


新智元报道
编辑:编辑部 HYZ
【新智元导读】OpenAI的Sora翻车后,迎来谷歌的暴击:昨天深夜,Veo 2、Imagen 3、Whisk一套组合拳打来,AI视频和生图根据,再次被谷歌改变了。
就在昨天,谷歌再次爆打OpenAI。
全新发布的Veo 2,实测效果已经被许多人公认「超越Sora」。
作为谷歌最先进的视频生成模型,Veo 2更好地理解现实世界物理和运动的细微差别,理解电影摄影语言的能力(如镜头类型和效果),分辨率高达4K。

同时放出的,还有Imagen 3图像生成模型,和用图像而非文本作为prompt的工具Whisk。
无论是在LLM上,还是在视觉创作上,谷歌正在缩小和OpenAI的差距。
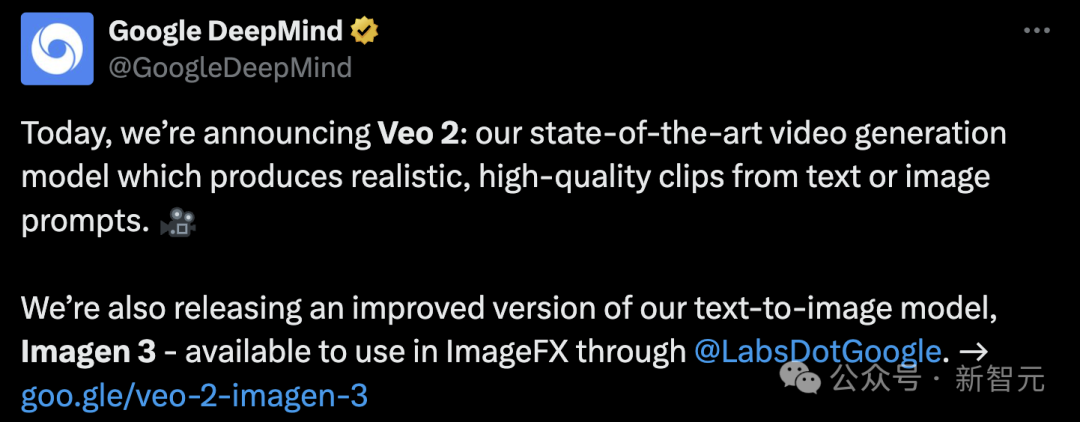
举个栗子,我们用相同的提示「A pair of hands skillfully slicing a ripe tomato on a wooden cutting board」生成一个切西红柿的视频。

在Veo 2中,西红柿不仅会随着刀子的前后移动而移动,并且其横断面清晰可见。切片虽略显厚实,但前后始终保持一致,而且还能正确地叠放起来。
相比之下,Sora不仅照着手指疯狂下刀,而且切了半天的西红柿依然「完好无损」……

