

新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。
这合理吗??
为了真实检验模型数学推理能力,上海人工智能实验室司南OpenCompass团队放大招了。
推出新的复杂数学评测集LiveMathBench,以全新性能指标G-Pass@16来连续评估模型的性能潜力和稳定性。

好家伙!团队在模拟真实用户使用采样策略、重复多次评测大模型的数学推理能力时发现:
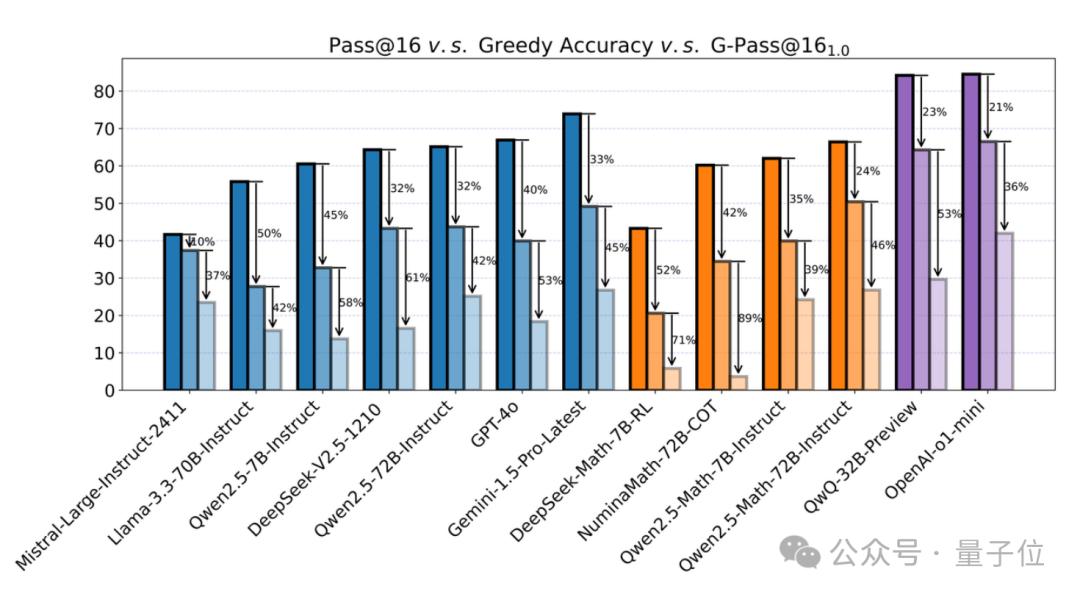
大部分的模型平均会有五成以上的性能下降,即使是最强推理模型o1-mini也会下降3成6,更有模型直接下降九成。
具体咋回事儿下面接着看。
全新评价指标: G-Pass@k
研究团队重新思考了大模型评测常用的技术指标,如传统经常采用的Pass@k, Best-of-N, Majority Voting,这些指标主要关注模型的性能潜力,缺少对模型的鲁棒性的评测。
而真实场景中,为了提高回复的多样性,模型往往使用采样解码的方式进行推理,这也会带来大量的随机性。在复杂推理任务中,这种随机性会严重影响模型的性能,而用户更预期在真实问题中,模型能又稳又好。
Pass@k指标回顾
经典的Pass@k指标关注模型在多次生成中至少给出一次正确答案的概率。假设模型生成次数为,正确答案数为,c表示其中正确解的数量,那么Pass@k的计算方式如下:
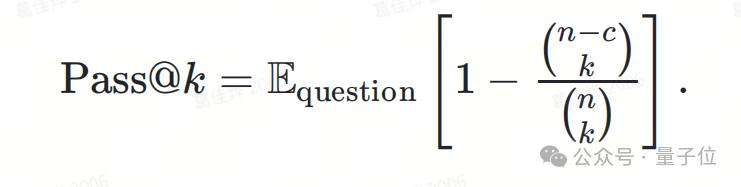
兼顾性能潜力与稳定性的评测指标G-Pass@K
Pass@k体现了模型的性能潜力,却不能体现模型的稳定性,基于这一目的团队将Pass@k推广为Generalized Pass@k(以下简称G-Pass@k)。
