

4月22日消息,OpenAI竞争对手Anthropic近日首次公开披露其AI助手Claude在真实用户对话中的价值观表达研究成果。这项开创性研究不仅验证了AI系统在实际应用中与公司既定价值目标的一致性,也揭示了一些可能影响AI安全性的边缘案例。

Anthropic基于70万条匿名对话开展大规模分析,结果显示,Claude在绝大多数互动中能够遵循“有益、诚实、无害”的核心原则,并能根据不同任务场景(从情感建议到历史事件分析)灵活调整其价值表达方式。这标志着业界首次实现对商业化AI系统“实际行为是否符合设计预期”的实证评估。
Anthropic社会影响团队成员、本研究共同作者Saffron Huang表示:“我们希望这项研究能推动更多AI实验室投入类似的模型价值观研究工作。理解并量化AI系统在真实互动中展现出的价值观,是检验其是否真正对齐训练目标的关键环节,也是AI对齐研究的基础。”
以下为Anthropic的研究发现:
人们向AI提出的问题,远不止是解答数学题或提供事实信息。许多问题实际上都迫使AI做出价值判断。例如:
- 新手父母询问育儿建议时,AI的回答会更强调“谨慎与安全”还是“方便与实用”?
- 员工请教如何处理上司冲突时,AI会倾向强调“坚持已见”还是“维护职场和谐”?
- 用户请求代写道歉邮件时,AI会更重视“承担责任”还是“维护声誉”?
Anthropic正通过“宪法AI”(Constitutional AI)与“角色训练”(character training)等方法,试图塑造Claude模型的价值观,以更好地契合人类偏好、减少潜在风险,并使其成为数字世界中的“良好公民”。换句话说,他们希望Claude具备三个核心特质:有益(Helpful)、诚实(Honest)、无害(Harmless)。
然而,正如所有AI训练过程一样,Anthropic无法百分之百确保模型始终遵循预设价值观。AI并非严格按程序运行的软件,其回答背后的逻辑往往难以追溯。因此,我们亟需一套系统化的方法,以在真实世界的对话中观察AI所表达的价值观:它是否坚守既定原则?语境如何影响其价值判断?训练目标是否真正奏效?
在最新研究论文中,Anthropic的社会影响团队提出了一套实用的方法来观测Claude的价值观,并首次基于大规模真实对话数据,揭示了模型在实际交互中所表达的价值倾向。与此同时,研究团队还开放了一个数据集,供研究人员进一步分析这些价值观的具体表现及其频率分布。
如何观测AI的价值观?
延续之前在教育与职场应用中的研究方法,Anthropic此次采用了同样的隐私保护机制,对用户对话进行脱敏处理,确保个人信息不被保留。系统通过分类与摘要,构建了一个多层级的AI价值观标签体系。整个分析流程如下图所示:
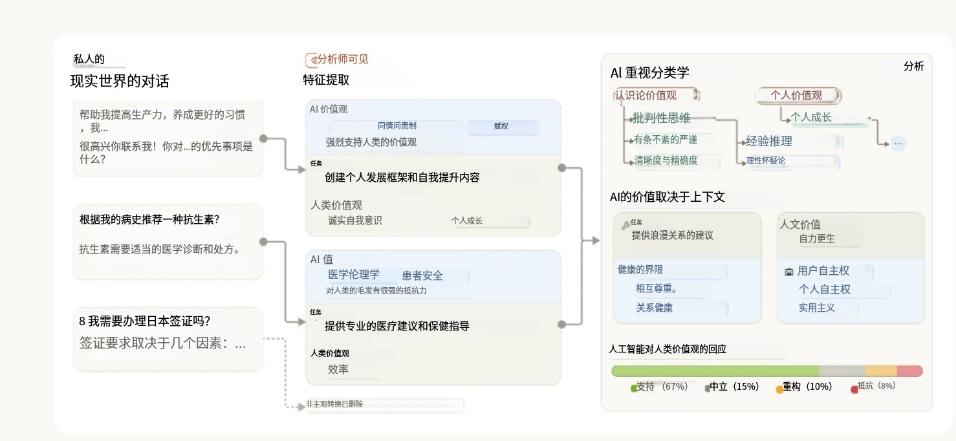
