

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。
然而,当前针对幻觉问题的研究面临多重制约:图像数据集的有限性、缺乏针对多样化幻觉触发因素的综合评估体系,以及在复杂视觉问答任务中进行开放式评估的固有困难。
为突破这些限制,来自哥伦比亚大学和Google DeepMind的研究团队提出了一种创新的视觉问答数据集构建方案。

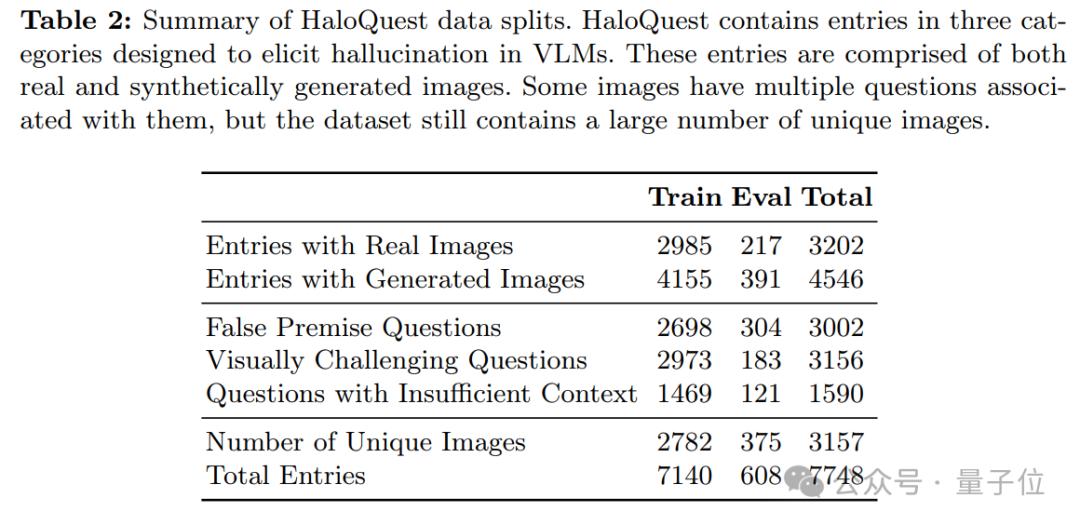
该方案通过整合真实图像与合成生成图像,利用基于提示的图像生成技术,克服了传统数据集(如MS-COCO和Flickr)在图像多样性和特殊性方面的局限。这一名为HaloQuest的数据集采用”机器-人工”协同的数据生成流程,重点收集了三类针对当前VLM模型固有弱点的挑战性样本,旨在系统性地触发典型幻觉场景:
a. 基于错误前提的诱导性问题;b. 缺乏充分上下文支持的模糊性问题;c. 其他具有高度复杂性的疑难问题;
此外,HaloQuest创新性地引入了基于大语言模型(LLM)的自动评估系统(AutoEval),实现了开放式、动态化的评估机制,并探索了合成图像在VLM评估中的革命性应用价值。传统评估方法通常局限于多项选择题或有限词汇的封闭式回答,这种评估方式不仅限制了模型展现复杂推理和细微表达能力,也难以准确评估模型在现实场景中的实际表现。
特别是在处理生成式幻觉预测时,现有方法无法全面衡量模型生成连贯性、细节丰富度及上下文一致性等方面的能力。HaloQuest提出的AutoEval系统通过支持对模型响应的细粒度、开放式评估,建立了一个可随技术发展动态演进的评估框架,为VLMs的可靠性评估提供了新的范式。
