

没有外部数据,AI 自己也能进化?
听起来有点吓人,于是谷歌 DeepMind 的这项研究很快引起了广泛关注。

论文地址:https://arxiv.org/pdf/2411.16905
新的方法被命名为「苏格拉底式学习」(Socratic Learning),能够使 AI 系统自主递归增强,超越初始训练数据的限制。

研究人员表示,只要满足三个条件,在封闭系统中训练的智能体可以掌握任何所需的能力:
a)收到足够信息量和一致的反馈;
b)经验 / 数据覆盖范围足够广泛;
c)有足够的能力和资源。
本文考虑了假设 c)不是瓶颈的情况下,在封闭系统中 a)和 b)会产生哪些限制。
苏格拉底式学习的核心是语言游戏(即结构化的交互),智能体在其中交流、解决问题并以分数的形式接收反馈。
整个过程中,AI 在封闭的系统中自己玩游戏、生成数据、然后改进自身的能力,无需人工输入。如果游戏玩腻了,AI 还可以自己创建新游戏,解锁更多抽象技能。
Socratic Learning 消除了固定架构的局限,使 AI 的表现能够远超其初始数据和知识,且仅受时间的限制。
迈向真正自主的 AI
考虑一个随时间演变的封闭系统(无输入、无输出),如下图所示。
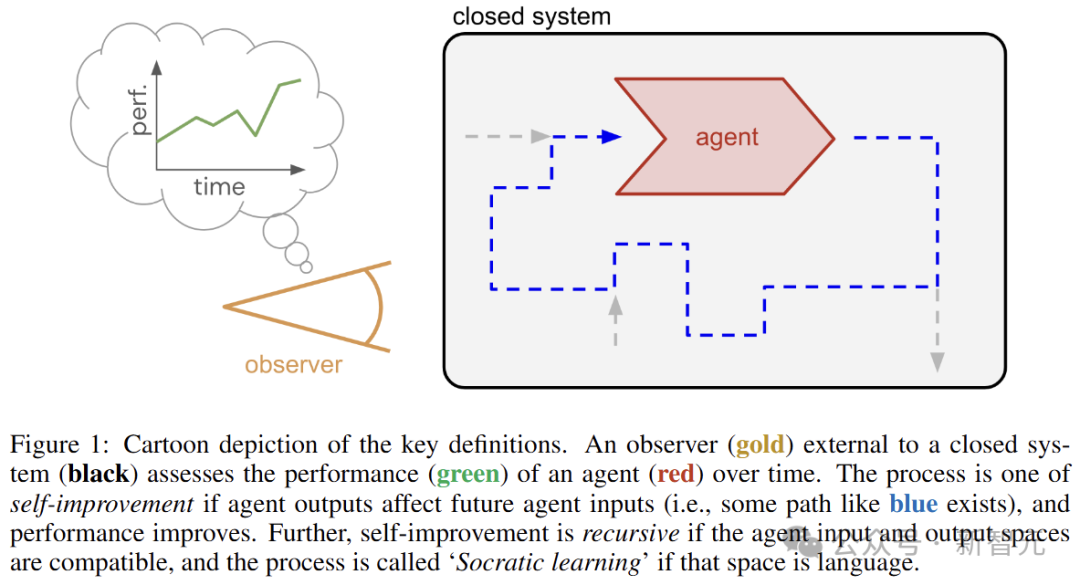
在系统中,有一个具有输入和输出的实体(智能体,agent),它也会随着时间的推移而变化。系统外部有一个观察者,负责评估智能体的性能。
由于系统是封闭的,观察者的评估无法反馈到系统中。因此,智能体的学习反馈必须来自系统内部,例如损失、奖励函数、偏好数据或批评者。
考虑蓝色虚线的路径,让智能体输出影响未来的智能体输入,并且性能得到提高(自我改进过程),如果输入和输出空间兼容,则这种自我提升是递归的。
自我提升过程的一个典型例子是自我博弈,系统让智能体作为游戏的双方,从生成一个无限的体验流,并带有获胜反馈,来指导学习的方向。

反馈是其中的关键一环,AI 的真正意义是相对于外部观察者的,但在封闭的系统中,反馈只能来自内部的智能体。
这对于系统来说是一个挑战:让反馈与观察者保持一致,并在整个过程中保持一致。
RL 的自我纠正能力在这里并不适用,可以自我纠正的是给定反馈的行为,而不是反馈本身。
苏格拉底式学习
与输出仅影响输入分布的一般情况相比,递归的自我提升更具限制性,但中介作用更少,最常见的是将智能体输出映射到输入的环境实例化。
这种类型的递归是许多开放式流程的一个属性,而开放式改进正是 ASI 的一个核心特征。
输入和输出空间兼容的一个例子是语言。人类的广泛行为都是由语言介导的,特别是在认知领域。
语言的一个相关特征是它的可扩展性,即可以在现有语言中开发新的语言,比如在自然语言中开发的形式数学或编程语言。

综上,本文选择研究智能体在语言空间中递归自我提升的过程。苏格拉底式学习,模仿了苏格拉底通过提问、对话和重复的语言互动,来寻找或提炼知识的方法。
苏格拉底并没有去外界收集现实世界中的观察结果,这也符合本文强调的封闭系统。