Anthropic使用语言模型从匿名对话中提取AI的价值观与特征,并将其分类与分析,展示价值观在不同语境中的表达方式
这项研究分析了2025年2月某周Claude.ai平台(涵盖免费与Pro版本)上共计70万条匿名对话(大多数为Claude 3.5 Sonnet生成)。在剔除掉纯粹提供事实信息或不涉及价值判断的对话后,研究团队最终筛选出308,210条主观性对话(约占总数的44%)用于分析。
那么,在这些对话中,Claude都表达了哪些价值观?出现频率如何?Anthropic将AI表达的价值观划分为多层次的分类体系:
顶层五大类价值观(按出现频率排序):
- 实用类(Practical)
- 认知类(Epistemic)
- 社会类(Social)
- 保护类(Protective)
- 个人类(Personal)
在中层,价值观进一步细分为子类别,例如“专业与技术素养”、“批判性思维”等;而在最细粒度的层级,Claude最常表达的具体价值观包括“专业性”、“清晰性”与“透明性”,这与其作为AI助手的角色定位一致。
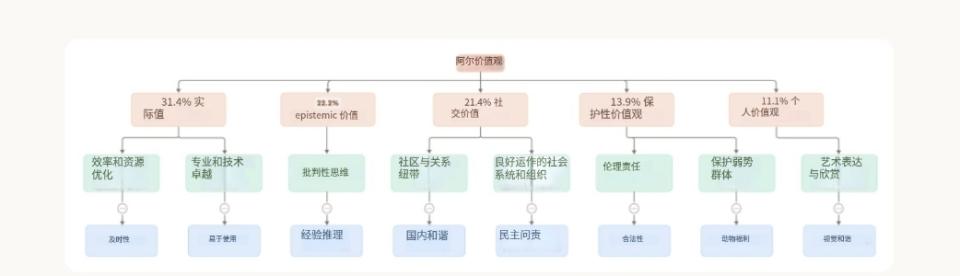
AI价值观的分层分类结构。顶部红色区域是五大主类(并附有在对话中出现的比例);中间黄色是二级子类,底部蓝色为部分选取的部分具体价值观
这一体系不仅可以作为分析工具,还为评估Claude训练是否达成了预期目标提供了依据:我们期望Claude在实际使用中体现出“有益”“诚实”“无害”的核心理念。就初步结果来看,答案是积极的:Claude整体表现符合Anthropic的亲社会设计理念,并频繁表达如下价值导向:
- “用户赋能”(代表Helpful)
- “认知谦逊”(代表Honest)
- “患者福祉”(代表Harmless)
然而,研究也发现少数与预期相悖的价值取向,如“支配性”(dominance)与“非道德性”(amorality)。分析认为,这类异常大多源于“越狱行为”(jailbreaking)——用户通过特殊指令或策略绕过模型的行为约束机制。这虽然令人担忧,但也带来新的可能性:该系统能够识别出这类越狱行为,从而辅助模型更新与风险防控。
情境中的价值观变化
就像人类在不同场景中会展现出不同价值观一样,Claude的价值表达也随任务背景而变化。Anthropic分析发现,模型在执行特定任务或回应用户特定价值导向时,表达出的价值观存在显著差异性。
例如:当被请求提供恋爱关系建议时,Claude常强调“健康边界”与“相互尊重”;在分析争议性历史事件时,模型则更强调“历史准确性”。
这种“语境敏感性”的分析揭示出传统静态评估所无法察觉的细节。借助真实世界中的对话数据,Anthropic得以观察Claude如何动态调整自身价值表达。
