


新智元报道
编辑:编辑部 HYZj
【新智元导读】昨天深夜,OpenAI彻底被谷歌狙击,震撼亮相的Gemini 2.0掀起智能体革命,原生多模态的多项惊人demo预示着:智能体时代,谷歌已经走在了最前面。
OpenAI Day 5,风头被谷歌再一次抢了。
就在刚刚,谷歌CEO劈柴、DeepMind CEO哈萨比斯、DeepMind CTO Kavukcuoglu三位大佬联手官宣:新一代原生多模态模型Gemini 2.0 Flash正式发布!
至此,Gemini正式进入2.0时代!
从命名来看,Gemini 2.0 Flash很可能是新系列的最小杯,但它的性能已经超越了上一代大哥1.5 Pro,而且速度提高了一倍。
甚至,它的性能完全超越o1-preview、o1-mini,仅次于GPT-4o(2024-11-20)。
不仅如此,2.0 Flash还具有出色的多语言能力,并可以原生调用谷歌搜索等工具。
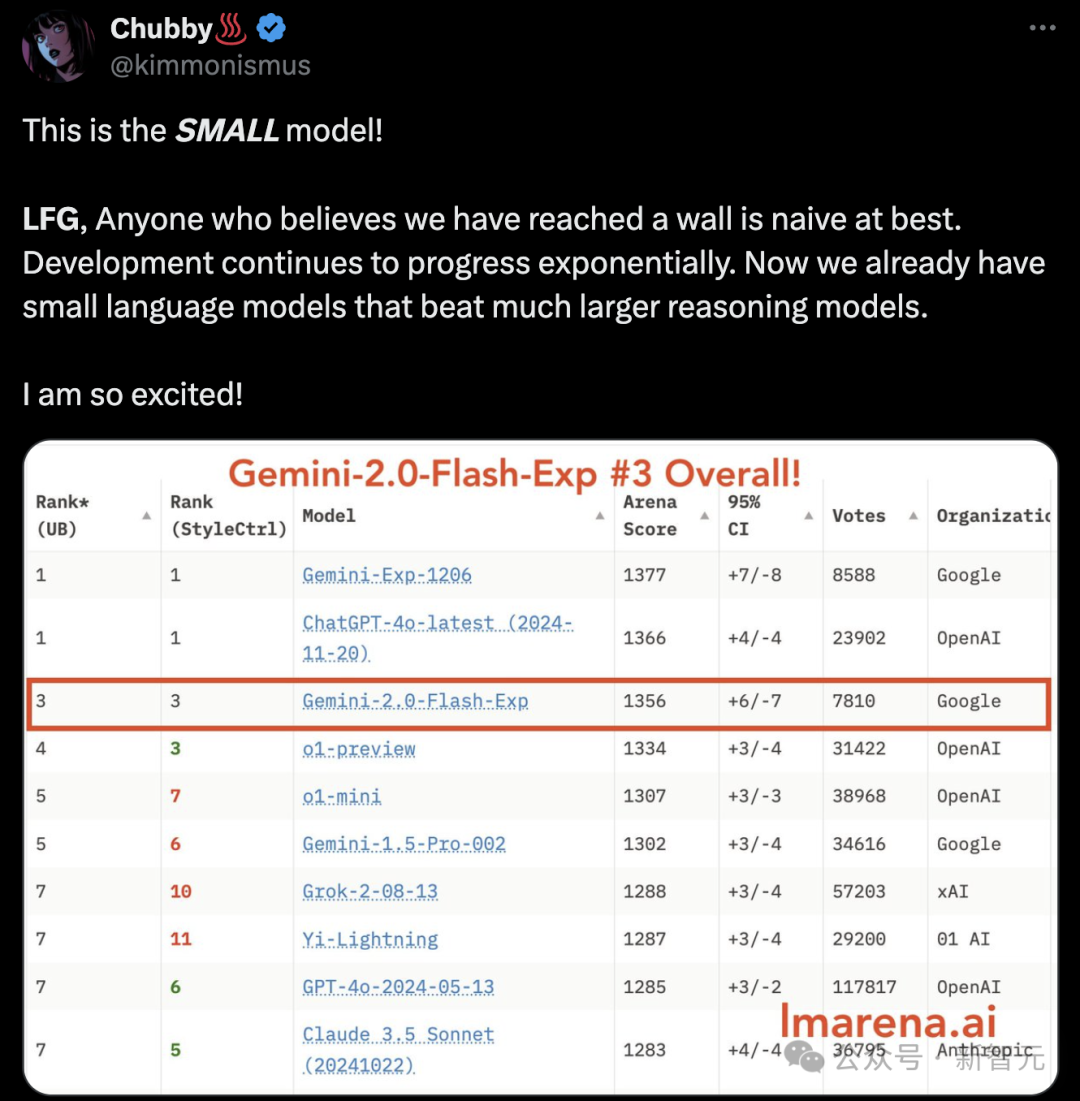
值得一提的是,Gemini 2.0 Flash非常擅长编码,在SWE-bench Verified基准上,直接击败完整版o1。
当然,除了新模型之外,谷歌还带来了一系列基于Gemini 2.0打造的智能体创新:
通用AI助手Project Astra
在浏览器中进行交互的智能体Project Mariner
为开发者打造的AI代码智能体Jules
游戏辅助智能体
机器人智能体

