

人工智能看病就要来了!?哈佛大学、斯坦福大学、微软等顶尖学府和机构的多名医学、AI专家日前联合开展了一项研究,该研究显示,OpenAI旗下o1-preview模型在鉴别诊断中的准确率高达78.3%。
该模型在医学推理多项任务中表现出卓越的能力,在鉴别诊断生成(判断“这是什么病”)、诊断临床推理(判断“这最可能是什么病”)和管理推理(判断“应该如何治疗”)方面,甚至达到了超人类水平。AI看病比医生强?清华大学电子工程系长聘教授、清华大学精准医学研究院临床大数据中心共同主任吴及告诉记者,医疗本质上是人对人的服务,这一过程非常复杂,医学诊疗不仅包含理论和科学,还涉及大量经验,很多时候依赖专家的直觉。“AI在医疗领域的应用难度较大,但会逐步渗透到一些典型场景中。”
据市场研究机构Global Market Insights的统计,2023年,医疗保健领域的AI市场规模价值为187亿美元,预计到2032年将达到3171亿美元,2024年至2032年的复合年增长率为37.1%。
哈佛大学、斯坦福大学、微软等顶尖学府和机构的多名医学、AI专家日前联合开展了一项研究,对OpenAI旗下o1-preview模型在医学推理任务的表现进行了综合评估。
结果显示,o1-preview模型在多项任务中表现出卓越的能力,在鉴别诊断生成(判断“这是什么病”)、诊断临床推理(判断“这最可能是什么病”)和管理推理(判断“应该如何治疗”)方面,甚至达到了超人类水平。
目前,AI技术在一些医院已初步展开应用,覆盖了分诊导诊、预先问诊、病历生成等多种场景。
清华大学电子工程系长聘教授、清华大学精准医学研究院临床大数据中心共同主任吴及告诉《每日经济新闻》记者,“AI在医疗领域的应用难度较大,但会逐步渗透到一些典型场景中。”

