

在今年春节期间DeepSeek带来的狂飙突进之后,全世界都在寻找下一个DeepSeek。
2月底,阿里通义万相Wanx 2.1模型开源,仅6天后就反超DeepSeek-R1,登顶模型热榜、模型空间榜两大榜单。此后,腾讯混元、阶跃星辰、昆仑万维等新的开源视频生成大模型陆续有来。
“下一个DeepSeek”,会诞生在AI视频这个领域吗?
不仅是专业AI视频创作者,也包括传统影视工业,短剧产业链,以及网文平台等IP所有者,都对此高度关注。
所谓“下一个DeepSeek”可以简单理解为“模型效果位于第一梯队+开源”。最核心的问题在于,一个足够优秀的开源视频大模型,会不会让现在的视频生成头部平台大幅度让利,让视频生成变成“白菜价”?
而果真如此,之后又会有什么连锁反应?
开源凶猛
事情首先要从X(推特)上面突然多出来的一大堆AI美女视频说起。
阿里巴巴于2月25日宣布开源通义万相2.1视频生成模型,不仅巩固了中国在全球AI开源领域的领先地位,更是引爆了技术爱好者的激情。
据介绍,该模型支持文生视频、图生视频任务,通过低显存需求降低技术门槛,并支持无限长1080P视频编解码,14B版本在权威评测Vbench中超越Sora、Luma等海外知名模型。
但是更重要的是,Wanx 2.1模型不仅在开源许可方式上极为宽松,模型本身也有很多能力是之前的开源,乃至很多闭源模型难以做到的。

它是“全球首个支持中文文字特效生成”的视频模型,能深度理解“中国风”指令(如生成水墨晕染的“福”字视频)。它可以精准模拟物理规律(如雨滴溅落的动态效果)。
而经过X的网友实测,它对于一些特定指令,在模型层并没有屏蔽太多的关键词,所以生成的内容也更为开放和多元,驱动了大量的“自来水”传播。
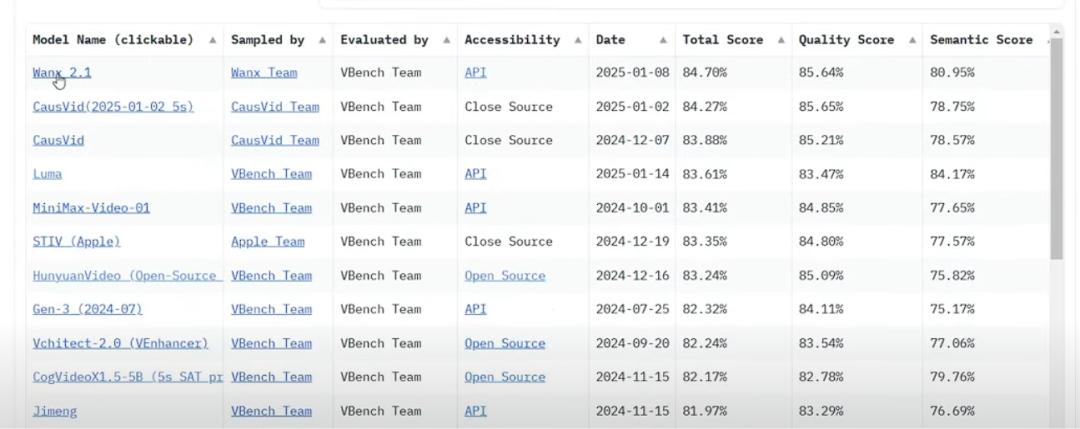
万相2.1开源后6天内即登顶Hugging Face趋势榜,也就是DeepSeek在爆火出圈之前已经在的那个榜单。它与此后开源的文本大模型QWQ-32B先后霸榜,阿里也被一些开发者称为“源神”。
开源鲶鱼搅动市场,国内其它一些重要的开源视频大模型也在这几个月内密集发布:
腾讯混元HunyuanVideo-I2V已开源推理代码和权重,有130亿参数,支持5秒短视频生成,新增对口型、舞蹈动作驱动功能,支持中英文生成,宣称在文本一致性、运动质量等维度表现领先。
阶跃星辰 Step-Video-T2V开源模型支持复杂场景生成,实测中在人物动作和物理规律方面,如芭蕾舞动作的生成等表现较优。
昆仑万维 SkyReels-V1面向AI短剧创作,基于13B参数微调好莱坞影视数据,支持T2V和I2V,生成电影级光影和表情动作,开源一周内Hugging Face下载量超2.4万次。其短剧应用DramaWave和FreeReels全球下载量达2309万次,内购收入流水超780万美元,如果其中实现实拍和AI短剧混合推送,那么盈利空间确实不小。
相应地,闭源的视频大模型也不甘落后。1月底,生数科技公布Vidu 2.0 版本,生成速度最快不到10秒,单秒视频成本仅需"4 分钱";官网同时推出错峰模式(低峰时段不限量生成,且不扣积分)。
生数近日动作频频,先是老总唐家渝挖来原字节火山引擎AI解决方案负责人骆怡航加盟,并出任新的CEO;然后又入住联想小天,走向PC预装的拉新之路,还跟两位好莱坞导演组建的一个新动画工作室联手,打算合拍一些AI动画大片。
字节除了主打即梦品牌之外,去年底开始也在大力地推的“豆包”客户端试水视频生成入口,并在今年春节前后全量上线。豆包的视频生成功能免费,但每天限制10次;跟即梦相比,在清晰度和能力上也有一些限制。
价格战前夜?
