

掩码离散扩散模型,可能并没有看上去那么厉害。
这是清华及英伟达研究人员最新提出的观点。
他们发现,作为离散扩散模型中性能最强的类别,掩码扩散模型可能有点“被包装过度”了。为啥呢?
第一,这类模型所宣称的超高性能,其实是由于一个技术上的小瑕疵,用32位计算时,模型会产生一种“降温”效果,使模型看起来表现很好,但实际上只是多样性被降低了。用更精确的64位计算,就会发现它们的表现并不如宣称的那么好。
第二,这些模型引入了“时间”的概念,看起来很高级,但研究发现这完全没必要。
第三,这些模型其实与已有的简单掩码模型完全等价,只要正确设置简单模型的参数,就能达到相同效果。
目前,这篇研究已入选ICLR 2025。

具体说了啥?一起来看。
背景
随着SEDD获得ICML 2024最佳论文奖,起源于D3PM的离散扩散模型迎来了复兴并成为自回归范式的有力竞争者,在文本、蛋白质等离散序列生成任务上掀起了研究热潮。
作为离散扩散模型中性能最强的类别,掩码式离散扩散模型(简称掩码扩散模型)在后续工作中被进一步简化,从而在理论形式上与连续空间扩散模型对齐。
掩码扩散模型通过引入一个连续的“时间”或“噪声水平”的概念,定义了一个从原始数据逐渐“加噪”(掩码)到完全掩码状态的前向过程,以及一个学习从掩码状态逐步“去噪”(预测被掩码部分)恢复数据的反向(生成)过程。
在使用生成式困惑度(Gen PPL)作为衡量文本生成质量的指标时,掩码扩散模型在先前工作中均显示出了随采样步数增加的性能提升,并在足够多步数下超越自回归模型。
这种对比是否公平?同时,作为离散空间中的“扩散”模型,是否意味着其可以借鉴标准扩散模型相关算法来增强性能?
论文从训练和采样两个方面对掩码扩散模型进行解构。
掩码扩散模型与掩码模型的差异
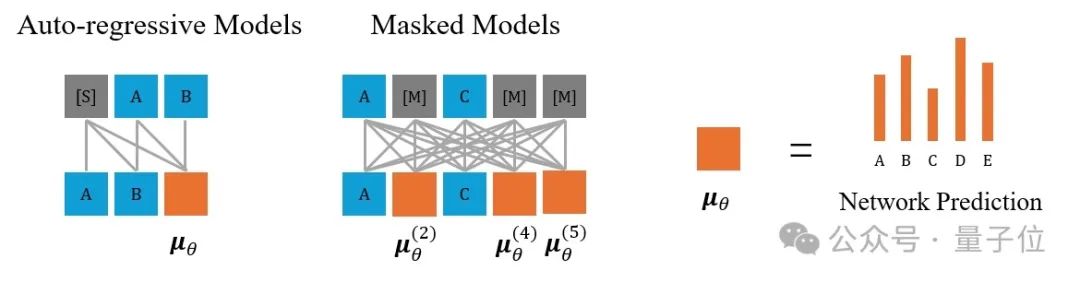
尽管掩码扩散模型借鉴了扩散模型的框架,但其核心操作与经典的掩码语言模型(如 BERT,Mask-Predict) 或掩码图像生成模型(如 MaskGIT)有着相似之处:都是对部分内容进行掩码(masking),然后预测被掩码的内容。