而这仅仅是一个开始。
对于AI智能体来说,2025年将是关键之年,而谷歌将凭借着Gemini 2.0支撑起自己的智能体工作流。
Gemini 2.0,迄今最强大的AI模型
Gemini 1.0和1.5,是第一批原生多模态模型。
NotebookLM就是很好的例子,说明了多模态和长上下文可以为人们带来什么。
今天,谷歌专为新智能体时代打造的下一代模型——Gemini 2.0,重磅登场了。
这个迄今最强大的模型,能使我们构建更接近通用助手的全新AI智能体。
下一步,谷歌会将Gemini 2.0的高级推理功能引入AI Overviews,解决更复杂的主题和多步骤问题,包括高级数学方程、多模态查询和编码。
Gemini 2.0的进步,得益于谷歌对全栈式AI创新长达十年的投资。它基于定制硬件构建,比如第六代 TPU Trillium。TPU为Gemini 2.0的训练和推理,提供了100%的支持。
Gemini 2.0支持全新的多模态AI智能体,它们能看到、听到你周围的世界,还能思考、计划、记住、采取行动。

Gemini 2.0 Flash,原生多模态
今天,谷歌发布了Gemini 2.0系列模型中的第一个——Gemini 2.0 Flash的实验版本。
基于谷歌迄今最受开发者欢迎的1.5 Flash,Gemini 2.0 Flash在保持同样快速响应时间的同时,提供了更强劲的性能表现。
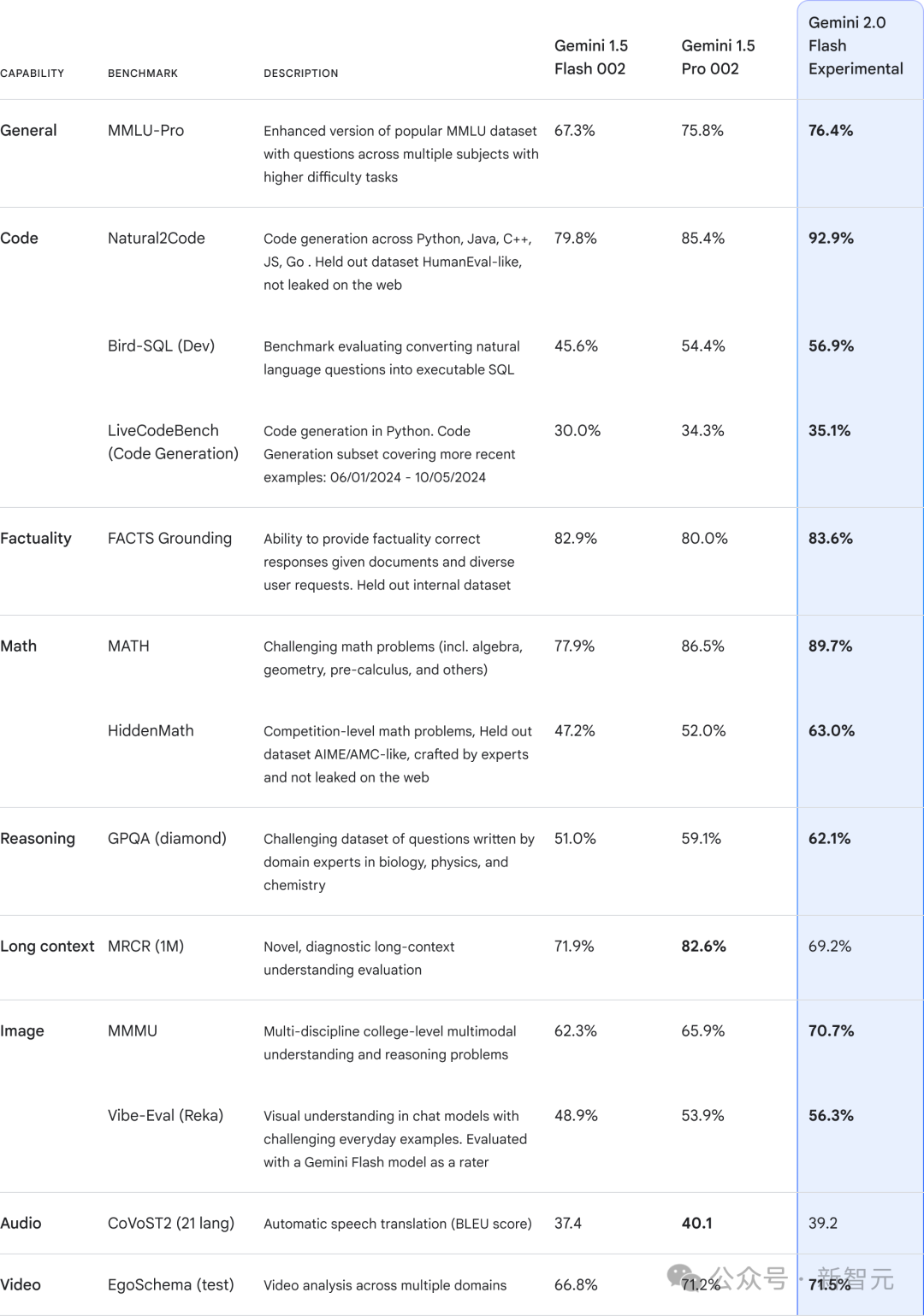
值得注意的是,2.0 Flash在关键基准测试上不仅超越了1.5 Pro的表现,而且速度提高了一倍。
除了支持图像、视频和音频等多模态输入外,2.0 Flash还支持多模态输出,包括原生生成的图文混合内容和可调控的多语言文本转语音(Text-to-Speech,TTS)功能,并且可以原生调用多种工具,如谷歌搜索、代码执行以及第三方用户自定义函数等。
在各项基准测试中,相较于前一代1.5 Pro和1.5 Flash,最新2.0 Flash实现了全面的提升,尤其是代码、数学、推理能力方面。
不过,在长上下文、音频方面,2.0 Flash性能非常有限。
目前,Gemini 2.0 Flash Experimental在Google AI Studio和Vertex AI平台上,通过Gemini API正式向开发者开放。多模态输入和文本输出功能,均可使用。