DeepSeek通过技术优化,将原本高高在上的推理模型全面普及,且成本大为压缩,API定价仅为OpenAI同类模型的3%。
这迫使国内外闭源大模型厂商紧急调整。OpenAI紧急将GPT-4.5、深度研究等功能从200美元一个月的最高档会员下放,o1也释放了思维链供用户参考。百度原本收费50元一个月的文心一言会员4月1日起全面免费。阿里通义、腾讯混元大模型API价格下调至每百万tokens 0.1元区间。
目前,作为国内视频生成领域两大“扛把子”,可灵和即梦这两个平台的会员定价非常坚挺,分别是66元/月和69元/月。虽然包年略便宜,有时也会有折扣,但总体上单次生成的费用在约0.6元/秒。
由于缺乏局部修改功能,创作者需依赖随机生成后“抽卡”完成内容制作,单个镜头动不动就要反复生成几十次。
由传统广告公司转型AI短剧的夫子AI团队介绍,他们开通了可灵和即梦的包年会员,两家年费合计5594元(平均每月约466元)。他们制作的AI短剧《我在阴间送外卖》,单个镜头需「抽卡」30次以上,每次花费约3.5元,单镜头成本超100元,整部短剧制作成本约5000元,最终播放量超90万,尽管没有直接收入,但也吸引了商业客户询单。

由广告人转型AI科幻短片的希希叔叔,选择制作非系列化的单集短片如《失败者宇宙》,降低对画面一致性的高要求。他每月花费约200元开通可灵+即梦会员,单部短片成本控制在2000元以内。作为个人创作者,他通过会员积分和「闲时折扣」压缩成本,一部短片的制作周期约7天。
由UI设计师转型AI短剧的丹尼,主要依赖本职工资支撑创作。他制作的《白骨精前传》抽卡花费约5000-6000元,平均每月投入超1000元。丹尼尝试过海外服务,但Runway的价格是可灵的10倍(约1美元/5秒视频),因此坚持使用国内平台。
对比海外定价,国外平台费用平均约为国内5-6倍(就像是国内1元=国外1美元)。至于谷歌最新发布的Veo 2视频生成模型,每秒0.5美元的定价更为离谱,4秒钟就15块钱了。
参照DeepSeek引发的“按厘计价”风潮,一个足够普及的视频生成大模型,有望逼迫头部闭源模型的API价格下降到原本的1/10;企业服务则可能从万元级的项目制,转向百元级的订阅制就能满足,“大模型施工队”二次失业在即。
若开源视频大模型复刻DeepSeek路径,当前可灵、即梦等,乃至Sora、Veo等海外模型的商业模式就都有可能面临巨大的挑战。
视频的特殊性和普遍性
万相2.1虽好,但还真的没到DeepSeek那种连友商都要接入的程度,所以暂时价格战还没有打起来。实际上,现在市面上任何一个AI视频大模型,其效果都还没到能完全顶替真人实拍的程度,其中“油性”或者说“AI味儿”还是相当重的,就更不用说乱码和鬼画符的幻觉问题了。
即使有商业化的心思,人们也不敢贸然给AI短片配上跟人工短片一样的价格。湖南台风芒App播出的《兴安岭诡事》的制作成本60万,全集解锁只需要5.9元,跟真人微短剧显然不在一个档次。该剧最终播放量锁定在5000万次的量级。
有人乐观地将万相2.1比作DeepSeek的V3或者V2时刻,期待着一个视频版“R1”会驾着七彩祥云从天而降,带来业界期盼已久的冲击。