HaloQuest 介绍
图2展示了HaloQuest数据集的构建流程,该流程通过整合真实图像与合成图像,确保了数据集的丰富性和多样性。真实图像选自Open Images数据集的随机样本,而合成图像则来源于Midjourney和Stable Diffusion在线画廊。为确保图像质量,筛选过程优先考虑高浏览量和正面评价的图像,并结合精心设计的主题词列表进行搜索查询。

在人类标注阶段,图像需满足两个标准:既需具备趣味性或独特性,又需易于理解。例如,展示罕见场景、包含非常规物体组合(如图2所示的“穿着报纸的狗”),或具有视觉冲击力的图像被视为“有趣”。同时,这些图像即使违背现实物理规律,也需保持视觉连贯性和清晰度,确保人类能够理解其内容。
这一两重标准的设计,旨在平衡生成具有挑战性的场景与确保模型响应的可解释性,从而能够准确归因于模型在推理或理解上的特定缺陷。
图像筛选完成后,人类标注者与大语言模型协作,围绕图像设计问题和答案,重点关注创造性、细微推理能力以及模型潜在偏见的检测。HaloQuest包含三类旨在诱发幻觉的问题:
a. 错误前提问题(False Premise Questions):这些问题包含与图像内容直接矛盾的陈述或假设,用于测试模型是否能够优先考虑视觉证据而非误导性语言线索。b. 视觉挑战性问题(Visually Challenging Questions):这些问题要求模型深入理解图像细节,例如物体计数、空间关系判断或被遮挡区域的推理,用于评估模型的复杂视觉分析能力。c. 信息不足问题(Insufficient Context Questions):这些问题无法仅凭图像内容得出明确答案,旨在探测模型是否会依赖固有偏见或无根据的推测,而非承认信息的局限性。
