

就在今天凌晨,OpenAI的全新音频模型上线了!语音智能体的时代正式开启了!现在可以利用新的语音模型,指导GPT-4o的说话语气:想温柔就温柔,让疯狂就疯狂!而且,定价也很亲民,比上一代语音模型更便宜。
就在今天凌晨,OpenAI的全新音频模型上线了!
这次,一共发布了三款全新语音识别模型gpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-mini-tts,正式开启了语音智能体的时代。
三款模型的语音转文本和文本转语音的功能,让开发者能轻松构建智能体。
gpt-4o-transcribe (语音转文本):比原来的Whisper模型更准确,更理解人类说话,错误更少
gpt-4o-mini-transcribe (语音转文本):gpt-4o-transcribe 的精简版本,速度更快、效率更高
gpt-4o-mini-tts (文本转语音):可控性强,用户可以直接对它发号施令,不仅指定说什么,还能教它怎么说
在价格上,也有大惊喜:API价格,最低达到了每分钟0.3美分!
跟昨天的o1-pro API的天价token相比,语音模型的API真可谓是良心价了。
要知道,昨天的OpenAI史上最贵API,输入价格150美元/每百万token,输出价格600美元/每百万token,比DeepSeek-R1要贵上千倍。
这也就意味着,以后像客服中心记录电话或者记录会议内容这样的工作,都会变得更可靠,更方便,甚至更便宜!
语音转文本的两个全新模型,比起之前又来了一波大升级,比OpenAI原来的Whisper模型更准确,能更好地理解人类语音。
在多种语言上,有更低的词错误率(WER)。

最新语音转文本STT模型,减少了在FLEURS上的转录错误率WER
其中,语音转文本GPT-4o-Transcribe在API中可用,每分钟仅0.6美分,与Whisper价格相同,而GPT-4o-Mini-Transcribe是0.3美分,是满血版的半价。
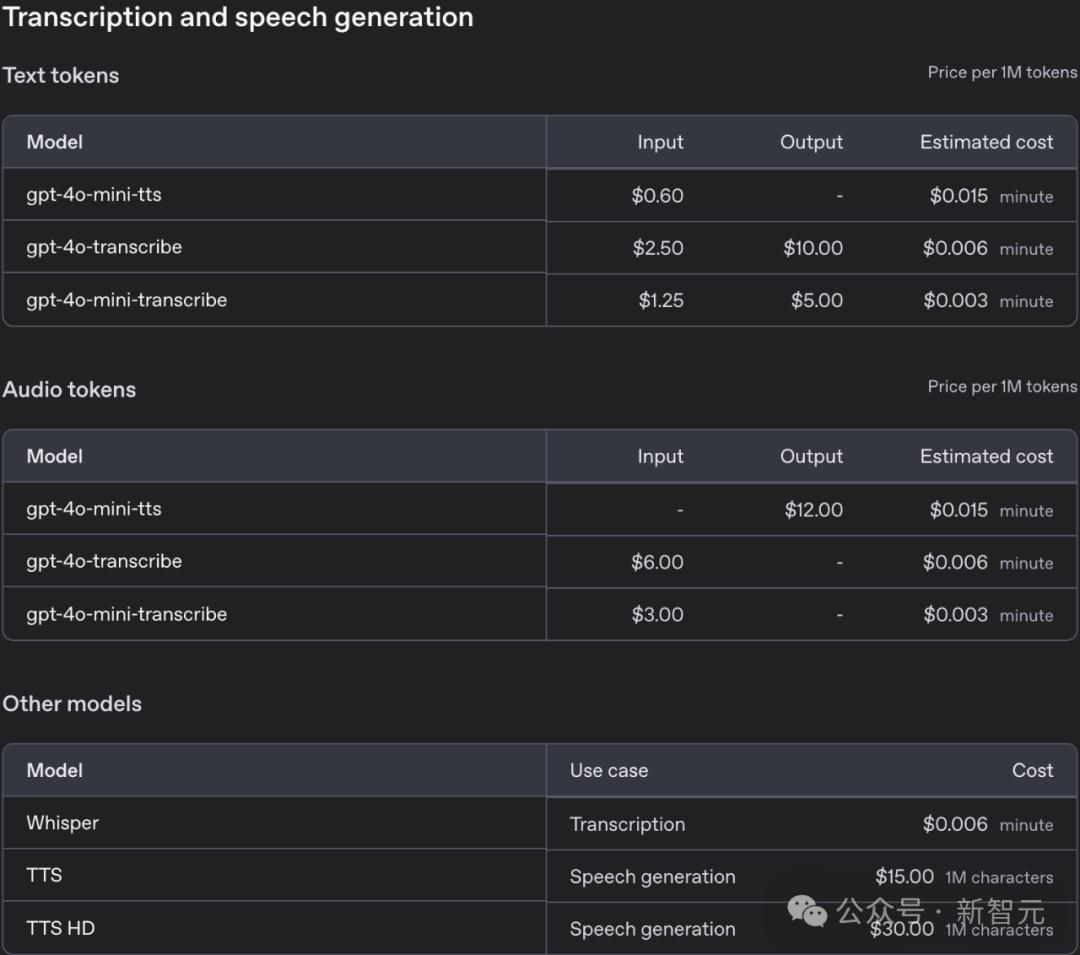
其他模型为OpenAI上一代语音模型
这些新模型可以通过API来使用,让开发者能创建更智能、更个性化的语音助手。
从而更好地理解各种口音和快速说话,甚至在嘈杂的环境中也表现良好。
另外,OpenAI还推出了一个新的TTS(文本转语音)模型:gpt-4o-mini-tts。
现在,OpenAI已经开放了免费体验地址,只要输入文字,就可以生成语音,还能选不同的语气。