不过,实际情况可能无法如此简单类比。
目前国内AI视频创作者主要使用的平台,实际上各有特色。可灵的核心优势在于真实的人类动作与高清晰度。可口可乐广告团队认为可灵生成的人类动作更自然,且画面清晰度领先于其他工具(如Leonardo、Runway)。
在娱乐资本论此前的报道 中,创作者董嘉琦提到可灵对文本的语义理解能力更强,模型迭代快,能快速响应复杂需求;擅长生成符合东方审美的场景和人物,适合广告、短剧等需要真实感和高完成度的场景。
创作者朱旭评价,即梦对物理世界的运动逻辑(如物体碰撞、光影变化)模拟更精准,适合现实类短片、纪录片风格内容。即梦也较早推出首尾帧控制功能。
生数Vidu在动漫风格化、多主体参考功能上表现突出(如生成多角色互动镜头)。正如它在《毒液:最后一舞》的水墨宣传片体现的,生成的镜头运镜更具创意,适合抽象或艺术化表达。因此它受到二次元动画、艺术实验短片作者的欢迎。
Runway、Luma等国外工具则常被用于欧美风格的创作。
所以,专业视频团队的工作流很难完全脱离对定价很贵的“两巨头”的惯性使用,正如在作图领域有豆包的替代,但MidJourney或Recraft的特定风格依然有一定依赖性一样。
现在开源视频模型的发展还不到DeepSeek那个程度,但视频生成领域的一场价格战,可能已经箭在弦上。
同属闭源模型的生数科技Vidu,在推出2.0版以后也上线全新的收费套餐,直接将每秒单价成本降至最低4分钱。以各家720P每秒单价计算,Vidu 2.0为 0.258元/秒,是行业平均价格的不到一半;而且官网“错峰模式”在半夜抽卡,甚至是全免费。
去年底,生数科技投融资负责人樊家睿对娱乐资本论表示 ,今年Vidu预计在生成速度、多元一致性和多模态真正融合方面会有重大突破。“生成速度方面,Vidu将进一步“逼近极限”。把速度提上来,意味着把性价比提上来,AI视频生成会更普及、更高效。”
全网都在考虑“你们大模型全开源了,那到底咋挣钱啊”的问题。不过就算没有开源震撼弹,闭源厂商一样会卷价格,因为视频大模型背后没有秘密。
正如Manus联合创始人张涛此前所言 ,光鲜亮丽的Sora背后也是“大算力出奇迹”的常规路线,是算力、算法、数据堆叠而成的结果。各家闭源厂商用常规的步伐,已经可以快速走量,压低价格。
年初震撼业界的Sora最后是“起个大早,赶个晚集”。在国内视频生成模型的军备竞赛中,效果迅速到达世界领先水平,得到了全球客户的认可。去年圣诞节可口可乐的广告使用了可灵 作为主力工具。
根据AI产品榜统计的2月份应用 (不含网站端,下同)数据,可灵海外版在全球认知更高,占到出海总榜的第12位,海外版的月活环比增幅也达到90.55%。相比之下,曾经的当红炸子鸡Luma月活下降了31%,是2月份统计中降速最大的应用。
现在的问题显然是,这个赛道里的参与者还不够多。
API和本地部署问题
影响定价的另一个变量是,如果云计算平台放开了部署一些视频大模型的API,或者用户在自己的电脑上装稍微小一点的模型,使得普通视频的制作成本降低,会不会牵动头部模型降价?
