

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。
以后,人人都能轻松上手3D模型设计。
近日,Stability AI发布消息,公开3D重建新方法SPAR3D的设计原理、代码、模型权重等。
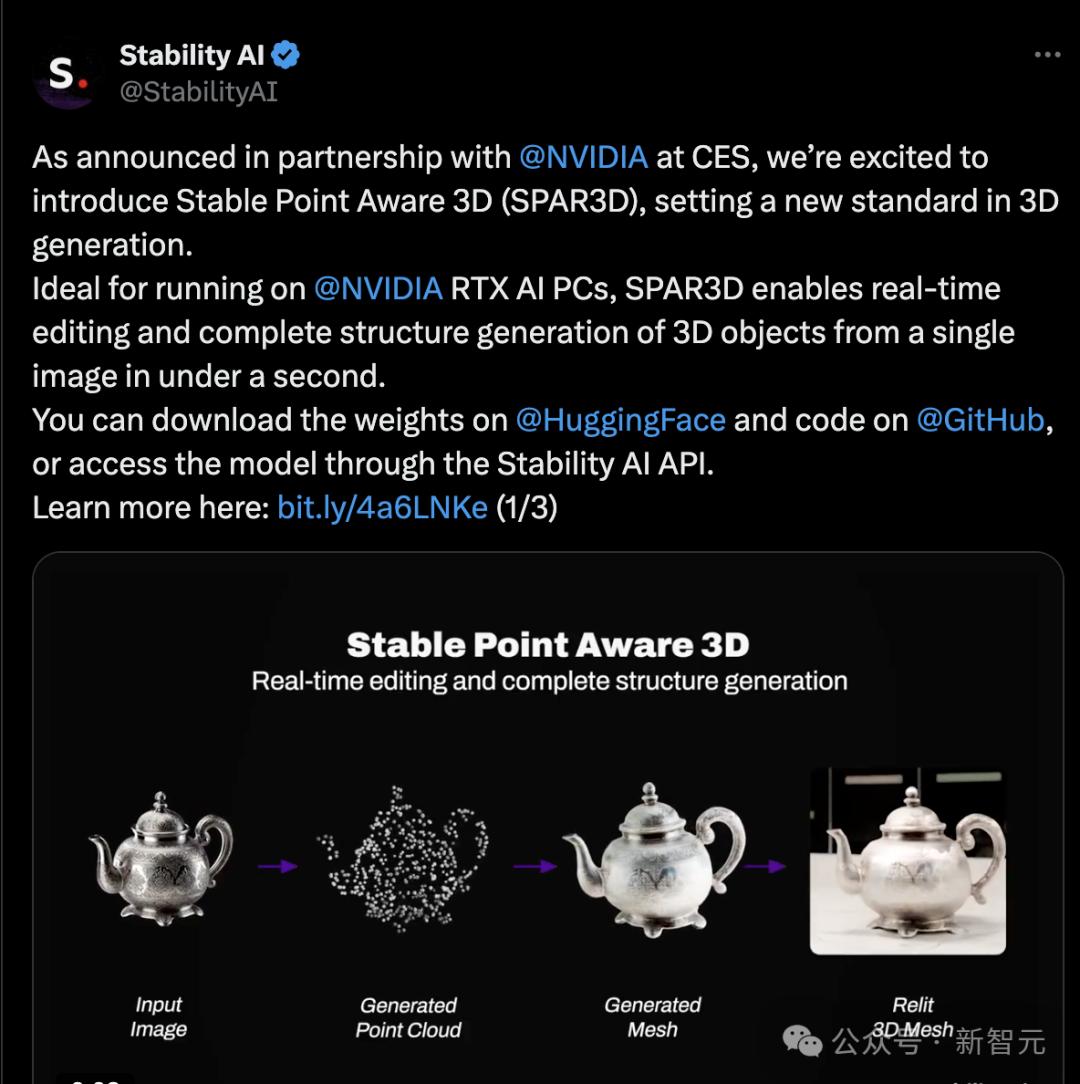
SPAR3D可在一秒内从单张图像生成3D物体的完整结构并且可以实时编辑。

文章亮点 :
新方法SPAR3D实现了实时编辑,在不到一秒内可从单图完成3D对象的结构生成。
SPAR3D将点云采样与网格生成技术相结合,可以完全的控制3D对象。
第一阶段主要依赖扩散模型生成稀疏点云数据,第二阶段主要靠Transformer生成网格。
不确定性集中在点采样阶段,提高了计算效率。
用实验证明了,新方法主要依赖输入图像重建正面,依赖点云生成背面。
基准测试,比SPAR3D快的没它好,比它好的没它快。
使用Stability AI Community License,可以免费商用。