BERT在训练时只会掩码一小部分token,适用任务为表征学习、文本理解而非生成,而Mask-Predict与MaskGIT扩大了掩码比例的范围并可用于文本、图像生成。
相比于掩码模型,掩码扩散模型引入了一个关键的复杂性:时间步(time step)。其训练和采样都严格依赖于一个预先定义的、随时间变化的掩码(噪声)调度。
模型需要根据当前的时间步 t 来预测原始数据。
具体而言,它和掩码模型的差异体现在:
在训练中,掩码模型被掩码的token数量及不同掩码比例对应的损失权重可以随意设定;掩码扩散模型同一时间对应被掩码token的数量是不确定的,不同时间的分布及权重需要特殊设置使得损失构成模型似然(likelihood)的证据下界(ELBO)。
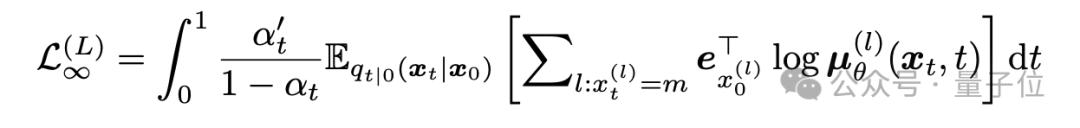
在采样中,掩码模型按照token为粒度,逐token解码;掩码扩散模型以时间为粒度进行离散化,从时间t转移到更小的时间s时,每个token被解码与否通过概率采样决定,被解码token的数量是不确定的。
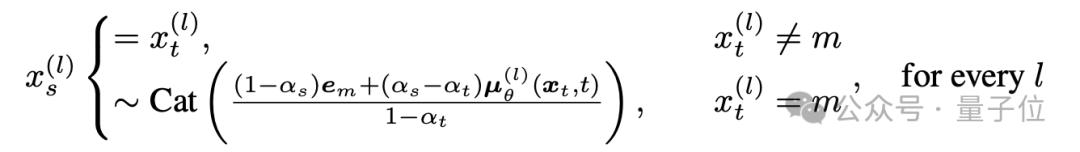
掩码扩散模型的采样存在隐性数值问题
先前评估掩码扩散模型性能的关键指标之一是Gen PPL,其通过计算参考模型(如GPT-2)对模型生成内容的“惊讶程度”来衡量生成质量。
然而,Gen PPL 指标对采样过程中的超参数(如采样温度)极为敏感,并且可以通过调整这些参数轻易地“刷低”数值,但这并不代表模型本身的生成能力有实质提升。
本研究首次揭露,掩码扩散模型特有的采样过程存在隐藏的数值问题,即使在常用的32位浮点数精度下也会带来类似于降低温度的效果。
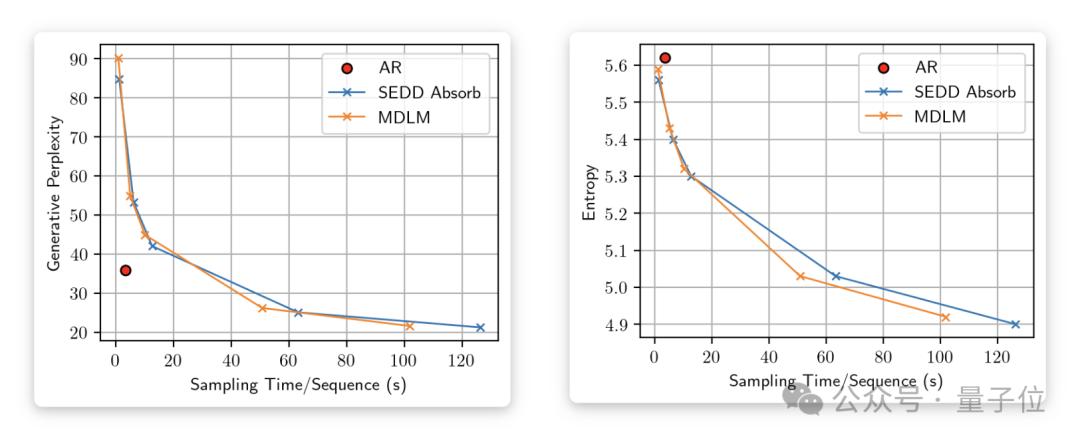
为了显示这一点,论文额外测试了生成句子的熵(entropy)来衡量生成多样性。
随着采样步数的增加,Gen PPL不断下降并超过自回归模型(左图),然而熵也在持续降低(右图)。
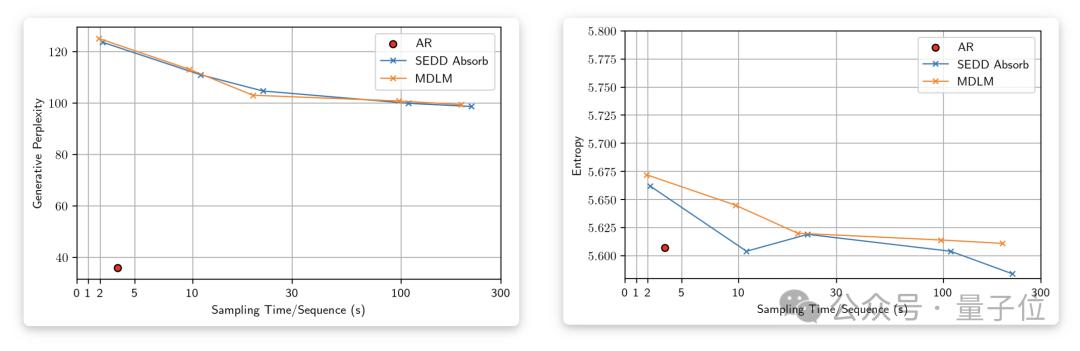