图片来源:论文《大型语言模型在医学推理任务中的超人表现》
o1-preview诊断准确率高达近80%
该研究通过五个实验对o1-preview模型进行了综合能力评估,包括鉴别诊断生成、诊断推理、分诊鉴别诊断、概率推理和管理推理能力。
这些实验由医学专家使用经过验证的心理测量方法进行评估,旨在将o1-preview的性能与以前的人类对照组和早期大型语言模型基准进行比较。结果表明,与医生、已有的大语言模型相比,o1-preview在鉴别诊断、诊断临床推理和管理推理的质量都有明显提高。
在评估o1-preview鉴别诊断生成的能力时,研究人员使用了发表在国际顶级医学期刊《新英格兰医学杂志》(NEJM)上的临床病理会议(CPC)病例。结果表明,o1-preview在鉴别诊断中的准确率高达78.3%。
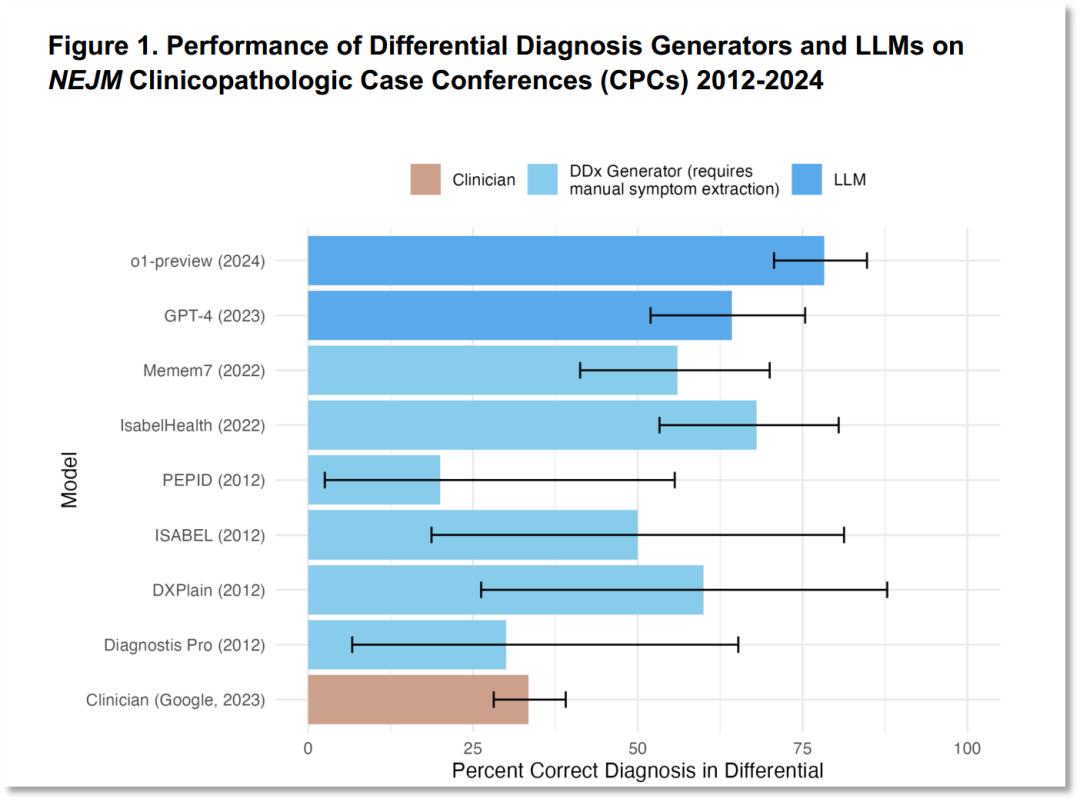
图片来源:论文《大型语言模型在医学推理任务中的超人表现》
值得注意的是,o1-preview在88.6%的病例中得出了准确或非常接近准确的诊断结果,而GPT-4只有72.9%。
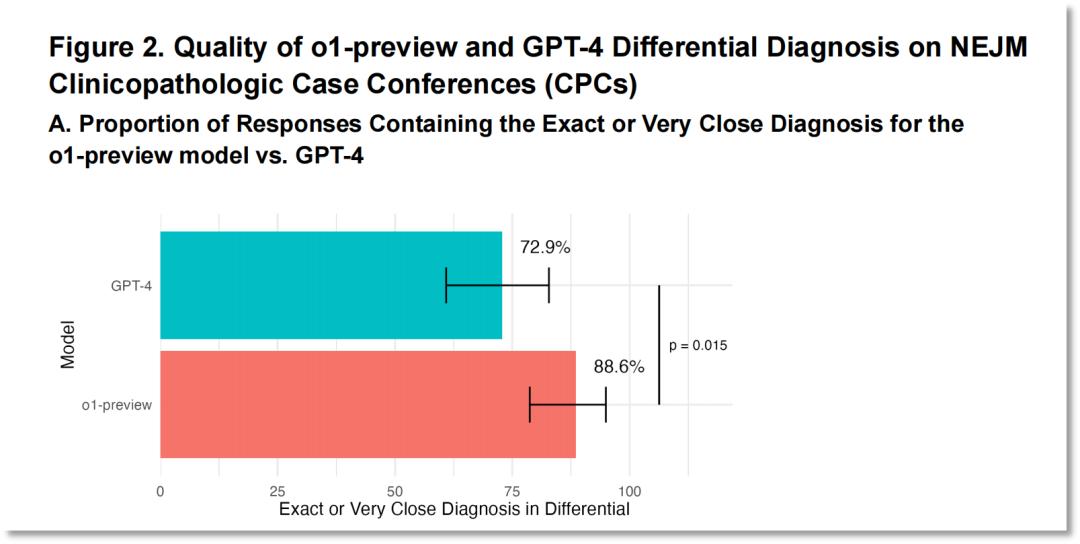
图片来源:论文《大型语言模型在医学推理任务中的超人表现》
此外,在87.5%的病例中,o1-preview选择了恰当的检查项目;另在11%的病例中,两位医生均认为该模型所选检查方案是有效的;而在仅有的1.5%的病例中,其检查方案被两位医生认为是无效的。
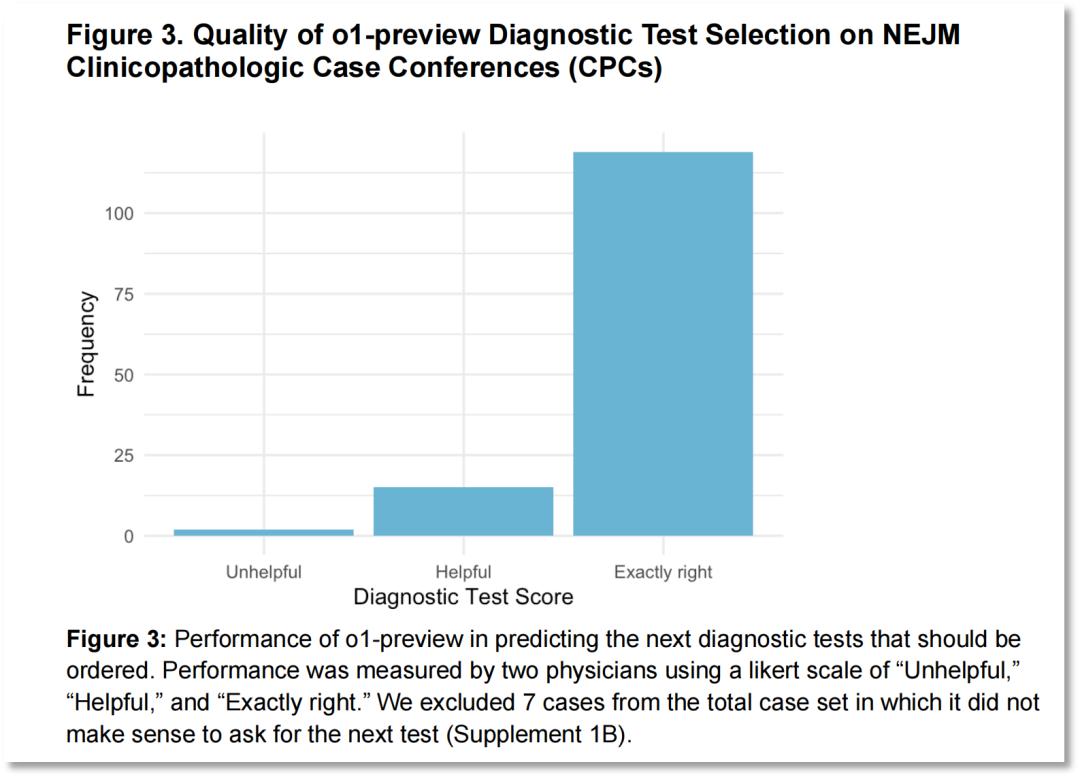
图片来源:论文《大型语言模型在医学推理任务中的超人表现》