论文链接:https://arxiv.org/pdf/2501.04689 项目链接:https://spar3d.github.io/
架构设计
整个过程分为两个阶段:
点云生成阶段:专门的点扩散模型生成详细的点云,捕捉物体的基本结构。
网格生成阶段:三平面Transformer在处理原始图像特征的同时处理点云,生成高分辨率的三平面数据。利用三平面数据进行3D重建,准确捕捉源图像的几何形状、纹理和光照。
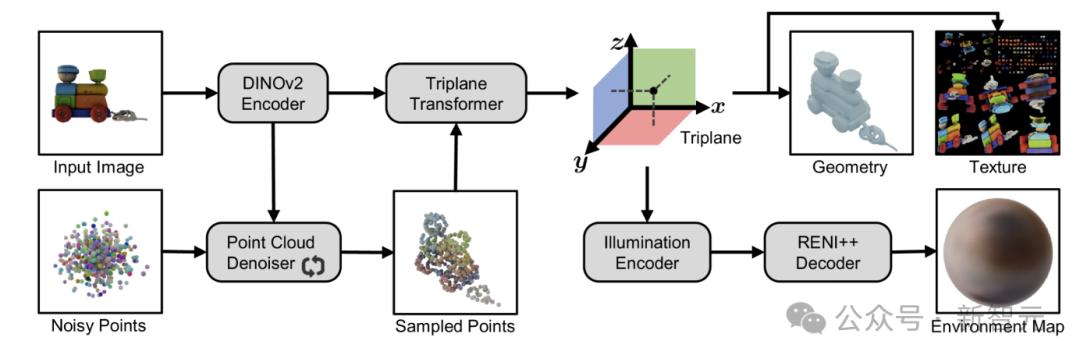
图1:SPAR3D双阶段架构图
双阶段架构
新方法结合了基于回归建模的精确性与生成技术的灵活性,实现了精确的重建和全面的控制。
新方法是「既要也要」:既要享受扩散模型分布学习的好处,又要避免输出保真度低和计算效率低的问题。

第一阶段使用扩散模型生成稀疏点云。然后是网格划分阶段,将点云转化为高度精细的网格。
主要想法是将不确定性建模集中到第一阶段,在这一阶段,点云的低分辨率允许快速迭代采样。
随后的网格划分阶段,利用局部图像特征将点云转换为高输出保真度的详细网格。
利用点云降低网格划分的不确定性,进一步促进了反渲染的无监督学习,从而减少了纹理中的烘托照明。
关键设计
关键的设计选择是使用点云来连接两个阶段。
为确保快速重构,中间表示只有足够轻量级才能高效完成生成任务。但是,它也要为网格划分阶段提供足够的指导。
这是因为点云可能是计算效率最高的三维表示方法,因为所有信息比特都被用来表示曲面。
此外,缺乏连通性通常被认为是点云的缺点。现在却变成了两阶段方法进行编辑的优势。
当背面与用户预期不一致时,可以轻松地对低分辨率点云进行局部编辑,而不必担心拓扑结构(见下图)。
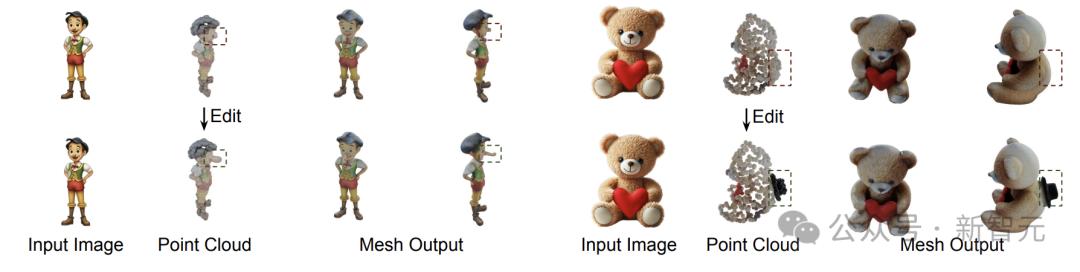
图2:局部编辑
将编辑后的点云送入网格划分阶段,可生成更符合用户要求的网格。比如在上图中,通过在点云中修改了人物鼻子长度,之后输出的网格后人物鼻子也变长了。
点采样阶段
点采样阶段生成稀疏点云,作为网格划分阶段的输入。
在点采样阶段,点扩散模型会根据输入图像学习点云的条件分布。
由于点云的分辨率较低,这一阶段的计算效率较高。
之后的网格划分阶段将采样点云转换为与可见表面对齐的高精细网格。
点采样的不确定性降低,有利于了在网格划分阶段以无监督方式学习材质和光照。
最后,使用稀疏点云作为中间表示,SPAR3D可以实现人工编辑。
此阶段包括:点扩散框架、去噪器设计和反照率点云。
点扩散框架
该框架基于去噪扩散概率模型。其中包括两个过程:
1)前向过程,在原始点云中添加噪声。
2)后向过程,去噪器学习如何去除噪音。
在推理(inference)阶段,使用去噪扩散隐式模型(Denoising diffusion implicit models,DDIM)生成点云样本,并使用无分类器扩散指导(Classifier-free diffusion guidance,CFDG)改进抽样的保真度。

