

在OpenAI发布会还在“产品雕花”的时候,谷歌继续努力更新基础模型。半个月前是3D场景生成基础模型、一周前是大杀四方的Gemini 2,而今天则是视频生成模型。
北京时间12月17日,谷歌发布了其文生视频模型Veo的下一个版本Veo 2。此次升级距离谷歌在今年5月的I/O大会上首次宣布Veo已经过去7个月。
但Veo仅在十几天前的12月3日才登上Axtrix,在这之前,用户只能利用VideoFX中的实验工具小规模试用这一视频生成软件。
这一版本主要带来三个核心升级。首先是真实感和保真度大为增加,它支持对长度为8s、清晰度为4K视频的输出,并在细节、真实性和伪影减少方面提升巨大。
其次,Veo以其对物理学的理解及遵循详细指令的能力,能够高度精确地捕捉运动。这正是前几日Sora频频翻车的点。
第三,Veo 2还提供了更多的相机控制选项,你可以输入诸如“镜头缓慢推进她的面庞”、“摄像机在追逐车辆的过程中趋于稳定”、“极近的特写镜头”来去描述你需要的镜头模式。

当然,从目前谷歌给出的范例来看,Veo 2 对物理世界的理解确实达到了相当的高度,尤其是人类乃至昆虫的动作表现,这些动作与世界交互的自然感都很强。比如这只用喙捕猎的火烈鸟,它激起的水花就不想Sora前两天演示时那种火山爆发般的夸张。

在实际的测试中,Veo也得到了SOTA的水平。谷歌选取了其他包括Sora在内的顶尖模型,在Meta发布的基准数据集MovieGenBench 上比拼了 1003 条提示及其对应视频。
从整体表现上看,Veo占优的情况都接近或超过了50%,不占劣势的情况则能达到70%左右。
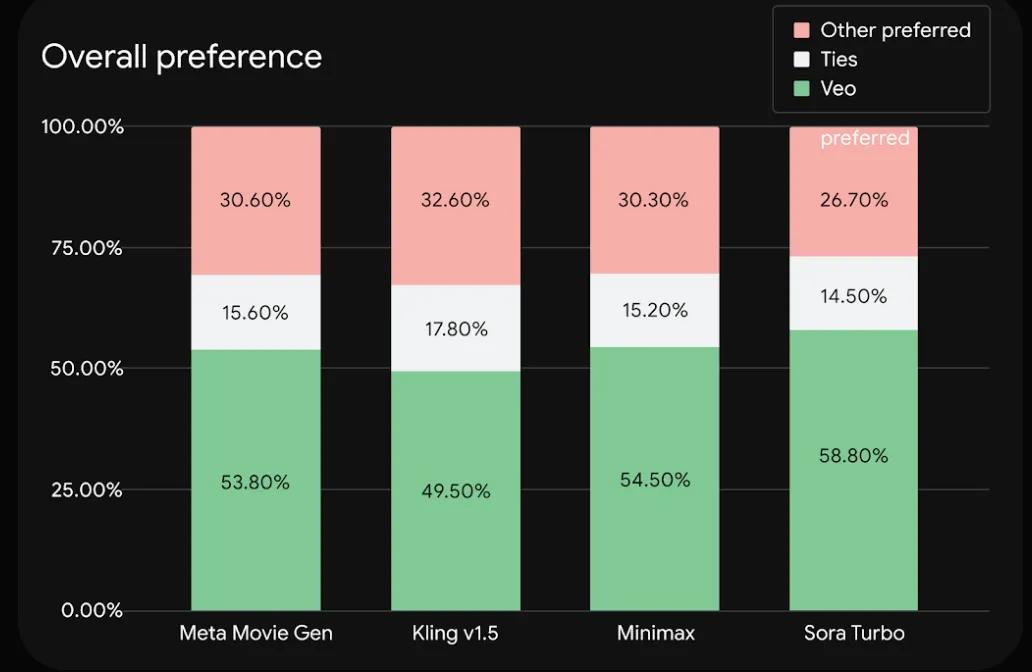
比较有趣的事,Sora Turbo在谷歌测试的所有模型中居然是表现最差的,而表现最好的是可灵1.5。
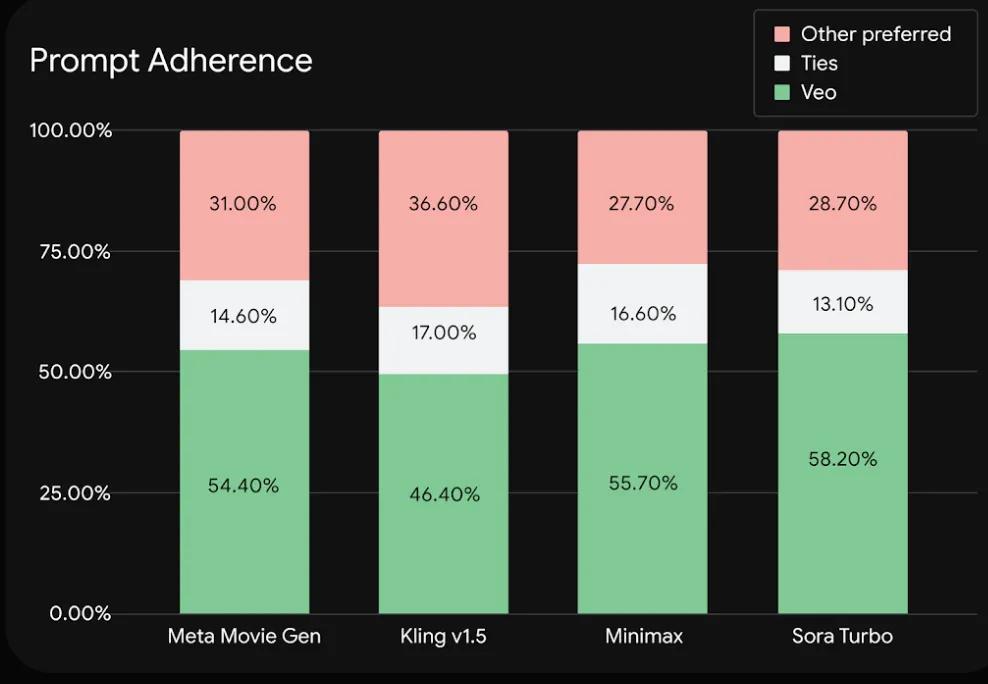
在指令遵循上,Veo表现也达到了SOTA,其他个个模型也和整体表现排名差异不大。
在报告中,谷歌承认了自己的模型也有短板。在复杂场景或复杂运动中保持完全的一致性仍然没法被突破。在他们自己给出的范例中,依然会出现凭空出现的人物。在运动中,人也可能依然出现那种不自然的“AI扭曲”。