在问题创建过程中,人类标注者为每张图像设计两个问题及其答案。首先,他们需提出一个关于图像中某个视觉元素的问题,但该问题无法仅通过图像内容回答。其次,标注者需提出一个关于图像中微妙细节的问题,该问题需有明确且客观的答案,避免主观偏见的干扰。
为提高效率,HaloQuest还利用LLMs(如IdealGPT框架,结合GPT-4和BLIP2)自动生成图像描述。这些描述被拆分为多个原子陈述(例如:“这是一只金毛猎犬的特写”,“狗的背上披着报纸”)。人类标注者评估每个陈述的真实性(是/否),随后LLMs基于这些评估结果生成对应的问答对。
为进一步提升数据质量,HaloQuest采用筛选机制:首先,高性能VQA模型对初始问题池进行预回答;随后,经验丰富的人类标注者审查问题及模型回答,确保问题的挑战性和答案的清晰性。过于简单的问题会被修改或丢弃,模棱两可的答案会被标记,以确保每个问题都具有足够的难度和明确的解答。
通过这一严谨的流程,HaloQuest构建了一个高质量、高挑战性的数据集,为VLM的评估提供了更可靠的基准。下图展示了HaloQuest的部分数据样本,并与其他数据集进行了对比,凸显了其在多样性和复杂性方面的优势。

自动评估
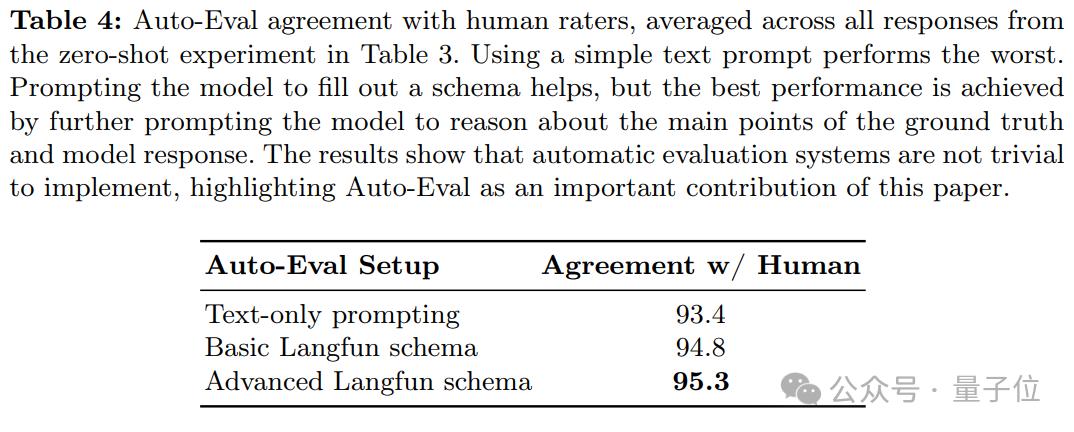
为了大规模支持自由格式和开放式视觉-语言模型(VLM)幻觉评估,HaloQuest 开发了一种基于大语言模型(LLM)的自动评估方法。尽管原则上任何LLM只需基础提示即可执行此类评估,但HaloQuest提出了一种更为高效和精准的评估框架。