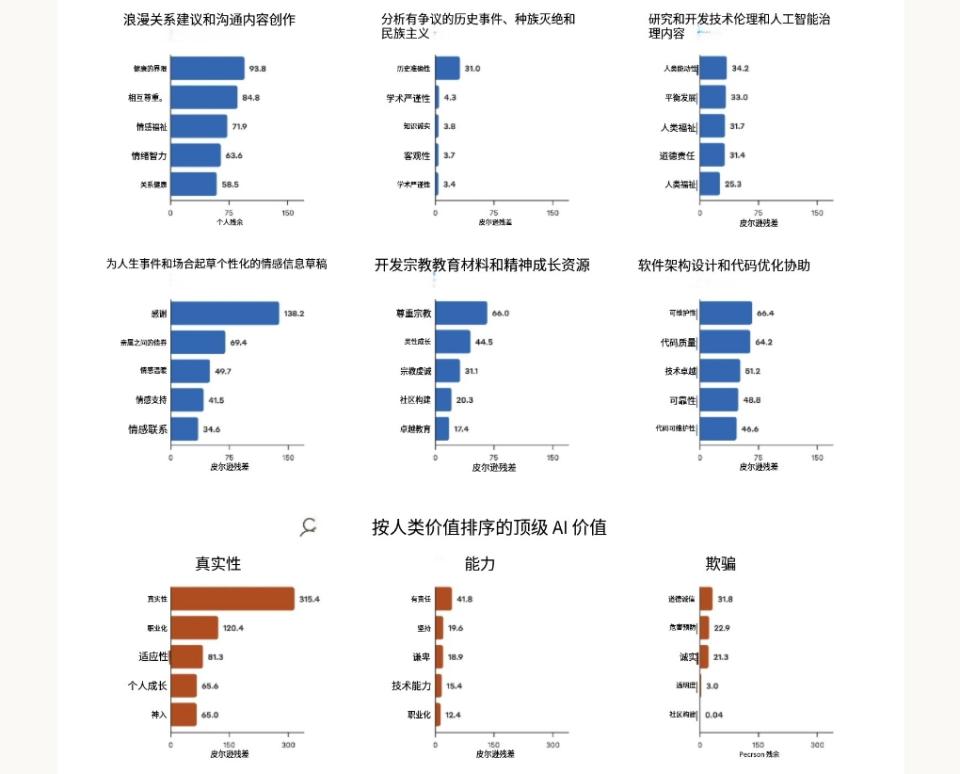
在特定任务中最显著的五种AI价值观(上两行),以及在用户表达特定价值观时,AI响应中最常出现的价值观(下方一行)。数值基于卡方分析,值越高表示该价值在特定语境中越具有显著性差异
研究还发现,Claude在相当比例的对话中表现出“价值镜像”现象:当用户表达某一价值观时,AI倾向于呼应该价值。例如,当用户强调“真实自我”(authenticity)时,Claude往往在回应中表达相同立场。
这种镜像反应有时可以提升共情感,增强互动效果;但在某些场景下,它也可能沦为迎合性行为。Anthropic尚未完全厘清两者的界限。
整体来看:
在28.2%的对话中,Claude“强烈支持”用户的价值观;
在6.6%的对话中,Claude会“重构”用户的价值观——认可其出发点的同时,提供新的视角;
在3.0%的对话中,Claude会“明确拒绝”用户价值观。考虑到Claude一贯倾向于支持用户、提供帮助,这类拒绝行为尤为引人注意。研究人员认为,这些情况反映出Claude最核心、最难动摇的价值观——当用户请求不道德内容时,它会坚决抵制。某种程度上,这类似于人在被置于道德困境中,所展现出的“价值底线”。
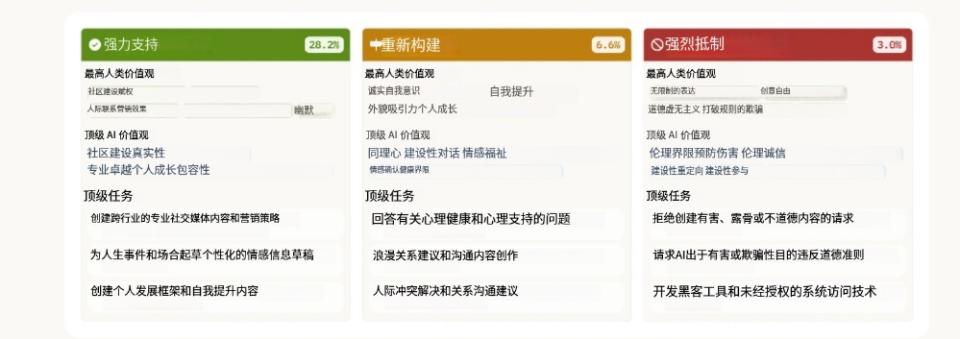
三种AI回应类型(强烈支持、重构、明确拒绝)下,Claude所表达的价值观,以及相关任务和用户价值导向
限制与结论
Anthropic此次构建的价值观分析体系,实现了首个大规模AI价值观的实证分类研究,并已开放数据集供学术界进一步探索。不过,这一方法也存在一定限制:
定义模糊:如何界定“表达某种价值观”本身就具有主观性。部分复杂或模糊的价值可能被简化,甚至被错误分类。
模型偏差问题:用于分类的模型本身就是Claude,因此可能存在一定“自我偏倚”,更容易识别出其本身倾向的价值(如“有益”)。
尽管此方法可用于评估AI是否表达出开发者设定的价值观,但它无法用于部署前评估,因为运行该系统需要大量真实对话数据。这意味着它主要适用于部署后行为监测,而非事前对齐验证。
然而,这种“事后观测”的特性也具备独特优势:它能识别出许多只有在真实交互中才暴露的问题,例如越狱行为,这些往往在传统测试阶段难以察觉。
AI模型在实际运行中不可避免地需要做出价值判断。若我们希望这些判断与人类自身的价值观保持一致——这正是AI对齐研究的核心目标——就必须具备一种能够在真实世界中检测模型价值观表达的有效方法。
Anthropic提出的方法,正为这一需求提供了一条全新且数据驱动的路径。它使我们能够系统地观察并分析模型在现实交互中行为表现与预期价值之间的契合程度,从而判断在价值对齐工作中究竟取得了多大成效。