DeepSeek官网和官方API在春节期间被突然涌入的流量冲击到瘫痪,但所谓“一鲸落,万物生”,云计算提供商早一天部署R1,用量早一天暴涨。
微软、腾讯、百度均一反常态,第一时间在云服务和C端产品两方面接入DeepSeek。硅基流动的日均调用量突破千亿token,较半年前增长十倍,从名不见经传的小型云一下变得路人皆知。
现在来看视频生成模型方面。近期比较出名的开源模型,都已经在HuggingFace和魔搭等地开放使用。如果厂商有自己的云,也会第一时间上线部署。
作为不自带云的小厂,阶跃的模型和Vidu等类似,都是优先服务于自家官网平台,目前首要任务还是获得更多人的接触和使用。
不过,所有这些服务都没有出现那种“国运级别”的用量暴涨。
当然,中小型云服务商很乐意接入尽可能全面的开源模型,以便将用户锁定在自己的服务内。去年11月,硅基流动上线了由Lightricks开源的视频生成模型LTX-Video,这是一个基于DiT架构的2B参数模型,能够在832*480分辨率下生成24 FPS的视频。
但另一个现实问题是,对视频生成模型API的调用,目前还缺乏一个普遍的方案。Chatbox、Cherry Studio等网页UI或客户端,都只覆盖了文字对话或者文生图界面,对视频生成的界面、参数等尚未统一。
而且,从文本、图片到视频,其token的消耗和浪费程度是倍数上升,相对的用户用量也逐级下降。
视频还有一个额外问题,只要预览每次“抽卡”成果,都可能带来很大的服务器负担。娱乐资本论之前探讨 为什么国内视频网站的画面都是“糊的”,曾经提到了平台出于服务器成本压力,不得不降低码率,用锐化等方法蒙混过关的苦衷。
云服务商自己也需要做一些性能调优,例如硅基流动的OneDiff加速库,据说可以使Stable Diffusion出图效率提升3倍。不过如何将类似经验迁移到视频上,真正做到给普通用户省钱,形成对商用模型的竞争态势,现在还没个谱。
至于本地部署——在自己的电脑放一个模型,当然是免费不限量的,但之前的问题是要么笨,要么慢。
DeepSeek-V3和R1有大量社区用户结合llama、qwen进行蒸馏,使其有机会运行在PC、Mac甚至手机上面。这是两年多以来,用户终于可以断网运行一个基本可用的模型,本地大模型不再是“样子货”。
但是在图片和视频生成方面,还没有迎来这样的时刻,目前本地小模型依然处于用起来很困难的状态。用户可以在本地部署Stable Diffusion已经有很长时间了,但Midjourney一直也没有因此而降价。
通义万相2.1小型的1.3B版本可在消费级显卡(如RTX4090)运行,生成480P视频仅需4分钟——但没有人向你保证本机生成480P视频可以解决画质、一致性、细节和幻觉问题。
总之,视频和图片一样,如果一次生成不可局部修改,必须“抽卡”的局面不改变,那么现有模型仅凭画风及连续性上的细微区别,就会一直维持各自的江湖地位。
AI视频创作彻底下沉
根据AI产品榜2月份应用数据,国内总榜中即梦排行第9,月活环比增加106%;Minimax的海螺第19(不过这是分拆改名之前的数据),环比月活也增加10%,同时海螺以日均使用时长6.63分钟排在国内时长榜的第2位;可灵独立客户端第23,月活环比增加113%。
这意味着过去一个月,一些头部视频生成大模型的C端使用都有了大幅度增长。App的增速上升,无疑也意味着视频制作的下沉,因为专业创作者更喜欢用Web端来生成。

AI作图 by娱乐资本论
随着豆包和元宝这两个通用AI客户端都加入了视频创作功能,更多下沉用户认知到AI视频,并且在日常生活中尝试,只是时间问题。
在娱乐资本论 ·视智未来的《对话AI创业者》节目中,闪剪智能的创始人严华培提到,由于算法优化和技术更新,数字人的制作定价从最初的一个8000元,降至去年8月时的300多元。通过订阅制,会员可以付费后多次修改数字人形象。
但如果是以大模型路线,而不是传统数字人路线来做,那么数字人可能就会低至几块钱甚至免费了,它可能会从大厂和媒体,降到网店老板之后,进一步下沉到菜市场的摊主。

回想DeepSeek发布之后,似乎有很多人的“任督二脉”突然被打通。它触达了以前可能从未接触过、也从未想象过的圈层。
父母辈使用DeepSeek询问子女的婚姻解法,年轻人则为自己算命、购买开运宝石,或是通过联网搜索充当购物导购。也有越来越多AI网文充斥各大平台,使人类作者和编辑感到痛苦。
在抖音快手等将拍短视频的自由下放给所有人之后,视频大模型的快速普及将是“技术民主化”的又一次飞跃。
事实证明,一项技术不是要等到发展成熟了才向下推广。当前的视频生成还存在清晰度、幻觉等严重的问题,但这可能并不是海量普通人在使用时会考虑的问题。
近期一些典型的“AI造谣”案件,不论是地震中小孩子的假图片,还是娱乐资本论曾经揭露的“江西帮” 炮制所谓“西安爆炸”假新闻,无一例外,并没有尝试做得特别逼真,只是用了最简单的,甚至是两三年前的过期AI技术。
当"抽卡自由"彻底释放人类的表达欲,视频内容将会汇入文本和图片的洪流,它们早已跟AI难解难分。我们和我们的后代所处的世界,将被生成式内容共同塑造和改变。
-
 C114通信网
C114通信网 -
 通信人家园
通信人家园