通过引入阈值,该工作关注模型在次生成中至少给出 ⎡ · ⎤次正确答案的概率。
一般来说,认为模型的每次生成是i.i.d.(Independent and Identically Distributed)的,那么模型给出的正确答案数服从二项分布,这可以通过超几何分布逼近二项分布。基于此,可以得出G-Pass@k的定义:
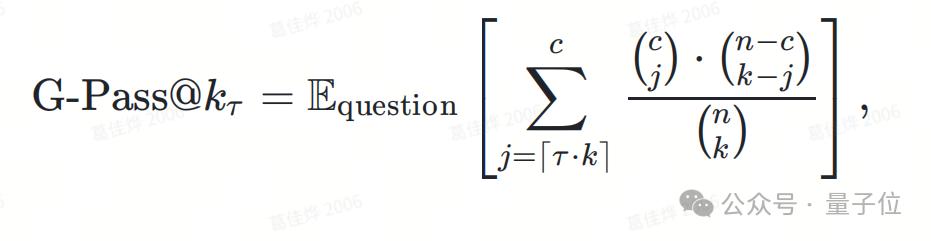
在较小时,G-Pass@k衡量模型的性能潜力;较大时,G-Pass@k衡量模型的稳定性,或者说模型对于问题的掌握程度,因此研究者可以通过G-Pass@k连续地观察模型的性能潜力与稳定性。
进⼀步地,研究团队还定义了mG-Pass@k用于对模型的性能进行整体观测。
具体来说,mG-Pass@k是 —G-Pass@k曲线下的面积,为了更好地模拟真实场景,团队重点考虑∊[0.5,0.1 ]的情况,即:
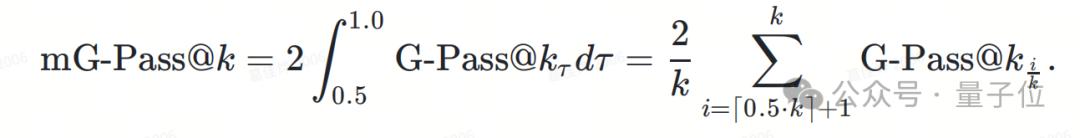
G-Pass@K是Pass@K是泛化形式
当⎡ · ⎤=1时,Pass@K是G-Pass@k等价,这意味着Pass@K是G-Pass@k的特例,读者可以参考论文附录提供的证明。
研究团队给出了两者关系的对比分析,如下图所示:
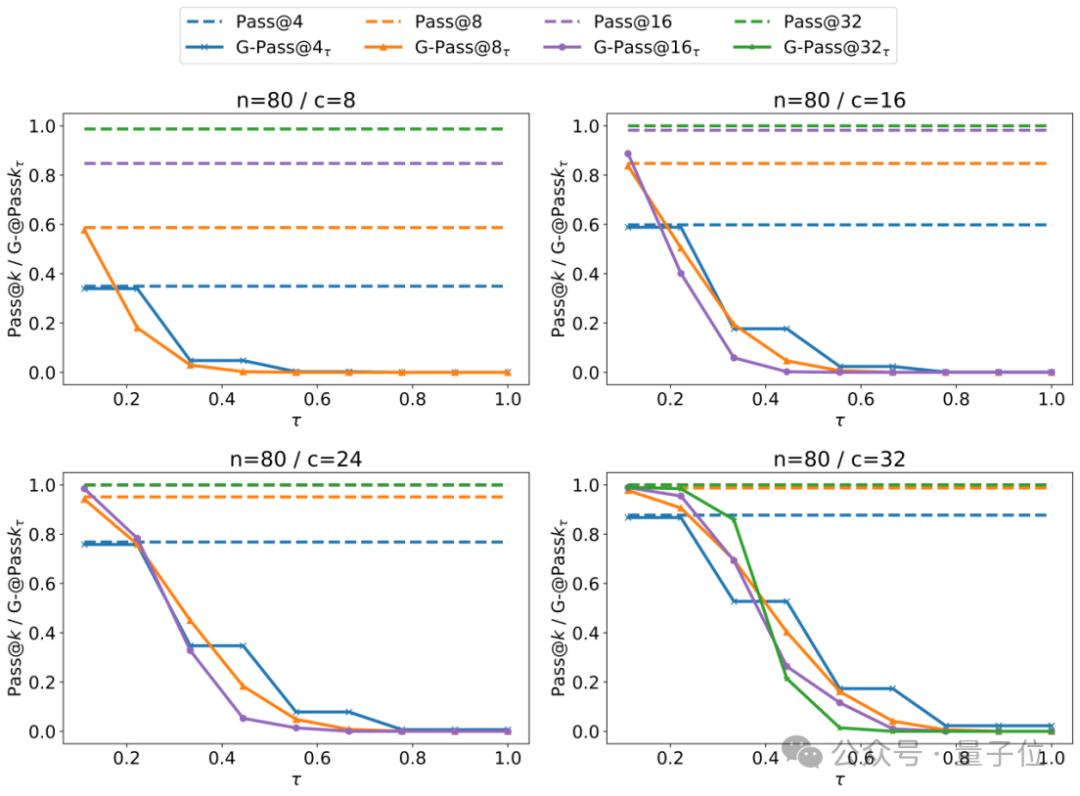
图中展示了不同的和c下Pass@K和G-Pass@k的值,可以看出在较小时,两者反映的是模型的潜力,然而这种分数可能是偏高的,在24/80的整体通过率下,Pass@K指标的值可以接近80%。
但当关注较高的时,更能够观察到模型在实际生成时的真实性能。