当采样过程以64位精度进行时,熵稳定在与自回归模型类似的水平,而Gen PPL则显著升高并远远落后于自回归模型。
论文通过进一步的数学推导,从理论上解释了这一温度降低效果的根源。
具体而言,在[0,1)区间上均匀采样的浮点数实际范围为[0,1-ε],其中ε是一个接近0的小数,这会导致基于Gumbel-max技巧的类别采样(categorical sampling)存在截断问题。
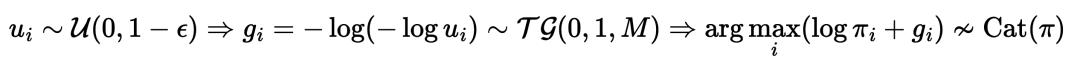

最终的分布不服从原先的类别概率π,而会偏移到
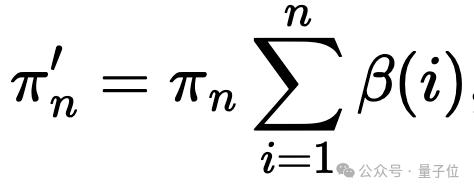
,其中
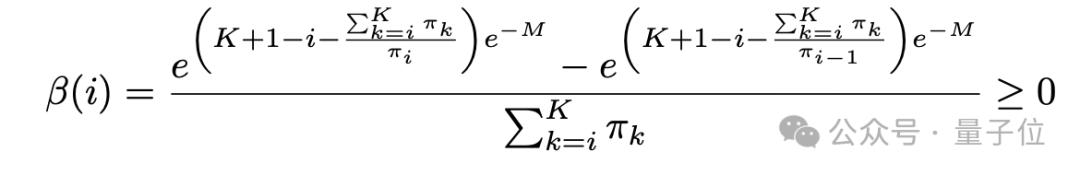
这一偏移会加强原先概率已经比较大的类别,从而达到类似降低温度的效果。
通过对类别采样部分的代码做对照试验,文章验证了64位采样+手动截断确实可以复现32位采样的效果。

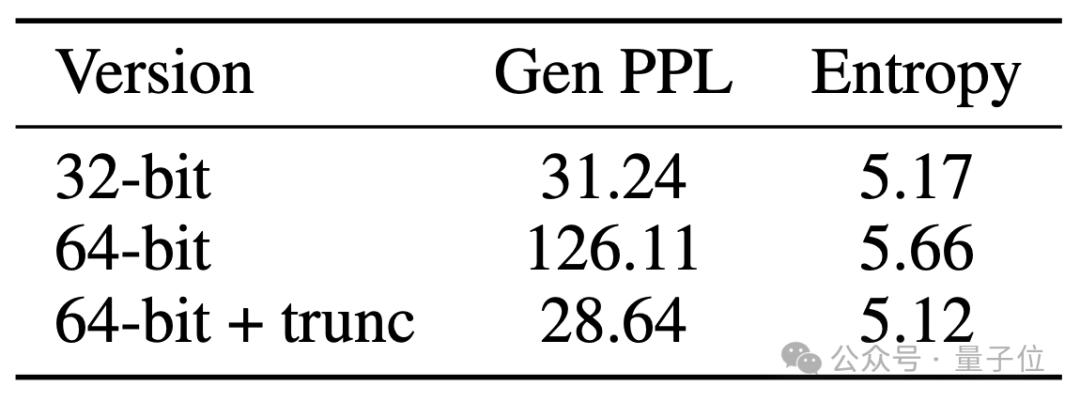
同时,上述数值问题对于单个token并不显著,逐token解码的模型(如自回归模型、掩码模型)在32位下基本不受影响。
然而,此问题会在掩码扩散模型中额外影响所有token之间的交互,导致某些token被优先解码,进一步降低生成多样性。
可以说,这是掩码扩散模型采样过程独有的数值问题。
掩码模型与掩码扩散模型的等价性
先前工作从最优网络的角度证明了掩码扩散模型中的时间并不必要,本论文进一步在训练和采样两方面证明掩码扩散模型和掩码模型的等价性。
具体而言:
在训练损失函数上,掩码扩散模型与时间有关的似然下界等价于掩码模型的以token为粒度的损失函数,只要满足:(1)被掩码token的个数n在1和L之间均匀采样,其中L是序列的总长度(2)预测损失对n取均值,即施加“似然权重”1/n来实现最大似然训练。

需要注意的是,对不同时间/掩码比例施加的权重并不影响网络在无限容量下的最优值,而决定了网络训练过程中的重点优化区域。
文本生成的自回归范式采取了最大似然训练,而在图像上,最大似然训练往往会带来生成质量的下降。