Veo 2

Sora
难怪有网友说,在理解物理世界和一致性上,Veo 2已经到了next level。

高达4K的分辨率,大大提升的细节和真实感,人体动作和表情的改善,以及更好的物理建模和时间一致性,都让Veo 2达到了顶级AI视频模型的级别。
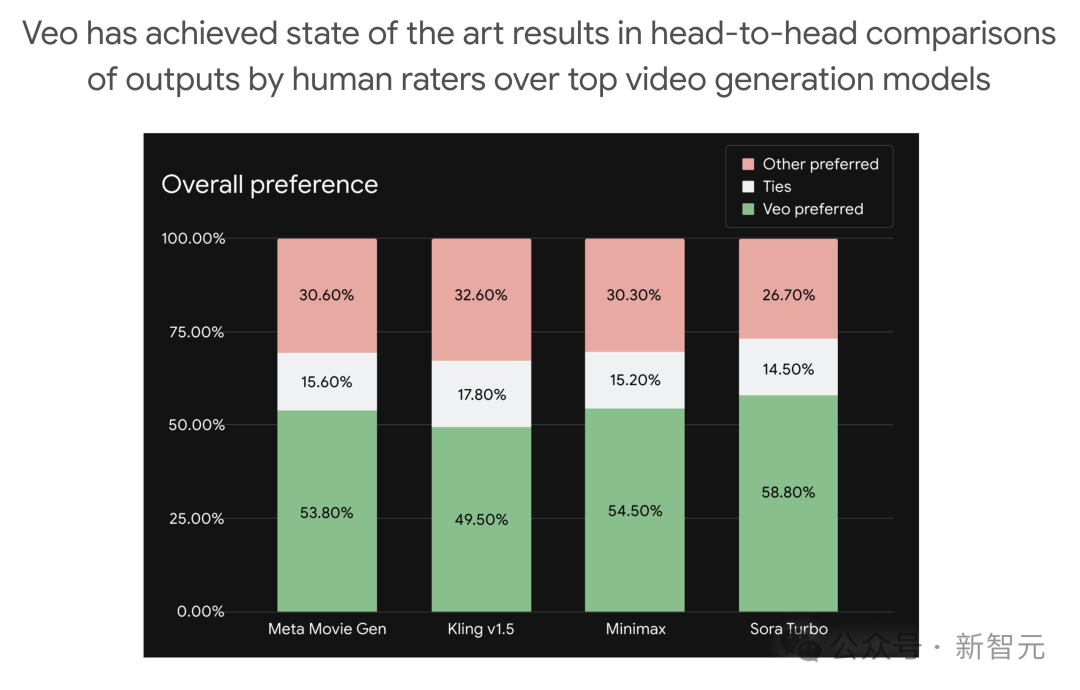
在Meta的Movie Gen Bench上,Veo已经可以和Kling、Minimax、Sora掰手腕了

Veo 2强势升级,4K电影级画质
想象一下,只用简单文字描述,就能生成高达4K、超长分钟的精美视频。
Veo 2正是这样一个颠覆性的创新。
它可以遵循简单和复杂的指令,并在物理模拟过程中,展现出令人惊叹的生成质量。

镜头如清风般轻柔地穿梭在粉彩色的木制蜂箱之间,勤劳的蜜蜂翩翩起舞,时隐时现于画框之中。画面缓缓停驻在场景中央那位气质优雅的养蜂人身上,他身着的洁白养蜂服在金色的午后阳光中熠熠生辉。他轻抬着一罐琥珀色的蜂蜜,略微倾斜着让阳光透过蜜液折射出温暖的光晕。在他身后,一片高大的向日葵随着微风轻轻摇曳,金黄的花瓣在温暖的阳光照耀下绽放出柔和的光芒。镜头徐徐上移,展现出一座典雅的乡村老宅,薄荷绿色的百叶窗点缀其间,摇曳的树影在墙面上织就出斑驳的光影图案。这组照片采用35毫米镜头搭配柯达Portra 400胶片摄制,浸润在金色光线中的每一个细节——养蜂人的手套、晶莹的蜂蜜罐、饱经岁月的蜂箱木纹,都呈现出丰富而细腻的质感层次
现在,Veo 2可以像电影摄影师一样和我们交流。不必再费力和它讨论技术参数、猜测Gemini的标题,只要用习惯的术语说出想要的内容即可。

Veo 2生成的经典追车场景
另外,我们还可以进行更精确的相机控制,比如下图就是一个包含第一人称视角、转移焦点的提示。
可以看到,车内的皮革内饰、车速表等高频细节,给人留下极其深刻的印象。