在推特上,已经有一些网友做了测试。表明Veo 2的镜头控制和运动能力所言不虚。在提示词为“一个人坐在咖啡馆里喝咖啡的视频。过了一会儿,镜头切换到另一个视角,显示旁边桌的人正在给他们写信。”的情况下,Veo 2可以很好的完成导演叙事的镜头切换,写作的动作也非常自然。

而将同一个提示词给到Sora,它首先无法实现镜头切换,对于提示词中两个人对坐也未跟随,画面中只有一个人。而且写作动作也有点像是悬空画笔。

之后我们还测试了其他的顶尖模型。比如海螺,它无法实现镜头切换,但用变焦实现了部分镜头切换的逻辑,空间和两个人物的关系也符合提示词。

混元的影视氛围感直接拉满,也完成了切镜。但视频中两人的关系交代没有那么清晰。

可灵确实是表现最好的一个,切镜、两人的关系都把握住了。除了审美和细节上不如Veo 2外,其它部分都近乎完美。

在另一个测试中,用同样的提示词

这是Veo 2的结果

这是Sora的结果
就算Veo 2的输出是有瑕疵的,但Sora这个迟缓、空荡的场景已经输太多了。
至于其他模型,可灵输出的场景感不错,但弄臣的现实非常刻意,从空间关系上看也不太可能,其中还有很多残影。

而海螺则是在提示词遵循上仅次于Veo 2,只是没有满足“镜头从女王背后取景”这点。但细节还原就较Veo 2差不少了。

看了这么半天,谷歌评测中说的Sora最差不无道理。
2025年还没开始,OpenAI的王冠看起来就有点不稳了。怪不得连微软CEO最近在采访中都豪言“没有OpenAI,我们也能开发出最一流的模型。”
看来,在这场AI战争中,还有的是逆转的好戏。
不过谷歌这回还是没改画饼的毛病。Veo 2 现在依然在内测阶段,只能在VideoFX上排队申请。希望它在25年全量和新产品发布的速度都能提起来。把画饼大师的定位让给OpenAI。毕竟Sora花了9个月才发出来,也和过去的谷歌不相上下了。


