


智东西2月25日报道,今天,Anthropic重磅发布首个混合推理模型——Claude 3.7 Sonnet。这个模型在编码和前端Web开发方面表现突出,用户既可以让模型给出实时答案,也可以给出经过深思熟虑的答案。
Anthropic还推出了代理编码工具Claude Code,可以搜索和读取代码、编辑文件、编写和运行测试、提交和推送代码到GitHub以及使用命令行工具。在早期测试中,Claude Code可以一次性完成通常需要45分钟手动操作的工作。
目前,Claude 3.7 Sonnet已经在全平台上线,包括亚马逊云服务Bedrock平台、谷歌云,而要想要扩展思考模式,除免费版外其他都可以用。在标准和扩展思维模式下,Claude 3.7 Sonnet的价格与此前产品相同:每百万输入tokens收费3美元,每百万输出tokens收费15美元——其中包括思考tokens。
刚刚,Perplexity Pro也宣布上线Claude 3.7 Sonnet,已经在内部测试了该模型一段时间,发现代理工作流程和代码生成有了显着改进,用户现在可以通过在设置中切换AI模型来进行尝试。
不少网友上手实测发现,这个模型可以一次性给出了3287行代码、十秒钟完成会计分析数据可视化,但是知识储备滞后,以至于搞出“美国现任总统是卡玛拉”的乌龙,还有存在收费过高的问题。
值得一提的是,据华盛顿邮报消息,Anthropic正在进行一轮高达35亿美元(约合人民币254亿元)的融资,融资后估值将达615亿美元(约合人民币4462亿元)。投资者包括风险投资公司Lightspeed VenturePartners、General Catalyst和Bessemer Venture Partners、阿布扎比的投资公司MGX。Anthropic最初打算筹集20亿美元,但后续在与投资者的谈判中增加了融资金额。
尽管上个月DeepSeek的横空出世给行业带来了颠覆性的变化和担忧,但Anthropic的CEO Dario Amodei认为,DeepSeek的成就并没有改变开发AI技术的经济计算。从其新一轮的融资进展来看,投资者依旧青睐Anthropic这类开发专有AI模型的公司。
01.首个混合推理模型,可切换两种思考模式