通过人类评估,Veo 2模型在与几大顶尖视频模型的对比中,脱颖而出。
它不仅仅是简单地生成视频,更是对现实世界物理规律、人类动作,表情方面得到了极致的理解。
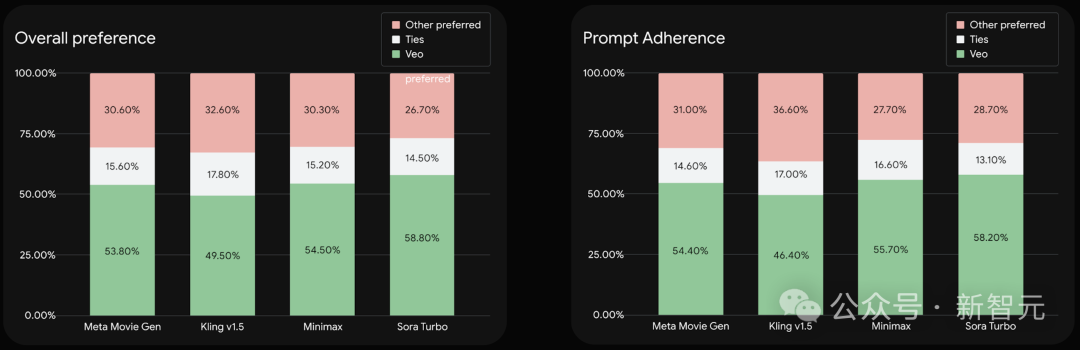
对此,谷歌总结了新模型的三大亮点:
首先是, 增强的真实感和保真度。
相较于其他的AI视频模型,Veo 2在细节、真实感、伪影减少方面得到了显著的改进。
其次是,领先的运动能力。
Veo 2能以精确的方式生成运动画面,这主要归功于它对物理学的理解、和遵循详细指令的能力。
第三个是,更强大的相机控制选项。
它能精确理解指令,创建各种拍摄风格、角度、运动效果,以及这些元素的组合。
对于创作者而言,Veo 2就像是一个无所不能的AI导演。你可以指定电影类型、镜头风格,甚至是特定的电影技巧,它皆可完美呈现。
比如这位在显微镜前科学家的面部特写。

富有电影感的镜头捕捉了一位身着暗黄色生化防护服的女医生,实验室惨白的荧光灯将她的身影笼罩其中。镜头缓缓推进她的面部特写,细腻的横向推移突显出她眉宇间深深刻画的忧思与焦虑。她专注地俯身于实验台前,目不转睛地透过显微镜观察,手套包裹的双手正谨慎地微调着焦距。整个场景笼罩在压抑的色调之中,防护服呈现出令人不安的黄色,与实验室冰冷的不锈钢器械相互映衬,无声地诉说着事态的严峻和未知的威胁。景深精确控制下,镜头对准她眼中流露的恐惧,完美传达出她肩负的重大压力与责任
再比如,一个从场景中间滑过的低角度追踪镜头。

晨光徐徐升起,为这幅精心布置的早餐图景镀上一层温暖的金边。金黄色的枫糖浆如丝绸般缓缓流淌,轻柔地浇注在层层叠起的蓬松松饼上,每一片松饼都袅袅升起缕缕暖意盎然的水汽。特写镜头捕捉着金黄酥脆的培根,只见它滋滋作响,细小的油珠在阳光下化作金色光点翩翩起舞。醇香的咖啡优雅地旋转注入通透的玻璃杯中,逐渐在杯中漾开层层叠叠的焦糖色咖啡奶泡。最后,镜头如潜水般俯入一枚刚切开的鲜橙,以震撼的微距视角展现出饱满晶莹、汁水四溢的果肉纹理
更令人惊叹的是,Veo 2对专业术语的理解。
只需在提示中输入「18mm lens」,Veo 2就得知创建拍摄广角镜头,或在提示中加入「浅景深」(shallow depth of field)它便可模糊背景,突出主体。

不仅如此,Veo 2很少有「幻觉」,比如AI视频中多出的手指问题。
沃顿商学院教授Ethan Mollick实测Sora时,结果发现水獭在飞机上使用WiFi的画面中,长出了人类的手,非常诡异。