去噪器设计
使用与Point-E类似的Transformer去噪器,将噪声点云线性映射到一组点token中。
使用DINOv2将输入图像编码为条件token。
然后将条件和点token串联起来,作为Transformer的输入,用来预测每个点上添加的噪声。
反照率点云
在网格划分阶段,新方法同时估算几何体、材质和光照。
然而,这种分解本身就很模糊,因为相同的输入图像可以被多种光照和反照率组合解释。
如果只在网格划分阶段学习,非常难这种高度不确定的分解。
因此,在点采样阶段,通过扩散模型直接生成反照率点云,减少了不确定性。
将反照率点云采样输入到后续的网格生成阶段,大大降低了反渲染的不确定性,并使分解学习稳定了下来。
网格生成阶段
网格生成阶段根据输入图像和点云生成纹理网格。
网格模型的主干是一个大型三平面Transformer,它能根据图像和点云条件预测三平面特征。
在训练过程中,会将几何图形和材质输入可微分渲染器,以便应用渲染损失来监督新模型。
三平面Transformer
新方法的三平面Transformer由三个子模块组成:点云编码器、图像编码器和Transformer主干网络。
Transformer编码器将点云编码为一组点token。由于点云的分辨率较低,每个点都可以直接映射为一个token。
新模型的图像编码器是DINOv2,它可以生成局部图像嵌入。
三平面Transformer采用了与PointInfinity和SF3D相似的设计。
这种设计可以生成384×384高分辨率的三平面图。
表面估计
为了估计几何形状,使用浅层MLP对三平面进行查询,以生成密度值。
使用可变行进四面体(Deep marching tetrahedra,DMTet)将隐式密度场转换为显式曲面。
此外,还使用两个MLP头来预测点偏移和表面法线以及密度。
这两个属性减少了行进四面体所带来的假象,使局部表面更加平滑。
材质和光照度估算
反向渲染,与几何图形一起联合估计材质(反照率、金属和粗糙度)和光照。
利用RENI++基于学习的光照先验建立了光照估计器。
RENI++最初是一个用于HDR照明生成的无条件生成模型,因此需要学习编码器,将三平面特征映射到RENI++的潜空间中。
这样,就能估算出输入图像中的环境光照度。
反照率是通过与几何类似的三平面来估算的,其中浅层MLP可预测每个三维位置的反照率值。
对于金属和粗糙度,采用SF3D,并通过贝塔先验学习以概率方法进行估计。
并用AlphaCLIP代替SF3D的CLIP编码器,利用前景物体遮罩来缓解这一问题。
可微渲染
新方法实现了一个可微渲染器(renderer),它能根据预测的环境贴图、PB材质和几何体表面渲染图像(见图3)。
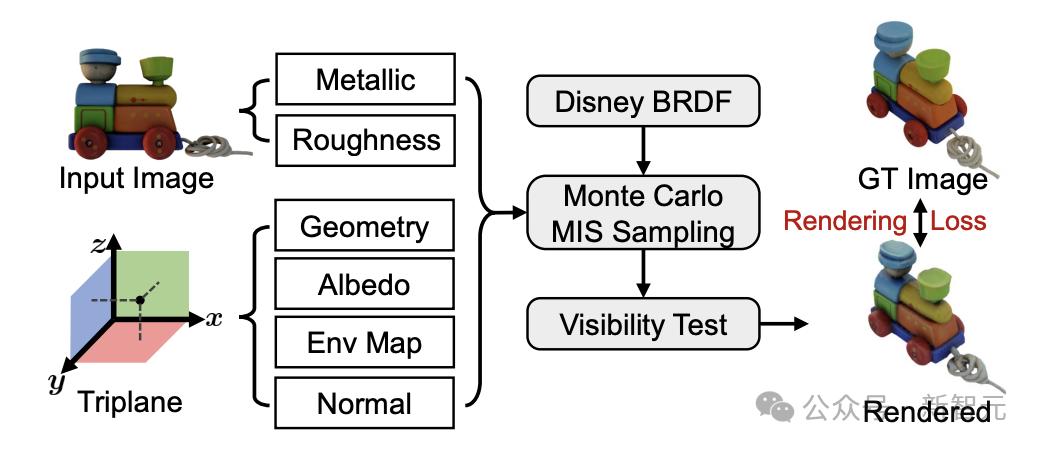
图3:可微分着色器
作者向可微网格光栅器(rasterizer)添加了可微着色器(shader)。
由于使用RENI++重构环境贴图,因此需要明确整合传入的辐照度。
在此,使用了蒙特卡罗积分法。