LiveMathBench:避免数据污染的复杂数学评测集
研究团队构建了一个新的benchmark LiveMathBench用于验证实验。
具体来说,他们收集了最近发布的中国数学奥林匹克,中国高考最新模拟题,美国数学竞赛和美国普特南数学竞赛中最新的题目,尽量减少数据污染的可能性。
整个LiveMathBench(202412版本)包括238道题目,每个题目提供中文/英文两个版本的题目,覆盖不同的难度。研究团队计划后续持续更新LiveMathBench中的题目,来持续观测LLM的真实数学水平。
另外,研究团队还在两个公开Benchmark MATH500和AIME2024上进行了实验。
对于MAH500,研究团队选择了难度为L5的题目,命名为MATH500-L5;对于AIME2024,研究团队使用了Part1和Part2两个部分全部45道题目,命名为AIME2024-45。
实验
在实验设置方面,对于每道题目,进行了16*3=48次生成并报告G-Pass@16分数。研究团队在通用模型、数学模型和类o1模型三种不同类型的大模型中选择了具有代表性的大模型进行实验。
LiveMathBench性能对比如下:
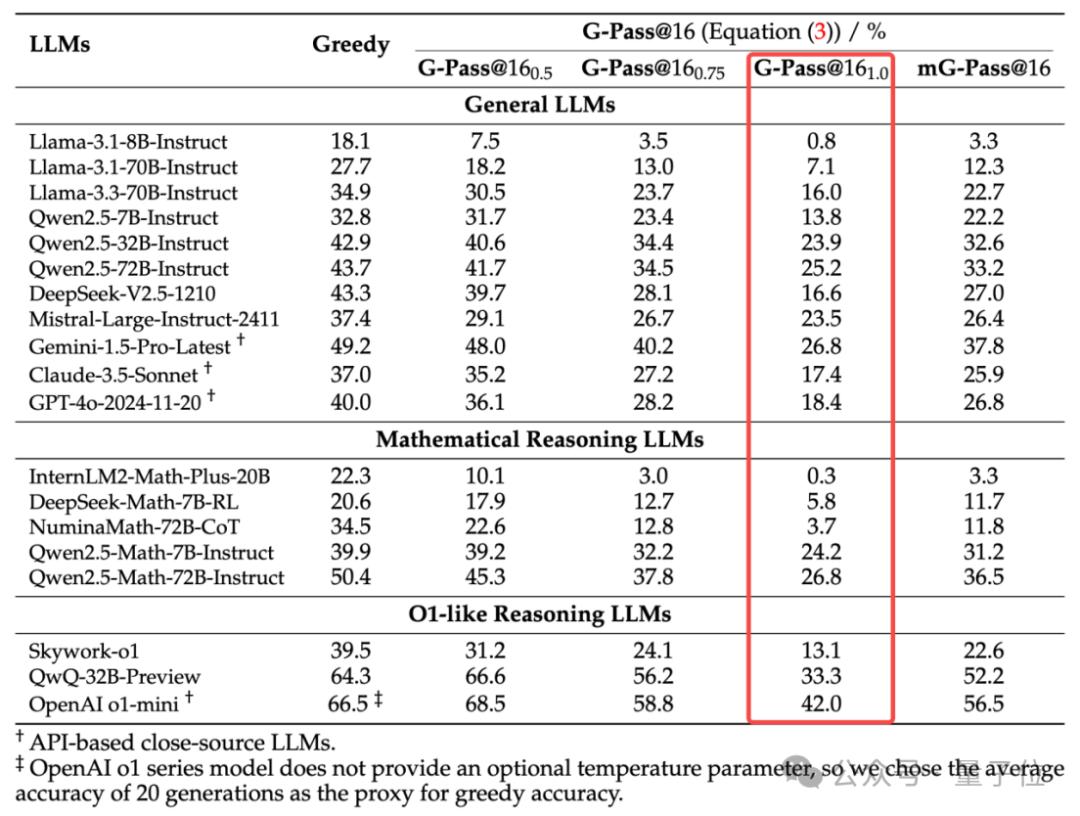
根据实验结果,可以看到:
大部分闭源模型和开源模型在G-Pass@161.0指标上也都不超过30分。
最强的o1-mini模型在G-Pass@161.0获得了最高分42分,相对性能下降比例也是所有模型中最低的(36.9%),虽体现出相对较高的稳定性,但仍然难以忽视。
Math-500-L5/AIME2024-45性能对比如下。
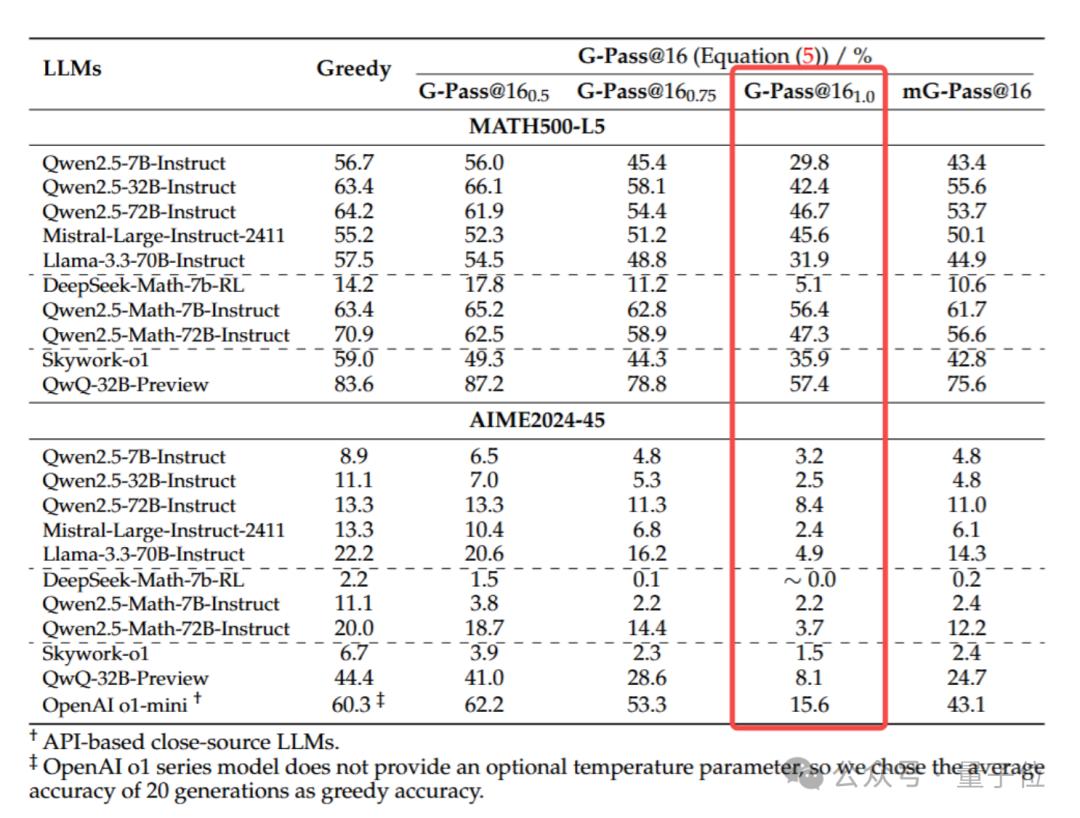
