

半导体行业的发展并非一蹴而就,而是建立在逐年累积的巨大技术进步之上,其发展速度或许超越了历史上任何其他行业。IEEE国际电子元件会议(IEDM)是芯片制造商展示这一进步的关键场所之一。论文主题涵盖了商业相关的、最终可能实现的,以及其他可能不会实现但仍然有趣的技术。

半导体:50多年累积的增量增长。来源:AMD
在2024年12月举办的IEEE IEDM 2024会议上,台积电、英特尔、IMEC、IBM和三星等各大半导体公司的研究人员汇聚一堂,分享了关于半导体技术的最新研究成果。
对于逻辑芯片,台积电的N2(2nm)工艺、三星等研究的2D材料、CFET(垂直堆叠互补场效应晶体管)的进步,以及英特尔在硅通道扩展上取得的成就超出了人们的预期。专家小组的结论是,尽管会议上的进展令人瞩目,但这还不足以跟上人工智能(AI)的发展步伐。
对于内存,一个重点是存内计算,这是解决人工智能内存墙的长期解决方案。
Meta展示了一种独特的3D堆叠内存实现方案。先进封装技术也受到广泛关注。这是趋势所在,因为封装现在是推动算力的关键途径——我们将讨论英特尔的新EMIB-T 2.5D技术和台积电的下一代SoIC 3D混合键合产品。
台积电N2节点:材料创新推动性能提升
台积电是先进逻辑芯片领域的顶尖企业。他们的一个关键优势是卓越的工艺技术。台积电的GAA(全环绕栅极)工艺节点N2,作为其首个采用该技术的制程,有望延续其在先进制程领域的竞争优势。
对于晶体管,2N工艺性能宣称与之前发布的内容一致——速度提升15%或功耗降低30%,以及大于1.15倍的密度缩放。提供了六个阈值电压级别(Vt,即晶体管导通所需的电压),这一点值得注意,因为相较于鳍式场效应晶体管(FinFET),GAAFET的Vt调整难度更大。阈值电压选项菜单帮助芯片设计师优化性能和功耗:逻辑核心可能使用低Vt晶体管以实现高速度,而I/O等外围功能则受益于更高Vt以最大限度地降低功耗(通常低Vt意味着晶体管可以更快切换,但也会有更多电流泄漏,即高性能但高功耗。高Vt则相反)。
为了实现不同的阈值电压,必须以精细的控制方式沉积介电材料,使其厚度不同。此外,还有一个挑战,即无法直接看到栅极通道的底部。这是在GAA中比FinFET工艺使用更多原子层沉积(ALD)技术的关键原因之一。