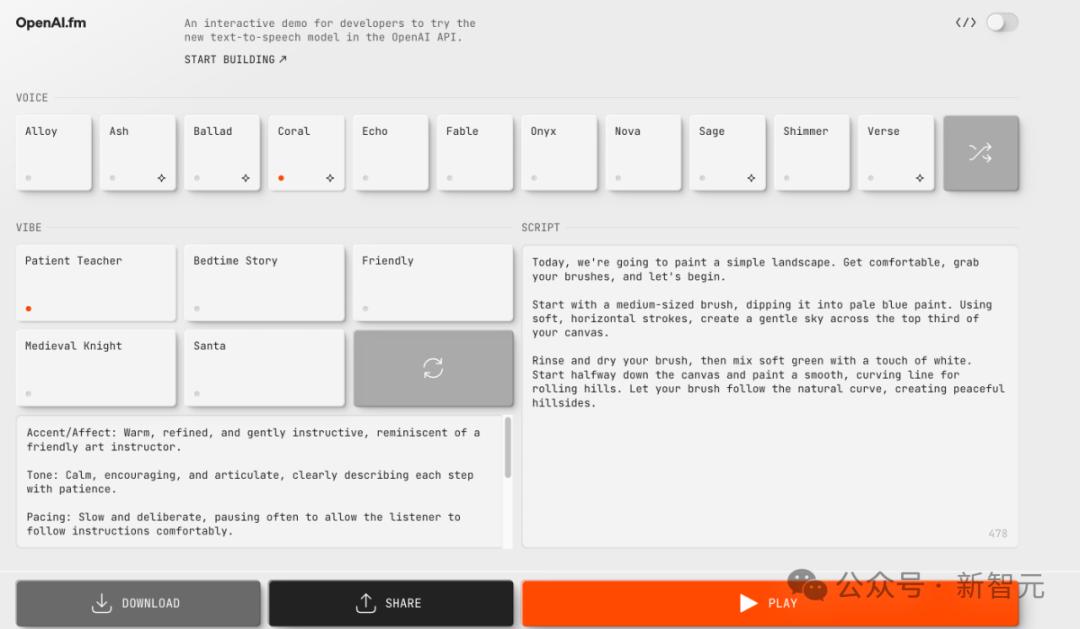
API体验地址:https://www.openai.fm/
现场实测
昨天凌晨的直播中,OpenAI给我们现场怼脸实测,展示了一番新的TTS模型实际表现到底怎么样。
首先,他们的VOICE(音色)选择了Ash,然后在VIBE(大概是情感的意思)中随机出了Mad Scientist(疯狂科学家)。
之后输入了需要合成音频的脚本:
Ah-ha-ha! The stars tremble before my genius! The rift is open, theenergy surging-unstable? Perhaps. Dangerous? Most certainly!
Captain Rylen's hands twitch over the controls. Fools! They hesitate, but I-I alone see the future! 「Engage the thrusters!」 I bellow, eyes wild with possibility.
The ship lurches, metal groaning-oh, what delicious chaos! Light bends,time twists,and then-800M!
Silence. Darkness. And then. oh-ho! A new universe! Bigger! Stranger! Andmine for the taking!
Ah-ha-ha-ha!
首次尝试的时候没输出,不过刷新后很快模型正常输出音频,大家可以通过下边视频感受一下模型的效果。
可以听得出,合成的语音质量还是挺高的,基本上没有多少AI味了,甚至还有一些高级感。
语音清晰,但语气狂得飞起,听起来就像一本正经的吹牛。
接着,他们又换了另一种VIBE:Serene(宁静),输入了下面的合成脚本:
This livestream is going really well! You are doing great.
这次的语音效果就显得十分平静,给人一种宁静感,就像李白《静夜思》的意境一样。
还可以利用全新的的语言模式,直接调用智能体!
从今以后,文本智能体转换为语音智能体变得轻而易举。
直播中,演示了要在电话上使用Patagonia客服智能体,需要修改已有智能体的哪些代码。
只用9行代码,智能体不仅听得懂人话,而且会开口说话了!