为了进一步评估o1-preview的临床推理能力,研究人员使用了NEJM Healer(一款在线工具,学习者可以通过与虚拟患者的互动来提升他们的临床推理和诊断技能)中的20个临床病例。
结果表明,o1-preview的表现明显优于GPT-4、主治医师和住院医师。在80例病例中,有78例获得了完美的R-IDEA评分。R-IDEA评分是一个10分制量表,用于评估临床推理能力。

图片来源:论文《大型语言模型在医学推理任务中的超人表现》
此外,研究人员还通过灰质管理案例和标志性诊断案例评估了o1-preview的管理和诊断推理能力。
在灰质管理案例中,o1-preview得分明显高于GPT-4、使用GPT-4的医生和使用传统资源的医生。在标志性诊断案例中,o1-preview的性能与GPT-4相当,但优于使用GPT-4或传统资源的医生。
研究仍有局限性
研究表明,大语言模型如o1-preview在辅助医生进行诊断决策方面具有巨大潜力。然而,该项研究也具有部分局限性。
首先,o1-preview有“啰嗦”倾向,而这种特性可能会让其在试验中取得更高分。
其次,目前的研究只反映了模型性能,但现实中离不开人机交互。人机交互对开发临床决策辅助工具至关重要,下一步应该确定大语言模型(如o1-preview)能否增强人机交互。人类与计算机之间的交互或许是不可预测的,表现良好的模型与人类交互中甚至可能出现能力退化的情况。
第三,研究只考察了临床推理的五个方面,但目前已知有几十个其它任务可能对实际的临床护理有更大影响。
第四,研究案例集中在内科,并不能代表所有医疗实践。此外,研究在设计上也未将诊断类型、患者个体差异以及就医地点的不同等因素纳入考量。