看看Veo 2在双手细节的生成,堪称极致。

当然,Veo 2生成的视频,并非没有破绽。
它在创建逼真、充满活力或复杂的视频,以及在复杂的运动场景中,难以保持一致性。
下面这位冰上舞者的双腿,在复杂的前进运动中,出现了变形。
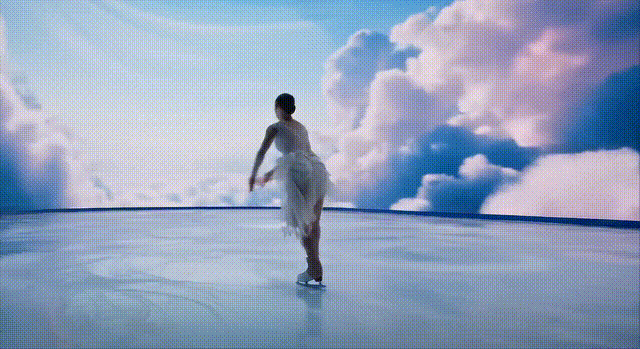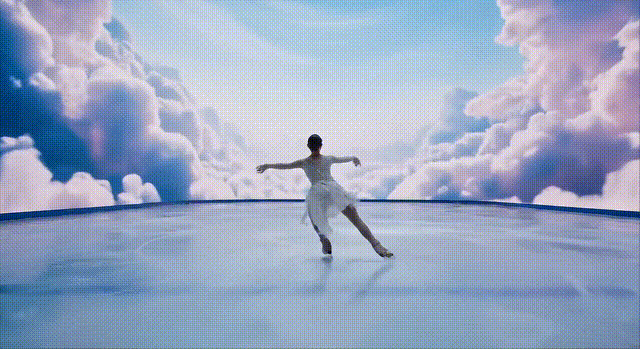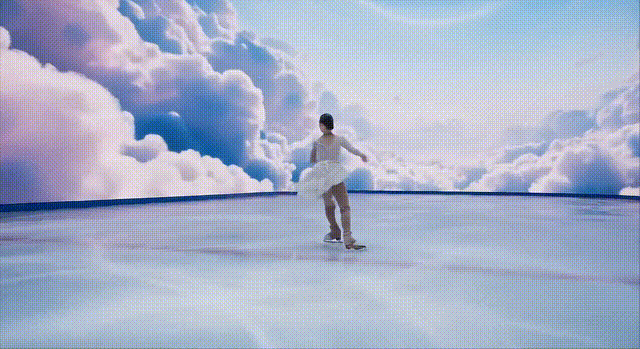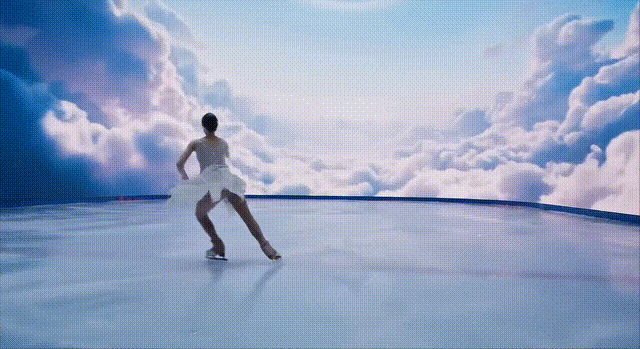
滑滑板的男孩,在空中翻越时,双腿双手出现了幻觉。

在安全性方面,谷歌为Veo 2加入了隐形的SynthID水印,有助于一眼识别是AI生成的内容。
目前,Veo 2已经登录VideoFX,预计明年它将进军YouTube Shorts等平台,为内容创作者开启全新的可能性。
下面分享了Veo 2更多优秀的demo:








左右滑动查看
Imagen 3:颜色明亮,构图更精准
今天,备受期待的Imagen 3同时迎来了重大升级。
这次升级的提升,堪称革命性。首先是图像的整体质感,更加明亮,构图更为精准。



宛如知名漫画师创作的橙发少女,像游戏设定一般宏大的幻想世界,难以分辨是AI还是照片的黑白人像(左右滑动查看)
在艺术风格的表现上,从照片级写实到印象派绘画,从抽象艺术到动漫风格,Imagen 3都能实现更为准确的还原。
其次,它能精准执行用户的提示词指令,呈现出更为细腻的细节和更丰富的纹理效果。
在与其他顶级AI生图模型对决中,Imagen 3取得了最优的人工评估结果。