对于开源数据集:
在常用的高中竞赛级别题目MATH500-L5上,多数模型不管是贪婪解码的表现还是稳定性G-Pass@161.0的表现都相比LiveMathBench都有所提升,而AIME2024则相反,大多数模型的G-Pass@161.0分数都只有个位数,甚至部分模型接近0分;
对于难度颇高的AIME2024,虽然o1-min和QwQ-32B-Preview在贪婪解码下表现突出,但面对高难度题目下的稳定性还是难以保证,如QwQ-32B-Preview甚至跌到了不到原来的1/5,而其在MATH500-L5中却比较稳定,达到了原分数的3/5,这也说明了最新的高难度数学题目对模型的稳定性带来了更大的压力。
最后,模型在不同难度题目上的能力分析如下 。
下表展示了关键模型在LiveMathBench两个子集上的性能表现。
其中CCEE代表中国高考题目,主要涉及到基础的高中数据知识;而WLPMC代表来自普特南(Putnam)竞赛的题目,普特南竞赛是久负盛名的美国大学生数学竞赛,其题目难度要高于高考题目。
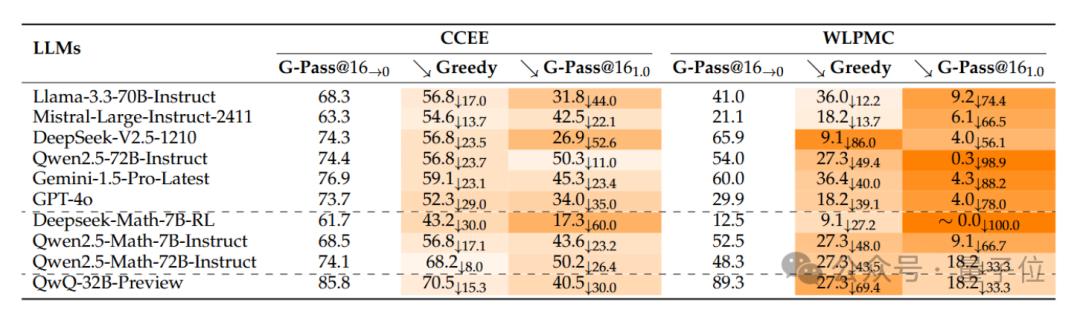
由实验结果可以看出,先进的推理模型,例如DeepSeek-V2.5, Qwen2.5-72B-Instruct, QwQ等在Pass@16指标下在两个子集上都有较好的性能,但大部分模型在WLPMC上的稳定性下降更为严重。
因此可以有如下猜想,推理模型容易学习到训练数据中的平凡解,导致Pass@k等指标的上升,然而在困难的问题上,这种提升并不与模型真实推理性能提升相关。在强基座模型的训练中,更应该关注推理稳定性的表现,以提升其真实推理能力。
重要观测
观察一:闭源和开源模型均不能稳定地进行复杂推理