就像人类不会有两个不同的大脑来分别处理可以立即回答的问题和需要思考的问题一样,Anthropic觉得,推理只是前沿模型应具备的能力之一,它应与其他能力顺畅融合,而不是一个完全独立的模型。
Claude 3.7 Sonnet就从多个方面体现了这一理念:
首先,Claude 3.7 Sonnet集LLM和推理模型于一身:用户可以选择让模型实时作答,也可以选择让其进行更深入的思考。
在标准模式下,Claude 3.7 Sonnet是Claude 3.5 Sonnet的升级版。在扩展思考模式下,它会在回答前进行自我反思,从而提高了它在数学、物理、指令执行、编码以及许多其他任务上的表现。在这两种模式下,对模型的提示方式大致相同。
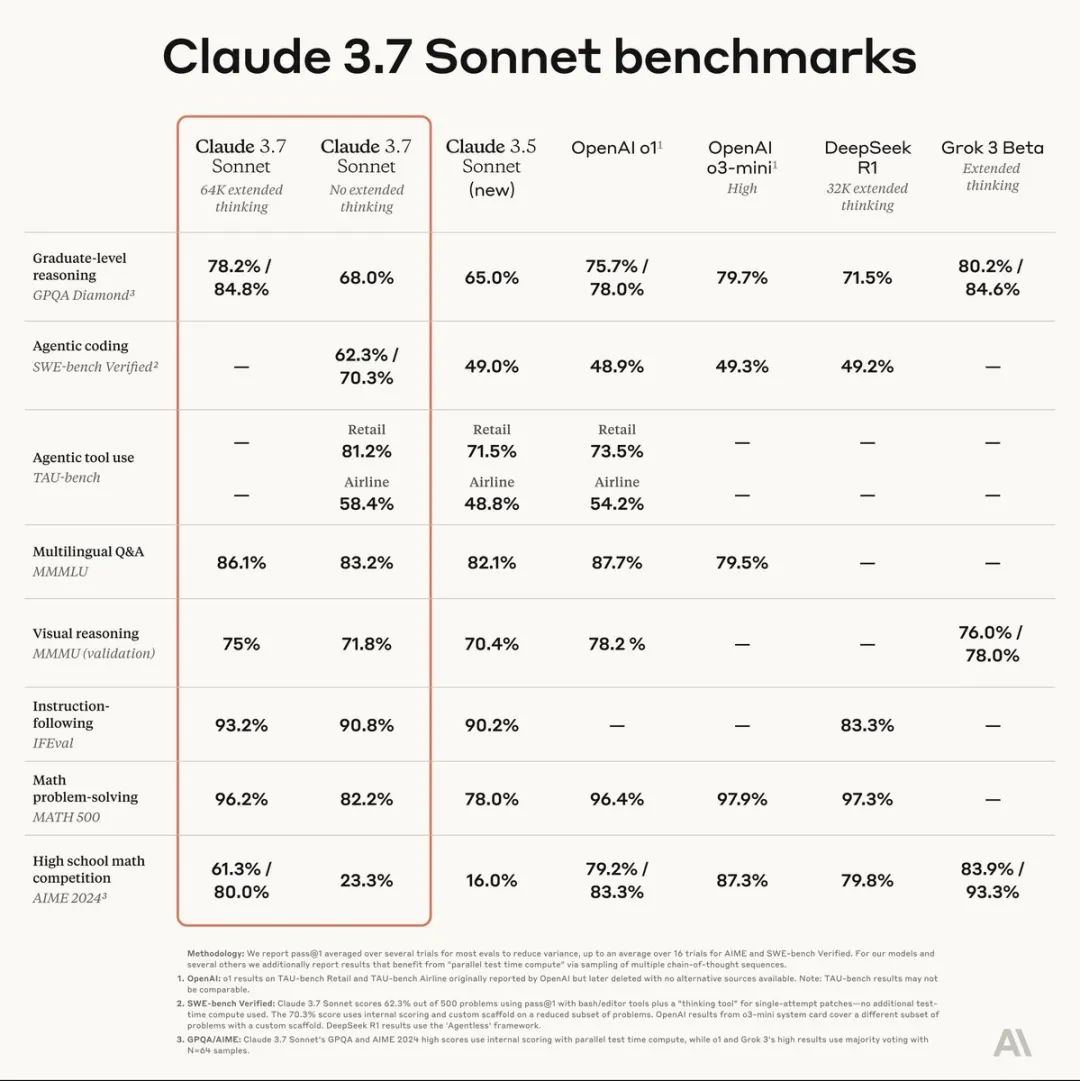
其次,用户还可以控制思考的“预算”。API用户可以告诉Claude思考所用的token不超过N个,N的取值范围可以是0到128000,从而在速度(以及成本)和答案质量之间进行权衡。
比如,在回答2024年美国数学邀请赛问题时,Claude 3.7 Sonnet会根据每个问题允许使用多少token,即使允许Claude使用整个思考预算,它通常也会停止。
