

在为提供人工智能功能的工具和应用程序(如 Apple Intelligence)创建大型语言模型(LLM)的过程中,存在的问题之一是首先创建 LLM 的效率低下。 为机器学习训练模型是一个资源密集型的缓慢过程,通常需要购买更多的硬件并增加能源成本。
2024 年早些时候,苹果公司发布并开源了 Recurrent Drafter,即 ReDrafter,这是一种在训练中提高性能的推测解码方法。 它使用 RNN(递归神经网络)草稿模型,将波束搜索与动态树关注相结合,用于预测和验证来自多条路径的草稿标记。
与典型的自动回归标记生成技术相比,这将 LLM 标记生成速度提高了 3.5 倍。
在苹果公司机器学习研究网站的帖子中,苹果公司解释说,除了使用Apple Silicon的现有工作外,该团队并未止步于此。 本周三发布的新报告详细介绍了该团队如何将研究成果应用于 ReDrafter 的创建,使其能够与 NVIDIA GPU 配合使用。
用于生成 LLM 的服务器通常采用 NVIDIA GPU,但高性能硬件往往需要高昂的成本。 仅硬件一项,多 GPU 服务器的成本就超过 250000 美元,更不用说所需的基础设施或其他相关成本了。
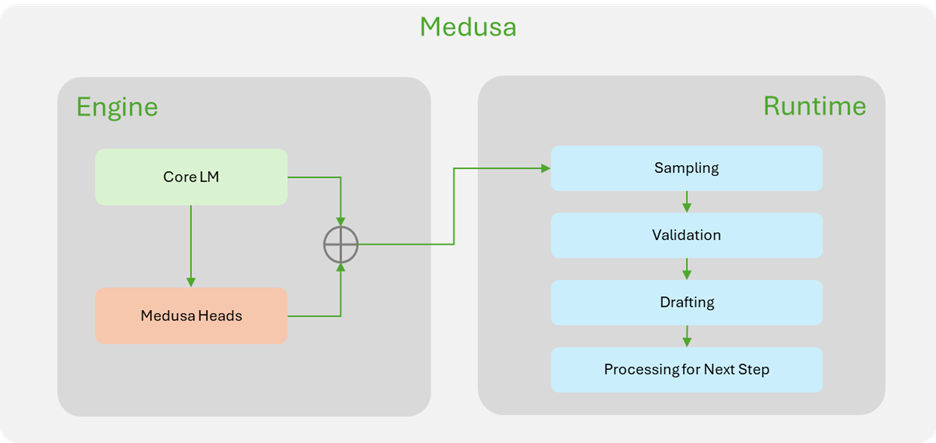

苹果与 NVIDIA 合作,将 ReDrafter 集成到 NVIDIA TensorRT-LLM 推理加速框架中。 由于 ReDrafter 使用了其他推测解码方法没有使用的运算符,因此 NVIDIA 必须添加额外的元素才能使其正常工作。
通过整合,在工作中使用 NVIDIA GPU 的 ML 开发人员现在可以在使用 TensorRT-LLM 进行生产时使用 ReDrafter 的加速令牌生成功能,而不仅仅是那些使用 Apple Silicon 的开发人员。
在 NVIDIA GPU 上对数以百亿计的参数生产模型进行基准测试后发现,贪婪编码的每秒生成令牌的速度提高了 2.7 倍。
其结果是,该过程可用于最大限度地减少对用户的延迟,并减少所需的硬件数量。 简而言之,用户可以期待从基于云的查询中获得更快的结果,而公司则可以在花费更少的情况下提供更多服务。
在 NVIDIA 的技术博客上,这家显卡生产商表示,此次合作使 TensorRT-LLM"功能更强大、更灵活,使 LLM 社区能够创新出更复杂的模型并轻松部署它们"。
该报告是在苹果公司公开证实其正在调查是否可能使用亚马逊的 Trainium2 芯片来训练用于Apple Intelligence功能的模型之后发布的。 当时,该公司预计使用该芯片进行预训练的效率将比现有硬件提高 50%。