研究人员对当前主流的约20个模型进行了测试,发现尽管多数模型在贪婪解码的准确率Greedy Accuracy和Pass@16上表现相对较好,但当使用G-Pass@K指标进⾏评估时,性能却显著下降。
当设置为1.0时,即要求模型在所有16次采样中都提供正确答案, 几乎所有模型的表现都急剧下降。
例如,在对LiveMathBench的测评中,Llama-3.1-8B-Instruct模型的准确率从18.1%下降到0.8%(G-Pass@16=1.0),降幅高达95.7%。即使是较大的模型,如NuminaMath-72B-CoT,其准确率也从34.45%下降到3.7%,减少了89.3%。
在大约20个测试模型中,平均性能下降了60%。即便是表现最为稳定的OpenAI o1-mini,其准确率也从66.5%下降到42.0%,降幅为36.9%。
即使将放宽到0.5,即只要求一半的样本正确即可通过,通用模型、数学推理模型和o1-like模型仍分别经历了14.0%、22.5%和4.8%的平均性能下降。
这表明,在复杂条件下,多数模型难以在多次采样中保持一致的推理能力。
不过目前的评估指标通常依赖单次贪婪解码,可能无法充分反映这些模型在实际应用中的鲁棒性和稳定性。
因此,研究团队指出,需要对模型的推理能力进行更严格的评估,尤其是在那些需要在多次采样中保持一致性和可靠性的重要应用中。
观察二:增大模型规模对推理能力的提升有限
研究人员观察到,以同系列模型Qwen2.5-32B-Instruct与Qwen2.5-72B-Instruct为例,虽然它们的模型规模相差一倍以上,但无论指标采用G-Pass@K还是Greedy Accuracy,无论评测数据集是最新的LiveMathBench还是现有开源数据集,两者的表现均相似。