Imagen 3生成的图像,在所有风格上都得到了提示,包括照片写实主义、印象主义、动画和抽象主义。

特写镜头下,工匠的双手在陶轮上塑造着一件泛着光泽的陶器。金色的光芒如丝如缕,连接着陶艺师的手与黏土,随着动作优雅流转。工作室内充满丰富的质感——布满工具的尘旧架子、散落的陶土碎片,以及透过木制百叶窗洒落的自然光束。光线与能量的交织营造出一种空灵、近乎魔幻的氛围
下面这种冬日雪地中红松鼠的特写,仿佛高清大片,无论是松鼠的皮毛、空中的雪花,还是背景中松针的虚化,都体现出了细节的考究。

特写镜头捕捉了一个冬日仙境场景——柔软的雪花飘落在被雪覆盖的森林地面。在一根结霜的松枝后,一只红松鼠静静地坐着,它明亮的橘红色皮毛在白色背景中格外醒目。它捧着一颗榛子,享用美食时似乎完全忽视了周围飘落的雪花
在1940年代风格的欧洲火车站,一对恋人深夜在火车前相拥,整个场景让人想起众多电影中的离别场景。

1940年代的欧洲火车站笼罩在晨雾中,精致的铸铁拱门和蒙雾的玻璃窗勾勒出车站的轮廓。蒸汽从铁轨上袅袅升起,与浓雾交融。一对恋人在火车旁深情相拥,昏暗的琥珀色灯光将他们的身体勾勒成剪影。即将启程的火车若隐若现,红色的尾灯在雾中渐渐淡去。女子身着褪色的红色外套,紧握着一本小皮日记,男子则穿着饱经风霜的军装。空气中漂浮的尘埃在柔和的金色背光中闪烁。整个场景弥漫着忧伤而永恒的气息,令人联想起战时电影中那些刻骨铭心的离别场景
浅景深拍摄的亚洲女子肖像,光影效果一绝。

一幅亚洲女性的肖像,背景是幽绿的霓虹灯光,采用浅景深拍摄
超现实的场景,Imagen 3也能精准把握,比如下面这只草莓蜂鸟。整个图像呈现出高分辨率的专业摄影手法,景深控制让蜂鸟和花在虚化的背景中更显生动。

一张精妙的微距素材照片,展现了一颗精心雕刻成蜂鸟形状的草莓,栩栩如生地呈现出蜂鸟正在啜饮鲜艳管状花朵花蜜的瞬间,翅膀因快速振动而形成朦胧的动感。背景是一片生机盎然的彩色花园,经过柔化处理呈现出梦幻般的虚化效果。图像细节丰富,采用浅景深拍摄,使草莓蜂鸟保持锐利清晰的焦点,同时让背景自然柔和。高分辨率的专业摄影手法和柔和的打光让整个场景层次分明,专业的色彩分级更突显了画面的鲜艳色彩,创造出清晰度极高的视觉效果。精确的景深控制让蜂鸟和花朵在虚化的背景中更显生动突出
一拖一创,风格任意定
不仅如此,谷歌还推出了一个全新的尝试——生成式AI实验性项目Whisk。

以往,我们都需要输入冗长、详细的文字提示来生成图像,Whisk彻底改变了这一形式,现在只用图像就可了。
把图片简单一拖,Whisk就能帮我们创作。

在Whisk中,我们可以通过上传图片,来定义主体、场景和风格,然后将它们重新混合,创造出自己独特的作品,比如数字玩偶、珐琅徽章、精美贴纸。
下面,你会看到想象大开的梦幻鱼、粉色花环海象、糖粉甜甜圈和长角的奇幻生物猫。




左右滑动查看
为什么用图像的prompt就能生图?
这是因为在系统底层,Gemini模型会自动为我们上传的图片生成详细的文本,随后文本会被输入到Imagen 3中处理。
而这一过程,绝非简单地复制原图,而是重点提取主题的核心特征,由此才能让我们自由组合不同主题、场景和风格元素。
当然,由于Whisk只会提取图像中的几个关键特征,因此生成图像也可能会和我们的预期不同。
你可能也看出来了,Whisk并不像传统的图像编辑器,进行像素级的完美编辑,而是一种崭新的创意工具,让人创造性地探索天马行空的想法。
就如谷歌所说,它的核心价值,是自由尝试各种可能性,在各种创意方式中进行极致的探索,保留下自己最满意的作品。


