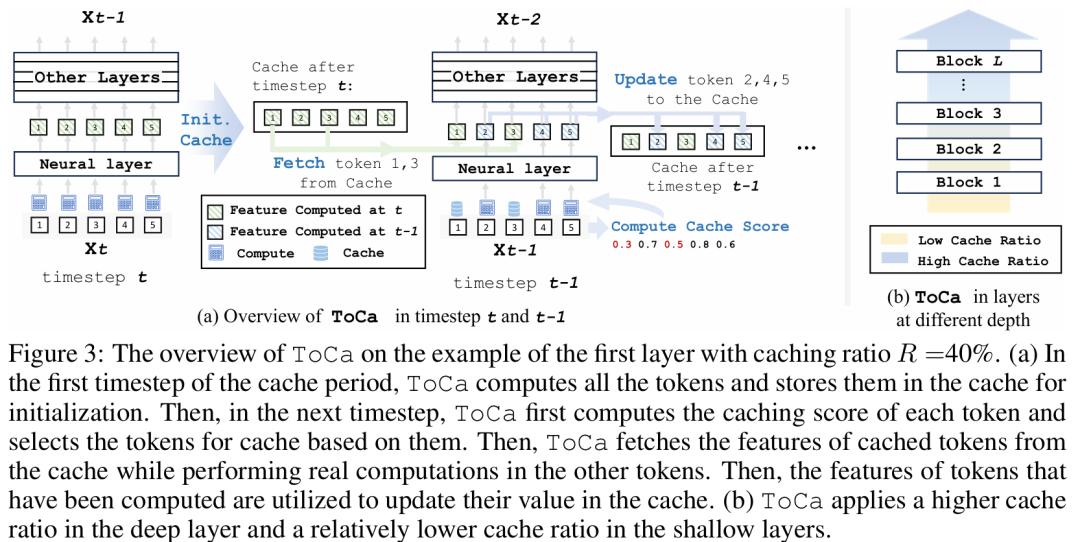
ToCa的缓存-复用流程如图3(a)所示:
Cache 初始化 首先推理一个完整的时间步,将各层的特征放入cache中以便使用。
重要性得分计算在使用ToCa的时间步上,对于每一层:先计算各个token的重要性得分,将最低的部分token 标记为cache状态(例如图示中ID为1和3的token),不传入网络层进行计算。
部分计算对于被传入的token(2,4,5),执行正常的计算,得到它们的输出。
Cache更新从cache中调出存储的 token 1,3的输出,并将计算得到的新的token 2,4,5输出更到cache中。
通常这样的一个循环长度为2~4个时间步,即1步充分计算后续搭配1至3个ToCa step。此外,ToCa还基于不同层的重要性,设计了随着层深度上升而衰减的计算比例,详情请参考论文。
重要性得分计算
如图4所示,ToCa设计了基于4个不同方面考虑的重要性分数计算,在实际应用中它们以 加权求和给出总的重要性得分,详情请参考论文。
实验结果
ToCa被应用于文本到图像生成模型 PixArt-alpha, FLUX, 类到图像生成模型 DiT, 以及文本到视频生成模型 OpenSora以验证其方法有效性,充分的实验结果证明,ToCa具有超越其他同类方法的加速效果。
图像生成模型: PixArt-alpha,FLUX, DiT

如上图所示,ToCa相比另两种加速方法和无加速的高质量原图对齐效果更佳,且具有更佳的图-文对齐能力(例如从左到右第四列的wooden dock)。
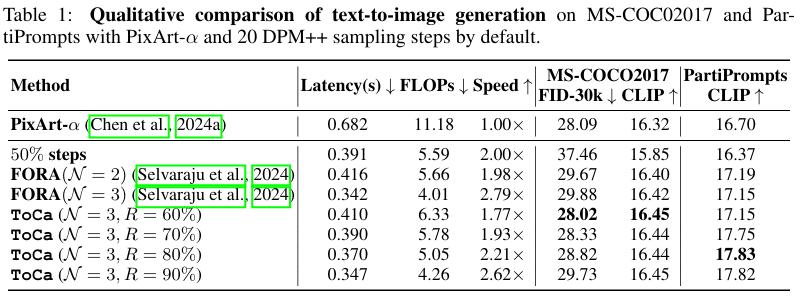
从FID-30k和 CLIP Score上衡量,ToCa也取得了远超其他方法的表现。