在现代逻辑芯片缩放中,互连技术与晶体管本身同样重要,台积电在这方面做出了真正的改进。栅极触点现在采用无阻挡层的钨材料,几乎肯定使用了应用材料的Endura平台,在连续真空环境下进行预清洗、物理气相沉积(PVD)钨衬层以及化学气相沉积(CVD)钨填充腔操作。尽管应用材料在IEDM 2023上的演讲声称电阻率降低40%,但台积电在实际应用中电阻和电容(RC)可降低55%。这直接转化为性能提升:在环形振荡器测试设备中提升超过6%。
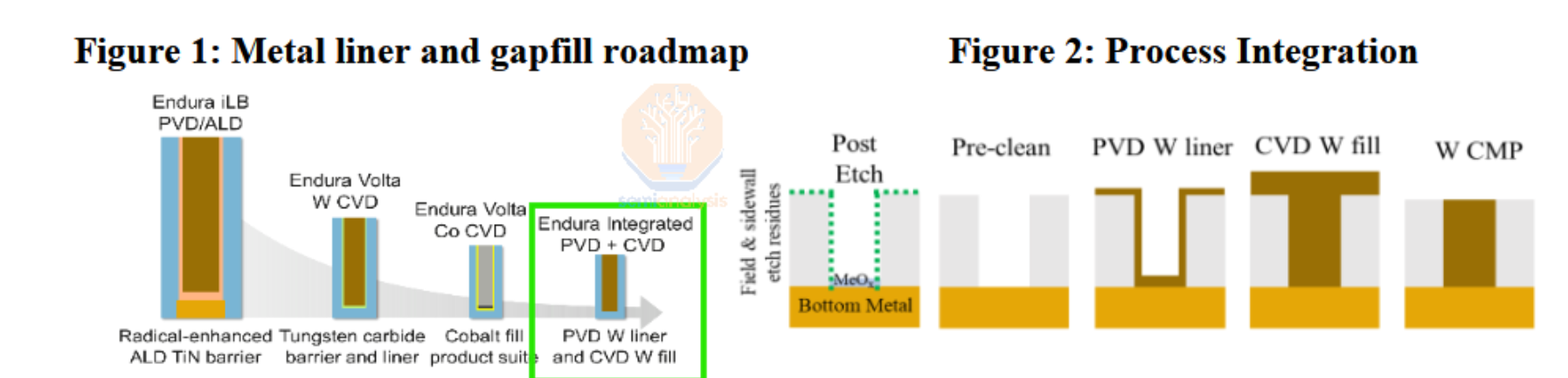
来源:应用材料
最后是一些关于金属层中RC降低的消息。在单次光刻的ArFi层中,“主力”金属层和通孔的RC分别降低19%和25%。我们认为可能是因为使用了更好的介电材料。更令人印象深刻的是,一种经过优化的M1(金属层1,是倒数第二层,因此布线非常密集)光刻方案,不仅节省多个极紫外光刻(EUV)掩模,还使该层的电容降低50%!细节仍是个谜——以下是供“侦探们”参考的完整引述:
“优化的M1采用新颖的1P1E EUV光刻,使标准单元电容降低近10%,并节省多个EUV掩模。”
业内共识,上一个十年是光刻的十年,而即将到来的是材料的十年。N2的细节证明了这一点:材料创新推动性能提升,同时关键层中的EUV掩模需求减少。
值得注意的是,英特尔、三星和Rapidus中,除了Rapidus发表了一篇关于阈值电压调整的论文外,均没有展示其竞争性“2nm”GAA节点。这可能表明他们在这些工艺节点上还不够成熟。
2nm以下决胜关键:CFET
现在,GAA即将进入大规模生产阶段,CFET成为新的“下一个大事件”。我们在IEDM 2023综述中深入探讨了动机和细节,但要点在于,将PMOS和NMOS晶体管上下堆叠,相比于传统的并排配置,可实现约1.5倍的缩放。
集成是关键挑战。前端线路(晶体管)堆叠高度加倍,第二个晶体管必须在不破坏下方晶体管的情况下构建,并且即使不是为了传输信号,也需要直接背面接触来提供电源。
IMEC展示了一个概念性的4层CFET单元,通过共享将顶部和底部晶体管与背面供电网络(BSPDN)相连。