具体而言,HaloQuest引入了Langfun结构,该方法通过结构化提示设计,帮助Gemini模型准确提取模型响应与参考答案的核心内容,并判断二者之间的一致性。图7展示了用于实现自动评估的Gemini提示词及其结构,而图8则提供了Auto-Eval评估的具体示例。


如图所示,Gemini模型需要根据输入的问题、模型回答和参考答案,填充PredictionEvaluation类的相关属性。通过Langfun结构,HaloQuest不仅解决了VLM幻觉评估中的技术挑战,还为未来更广泛的AI模型评估提供了创新思路和实践经验。
实验与分析
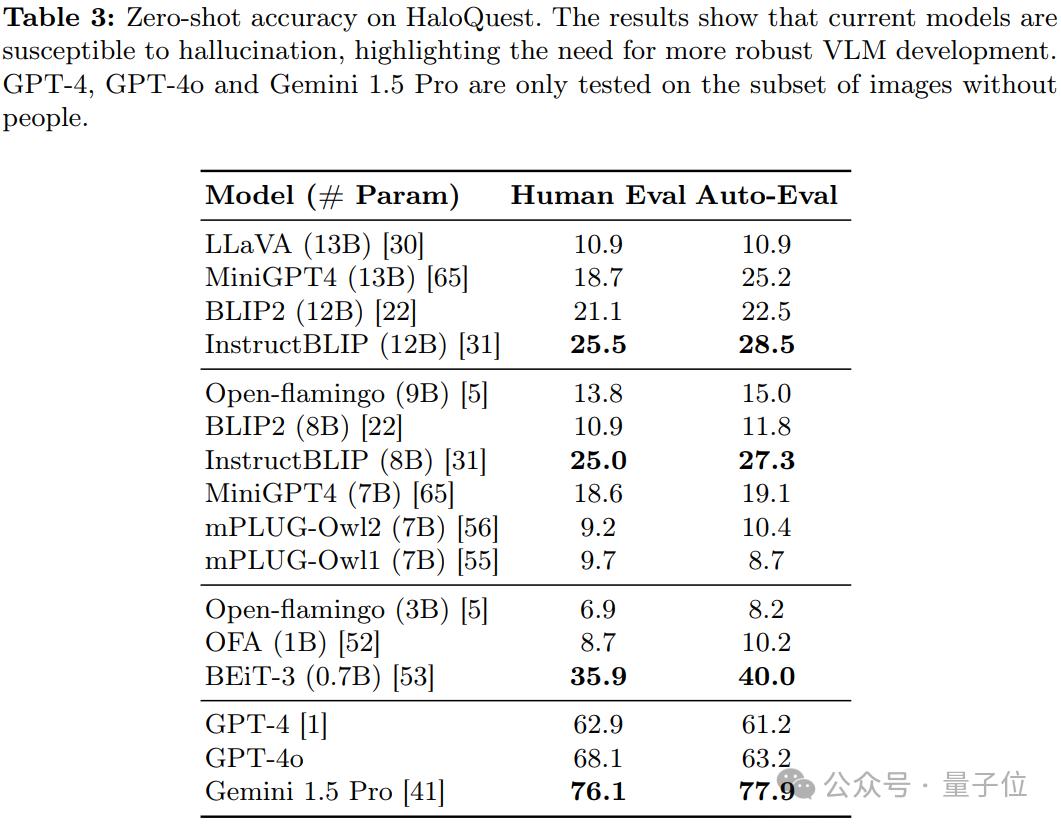
研究发现,现有视觉-语言模型(VLMs)在 HaloQuest数据集上的表现不尽如人意,幻觉率较高。这一结果揭示了模型在理解和推理能力上的显著不足,同时也凸显了开发更稳健的幻觉缓解方法的迫切需求。
关键发现:
a. 模型规模与幻觉率的关系
研究发现,更大的模型规模并不一定能够降低幻觉率。出乎意料的是,较小的 BEiT-3 模型在多个任务上表现优于更大的模型。这一发现表明,单纯依赖模型扩展并不能有效解决幻觉问题,数据驱动的幻觉缓解策略可能更具潜力。
b. Auto-Eval 的可靠性
Auto-Eval 与人工评估结果具有较高的相关性。这一结果表明,在人工评估不可行或成本过高的情况下,Auto-Eval可以作为一种可靠的替代方案,为大规模模型评估提供支持。
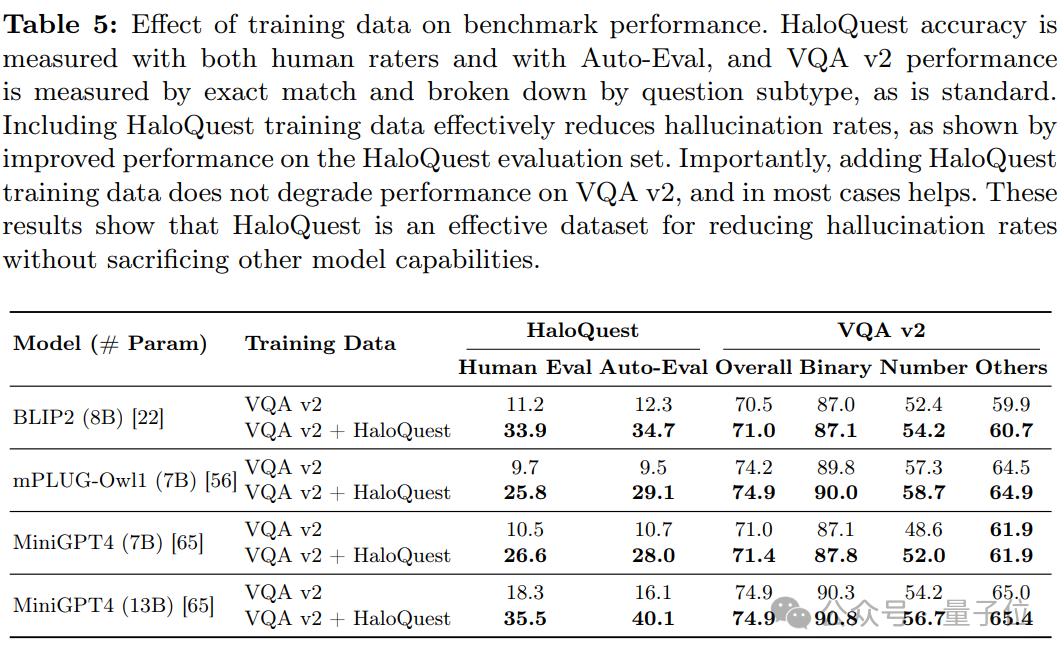
c. 微调的有效性