如上图所示,ToCa在FLUX 模型上的生成质量也极佳,可以看到和原图基本没有差异。但值得考虑的是在文字生成这类对细节要求极其高的任务上(例如左下角的地图)仍有差异,这将作为团队后续研究的出发点。
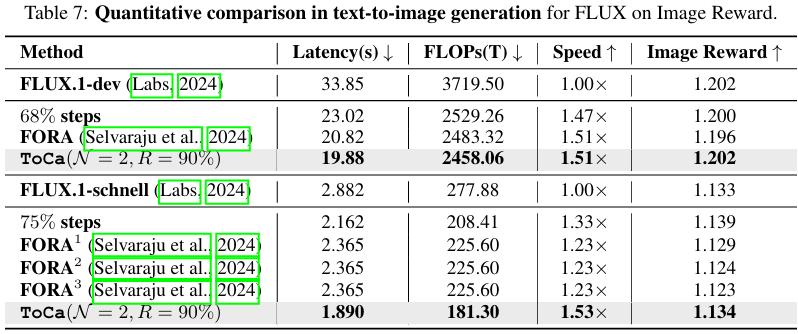
对于高级的模型,使用Image Reward通常能更好地对生成质量进行衡量,团队分别在50step的FLUX-dev和4step的FLUX-schnell上开展了实验,可以看到,ToCa在FLUX上1.5倍加速,相比未加速模型的数值指标基本不变,远远优于其他方法。
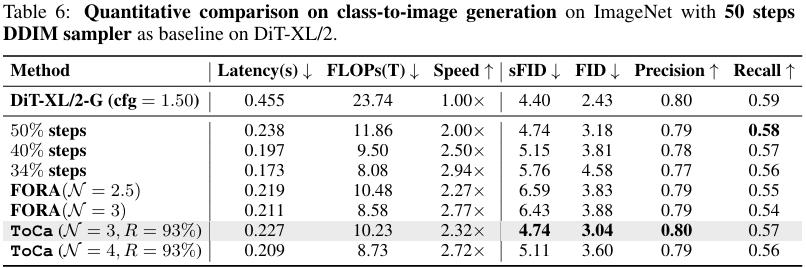
在基础模型DiT上的结果也证明了ToCa的优越性。
视频生成模型:OpenSora
团队制作了一个网页来展示OpenSora上的加速效果。
https://toca2024.github.io/ToCa
此外,团队将视频生成结果部分抽帧以供快速浏览:


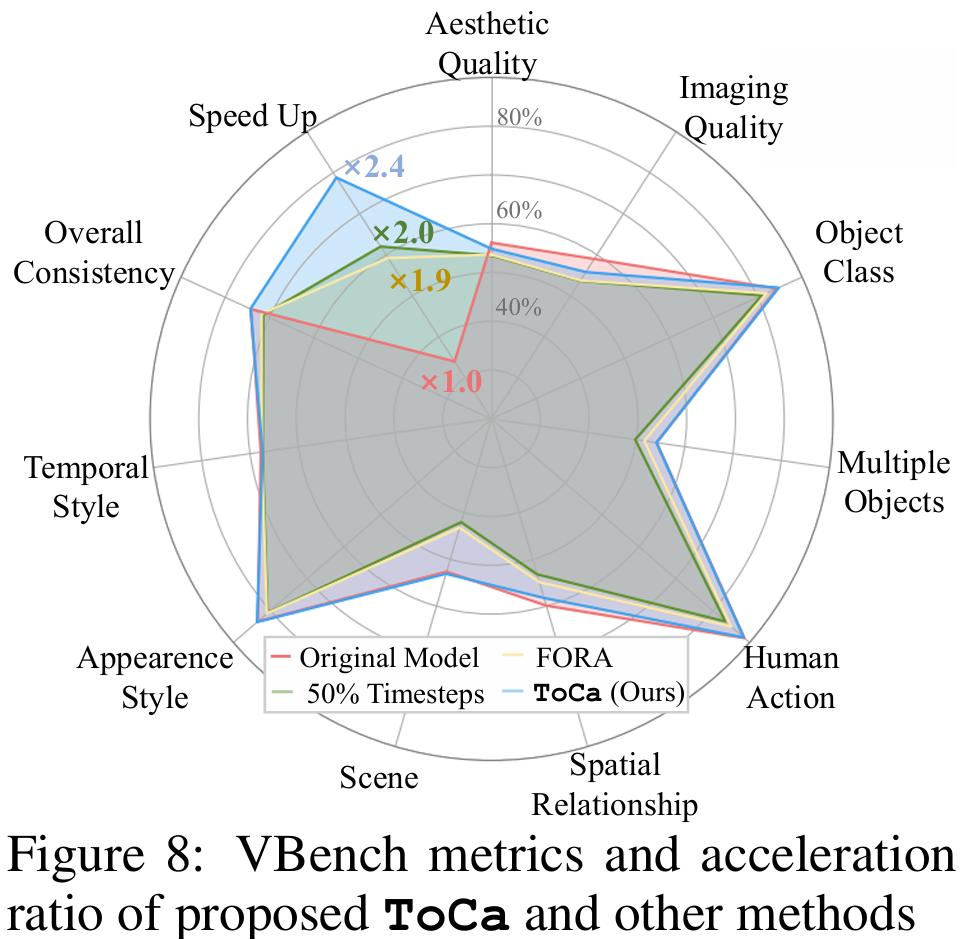
在VBench上测试ToCa的加速效果,实验结果表明,ToCa远优于其他方法,取得了高达2.36倍的无损加速, 在加速效果和生成质量上都取得最优表现。
ToCa在VBench的大部分指标上都取得了和原模型几乎相同的得分。
总结
ToCa作为首次被提出的从Token级来实现扩散模型加速的方法,相比以往加速方法具有更强的适配性,(尽管设计时作为专为DiT加速的方案,它的结构也可以被复用到U-Net结构的模型上),同时在多种任务上具有极佳的表现。近年来,包括ToCa在内的系列基于特征缓存的扩散模型加速方法兼具无需训练的优越性和强劲的无损加速效果,取得了卓越的成效,是一种不同于蒸馏类方法的值得被进一步探索的加速方案。
论文:https://arxiv.org/abs/2410.05317
Github:https://github.com/Shenyi-Z/ToCa