另外,在更大体量的模型Mistral-Large-Instruct-2411(123B)上,尽管模型规模继续增大,但其性能和稳定性相比 Qwen2.5-72B-Instruct 却出现下滑。
这表明,对于需要深度理解和逻辑推理的任务,简单增大参数并不能显著提升性能或稳定性。
这可能是因为这些任务不仅需要模型具备记忆和模式识别能力,更需要强大的推理和上下文理解能力。
观察三:模型的性能潜力和实际表现之间的巨大差距
研究团队在评估模型性能时发现,理论最大能力G-Pass@16→0、实际表现能力Greedy Accuracy和多次采样下的稳定能力G-Pass@16=1.0之间存在显著差距。
尽管模型在理论上具备相当高的潜在性能,但在实际应用中未能充分展现这一水平,尤其是在输出稳定性方面。一些模型在单次贪婪解码中表现出高准确率,显示出处理特定任务的潜力,但在保持一致高准确率方面却不稳定,远未达到最佳性能。
这反映了现有模型在推理稳定性和一致性上的不足,这在训练和评估中常被忽略。
模型在单次推理表现中易受输入数据变化、初始化状态或随机采样的影响,导致不同采样解码的结果不一致。
研究人员指出,在高可靠性和一致性要求的实际应用中,如何在保持接近最佳性能的同时确保输出的稳定性,是一个亟待解决的问题。
总结
本研究深入分析了当前大型模型的数学推理能力,提出了全新的性能指标G-Pass@16 ,用于连续评估模型的性能潜力和稳定性。
此外,还设计了避免数据污染的LiveMathBench数据集。
实验结果显示,目前的大型模型在推理性能方面未达到预期,尤其在多次重复采样时,性能出现显著下降。研究团队期望学术界和工业界能够在推理能力的鲁棒性研究上持续探索与推进。