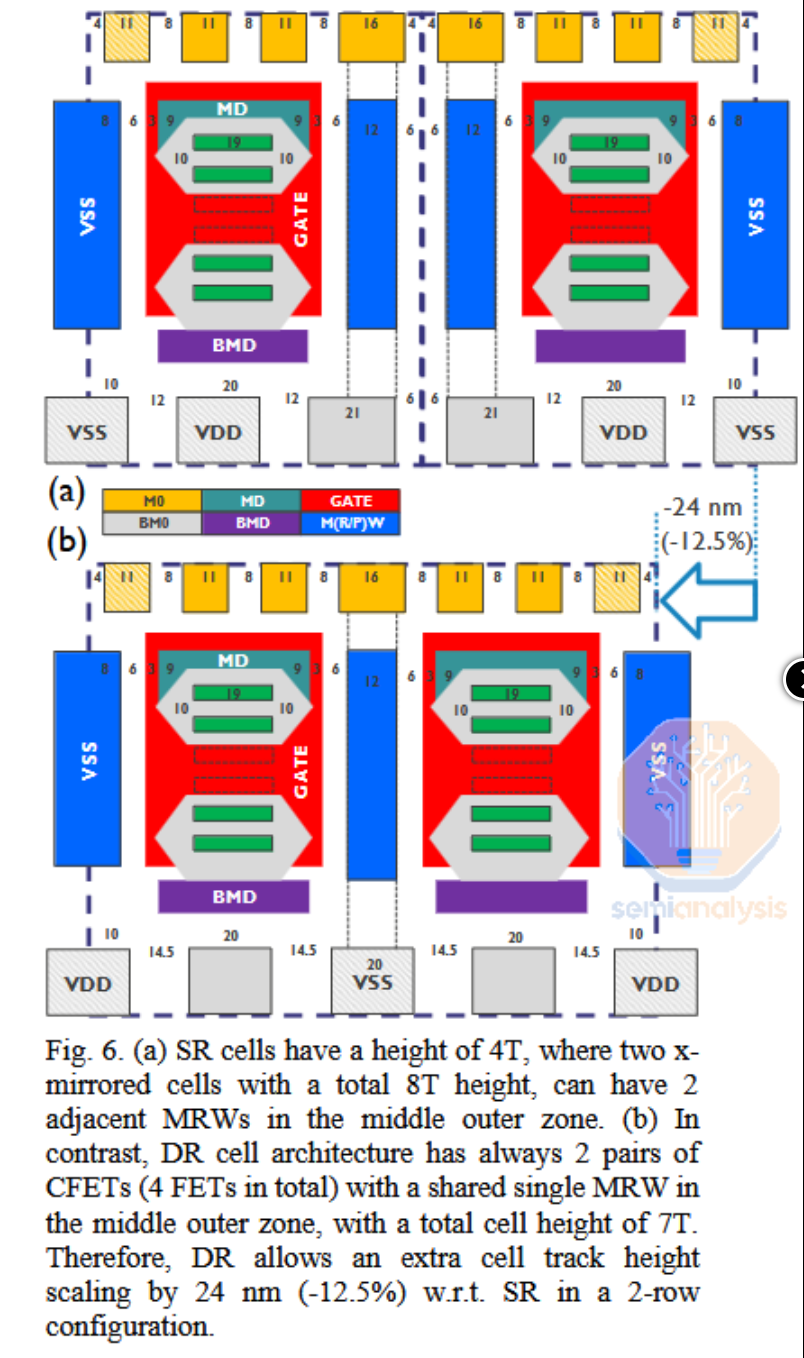
来源:IMEC
来源:IMEC
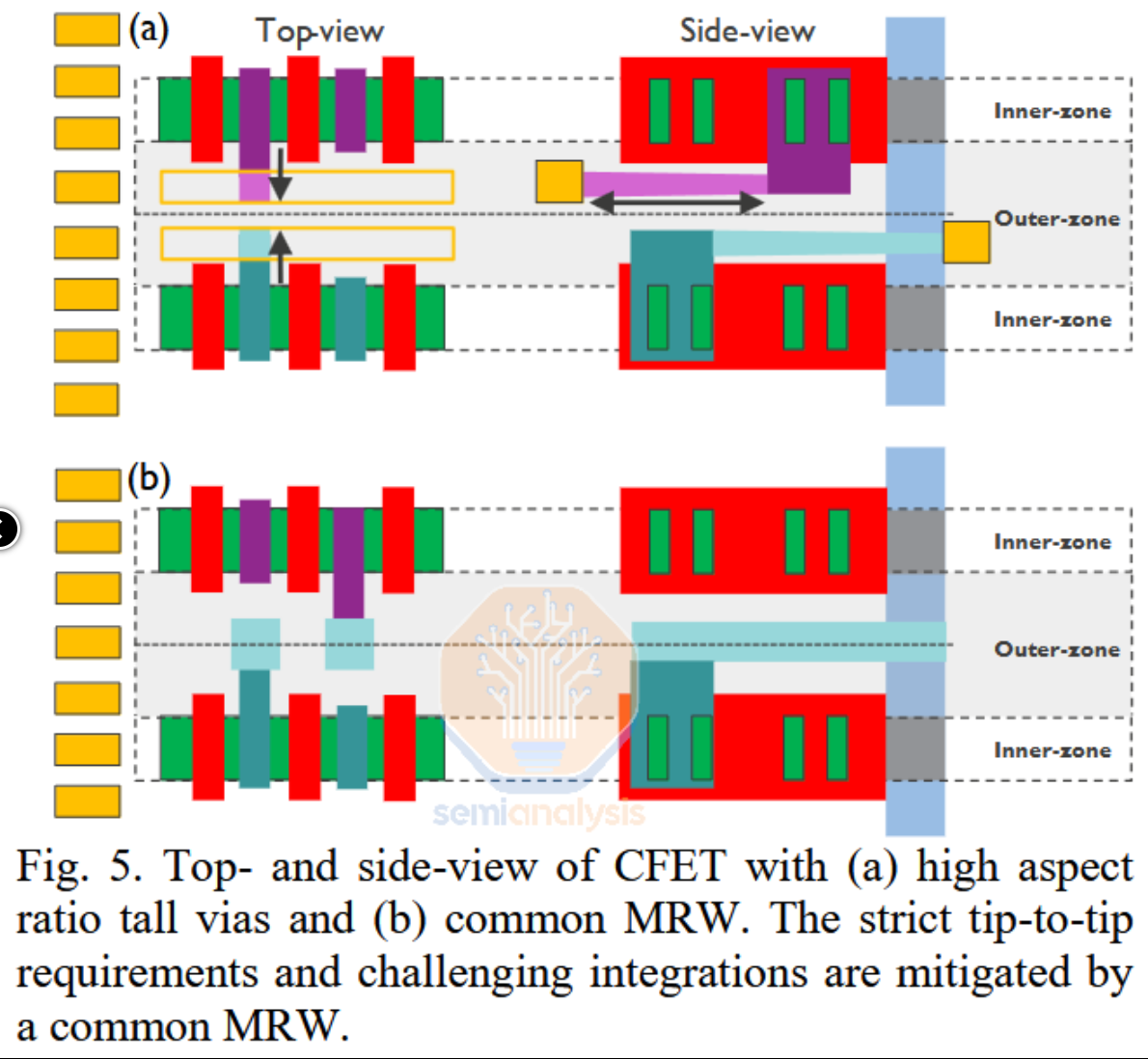
论文的重点是降低源/漏极接触的工艺复杂性。构建低电阻接触是提高性能的关键,但由于需要高纵横比以连接CFET的底部和顶部器件,这一工艺较为困难。IMEC的解决方案是设置共享的“中间布线墙”,它位于每个N+PMOS堆叠的一侧,根据需要连接到源极和漏极。像这样的“墙”或轨道比通孔更容易构建,因此可以实现更好的质量、性能等。但这仍有待证明,因为该论文仅模拟了集成流程。下一步可能是实际构建这些器件。
三星和IBM展示了一种新颖的“阶梯式”方法,在底部NFET中使用2个宽通道,在顶部PFET中使用3个较窄的通道。这样在形成接触时能够直接看到底部通道,意味着更容易实现高质量,从而提高性能。
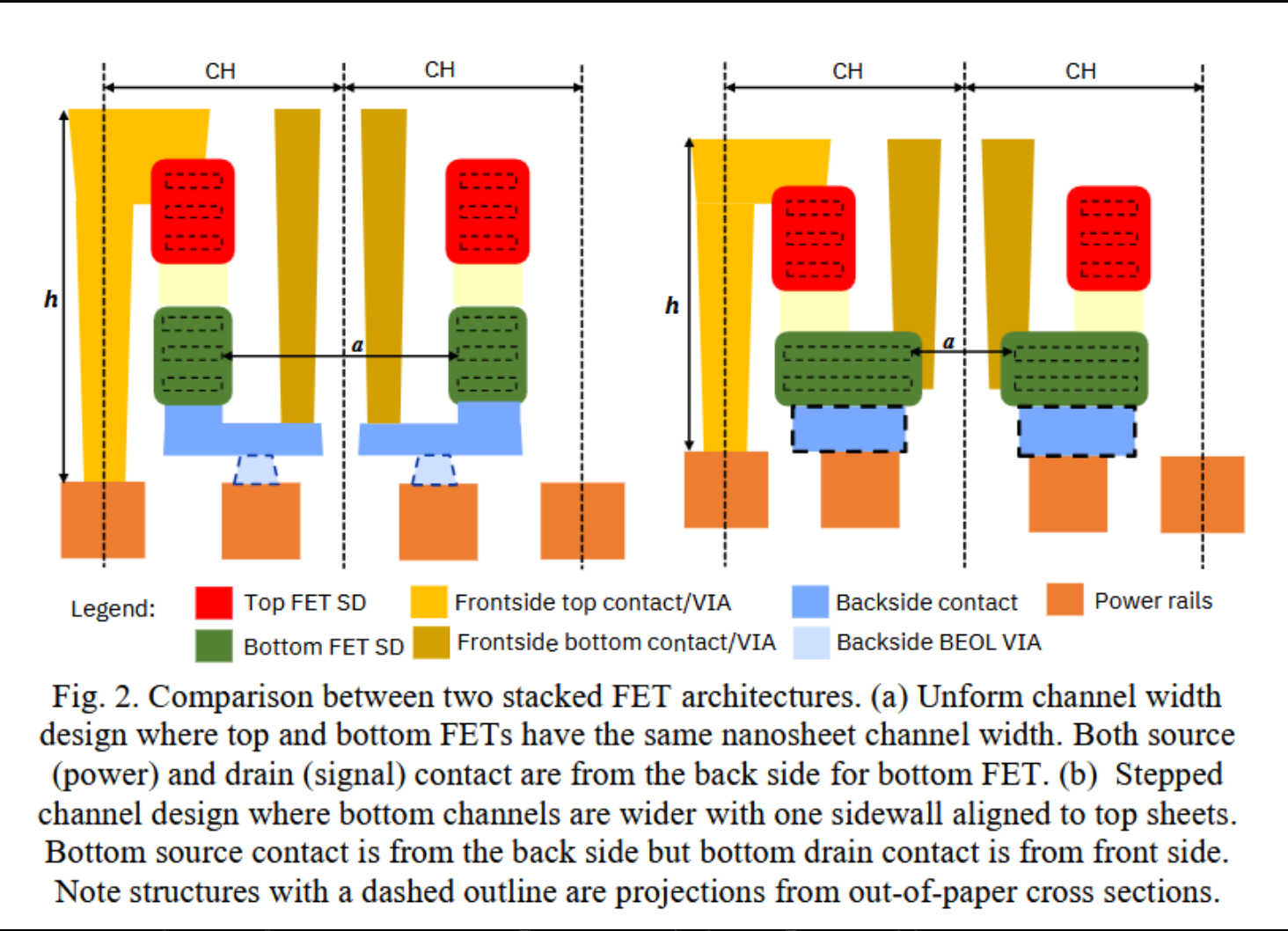
来源:IBM/三星
但这可能会带来缩放成本。论文认为,阶梯式方法将底部FET连接到信号,不比背面接触+通孔连接的方案差。这可能是对的,但基准并非正确。共享电源墙(如IMEC的方法)或背面的本地信号布线是更好的比较对象,而阶梯式设计及其更宽的通道在缩放方面比这两者都更差。
台积电再次展现出最佳水平。他们展示了能正常工作的CFET反相器,这意味着底部的pFET和顶部的nFET被连接在一起形成一个基本逻辑门。这是在工业化工艺集成路线图上领先其他公司一大步。最重要的是,他们采用一种有效的方法来形成顶部和底部FET之间的局部互连。这是IMEC在模拟中解决的问题,而台积电已经在硅片上实现。尽管可能是精心挑选的,但晶体管性能已经非常好,这表明局部互连和接触质量良好。高纵横比和严格的对准要求,将是实现大批量生产面临的主要挑战。

台积电展示了具有合理晶体管性能的工作CFET反相器。
来源:台积电
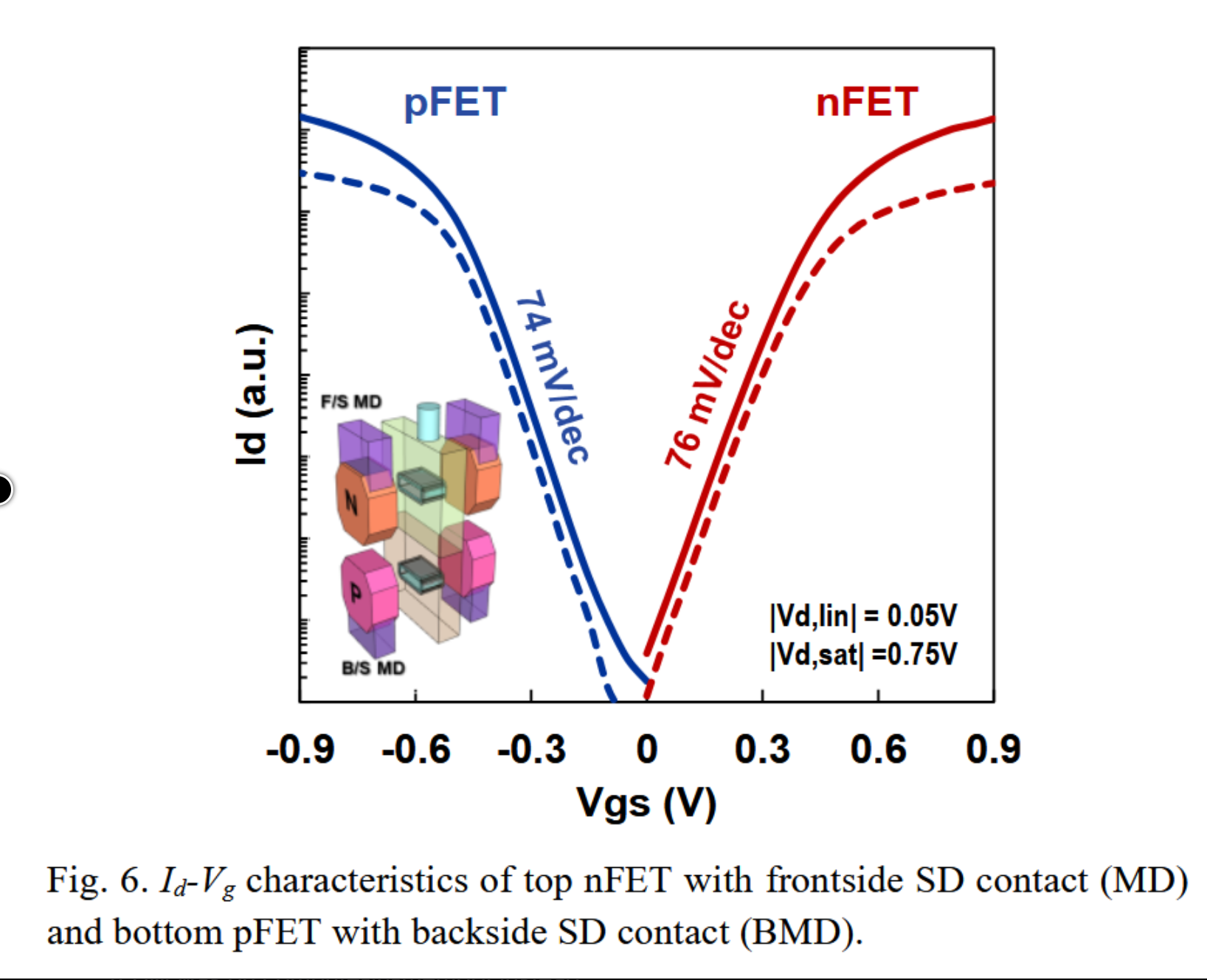
来源:台积电
英特尔没有展示任何CFET成果。在往年他们已经展示了相关进展,所以今年很可能是他们选择不展示。