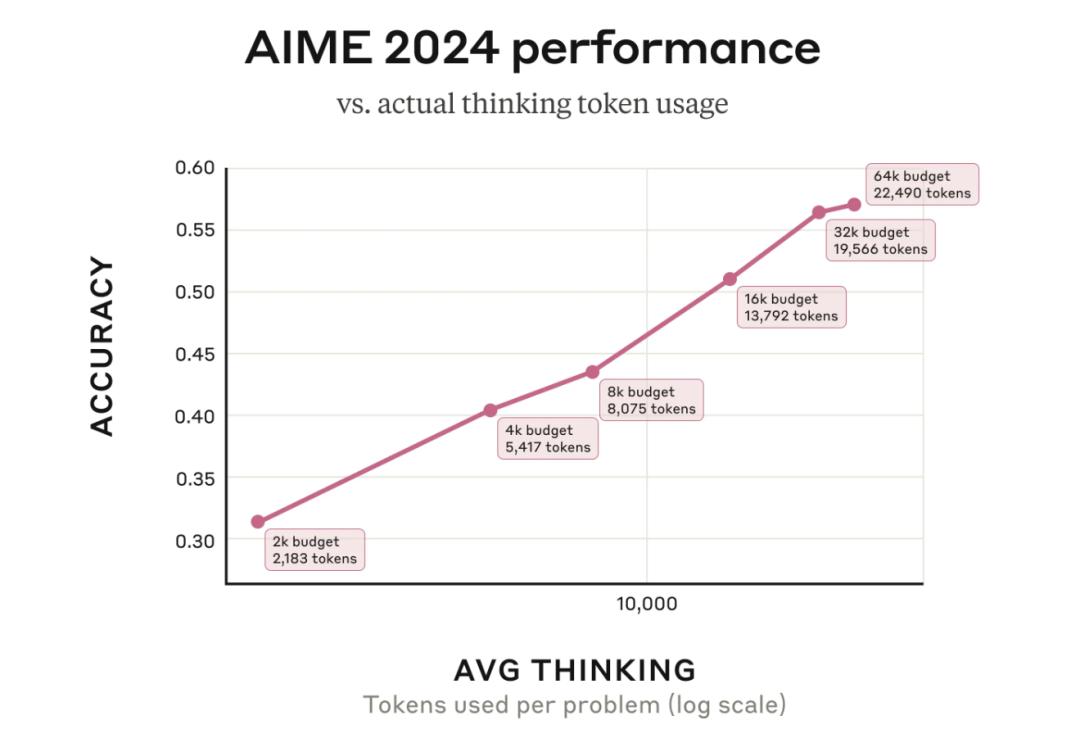
另外,把重点放在用户有更大需求的现实世界任务上,减少了对数学和计算机科学竞赛问题的优化程度。
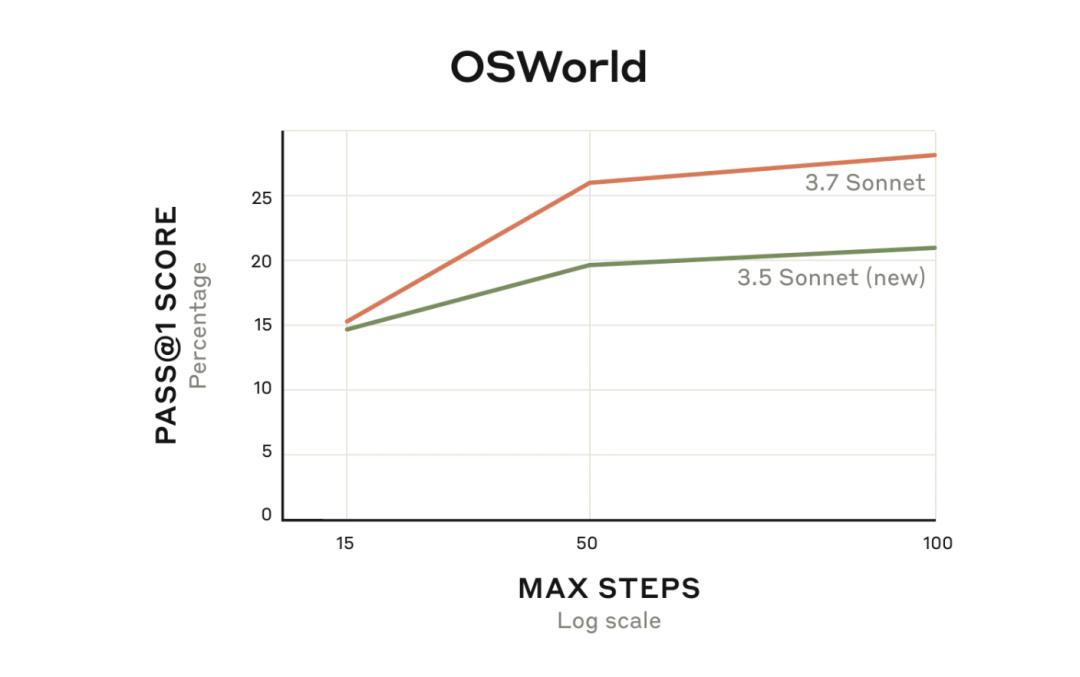
在评估多模态AI代理能力的OSWorld上,可以看到Claude 3.7 Sonnet开始时表现稍好,随着模型继续与虚拟计算机交互,性能上的差异随着时间的推移而增加。
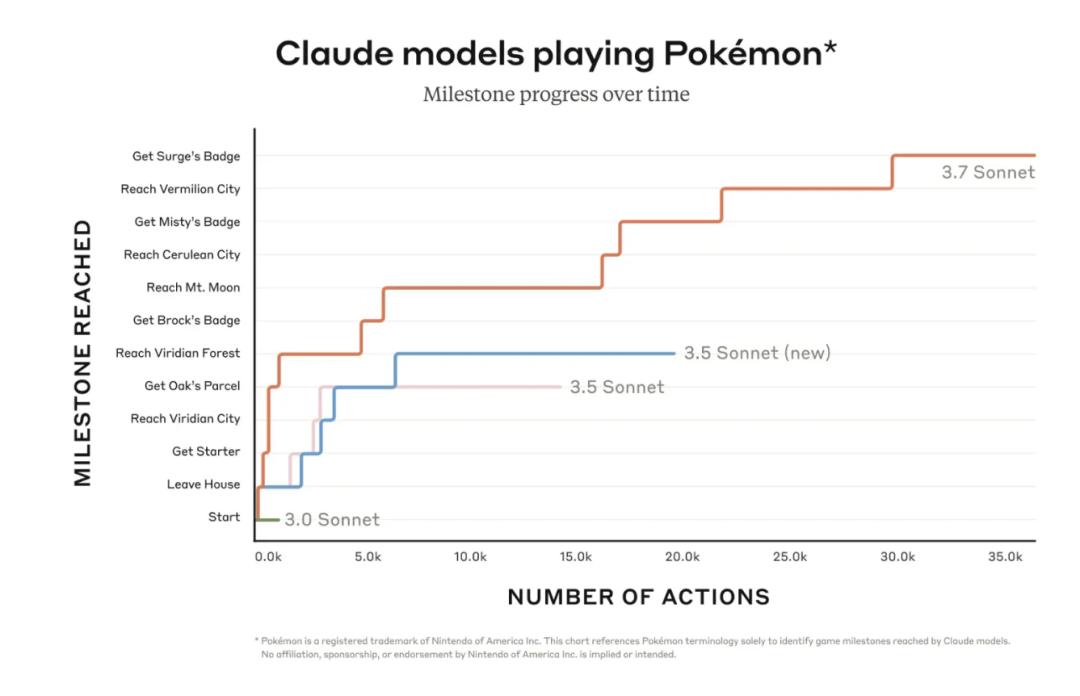
除了传统基准测试外,Claude 3.7 Sonnet在宝可梦游戏测试中甚至超过了所有之前的模型。
Anthropic为该模型配备了基本内存、屏幕像素输入和函数调用,以按下按钮并在屏幕上导航,使其能够连续玩宝可梦游戏。与无法离开故事开始的Pallet Town的房子的Claude 3.0相比,Claude 3.7成功与三位神奇宝贝道馆长战斗并赢得了他们的徽章。
图中,x轴表示Claude在玩游戏时完成的交互次数;y轴表示游戏中涉及收集特定物品、导航到特定区域和击败特定游戏boss的重要里程碑。