在采样过程上,掩码扩散模型逆时间的采样过程可以通过论文提出的首达采样器(first-hitting sampler),转化为与掩码模型相同的逐token采样,最多需要L步便可达到没有离散化误差的精确采样,而掩码扩散模型原有采样过程需要对时间无限细分才能完全精确。同时,采用逐token解码可以避免上文所述的隐藏数值问题。

结语
掩码扩散模型引入的“时间”概念可能不仅无益,反而有害(导致数值问题和不必要的复杂性)。
同时,其虽然带有“扩散”两字,但与连续空间上的扩散模型及其相关算法关系不大,如在论文中,作者仿照扩散模型为掩码扩散模型开发了高阶采样算法,其并不如连续空间中的加速效果显著。
在实践中,使用掩码扩散模型、引入连续时间相关的训练/采样过程或许并不必要,简单的掩码模型(如 MaskGIT 及其变种)在概念上更简洁,实现上更稳定,并且在理论上具有同等的潜力。
掩码模型作为自回归模型使用随机token顺序和双向注意力机制的变种,同样是基于似然的模型,可以作为建模离散数据生成的另一种选择。
由于双向注意力和KV cache机制不兼容,掩码模型在长上下文的推理速度上相较自回归模型存在瓶颈。
近期工作通过在双向注意力和因果注意力机制之间插值、使用随机顺序的自回归模型等方法使模型保持双向感知能力的同时,推理速度向自回归模型靠近。
也有工作探究非掩码类型的离散扩散模型与连续空间扩散模型的理论联系,其扩散机制更加属实,而非如掩码扩散模型一样是可有可无的噱头。
论文第一作者郑凯文为清华大学计算机系三年级博士生,在ICML、NeurIPS、ICLR发表扩散模型相关一作5篇。文章通讯作者为朱军教授,合作者张钦圣、陈永昕、毛含子为英伟达研究员,刘洺堉为英伟达副总裁与Deep Imagination研究组主管。
论文标题:Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling
论文链接:https://arxiv.org/abs/2409.02908
论文博客:https://zhengkw18.github.io/blog/2024/mdm/