如何解决内存瓶颈?
内存领域最热门的话题显然是HBM(高带宽存储器)。不幸的是,目前它与商业利益相关性太高,所以没有公司会在会议论文中提供详细信息。IEDM的焦点是存内计算。
这是一个关于解决内存瓶颈问题的广泛类别的潜在方案。目标是减少数据移动的开销,因为在当前架构中,大部分能源和时间都浪费在数据移动上。虽然减少需要移动的数据量(如降低精度、算法改进等)或增加内存带宽(如HBM)可以有所帮助,但理想的解决方案可能是将计算尽可能靠近内存,即存内计算。
SK海力士展示了一种AiM(内存加速器)的架构。他们构建了一个演示模型,将GDDR6与每个存储体相邻的处理单元结合在一起。

来源:SK海力士
结果显示,每GB的内存带宽比HBM高出两个数量级:

来源:SK海力士
由于大多数现代AI应用场景都受限于内存,这将带来显著的性能提升。然而,使用AiM设备存在明显障碍,主要是缺乏灵活性。杀手级应用可能是用于AR/VR的设备端AI。例如,手部跟踪等对延迟敏感的任务必须在设备上完成。
Meta 3D堆叠内存
Meta展示了将3D封装的SRAM或DRAM堆叠在计算单元上方(这实际上是近内存计算)的成果,并提出了一个理论上的内存内计算加速器,用于VR应用。
3D堆叠SRAM消除了对片外存储器访问的需求,将延迟和能耗降低40%。SRAM和DRAM的优化组合效果更佳。Meta提出的CIM(内存计算)设计包含逻辑+内存宏阵列,其能效可能达到现有加速器的两倍。
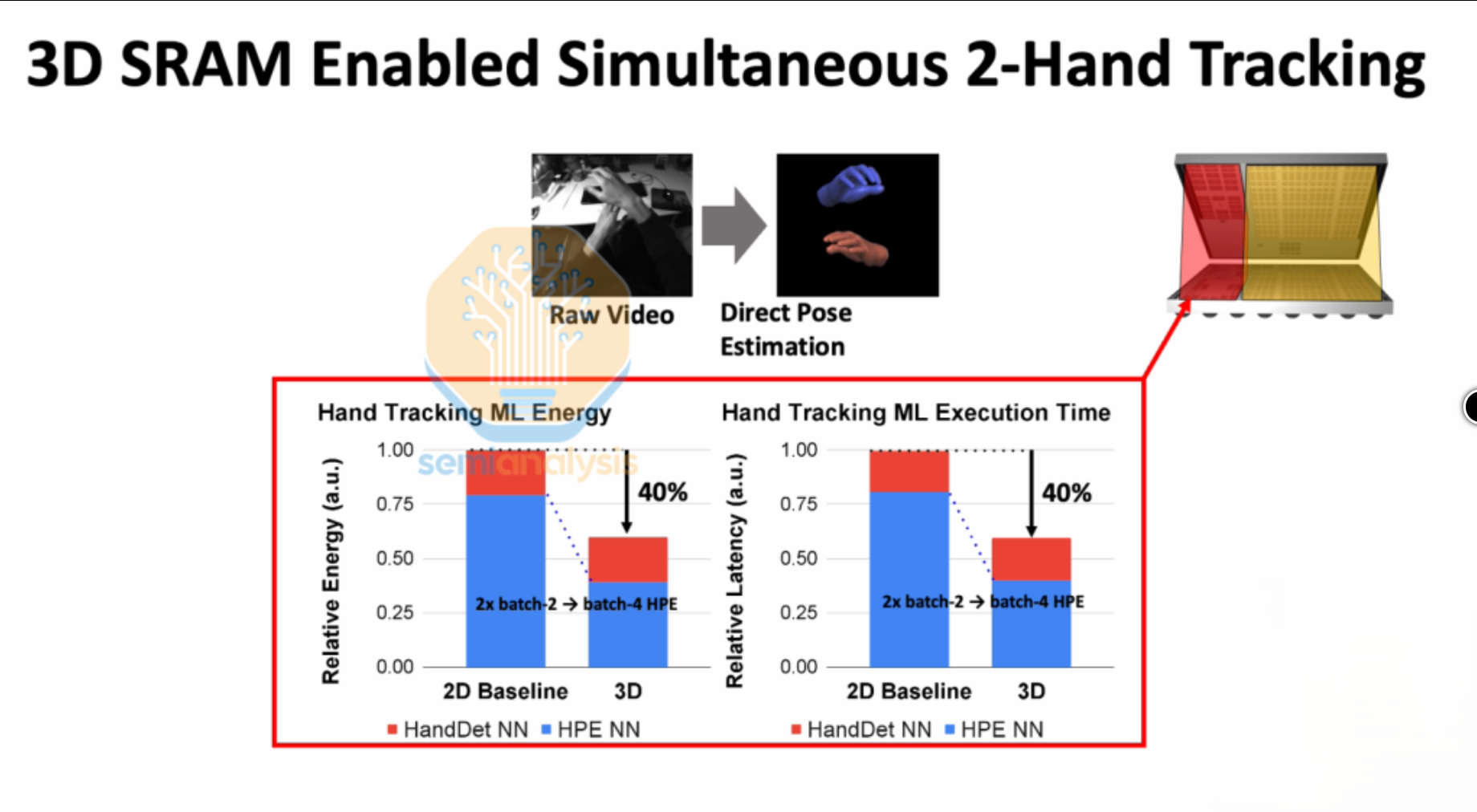
来源:Meta

来源:Meta
尽管理论和测试模型的结果看起来很不错,但要实现商业化仍存在一些障碍。首先,大多数CIM架构的可靠性和准确性比当前的计算+内存模式要差。例如,利用DRAM存储单元及其外围电路执行简单逻辑运算的方案,错误率较高。DRAM(或许多其他内存类型)和逻辑电路的制造从根本上不同且不兼容。以DRAM退火的热预算为例:可能需要600°C并持续数小时,远高于先进逻辑器件所能承受的温度。