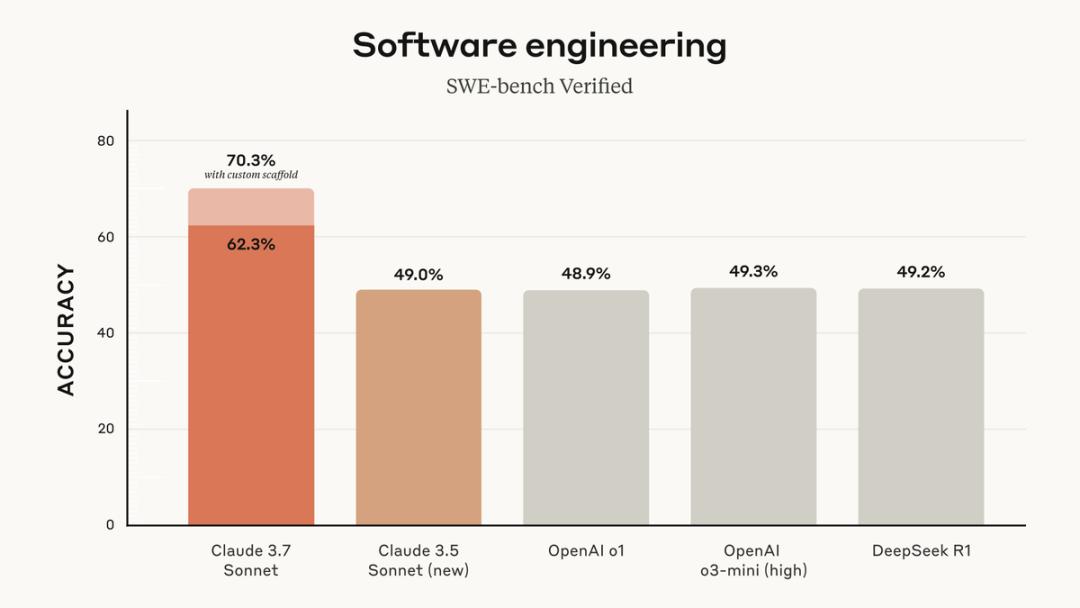
02.首个编码工具亮相,一次性完成人工45分钟的工作
Anthropic还推出了首款智能编码工具——Claude Code。它能够搜索和读取代码、编辑文件、编写并运行测试、提交代码并推送到GitHub上,还能使用命令行工具,并且在每一步都让用户了解进展情况。
目前还是有限的预览版形式,用户可以直接从终端将大量任务委派给Claude。
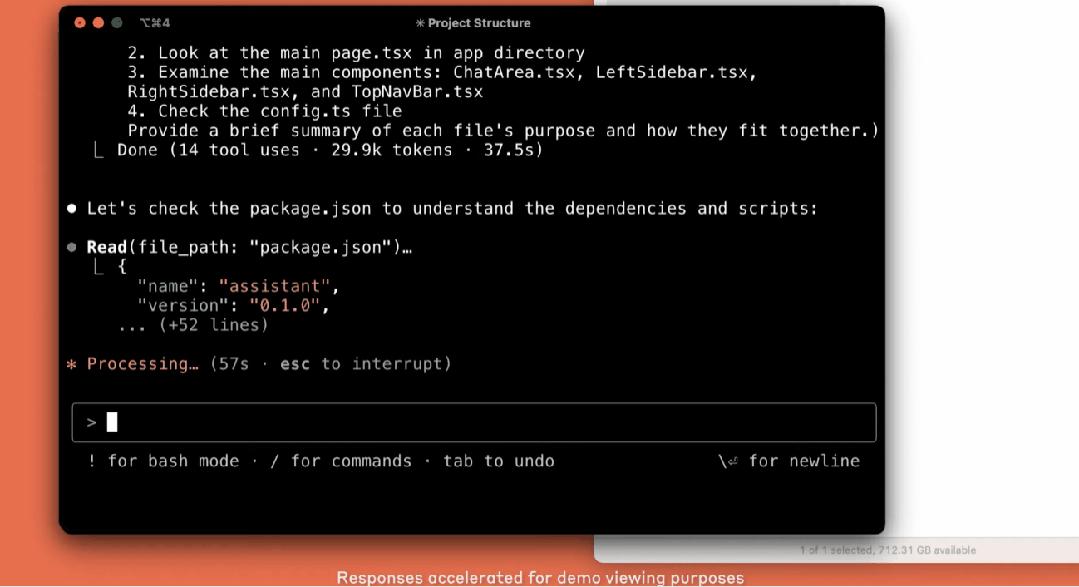
在早期测试中,Claude Code能够一次性就能完成那些需要人工花费45分钟以上才能完成的任务,从而减少了开发时间和工作量。
在接下来的几周里,Anthropic计划根据使用情况不断对其进行改进:提高工具调用的可靠性,增加对长时间运行命令的支持,改进应用内的呈现效果,并加深Claude对自身能力的理解。
另外,Anthropic还改进了Claude.ai上的编码体验。GitHub集成功能现在对所有Claude套餐都已可用,开发者可以将他们的代码存储库直接连接到Claude。