研究人员强调,医学领域诊断推理的基准正迅速接近饱和状态,因此亟需开发更具挑战性和贴近实际应用的评估手段。他们呼吁在真实的临床环境中测试这些技术,并为临床医生与人工智能的合作创新做好准备。
专家:AI将逐步渗透医疗典型场景
目前,AI技术在一些医院已初步展开应用,覆盖了分诊导诊、预先问诊和病历生成等多种场景。
美国耶鲁大学教授威廉·基西克(WiliamKissick)提出了著名的“医疗不可能三角”理论。这个理论指出,在既定的约束条件下,一个国家的医疗系统很难同时实现提高医疗服务质量、增加医疗服务可及性和降低医疗服务的价格。现实中的医疗困境,如“看病难、看病贵”以及不断出现的医患矛盾,正是传统医疗体系“医疗不可能三角”的具体表现。
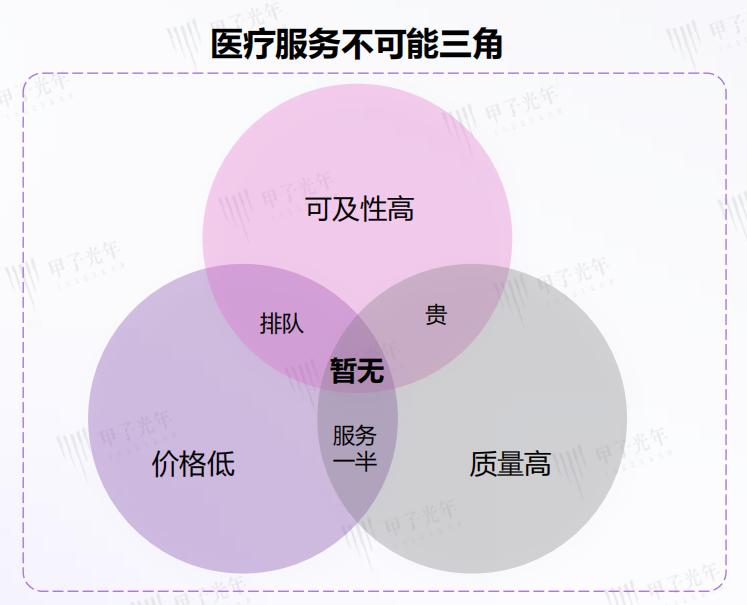
图片来源:甲子光年智库
而医疗AI的兴起可能为解决这一难题提供新的答案。AI赋能下的医疗服务可以大规模接待患者,实现随时随地的无限供应,并且其水平会随着持续训练迅速提升,已经达到了具有10至15年临床经验医生的水准,且每月还在不断进步。
清华大学电子工程系长聘教授、清华大学精准医学研究院临床大数据中心共同主任吴及在接受《每日经济新闻》记者采访时指出,相比自动化、智能设备等场景,AI在医疗场景的应用更为复杂。
吴及提到,医疗本质上是人对人的服务,这一过程非常复杂,医学诊疗不仅包含理论和科学,还涉及大量经验,很多时候依赖专家的直觉。因此,“AI在医疗领域的应用难度较大,但会逐步渗透到一些典型场景中。”
据市场研究机构Global Market Insights的统计,2023年,医疗保健领域的AI市场规模价值为187亿美元,预计到2032年将达到3171亿美元,2024年至2032年的复合年增长率为37.1%。