第二是成本。即使是像Meta展示的采用混合键合技术的近内存计算也是具有挑战性的。目前市场上唯一一款将内存与逻辑电路采用混合键合技术的主流产品——AMD的X3D CPU,其销量和利润率并不可观。使用DRAM库进行计算的方法需要一个更复杂的内存控制器。而共同制造方案也很复杂——可能需要专门的内存和逻辑电路工具。尽管如此,与传统计算相比,AI加速器的需求使得采用更昂贵的解决方案变得合理。CIM仍将会加大研发力度,成为可行产品。
英特尔2.5D封装技术:EMIB-T
即使在一个可能以器件为主题的会议上(国际电子器件会议),先进封装技术也受到大量关注。因为它是计算能力扩展的新前沿领域。
英特尔非正式地宣布其EMIB(嵌入式多芯片互连桥)2.5D封装技术的新变体——EMIB-T。T表示增加了TSV(硅通孔)。EMIB是英特尔对使用硅中介层的封装技术的命名:即把无源芯片嵌入有机基板中。在硅中介层中,互连密度可以是传统基板的两倍(或更多),这意味着整体封装性能可以更高。
初代EMIB技术声称具有成本优势,主要是因为它不采用制作成本相对高昂的硅通孔。这意味着一些信号和电源必须绕过中介层进行布线。而硅通孔能够为信号与电源布线带来更大灵活性,可选择将任意或所有信号及电源经由中介层传输。随着硅通孔制造技术的成熟,其成本也在降低。英特尔的EMIB-T目标市场是使用2.5D/EMIB和3D/Foveros的复杂异构封装,以提供超越掩模尺寸限制的多种互连密度。高性能计算(HPC)是其中最重要的应用场景。
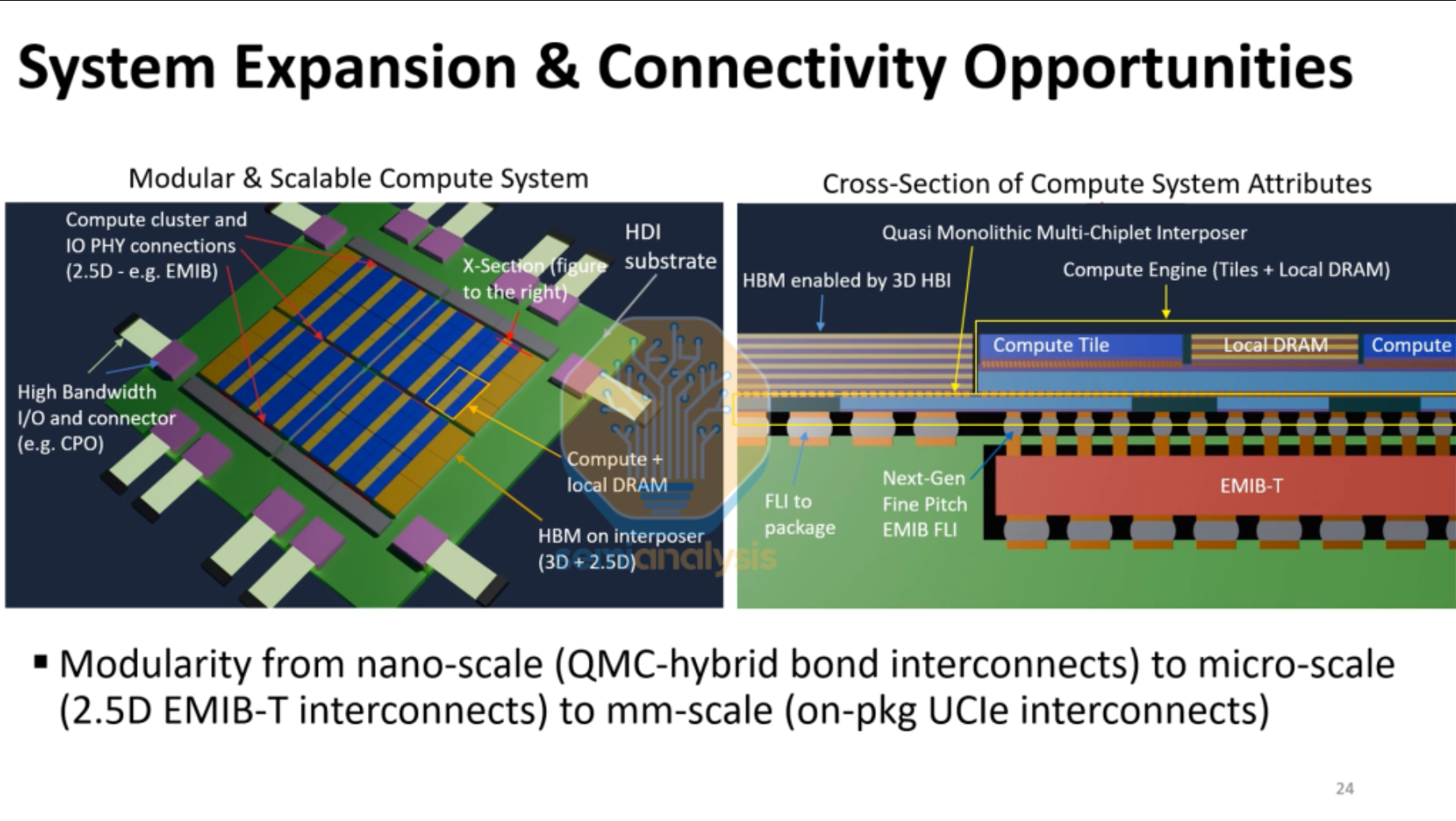
来源:英特尔
台积电3D封装技术:SoIC
台积电对其SoIC 3D封装技术进行了更新。虽然从技术上讲,台积电并不是混合键合的行业领导者(索尼在其CMOS图像传感器中已实现<4µm,并即将达到<1µm),但台积电在先进逻辑封装方面处于领先地位。此新一代SoIC技术似乎实现了<15µm的硅通孔互连间距。相比之下,英特尔的Foveros间距大约是25µm。由于互连间距的平方与密度和性能成正比,因此即使是与上一代SoIC相比,这一差距也是显著的:
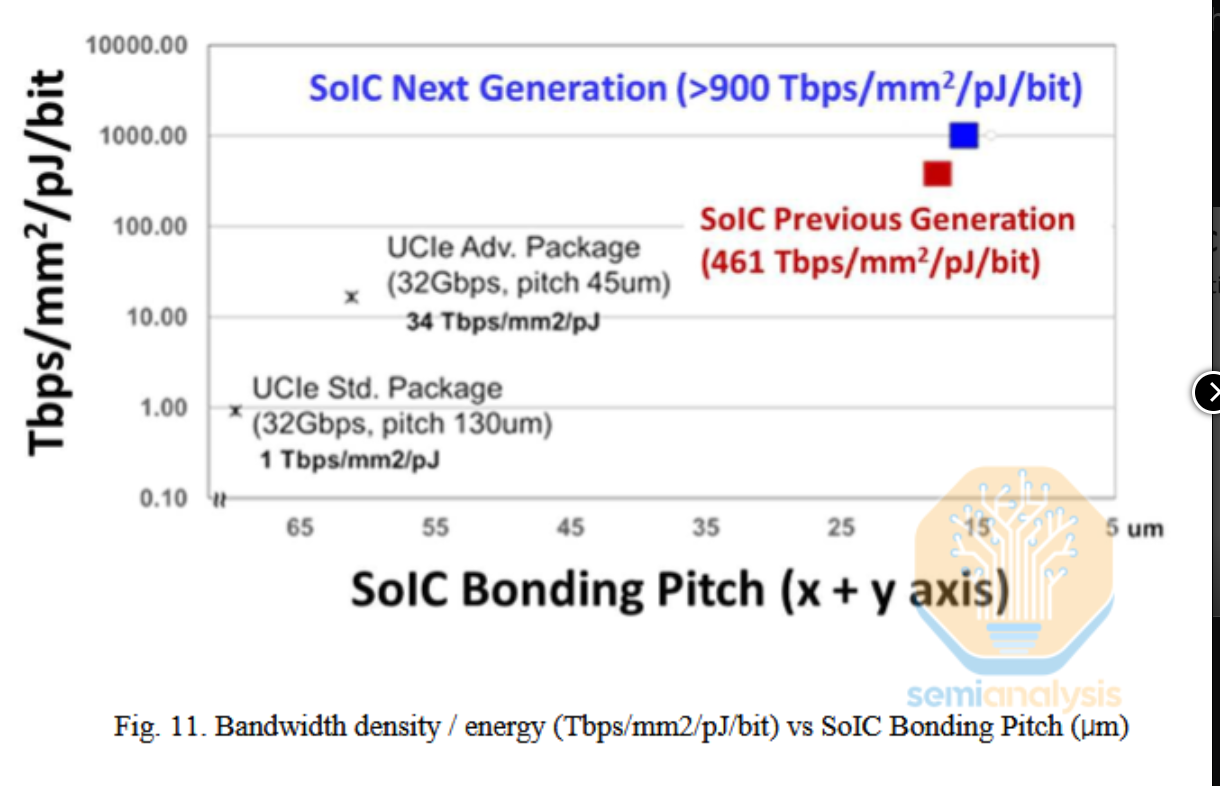
来源:台积电
来源:台积电
2D材料
