IT之家 10 月 2 日消息,去年刚成立的 Liquid AI 公司于 9 月 30 日发布了三款 Liquid 基础模型(Liquid Foundation Models,LFM),分别为 LFM-1.3B、LFM-3.1B 和 LFM-40.3B。这些模型均采用非 Transformer 架构,号称在基准测试中凌驾同规模的 Transformer 模型。

IT之家注意到,目前业界在深度学习和自然语言处理方面主要使用 Transformer 架构,该架构主要利用自注意力机制捕捉序列中单词之间的关系,包括 OpenAI 的 GPT、Meta 的 BART 和谷歌的 T5 等模型,都是基于 Transformer 架构。
而 Liquid AI 则反其道而行之,其 Liquid 基础模型号称对模型架构进行了“重新设想”,据称受到了“交通信号处理系统、数值线性代数”理念的深刻影响,主打“通用性”,能够针对特定类型的数据进行建模,同时支持对视频、音频、文本、时间序列和交通信号等内容进行处理。
Liquid AI 表示,与 Transformer 架构模型相比 LFM 模型的 RAM 用量更少,特别是在处理大量输入内容场景时,由于 Transformer 架构模型处理长输入时需要保存键值(KV)缓存,且缓存会随着序列长度的增加而增大,导致输入越长,占用的 RAM 越多。
而 LFM 模型则能够避免上述问题,系列模型能够有效对外界输入的数据进行压缩,降低对硬件资源的需求,在相同硬件条件下,这三款模型相对业界竞品能够处理更长的序列。
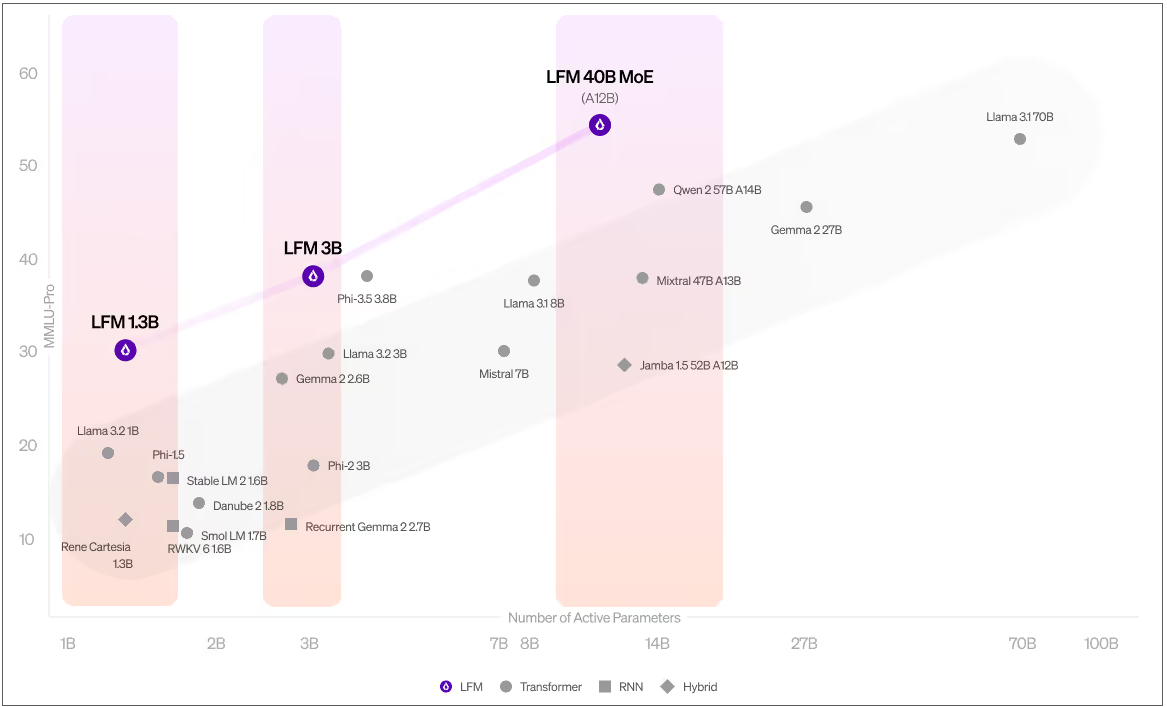
参考 Liquid AI 首批发布的三款模型,其中 LFM-1.3B 专为资源受限的环境设计,而 LFM-3.1B 针对边缘计算进行了优化,LFM-40.3B 则是一款“专家混合模型(MoE)”,该版本主要适用于数学计算、交通信号处理等场景。
这些模型在通用知识和专业知识的处理上表现较为突出,能够高效处理长文本任务,还能够处理数学和逻辑推理任务,目前该模型主要支持英语,不过也对中文、法语、德语、西班牙语、日语、韩语和阿拉伯语提供有限支持。
根据 Liquid AI 的说法,LFM-1.3B 在许多基准测试中击败了其他 1B 参数规模的领先模型,包括苹果的 OpenELM、Meta 的 Llama 3.2、微软的 Phi 1.5 以及 Stability 的 Stable LM 2,这标志着首次有非 GPT 架构的模型明显超越了 Transformer 模型。
而在 LFM-3.1B 方面,这款模型不仅能够超越了 3B 规模的各种 Transformer 模型、混合模型和 RNN 模型,甚至还在特定场景超越上一代的 7B 和 13B 规模模型,目前已战胜谷歌的 Gemma 2、苹果的 AFM Edge、Meta 的 Llama 3.2 和微软的 Phi-3.5 等。
LFM-40.3B 则强调在模型规模和输出质量之间的平衡,不过这款模型有所限制,虽然其拥有 400 亿个参数,但在推理时仅启用 120 亿个参数,Liquid AI 声称进行相关限制是因为模型出品质量已经足够,在这种情况下对相应参数进行限制“反而还能够提升模型效率、降低模型运行所需的硬件配置”。