不过,文本转语音、原生图像生成功能,现仅向首批合作伙伴开放。
为支持开发者构建动态交互式应用,谷歌还同步推出了新的多模态实时API,支持实时音频、视频流输入,并能够集成调用多种工具组合。
对于普通用户来说,即日就可直接用上2.0 Flash Experimental(网页端),移动端很快就会上线。
另外,正式版模型将于2025年1月份推出,同时将提供更多模型规模选择。
开启智能体新纪元
Gemini 2.0 Flash的面世,标志着AI交互再次进入了全新的阶段。
最令人兴奋的是,2.0 Flash具备了原生的用户交互界面的能力。
同时,它还在多模态推理、长文本理解、复杂指令执行与规划组合式函数调用、原生工具调用以及更低的延迟,取得多项技术突破。
这意味着,用户可以获得更加流畅、更直观的AI交互体智能体体验。
AI智能体的实际应用,是一个充满无限可能的研究领域。
谷歌正通过不断原型创新,打造出原生用户界面新体验:
「Project Astra」——探索通用AI助手的未来
「Project Mariner」——从浏览器入手,探索人类与智能体交互的未来方向
「Jules」——专为开发者打造的AI代码智能体
Project Astra:让多模态AI走入现实生活
今年I/O大会上,谷歌大杀器Project Astra首次亮相,在视觉识别和语音交互上,与GPT-4o几乎不相上下。

这一次,得到Gemini 2.0加持后,Project Astra能力也在以下四大方面得到改进:
- 更强的对话能力
Project Astra现在不仅能够使用多种语言进行对话,还支持混合语言交谈,同时对口音和生僻词的理解也更加出色。
- 扩展的工具集成
通过Gemini 2.0,Project Astra可以调用谷歌搜索、Lens和地图功能,让其作为日常生活助手变得更加实用。
- 增强的记忆能力
Project Astra现在可以保持长达10分钟的对话记忆,并能记住更多用户之前的对话内容,从而提供更加个性化的服务。
- 优化的响应速度
借助新的流式处理能力和原生音频理解技术,Project Astra现在可以以近乎人类对话的速度来理解语言。
此外,谷歌还计划将些功能引入Gemini应用等产品,并进一步扩展到智能眼镜等其他设备形式。
在演示视频中,研究小哥用装载了Project Astra的测试版Pixel手机和智能眼镜向我们展示了Astra的多模态能力。