由于在训练过程中样本数较少,采用了平衡启发式的多重重要度采样(Multiple Importance Sampling,MIS),以减少整合方差。
此外,为了更好地模拟之前工作中通常忽略的自遮挡(self-occlusion)现象,利用可见度测试,更好地模拟了阴影。
作者从实时图形学中汲取灵感,将可见度测试建模为一种屏幕空间方法。图4是该测试的示意图。
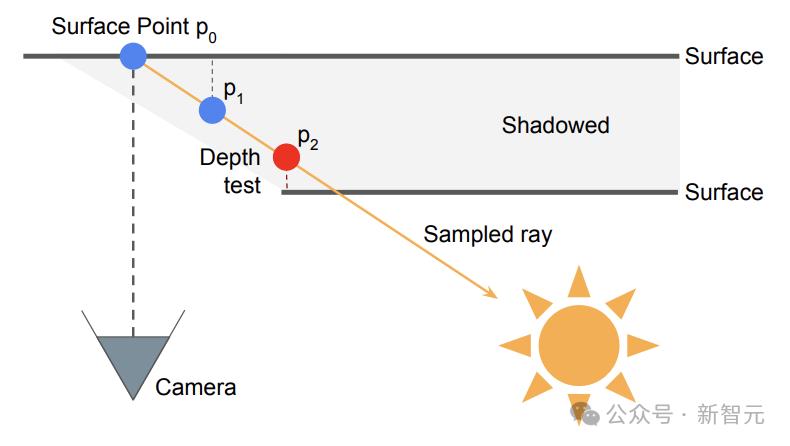
图4:阴影建模
具体来说沿着MIS提出的所有采样方向,在6个步骤内进行短距离(0.25)的光线步进,并将位置投影回图像空间。如果当前光线的深度比深度图中采样到的值更远,则该光线会被标记为阴影光线。
损失函数
新模型的主要损失函数是渲染损失,它用于比较来自新视角的渲染结果与真实图像(GT)。
具体来说,渲染损失是以下几项的线性组合:1)渲染图像与GT图像之间的L2距离,2)通过LPIPS测量的渲染图像与GT图像之间的感知距离,3)渲染的透明度与GT前景遮罩(mask)之间的L2距离。
除了渲染损失外,还遵循SF3D并应用网格与着色正则化,分别对表面光滑度和逆向渲染进行正则化。
交互式编辑
两阶段设计的一个独特优势是,它自然支持对生成的网格中的不可见区域进行交互式编辑。
在大多数情况下,可见表面由输入图像决定,并保持高度精确,而未知表面主要基于采样点云,可能与用户意图不一致。
在这种情况下,可以通过改变点云来编辑网格的未知表面。
如果只考虑编辑,点云可能是最灵活的三维表示方法之一,因为没有拓扑约束。
由于点云分辨率较低,编辑点云非常高效和直观。
用户可以轻松删除、复制、拉伸或重新着色点云中的点。
高效网格模型能够在0.3秒内生成调整后的网格,因此这一过程具有相当高的交互性。
实验结果
这部分包含了定量比较、定性结果、编辑效果和实验分析。文中也讨论了消融实验。
定量比较
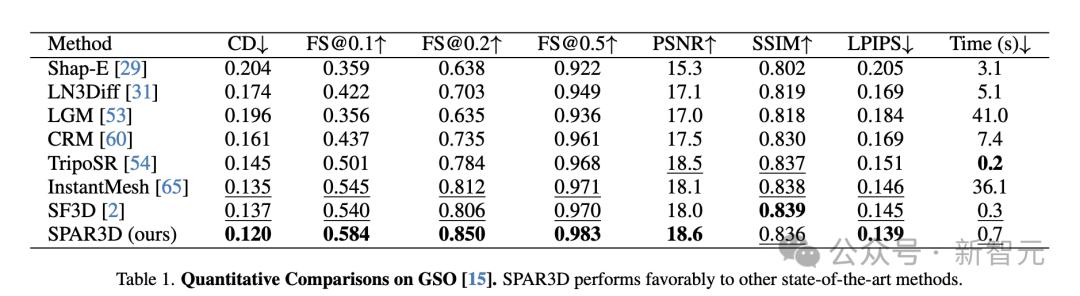
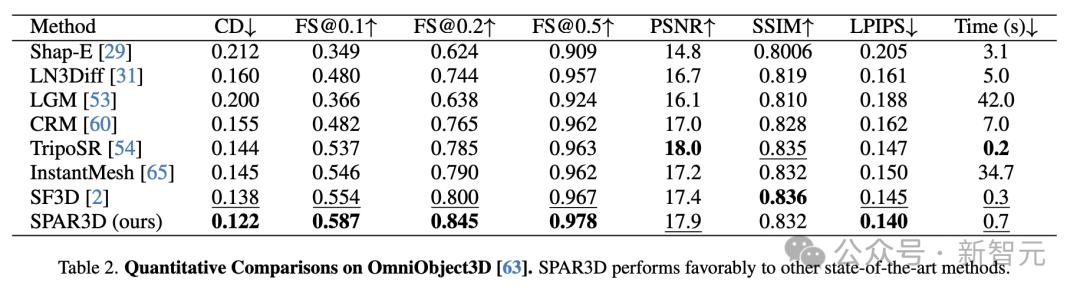
在GSO和Omniobject3D数据集上定量比较了SPAR3D与其他基准方法。
如表1和表2所示,SPAR3D在这两个数据集的大多数指标上显著优于所有其他回归或生成基准方法。
SPAR3D也是可以做到1秒内完成重建的模型之一,每个物体的推理速度为0.7秒,显著快于基于3D或多视图的扩散方法。
简而言之,比SPAR3D快的没它好,比它好的没它快。
定性结果
纯回归方法如SF3D或TripoSR重建的网格与输入图像对齐良好,但背面往往不够精确且过度平滑。
基于多视图扩散的方法,如LGM、CRM和InstantMesh,在背面展示了更多的细节。然而,合成视角中的不一致性导致了明显的伪影,整体效果更差。
纯生成方法如Shap-E和LN3Diff能够生成锐利的表面。然而,许多细节是错误的虚拟幻象,未能准确地遵循输入图像,且可见表面重建得也不正确。
与先前的工作相比,SPAR3D生成的网格不仅忠实地再现了输入图像,还展现了生成得当的遮挡部分,细节合理。

