

DeepSeek的余波仍在大模型生态深处震荡。它将重新激活去年春季一度兴起的AI PC热潮。当时,这场产品革命的核心,就是面向规模市场,交付个人AI用户体验。如今,这两个目标已经不再遥远。
上线不足1个月,全球数千万用户都在抢着下载DeepSeek的移动应用。但它的官方服务,在国内面临算力短缺的瓶颈,在美国则面临着“下一个TikTok”的监管压力。中国与美国的云巨头正在将这个开源模型整合到自己的云平台上,动手能力较强的工程师与研究者开始尝试本地部署它的蒸馏模型。
设备厂商刚刚在CES上发布新品,与DeepSeek擦身而过,但高度开源的高性价比的推理模型,势必成为个人AI设备的新支点。
模型性能是本地推理的用户体验的关键。本地推理模型对于维护隐私、优化推理速度,以及在没有网络连接的情况下继续提供服务至关重要。无论是完全依赖本地算力,还是与云形成混合推理引擎,都依赖于部署的推理模型的性能的不断提升。应该说,AI PC在构建个人AI体验方面,最初并不理想。
艾伦人工智能研究所(Allen Institute for AI)科学家Nathan Lambert将DeepSeek的R1推理模型,称为ChatGPT时刻以来,第一个开源模型权重且采用商业友好许可协议、对下游应用无限制的前沿模型。前沿模型,意味着它的性能已经无限逼近已经发布的最强大的闭源模型;再加上开源、友好,意味着更容易围绕其建立应用生态。
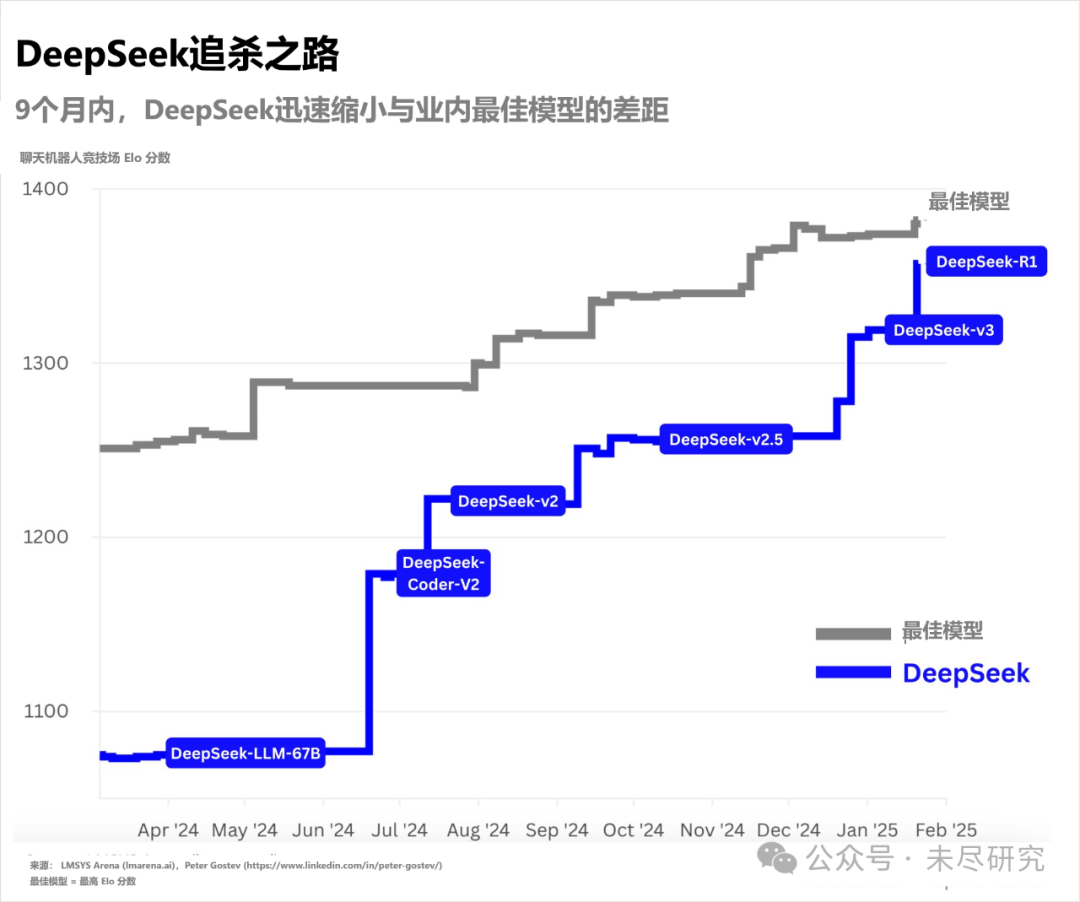
一般而言,同等条件下,基础模型性能越强大,蒸馏模型表现越好。完整版R1拥有6710亿参数规模,与其一同发布的蒸馏模型共6个,最小15亿参数,最大700亿参数,适合不同配置的终端设备本地部署。在R1发布后不久,LangChainAI就基于其中的140亿参数规模的蒸馏模型,搭建了一个完全本地的 “深度研究员”。年度最佳Mac应用Craft也迅速将14亿参数规模的蒸馏模型,更新到自己的本地笔记软件之中。
它们仍然不完美,但比此前的本地模型好用得多。而且,尽管扩展定律在预训练阶段的边际效应放缓,但大模型性能仍在提升,蒸馏模型的性能也因此能够得以继续提升;端侧设备的算力性能,也仍在追逐摩尔定律的轨迹,可以逐步在本地驱动更大参数规模的推理模型。
备注为DeepSeek研究员的推特用户DayaGuo(郭达雅),在被问及“如今推理模型处于GPT-2时代,还是已经到了GPT-3.5时代”时,乐观地回答当前仍处于“非常早期的阶段”,“强化学习领域还有很长的路要探索”,但“今年会看到显著进展”。
同样,V3与R1不会是DeepSeek开源的终点。此前,在谈及OpenAI从开源走向闭源的过程时,DeepSeek创始人梁文锋称,“我们不会闭源,我们认为先有一个强大的技术生态更重要。”
模型持续稳定地开源,可以建立与应用生态的反馈循环。这对推进整个开源生态至关重要。在最近一次长达5个小时的访谈中,Semianalysis的Dylan Patel称,模型正在商品化,基于这些模型的应用,会成为巨人肩膀上的赢家,DeepSeek的出现印证了这一趋势。基于云端的Perplexity,以及完全本地的Craft都迅速集成了DeepSeek。