首先,小哥在手机里打开了一封包含公寓信息的邮件,让Astra帮他识别并记住门禁码。
Astra直接读屏获取密码,告诉了他该如何操作开门,并记住了这个密码。

在视频的结尾,研究小哥在伦敦逛了一大圈回来,戴着智能眼镜向Astra询问门禁码,Astra准确地回答了出来。

小哥让Astra读取衣服上的洗涤标签,Astra马上给出洗衣建议。

接着他又将手机镜头转向洗衣机,询问Astra该如何操作洗衣机,Astra很快地提供了指导。

研究小哥准备出门,于是拿了一份地点清单,请Astra介绍了几个地方。

路过面包店看到司康(scone),小哥顺口问了下「scone」发音的问题。
随便指了个街边的雕塑,Astra就能讲出它的来历。

小哥看到伦敦街头的山羊绒,询问Astra它适不适合带回家种。
要知道,小哥在提问的时候并没有告诉Astra他的家在纽约,但Astra记得之前的对话,流畅回答。这体现出Astra的跨会话记忆能力。

研究小哥还测试了一下Astra给朋友挑礼物的能力。他在手机里浏览了一遍朋友的书单,让Astra读屏识别,并总结出这个朋友的阅读品味。
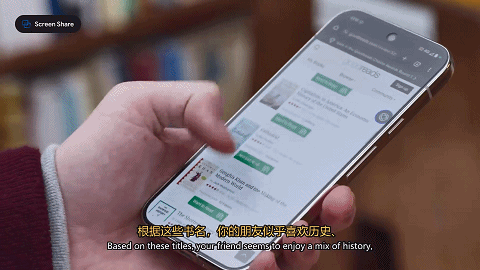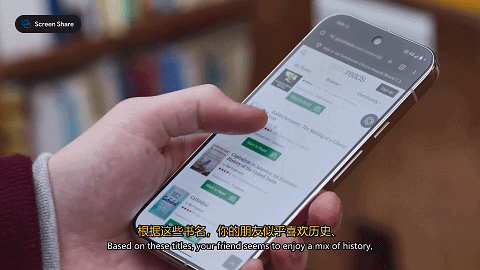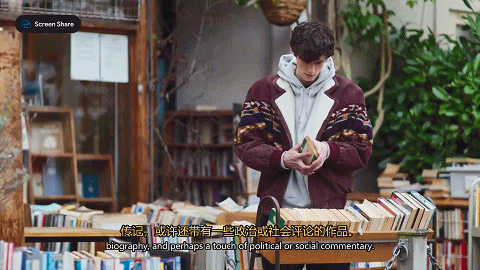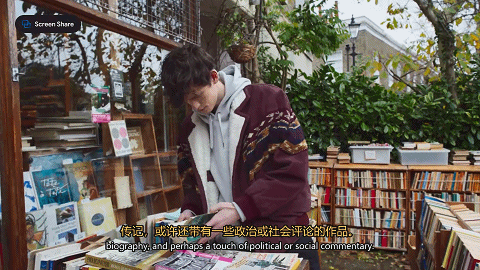
然后小哥挑了几本书,让Astra从中挑选最适合的一本。

小哥将手机摄像头对着路边的一辆公交车,询问Astra它是否会路过唐人街。

对于沿途会路过的地标,Astra也能迅速提供相关信息。

Astra的多语言能力也不容小觑,不仅英语溜,还能用法语和泰米尔语聊天。
除了能在手机上使用Astra,Astra还能搭载在智能眼镜上。
视频中,研究小哥戴着搭载Astra的智能眼镜上街了,上来就问了一句伦敦的天气,Astra对答如流。

骑行时,Astra还能认出路过的公园并介绍它的信息。

小哥准备骑车回公寓,让Astra查询沿途有没有超市。

Project Mariner:能帮你完成复杂任务的AI智能体
Project Mariner,或许听起来陌生。
但此前曾有外媒爆料称,谷歌自研全新智能体项目「Project Jarvis」能够将Chrome任务自动化,并由未来Gemini 2.0版本驱动,预计在今年12月发布。
种种迹象表明,贾维斯项目与Project Mariner有极大的关联。