作者进一步展示了SPAR3D在自然图像上的定性结果。
这些图像通过文本-图像模型生成,或来自ImageNet验证集。高质量的重建网格展示了SPAR3D的强泛化能力。

编辑效果
使用显式点云作为中间表示,能够实现对生成网格的交互式编辑。
用户可以通过操控点云轻松地改变网格的不可见表面。
在图7中,展示了一些使用SPAR3D进行编辑的示例,用户可以通过添加主要物体部件来改进重建,或改善不理想的生成细节。

图7:编辑效果
在左侧的两个例子中,通过复制现有点云,为马克杯添加了把手,为大象添加了尾巴。在右侧的两个例子中,通过移动或删除点云,修复了不完美之处,并改善了网格的局部细节。所有编辑耗时不到一分钟。
实验分析
为了进一步了解SPAR3D的工作原理,作者设计了新的实验。
设计SPAR3D时的核心假设是:两阶段设计有效地将单目三维重建问题中的不确定部分(背面建模)和确定部分(可见表面建模)分开。
理想情况下,网格化阶段应主要依赖输入图像重建可见表面,同时依赖点云生成背面表面。
为了验证这一假设,作者设计了一个实验,特意使用与输入图像冲突的点云。
在图8中,将一只松鼠的输入图像和一匹马的点云输入网格模型。

图8:正面看像松鼠,侧面看像马。
如图所示,重建的网格在可见表面上与松鼠图像很好地对齐,而背面表面则主要遵循点云。这一结果验证了假设。
在图像和点云冲突的情况下,模型根据图像重建可见表面,同时根据点云生成背面表面。
作者介绍
另外值得一提的是本文第一作者是中科大校友。

Zixuan Huang,伊利诺伊大学香槟分校在读博士,在Stable AI主导了此次工作。
之前,在威斯康星大学麦迪逊分校获得计算机科学硕士学位,在中国科学技术大学获得学士学位。
参考资料:
https://x.com/StabilityAI/status/1877079954267189664
https://stability.ai/news/stable-point-aware-3d?utm_source=x&utm_medium=social&utm_campaign=SPAR3D
https://arxiv.org/pdf/2501.04689