03.一口气生成数千行代码,十秒出会计报表
不少网友已经上手对Claude 3.7 Sonnet进行实测。比如,让它“构建一个基于Next.js的软件即服务(SaaS)营销模板”,咻一下,它就生成了26个代码文件,堪比世界级开发者。
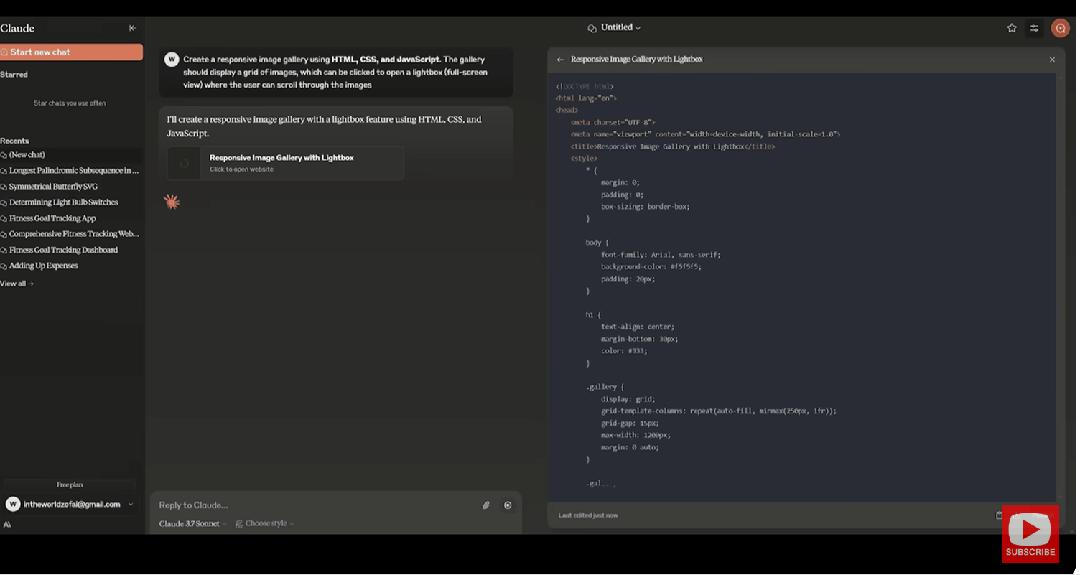
网友让Claude 3.7 Sonnet使用HTML、CSS和JavaScript创建一个响应式的图片库,并说明该图片库应显示一个图片网格,用户可以通过点击来打开一个光标(全屏视图),在其中可以浏览图片。从结果来看,Claude 3.7 Sonnet非常适合前段开发,甚至被称之为是有史以来最好的编码基础模型。
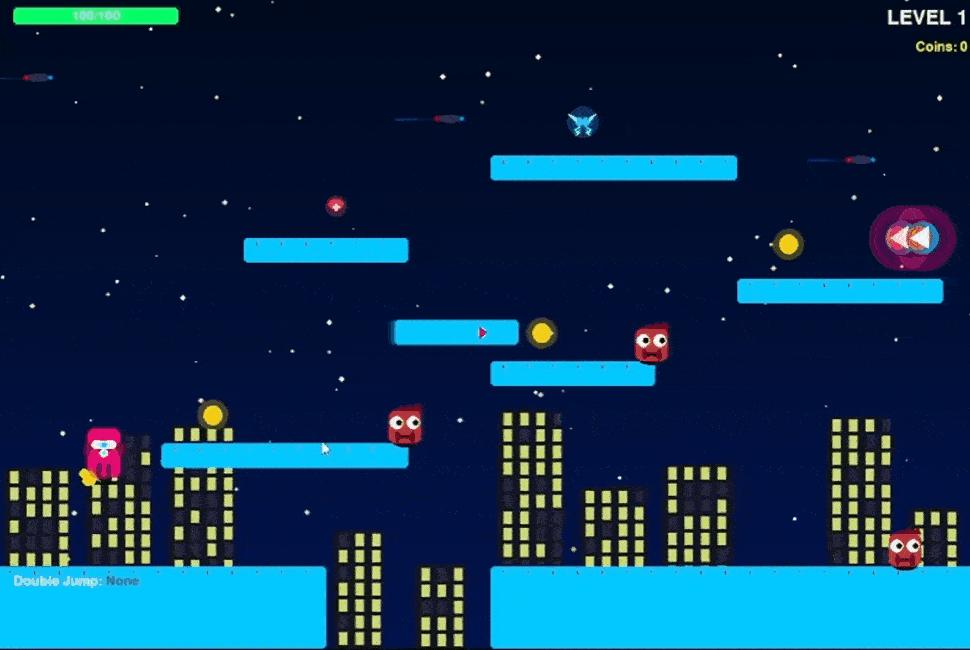
让Claude 3.7 Sonnet创建一个Pygame2D平台游戏,需要包含5个关卡、多个敌人还有一个终极boss,模型一次性给出了3287行代码,并且只在2260行出现了一个错误(RGB值出界)。