正如博客所述,Project Mariner是一个基于Gemini 2.0构建的早期「研究原型」。它从浏览器入手,探索人工智能与人类交互的未来。
Project Mariner的核心能力在于,卓越的信息理解和分析,它能够全面感知浏览器屏幕上的各种信息。
比如像素级精准识别,以及网页元素(如文本、代码、图像、表单等)智能分析。
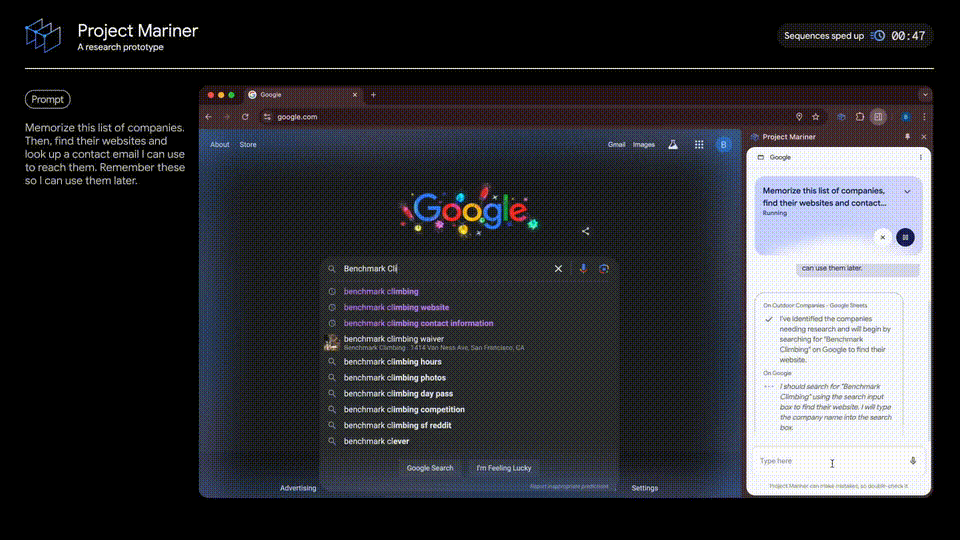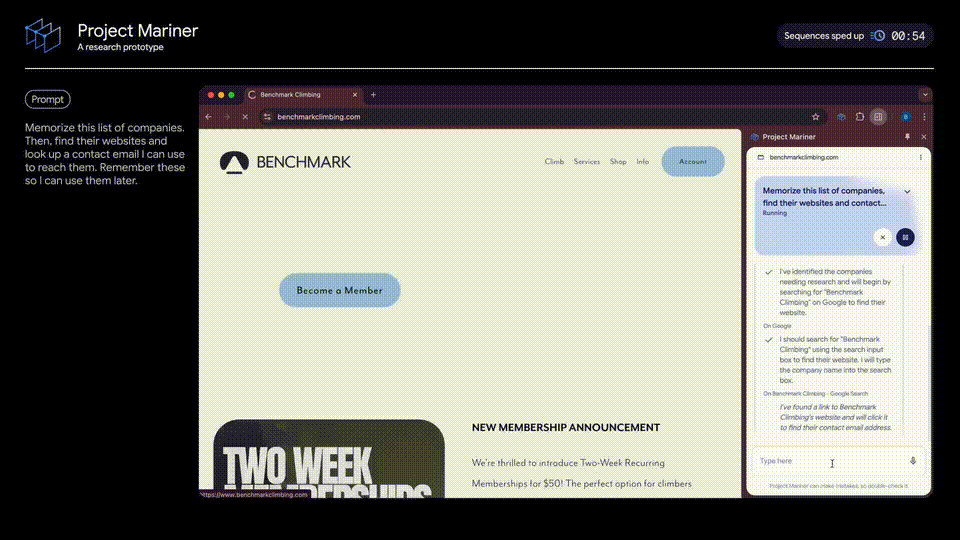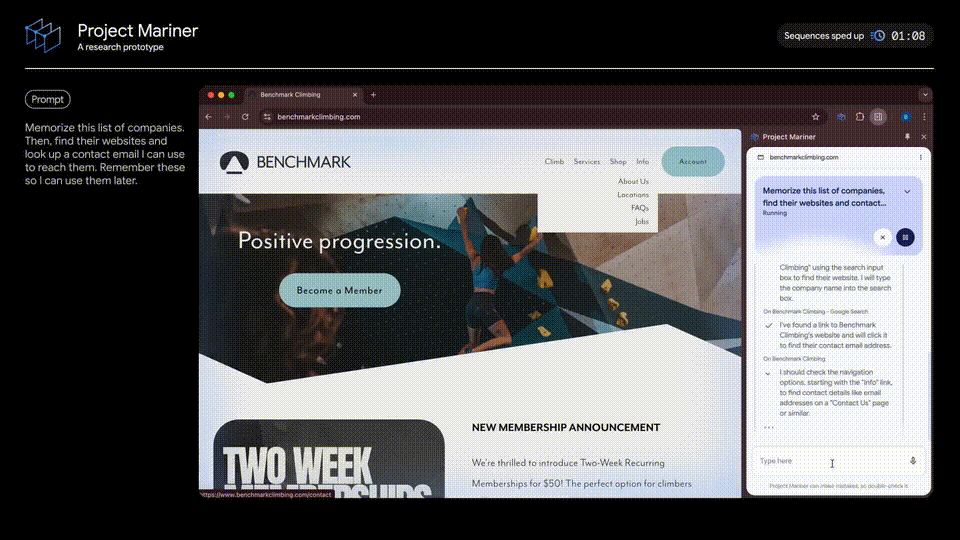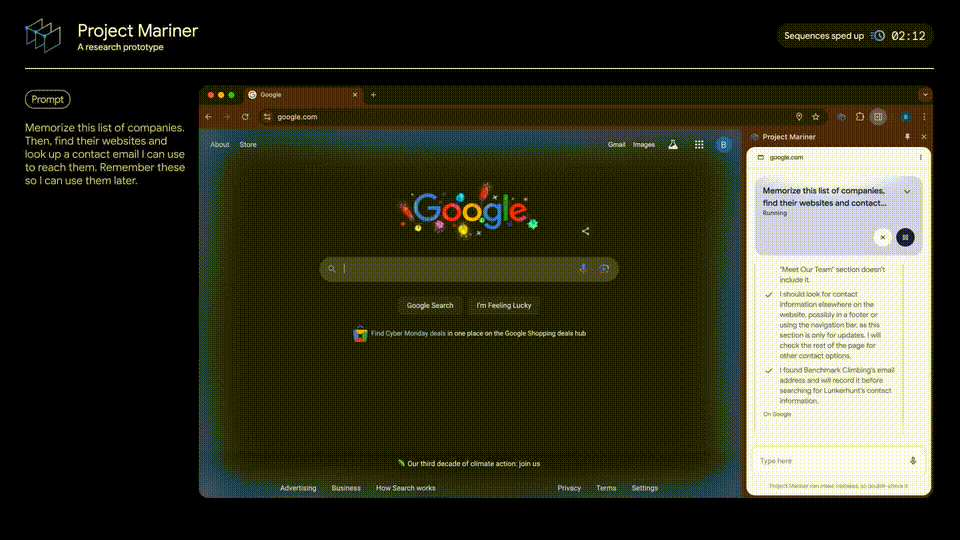
演示中,打开一个在线谷歌表格——户外公司,然后唤出Project Mariner(目前是Chrome实验性扩展程序)。