推理模型的应用不仅仅是聊天问答。代理、编码、任务自动化、计算机使用自动化,以及机器人,都将是AI的杀手级应用。这些杀手级应用,非常适合部署于本地。目前,15亿参数的R1蒸馏模型,在数学基准测试中优于GPT-4o和Claude-3.5 Sonnet,它甚至可以装到一个手机里。这能释放软件工程师的生产力,或数学与编码技能相对缺乏的其他行业工程师的创造力。
它们也非常有必要部署于本地。真正负责数据安全的,是开源模型的托管者,是云服务商和本地用户。
芯片厂商也在积极拥抱DeepSeek。AI服务器的垄断巨头英伟达看上去最受打击,但实际上,在今年的CES上,英伟达就公开了自己的Project Digits。它相当于个人AI的桌面数据中心,在 FP4 精度下,可提供高达1 PFLOPS的算力,官方文档称它可以本地驱动2000亿参数规模的大模型。黄仁勋预言未来每个数据科学家、研究者和学生的桌子上都会有一台。
英伟达相当重视DeepSeek的出现。它不仅基于NIM微服务提供了DeepSeek模型服务,还贴心地为消费者测试了在新发布的RTX 50系列上跑R1蒸馏模型的效果。这是首款支持FP4精度的消费级GPU,与上一代相比,推理性能提高了2倍,本地运行内存占用更小。其中,80亿参数的R1蒸馏模型,每秒钟处理200多个token。去年,未尽研究的报告将AI PC的下限设定基于70亿参数的模型,以每秒20个token的速度对外输出。
英伟达的老对手AMD,最快为DeepSeek“站台”,将其模型集成至Instinct系列数据中心芯片上。在CES上,该公司CEO苏姿丰(Lisa Su)也公布了面向消费者的全新的Ryzen AI Max系列处理器,号称最高支持700亿参数本地模型,预计今年二季度上市。
操作系统同样行动迅速。纳德拉在财报电话会议上称,对于像微软这样的超大规模云服务提供商和PC平台提供商来说,DeepSeek的出现是好消息。几日后,该公司就宣布为DeepSeek-R1进行了NPU(神经处理单元)优化,以适配搭载高通骁龙X芯片的Copilot+PC。
也许困扰于如何让Apple Intelligence在华落地的苹果公司,也可以在挑选合作伙伴的时候,考虑一下DeepSeek。
设备厂商戴尔与联想也动作不断。月初,戴尔公司CEO迈克尔·戴尔(Michael Dell)宣布已将R1模型整合到戴尔服务器中。今日,联想同时宣布在旗下AI服务器与AI PC业务领域,适配DeepSeek的模型。前者主要与沐曦合作,后者主要是将DeepSeek集成到个人智能体“小天”之中。
现阶段,DeepSeek凭借最优性价比与最开放的姿态,成为面向规模市场,交付最佳个人AI用户体验的关键节点。这一趋势正在改变大模型生态。未来,它不必是DeepSeek,但很可能仍是DeepSeek。
今年,随着DeepSeek及更多机构组织推出下一代开源模型,英伟达、AMD与高通等新的消费级算力芯片的陆续上市,AI PC或许再次激起一波换机周期。据Canalys统计,去年,全球PC出货量增长3.8%,达到2.55亿台,今年将会继续加速。
坐拥DeepSeek、联想与庞大知识工作者群体的中国,个人AI渗透率及其增速,将有望领跑全球。