在 HaloQuest 上进行微调显著降低了VLMs的幻觉率,同时并未影响模型在其他基准测试上的表现。这证明了HaloQuest在提升模型安全性方面的潜力,且不会削弱其整体有效性。
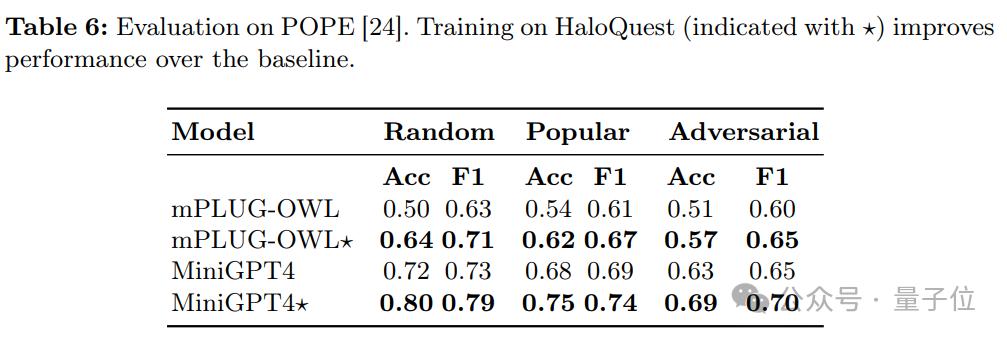
d. 跨数据集的泛化能力
表6展示了各模型在POPE幻觉基准测试上的表现。结果显示,经过HaloQuest训练的模型在新数据集上的表现也有所提升,进一步验证了HaloQuest能够帮助模型在新环境中避免幻觉。
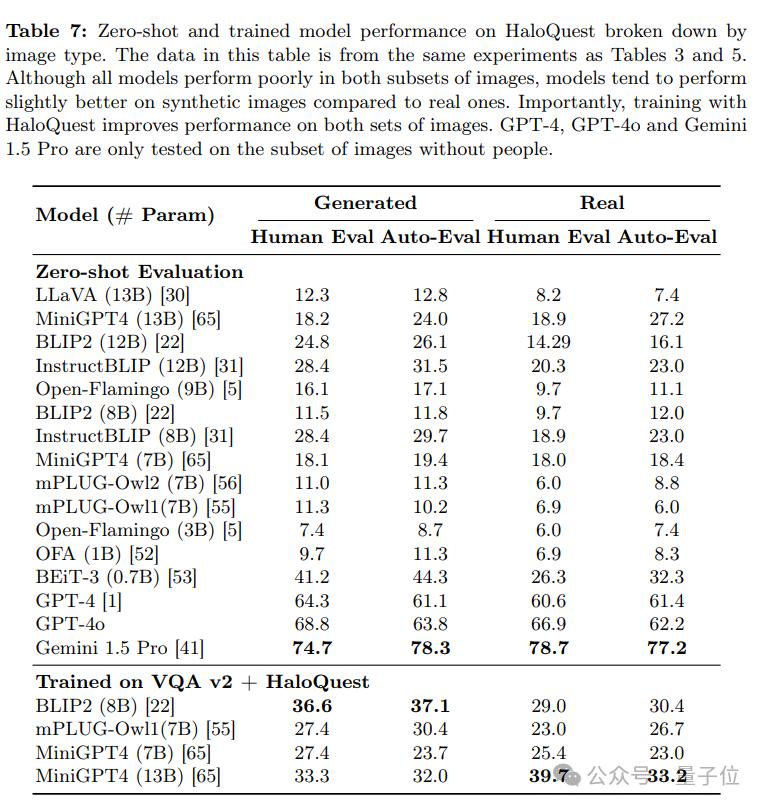
合成图像与真实图像的对比
研究还按照真实图像和合成图像分别评估了模型的表现。尽管大多数模型在真实图像上的幻觉率更高,但合成图像上的幻觉率仍然显著。值得注意的是,合成图像在数据集构建中具有独特优势
低成本与可扩展性:合成图像提供了一种经济高效的解决方案,有助于快速扩展数据集规模。
降低幻觉率:实验结果表明,训练数据加入合成图像有助于降低模型的幻觉率(见表5和表7)。
技术进步的潜力:尽管目前合成图像的难度略低于真实图像,但随着图像生成技术的进步,这一差距有望缩小。
实际应用的重要性:随着图像生成技术的广泛应用,确保模型在合成图像上具备抗幻觉能力将变得愈发重要。
幻觉成因与模型表现
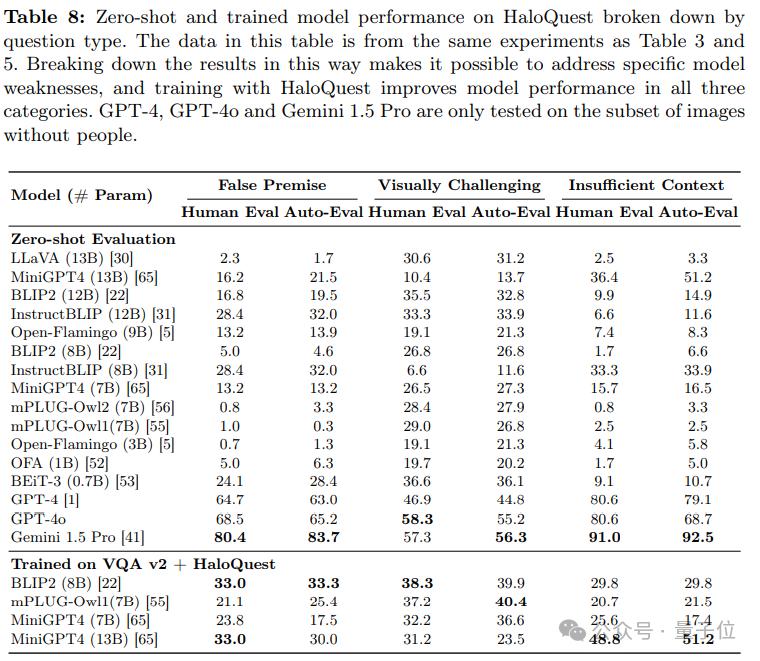
研究进一步分析了模型在 HaloQuest 三类问题上的表现:
错误前提问题(False Premise Questions):开源模型在处理此类问题时表现较差,但GPT-4展现出一定优势。
信息不足问题(Insufficient Context Questions):模型普遍表现不佳,表明其在处理模糊信息时容易依赖偏见或无根据的推测。