输入提示「记住这份公司的名单,然后,找到他们的网站,并查找我可以联系到他们的邮箱。记住这些方便我日后使用」

随后,智能体读取了表格中的内容,并了解到了所有公司名称。
通过搜索第一家公司名字,AI智能体点击查询后,进入了Benchingmark Climbing的官网主页,找到右上角「信息」菜单栏中的「关于我们」。
一直下滑到网页末端,找到了这家公司的邮箱地址。
接下来,是第二家公司Lunkerhunt,同样搜索找到官网,公司信息介绍得到邮件地址。
在右侧对话栏中,你可以清晰看到智能体的推理过程,能够更清晰理解它的操作。

表格中另外两家公司邮件查找,AI智能体同样执行如上的重复操作——导航搜索、点击链接、滚动页面、记录信息。
在浏览完第四个网站后,智能体完成了任务,并列出了所有的邮箱地址。

以上,我们所看到的能力,其实与Anthropic所展示的Claude 3.5操作计算机界面,执行各种任务的能力几乎一致。
智能体也是巨头们将在明年,重点布局的方向之一。
在业界权威的WebVoyager基准测试中,Project Mariner已交出了令人惊艳的成绩单:
作为单一AI智能体系统,它在真实网络任务的端到端测试中,取得了惊人的83.5%成功率。
这可能意味着,AI已经能够相对准确地模仿人类在互联网上,完成任务的行为。
此外,Project Mariner最大的亮点是其严格的安全设计,用户始终可以保持对系统的控制。
举例来说,其操作权限仅限当前浏览器的标签页,而且仅能执行一些基本操作:输入、滚动、点击。
若在执行购物等敏感操作之前,必须获得用户的最终确认。
尽管仍处于早期研究阶段,但Project Mariner证明了智能体在浏览器中导航的可能性,其意义远远超过了技术本身。
虽然目前在完成任务时,可能存在准确度不足和速度较慢的问题,但这都将随着技术迭代快速得到改善。
Jules:面向开发者的AI智能体
随着AI代码助手的迅速发展,它已从基础的代码搜索工具进化为深度融入开发者工作流程的智能助手。
如今,在评测真实软件工程任务的基准SWE-bench Verified中,搭载了代码执行工具的2.0 Flash已经可以取得51.8%的优异成绩。
得益于2.0 Flash超群的推理速度,智能体能够快速生成和评估数百个潜在解决方案,并通过现有单元测试和Gemini自身的判断,筛选出最优方案。
想象一下,你的团队刚刚完成了一次Bug Bash,现在你面临着一大堆待修复的bug。
从今天开始,这些让人头大的Python和Javascript编程任务,全部都可以交给由Gemini 2.0驱动的AI代码智能体——Jules去做了。
Jules可以异步工作并与你的GitHub工作流程集成,在你专注于真正想要构建的内容时,它会处理bug修复和其他耗时的任务。
Jules会制定全面的多步骤计划来解决问题,高效地修改多个文件,甚至准备拉取请求(pull request)直接将修复合并回 GitHub。
虽然还处于早期阶段,但从谷歌内部的使用经验来看,Jules可以为开发者带来诸多便利:
- 更高的生产力
把问题和编程任务交给 Jules,实现高效的异步编程。
- 进度跟踪
通过实时更新随时了解情况,优先处理最需要关注的任务。
- 完全的开发者控制
审查Jules制定的计划,根据需要提供反馈或请求调整,并在合适的时候将Jules编写的代码合并到项目当中。