二维(2D)材料有望取代硅晶体管沟道。沟道负责在晶体管的源极和漏极之间传导电流,其传导过程由与沟道接触或环绕沟道的栅极控制。在硅材料中,沟道长度(通常称为栅极长度或LG)低于约10nm被认为是不可行的,因为漏电流过高——晶体管效率低且难以关闭。由2D材料构建的沟道更易控制,且不易受导致硅材料漏电的机制影响。随着领先设备的栅极长度已达到10~20nm,2D材料已被纳入许多21世纪30年代的技术规划。
但2D材料仍远未达到商业化阶段。英特尔的一篇论文将主要挑战归纳为三大类:材料生长、掺杂与接触形成以及GAA堆叠/高介电常数金属栅极。
“掺杂与接触形成”包括为形成晶体管有源源极和漏极区域进行的掺杂,以及为与上方金属互连层形成低电阻连接而进行的接触操作。GAA堆叠需要在二维沟道周围沉积多层材料,以形成控制晶体管的栅极。
目前,在掺杂、接触和栅极形成方面,台积电已取得一些进展。台积电展示了针对P型器件接触的研究成果,这填补了一项空白。此前台积电已展示过N型晶体管的接触。接触是金属互连(布线)层与晶体管源极、漏极或栅极之间的电气连接。接触性能的关键因素,尤其是在现代器件尺寸为几十纳米的情况下,是电阻。挑战在于,源极和漏极由半导体材料制成——传统上是硅或这里的2D材料(本例中为WSe2)——其电阻较高。将互连金属直接沉积在源极或漏极上,会在界面处形成高电阻的肖特基势垒。金属与硅的粘附性通常也较差。
对于硅材料,常见的解决方案是硅化处理,这是一种沉积加退火工艺,在硅源极或漏极区域上形成高导电性的硅化物(例如NiSi)。然后可以在硅化物上构建金属互连,以完成从有源源极/漏极到电路布线的低电阻连接。
对于2D材料,无法进行硅化处理,因为它们不含硅。首选的解决方案是简并掺杂:将特定杂质引入2D材料结构中,将其从半导体转变为导体。实际上,对WSe2进行掺杂是很困难的:其晶格容易被破坏,且在整个材料中实现均匀的掺杂分布具有挑战性。但论文的作者们已经做到了这一点。接触问题是现代逻辑工艺中最大的挑战之一,为2D材料找到一条可行的前进方向是重大进步。
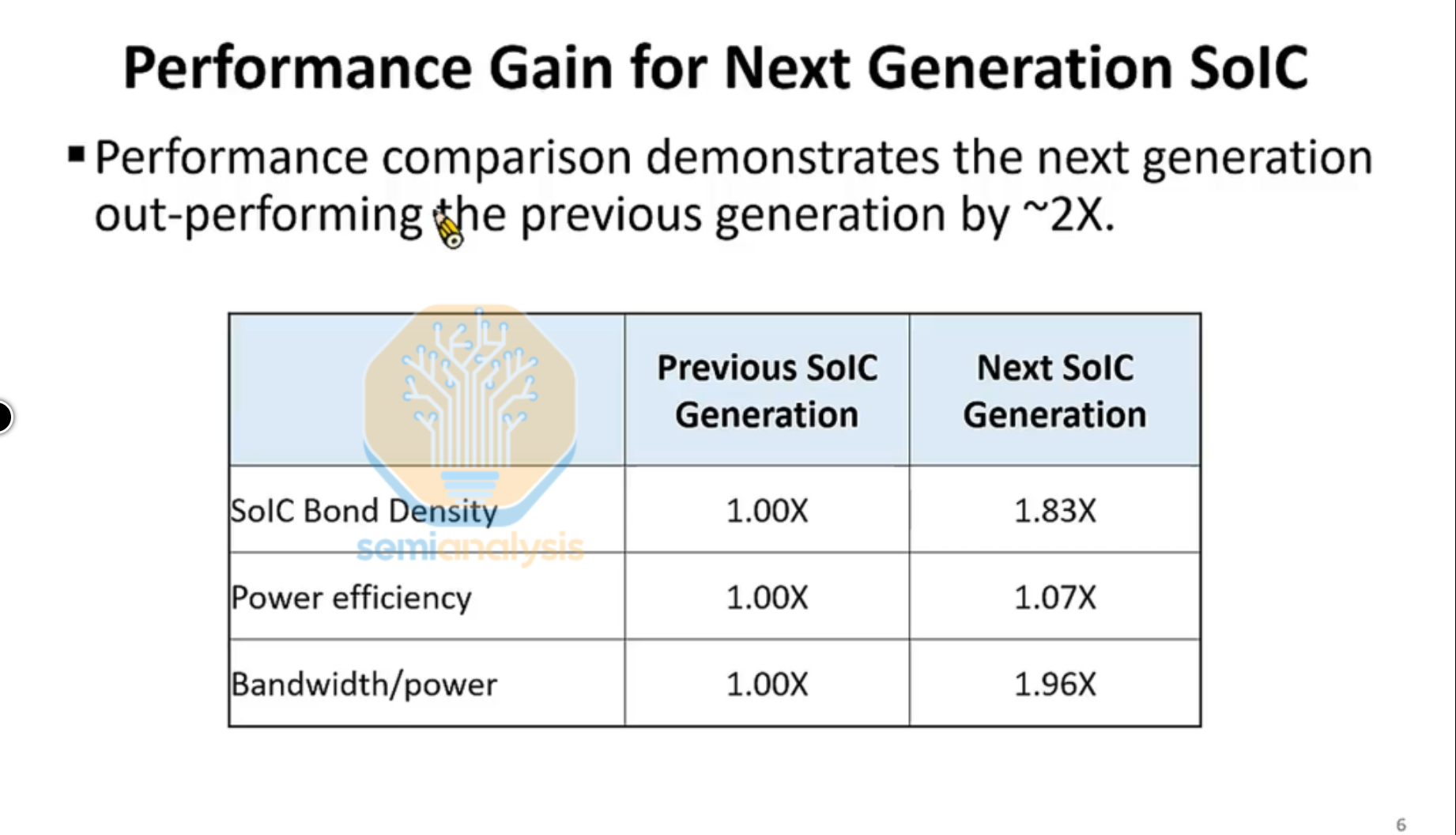
使用台积电C形接触方案的2D FET示意图。来源:台积电

第一列和第二列展示了接触区域,其中包含简并掺杂的二维材料,其上方是钯金属。来源:台积电
