

IT之家 2 月 12 日消息,豆包大模型团队今日宣布,字节跳动豆包大模型团队提出了全新的稀疏模型架构 UltraMem,该架构有效解决了 MoE 推理时高额的访存问题,推理速度较 MoE 架构提升 2-6 倍,推理成本最高可降低 83%。该研究还揭示了新架构的 Scaling Law,证明其不仅具备优异的 Scaling 特性,更在性能上超越了 MoE。
实验结果表明,训练规模达 2000 万 value 的 UltraMem 模型,在同等计算资源下可同时实现业界领先的推理速度和模型性能,为构建数十亿规模 value 或 expert 开辟了新路径。
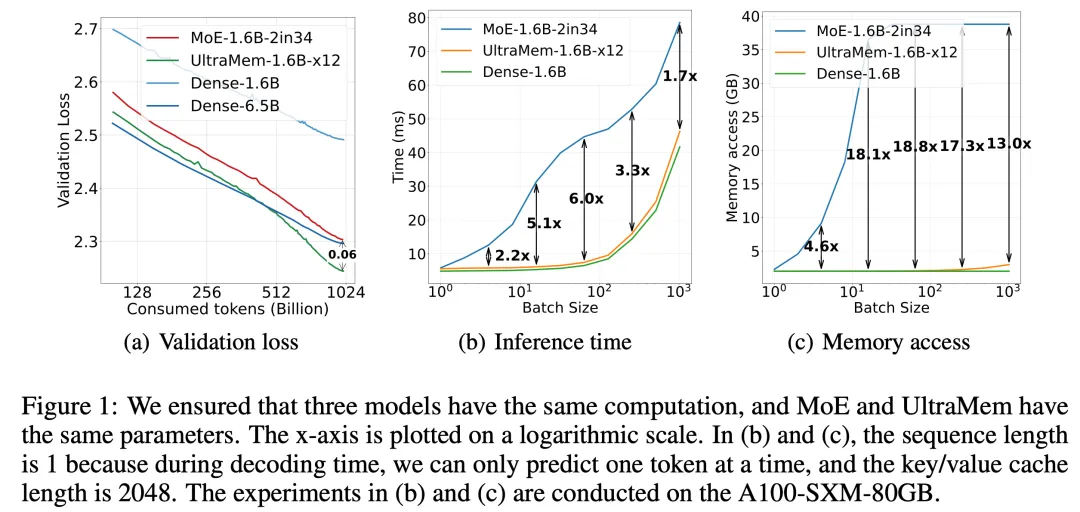
据介绍,UltraMem 是一种同样将计算和参数解耦的稀疏模型架构,在保证模型效果的前提下解决了推理的访存问题。实验结果表明,在参数和激活条件相同的情况下,UltraMem 在模型效果上超越了 MoE,并将推理速度提升了 2-6 倍。此外,在常见 batch size 规模下,UltraMem 的访存成本几乎与同计算量的 Dense 模型相当。
在 Transformer 架构下,模型的性能与其参数数量和计算复杂度呈对数关系。随着 LLM 规模不断增大,推理成本会急剧增加,速度变慢。
尽管 MoE 架构已经成功将计算和参数解耦,但在推理时,较小的 batch size 就会激活全部专家,导致访存急剧上升,进而使推理延迟大幅增加。
IT之家注:“MoE”指 Mixture of Experts(专家混合)架构,是一种用于提升模型性能和效率的架构设计。在 MoE 架构中,模型由多个子模型(专家)组成,每个专家负责处理输入数据的一部分。在训练和推理过程中,根据输入数据的特征,会选择性地激活部分专家来进行计算,从而实现计算和参数的解耦,提高模型的灵活性和效率。