游戏、机器人AI智能体
谷歌DeepMind一直致力于通过游戏来提升AI模型在规则遵循、策略规划和逻辑推理方面的能力。
就在上周,能够仅从一张图片就创造出无限种可玩3D世界的Genie 2诞生。
秉承这一研究传统,谷歌基于Gemini 2.0开发了新的AI智能体,能够协助玩家在视频游戏的虚拟世界中探索。

这些「游戏助手」智能体可以单纯依靠观察屏幕上的动作来理解游戏机制,并通过实时对话为玩家提供下一步行动的建议。
此外,它们还能通过接入谷歌搜索,帮助你获取网络上海量的游戏攻略和相关知识。
目前,谷歌正与Supercell等顶尖游戏开发商展开合作,深入研究这些AI智能体的运作机制,并在不同类型的游戏中测试它们理解游戏规则和应对挑战的能力,涵盖从《部落冲突》等策略游戏到《Hay Day》等农场模拟游戏。
除了在虚拟世界中探索AI智能体的应用能力,谷歌还在机器人领域进行创新性研究,将Gemini 2.0强大的空间推理能力应用其中,开发能在现实世界中提供实际帮助的AI智能体。
下面这些demo,展示了Gemini 2.0玩游戏的强大潜力。
注意,过程中没有任何具体的后训练或者游戏集成,Agent就可以对音频、游戏视频和从网络获取的实时信息做出响应。
在demo中,研究者对Gemini 2.0说:「我打算玩游戏了,我想确保完成每周的任务。你能看到它们吗?」

Gemini 2.0立刻回答,「是的,我能看见,看起来你需要收集300颗宝石,击败10个boss,你已经有10个宝石了。」
因为研究者表示自己经常忘记这件事,Gemini 2.0承诺会在游戏过程中留意,提醒她关于任务的事。
在另一个demo中,研究者表示在计划进行一次攻击,但首先需要训练一支军队,请AI帮他推荐一下军队构成。
Gemini立刻给出了非常明智的建议: 「根据屏幕左上角你的可用部队和数量,我们应该训练巨人、野蛮人、弓箭手和法师的组合。重点是使用巨人来吸收伤害,法师可以对付高输出防御设施,野蛮人和弓箭手可以处理较弱的建筑。」