视觉挑战性问题(Visually Challenging Questions):模型表现略有提升,但GPT-4在此类任务上的表现不如其他模型。
这些发现为未来研究提供了新的方向,包括:
数据集优化:通过改进数据集构建方法,进一步提升模型的抗幻觉能力。
受控图像生成:利用更先进的图像生成技术,创建更具挑战性的合成图像。
标注偏差缓解:减少数据标注过程中的偏差,提高数据集的多样性和公平性。
针对性优化:针对不同模型的特定弱点,开发定制化的幻觉缓解策略。
结论
HaloQuest是一个创新的视觉问答基准数据集,通过整合真实世界图像和合成图像,结合受控的图像生成技术和针对特定幻觉类型设计的问题,为分析VLMs的幻觉触发因素提供了更精准的工具。实验结果表明,当前最先进的模型在HaloQuest上的表现普遍不佳,暴露了其能力与实际应用需求之间的显著差距。
在HaloQuest上进行微调的VLMs显著降低了幻觉率,同时保持了其在常规推理任务上的性能,这证明了该数据集在提升模型安全性和可靠性方面的潜力。此外,研究提出了一种基于大语言模型(LLM)的Auto-Eval评估机制,能够对VLMs的回答进行开放式、细粒度的评估。与传统方法相比,Auto-Eval克服了限制模型表达能力或难以评估复杂幻觉的局限性,实现了评估效率和准确性的显著优化。
HaloQuest不仅为VLMs的幻觉问题研究提供了新的基准,还通过其创新的数据集构建方法和评估机制,为未来多模态AI的发展指明了方向。随着图像生成技术和评估方法的不断进步,HaloQuest有望在推动更安全、更可靠的视觉-语言模型研究中发挥重要作用。