局限性
在自我提升的三个必要条件中,覆盖率和反馈原则上适用于苏格拉底式学习,并且是不可简化的。
从长远角度来看,如果计算和内存保持指数级增长,那么规模限制只是一个暂时的障碍。另一方面,即使是资源受限的场景,苏格拉底式学习可能仍会产生有效的高级见解。
覆盖率意味着苏格拉底式学习系统必须不断生成数据(语言),同时随着时间的推移保持或扩大多样性。
生成对于 LLM 来说是小菜一碟,难的是在递归过程中防止漂移、崩溃或者生成分布不够广泛。
反馈要求系统继续产生关于智能体输出的反馈,这在结构上需要一个能够评估语言的批评者,且应与观察者的评估指标保持充分一致。
然而,语言空间中定义明确的指标通常仅限于特定的任务,而 AI 反馈则需要更通用的机制,尤其是在允许输入分布发生变化的情况下。
目前的 LLM 训练范式都没有足以用于苏格拉底式学习的反馈机制。比如下一个标记预测损失,与下游使用情况不一致,并且无法推断训练数据之外的情况。
根据定义,人类的偏好是一致的,但无法在封闭系统的学习中使用。将人类偏好缓存到学习的奖励模型中或许可行,但从长远来看,可能会产生错位,并且在分布外的数据上效果也很弱。
换句话说,纯粹的苏格拉底式学习是可能的,但需要通过强大且一致的批评者生成广泛的数据。当这些条件成立时,这种方法的上限就只取决于能够提供的计算资源。
LANGUAGE GAMES ARE ALL YOU NEED
语言、学习和基础是经过充分研究的话题。其中一个特别有用的概念是哲学家 Wittgenstein 提出的「语言游戏」。

对他来说,捕捉意义的不是文字,而需要语言的互动性质才能做到这一点。
具体来说,将语言游戏定义为交互协议(一组规则,可以用代码表达),指定一个或多个智能体(玩家)的交互,这些智能体具有语言输入和输出,以及在游戏结束时每个玩家的标量评分函数。
这样定义的语言游戏解决了苏格拉底式学习的两个主要需求:为无限的交互式数据生成提供了一种可扩展的机制,同时自动提供反馈信号(分数)。
从实用的角度来看,游戏也是一个很好的入门方式,因为人类在创造和磨练大量游戏和玩家技能方面有着相当多的记录。
实际上,许多常见的 LLM 交互范式也能被很好地表示为语言游戏,例如辩论、角色扮演、心智理论、谈判、越狱防御,或者是在封闭系统之外,来自人类反馈的强化学习。
Wittgenstein 曾表示,他坚决反对语言具有单一的本质或功能。
相比于单一的通用语言游戏,使用许多狭义但定义明确的语言游戏的优势在于:对于每个狭义的游戏,都可以设计一个可靠的分数函数(或评论家),这对于通用游戏来说非常困难。
从这个角度来看,苏格拉底式学习的整个过程就是一个元游戏,一个安排了智能体玩和学习的语言游戏(一个「无限」的游戏)。
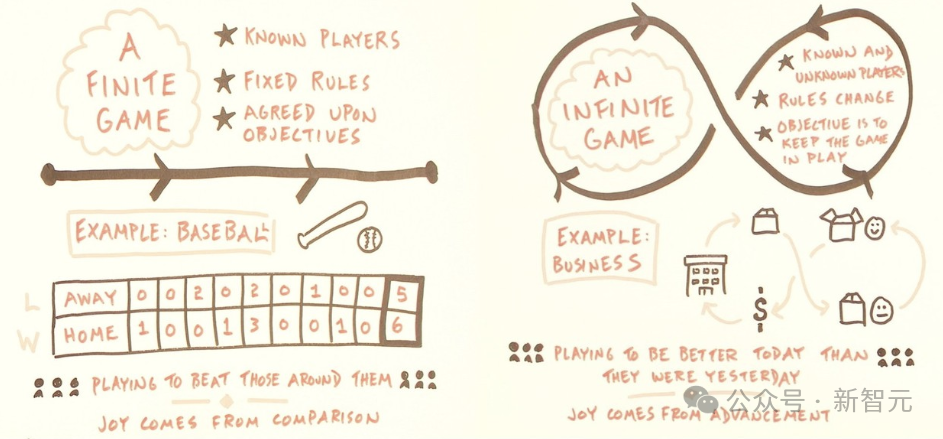
苏格拉底因「腐蚀青年」而被判处死刑并被处决。这也意味着,苏格拉底过程并不能保证与外部观察者的意图保持一致。
语言游戏作为一种机制也没有回避这一点,但它所需要的不是在单个输入和输出的细粒度上对齐的批评家,而是一个可以判断应该玩哪些游戏的「元批评家」:根据是否对整体性能有贡献来过滤游戏。
此外,游戏的有用性不需要先验评估,可以在玩了一段时间后事后判断,毕竟事后检测异常可能比设计时阻止要容易得多。
那么问题来了,如果从苏格拉底和他的弟子开始,数千年来一直不受干扰地思考和改进,到现在会产生什么样的文化产物、什么样的知识、什么样的智慧?