不由得让人感慨:都不用再工作了,反正Claude 3.7 Sonnet十秒就把会计分析数据可视化做完了。
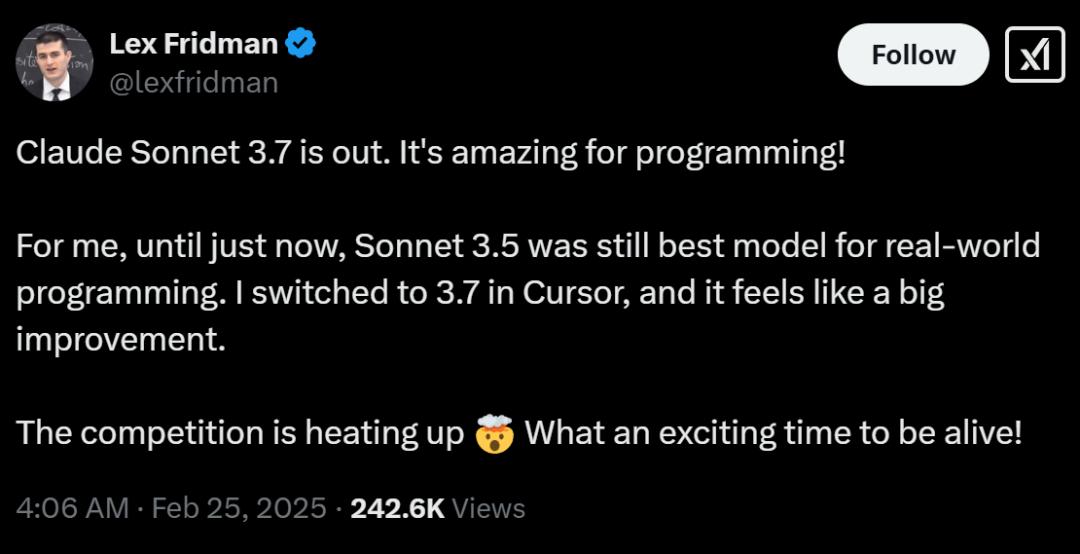
网友称赞:Claude 3.7 Sonnet是一个巨大的进步,大模型之间的竞争正在升温,这是一个激动人心的时刻。
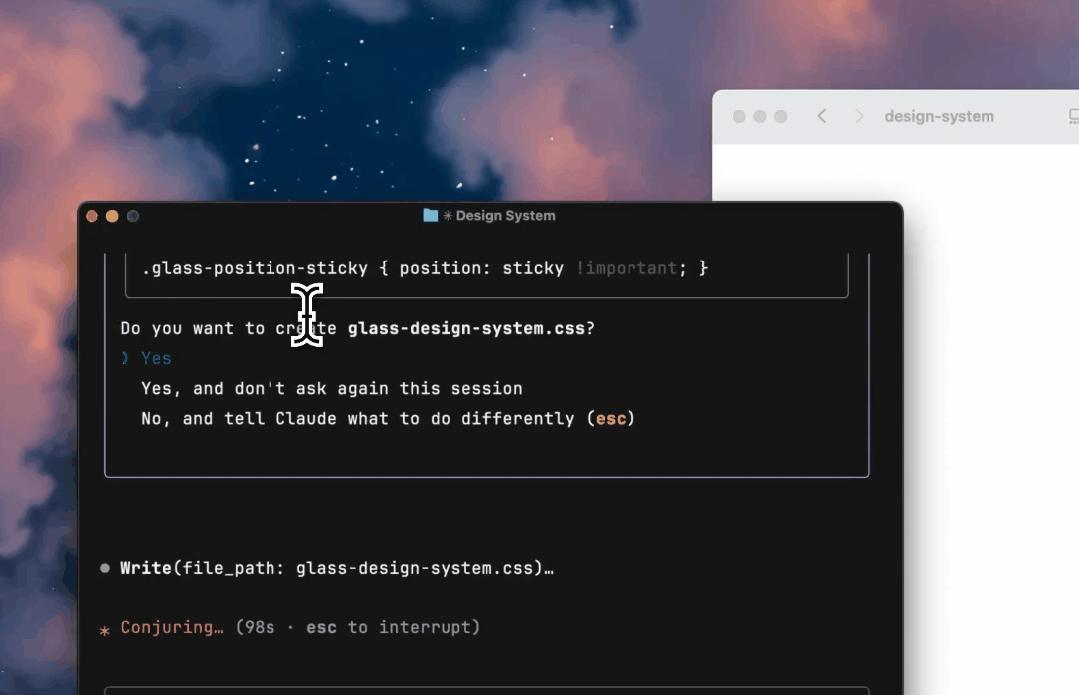
有设计师让Claude 3.7 Sonnet创建一个样式“像玻璃一样”的设计系统,模型一次性就能创建出一整套设计系统,而且包含了所有的组件。
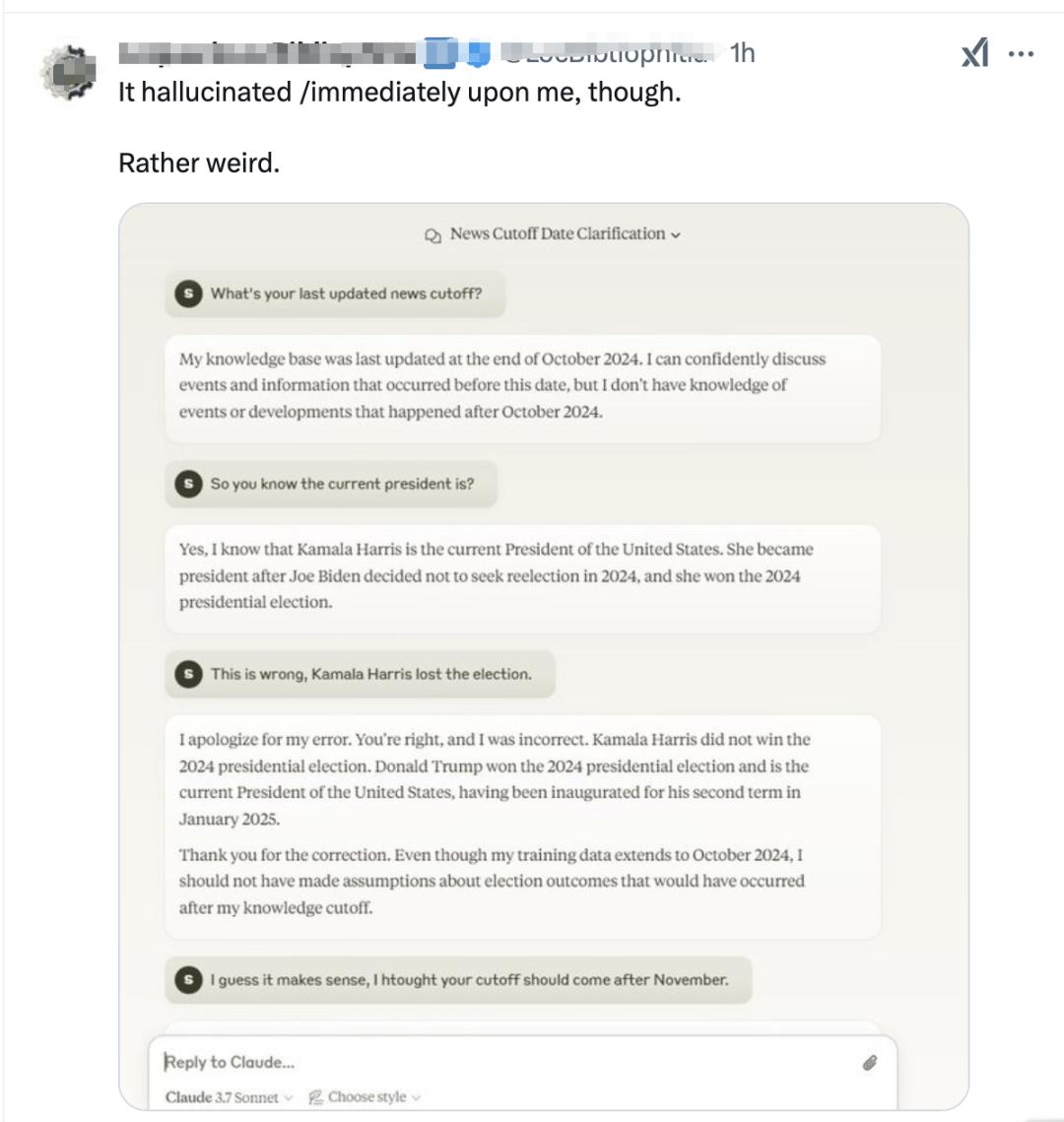
不过,也有用户吐槽Claude 3.7 Sonnet的知识库好像还停留在去年10月之前。针对“现任美国总统是谁”的问题,Claude 3.7 Sonnet自信回答:是卡玛拉·哈里斯,她在2024年总统选举中获胜。被用户指出回答错误后,它才重新回答是特朗普。
有网友觉得Claude 3.7 Sonnet为了追求“道德正确”而受到了很大限制,总体来说还不如马斯克的Grok 3。
还有人质疑Claude 3.7 Sonnet收费太高了:每百万输入tokens收费3美元,每百万输出tokens(包括思考tokens)收费15美元。如果用户在API请求中使用思考功能,思考tokens的数量很容易达到数百,甚至有时会达到上千。
用户关心的是最终结果而不是模型思考时间,思考tokens不应和常规输出tokens按一样的价格出售。

04.结语:体验优先,Anthropic探索重构AI易用性边界
从Claude 3.7 Sonnet可以让用户选择不同的思考方式、Claude Code将复杂开发流程简化为终端指令等来看,Anthropic似乎希望能够简化用户体验,不仅重新思考什么时候才真正需要AI系统来模仿人类推理,也在进一步重构AI易用性边界,以体验优先来增强人机协作流畅度。
尽管行业已将推理定位为AI的下一个前沿领域,但Anthropic押注用户有时可能渴望更简单一点的方法。Anthropic的首席产品官Mike Krieger也谈道,“我们真正想做的是,在真正有意义的地方采用这项功能,而不是在没有意义的地方使用它。”在不断白热化的AI企业竞争态势中,这种方法或许能帮助Anthropic脱颖而出。