栅极氧化物是2D材料商业化的另一关键挑战。正如台积电N2论文中所述,栅极氧化物的质量决定了晶体管的可控性。如果不能很好地控制晶体管……就没有可行的逻辑工艺。英特尔展示了高质量栅极氧化物的形成过程,由此实现了对晶体管的良好控制。DIBL(漏极感应屏障泄漏)和亚阈值摆幅较低,最大漏极电流较高——这些都表明静电控制良好。这里的主要创新似乎是工艺优化,特别是针对预清洗和氧化物沉积工艺。
来源:英特尔

来源:英特尔
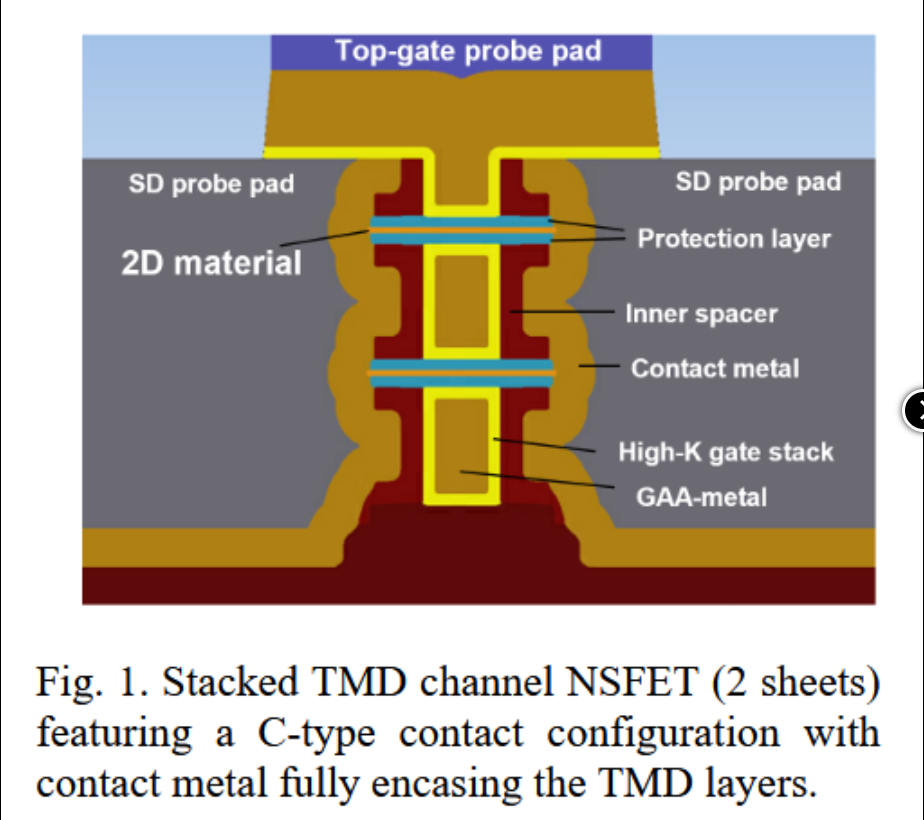
尽管在掺杂、接触和栅极形成方面取得了进展,但在2D材料生长方面仍缺乏进展。我们在去年的综述中写道:“生长是2D材料的基本问题。”大多数现有研究使用转移法——材料在蓝宝石衬底上生长,然后通过机械方式转移到硅片上。但这是一种实验室技术,无法扩展到量产。直接在12英寸硅片上生长是最有可能实现商业化的路径。
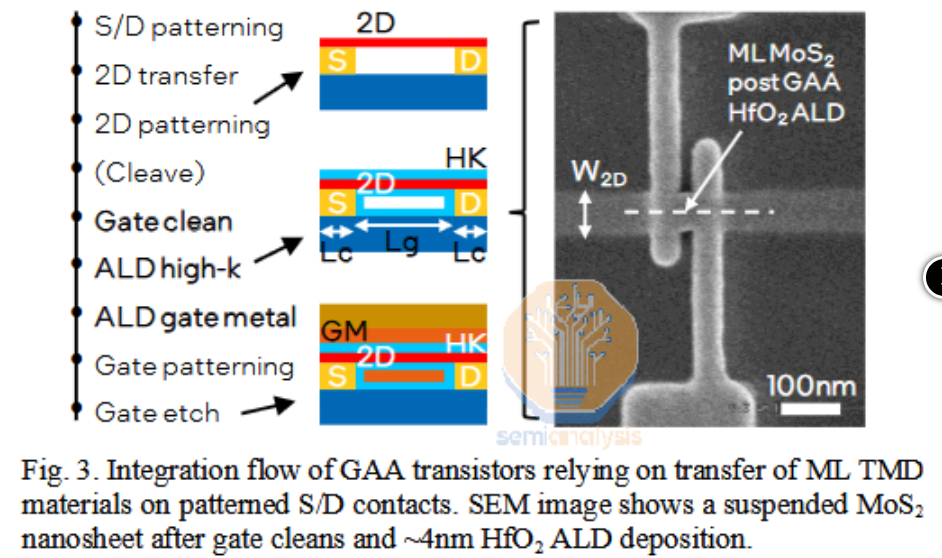
最近在这方面的进展似乎停滞不前。三星展示了使用8英寸测试晶圆进行的晶圆上生长。但材料在晶圆上的附着力不佳。解决方案是在每个晶体的边缘制造“夹子”,以在后续工艺步骤中将其固定。虽然展示了功能晶体管,不过是采用顶栅和底栅结构,而不是GAA结构。但这一工艺无法规模化。测试器件的沟道长度为500mm——大了两个数量级。如果每个沟道都需要夹子,那么所消耗的面积将抵消缩短沟道带来的缩放优势。真正的需求是在整个晶圆上生长高质量材料,而且不需要辅助结构。
来源:三星

来源:三星
台积电展示了完整的2D FET反相器——一个N型和P型晶体管连接在一起形成基本逻辑单元。这似乎是一个集成路径探索研究,因为器件本身是平面的,而不是GAA,并且比所需尺寸大一个或两个数量级。
在实现大规模生产之前,2D材料还有很长的路要走。目前的顶尖技术勉强能在合理的短沟道长度下制造出一个性能良好的晶体管。这必须扩大规模,达到至少每片晶圆数十亿个晶体管,然后每年生产10万片或更多晶圆。这意味着规模至少要扩大15个数量级。
英特尔:6nm栅极长度GAA晶体管