另外,Gemini 2.0还能自己查攻略。比如帮我们选角色,完成「在Reddit上搜索一下Donetta是什么」这样的任务。
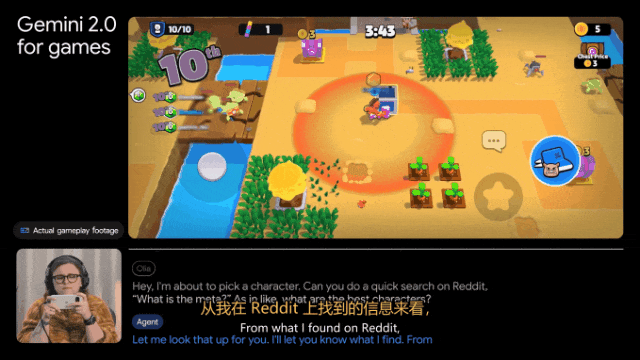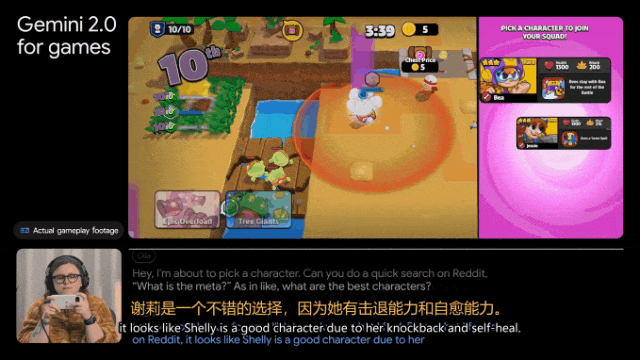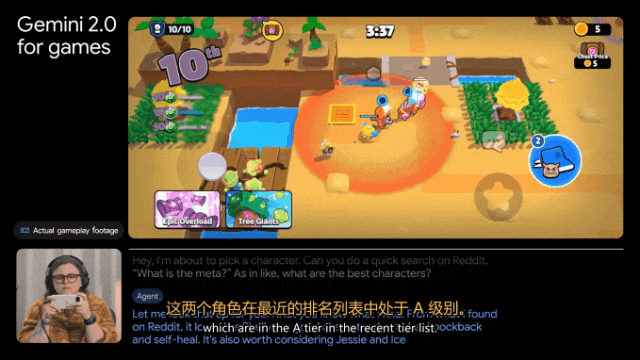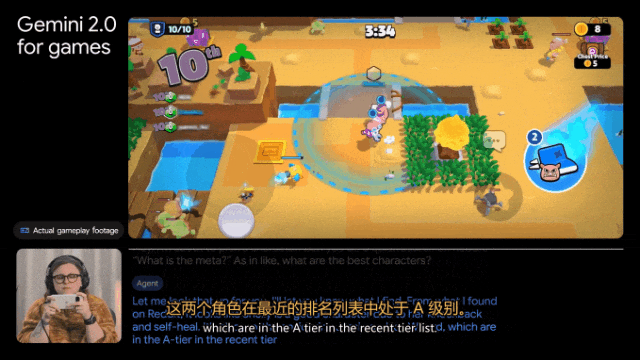
深度研究,个人研究助理来了
在智能体方面,谷歌今天还放出了一个名为Deep Research研究助理,并在Gemini Advanced中上线。
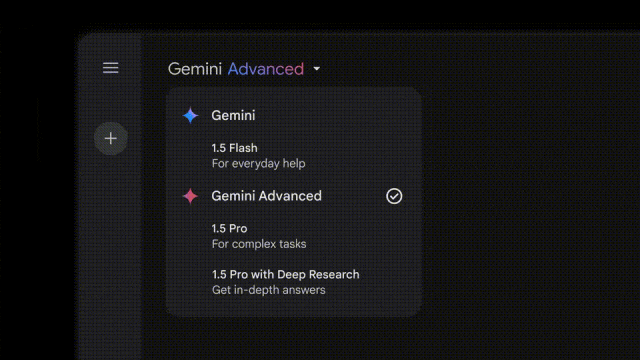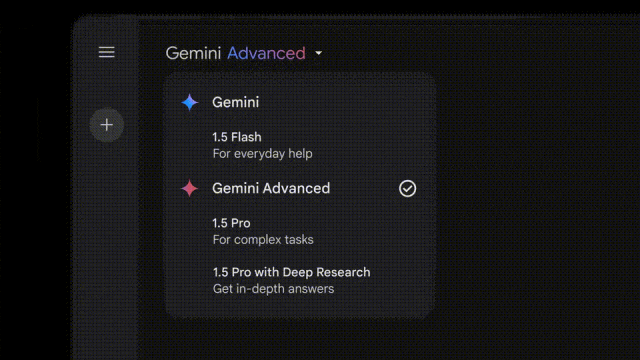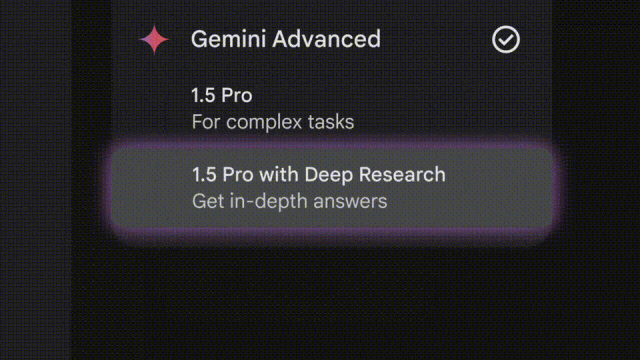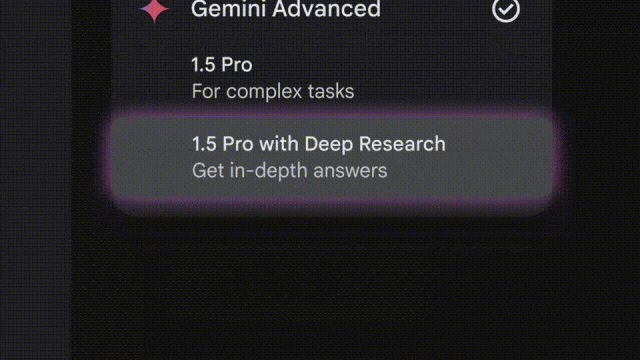
不过,这项新功能由Gemini 1.5 Pro加持。
它可以深入研究复杂的主题,创建报告,并提供相关来源的链接。

假设你想要完成一篇机器学术论文,主题是关于自动驾驶传感器的研究趋势,直接Deep Research。
它便会列出一项研究计划清单,包含了6个要点的信息查找、分析网址、创建报告,点击「开始研究」。

接下来,AI全网搜索分析,并汇总出一份全面详细的研究报告,包括了清晰的表格分析、搜索的62个网址来源。

有了Deep Research,能为我们节省大把的研究时间。