对2D材料来说更不利的是,理论上硅的最小栅极长度为10nm的说法已被证明是错误的。英特尔展示了一种单条带GAA晶体管,其栅极长度仅为6nm。
10nm有许多被认为是阻碍的挑战,其中最有趣的是量子隧穿。在如此极端的规模下,电子或空穴“隧穿”晶体管栅极所形成的能量屏障的概率不为零。尽管它们没有足够的能量跨越屏障,但仍能穿过它——结果是电荷通过晶体管泄漏。用漏电晶体管制成的芯片效率低下且容易出错。
英特尔的成果证明这种量子隧穿效应是可以减轻。该器件的性能虽不完美,但已经非常好,并且很可能通过足够的改进实现大规模商业化。亚阈值摆幅(衡量晶体管对栅极电压变化的响应程度,即晶体管开关的难易程度)已经接近理论室温最小值60mV/V。DIBL(漏极感应屏障泄漏,这种影响会随着沟道变短而加剧)大约是台积电N2工艺的两倍。它需要改进,但对于研发来说已经是不错的成果。
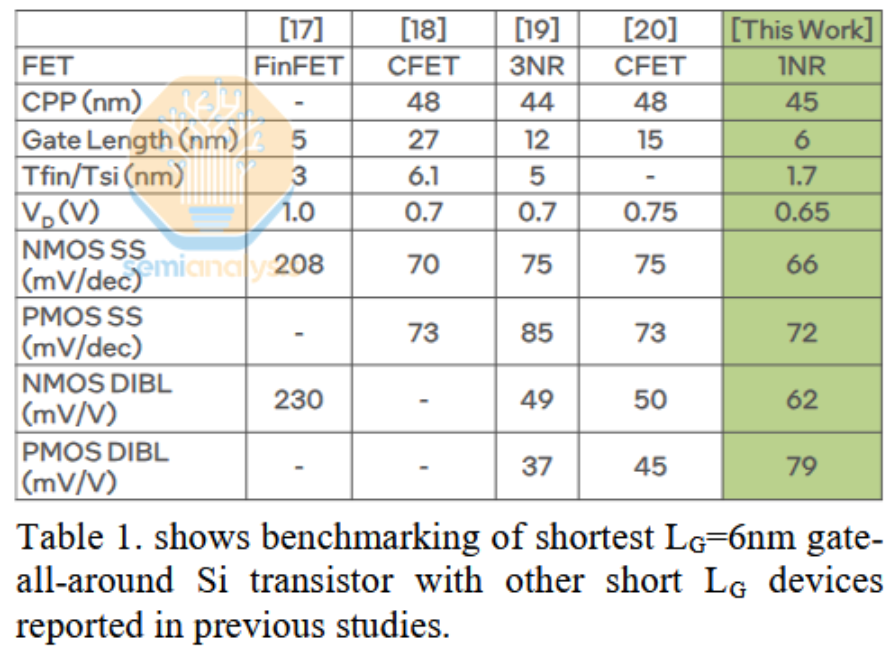
6nm栅极长度的GAA晶体管性能表现良好。之前已制造出5nm栅极长度的FinFET,但性能非常差。来源:英特尔
这一结果很可能将2D材料在技术路线图上的应用时间进一步推迟。芯片制造商不会冒险采用一种新的复杂技术,除非他们别无选择。
专家小组:需要突破
计算设备的持续进步无疑是惊人的,但还不够。如果基础设备技术没有进步,计算需求及其所需能源的指数级增长将难以为继。斯坦福大学的Tom Lee教授绘制了按当前增长率推算出未来150年的能源需求。这一推算跨度很大,但证明了必须做出改变。按当前增长率,到2050年,AI计算所需的能源将耗尽太阳射向地球的每一个光子。再过100年,我们将需要捕获太阳发出的每一个光子。IEDM专家小组建议,与其建造“戴森球(一种假想的巨型结构,它包围着一颗恒星,并捕获其大部分能量输出)”,不如在半导体器件领域寻求突破。
设备上的常规进步已不再满足需求。Tom Lee教授表示,在所有“AI指数”中,能源将成为限制因素,而且“我们无法用线性的手段战胜指数级增长的难题”。(校对/孙乐)
参考来源:
https://semianalysis.com/2025/02/05/iedm2024/#meta-3d-stacked-memory