就像AI版的Siri,可以直接询问最近的订单,智能体听起来就像真的客服一样。
Agent调用工具,获得相关信息后,回答自然,准确,流畅。
直播的结尾,还有一个小彩蛋。
OpenAI现场宣布举办有奖竞赛,可获得全球限定版收音机:
谁能想出最有创意的文本转语音使用方式,并分享给Open AI的Twitter账户,就有机会获得特别版收音机。
他们会选出3位获奖者,可能是因为这款收音机全世界只有三台,背面有Open AI的logo。
创意爆棚的小伙伴可以去碰碰运气。

OpenAI,意在语音Agent
OpenAI在博客中称,新的语音模型套件旨在为语音Agent提供强大支持,并已向全球开发者开放。

在最近几个月里,OpenAI一直在努力让文本智能助手变得更聪明、更强大、更有用。
OpenAI推出了很多Agent产品,比如Operator、Deep Research、Computer-Using Agents和Responses API,这些都是为了帮助AI助手更好地完成任务。
但是,为了让智能助手真正有用,需要让AI能和人更自然、更深入地交流,就像我们和朋友聊天一样。
所以,OpenAI让智能助手不仅能理解我们的话,还能用自然的声音回答我们。
现在,开发者还可以让智能助手的语音听起来更人性化,比如听起来像一位温柔的客服人员。这样,智能助手就能更好地为客服、讲故事等不同的场合服务。
自从2022年推出第一个音频模型以来,OpenAI一直在努力让AI变得更聪明、更准确、更可靠。
现在,开发者可以用这些新的音频模型来创建更准确的语音转文本系统和听起来更自然的文本转语音系统。
所有这些功能都可以通过API来实现。
全球领先的语音识别模型
昨天,OpenAI推出了两款新的语音识别模型:gpt-4o-transcribe和gpt-4o-mini-transcribe。
它们比原来的Whisper模型更准确,能更好地理解我们说的话。
在几个重要的测试中,gpt-4o-transcribe表现比Whisper模型好,错误更少。
这是因为OpenAI用了更先进的学习方法和更多音频数据。
这些新模型能更好地理解人说话的细节,减少错误,特别是在有口音、很吵或者说话很快的情况下。
现在,这些模型已经可以在OpenAI的语音转文本API中使用了。
新模型在多个测试中都取得了更低的WER,包括一个包含100多种语言的测试。这表明新模型在更多的语言上都能表现得很好。
指标「词错误率」(word error rate,WER)用于衡量语音识别的准确性:WER越低,表示模型越准确。
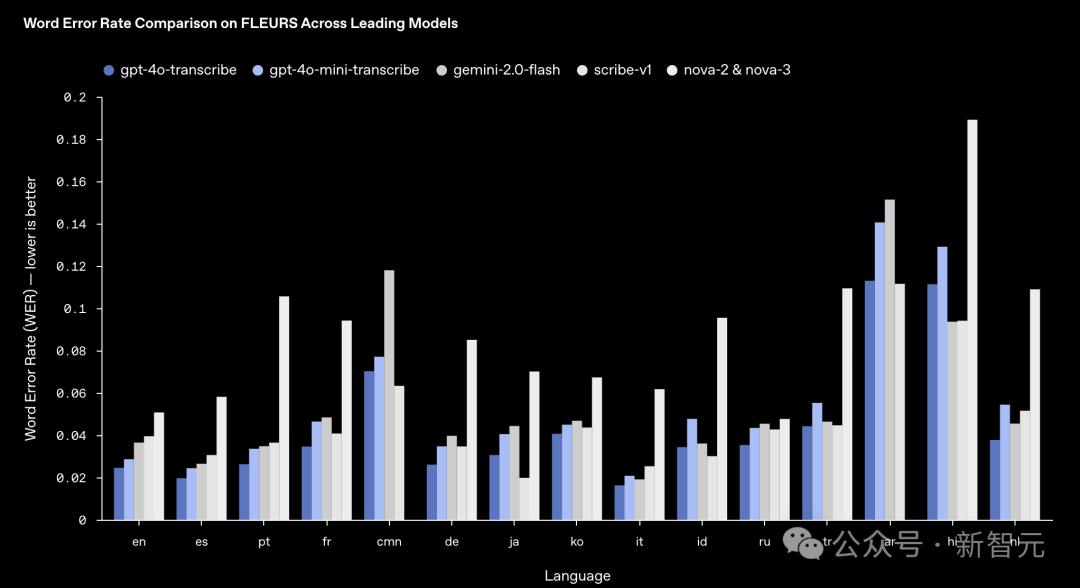
顶级模型在FLEURS上,不同语言的的WER比较
如图所示,新模型在大多数主要语言上的表现都优于其他领先的模型。
这意味着OpenAI的语音识别技术,在全球范围内都是领先的。
全新文本转语音TTS模型
OpenAI还推出了全新的gpt-4o-mini-tts 模型,具有更好的可控性。
开发者们有福啦!现在可以对模型 「发号施令」,不仅能告诉模型该说啥,还能教它怎么说。
不管是搞客户服务,还是进行创意故事创作,都能有超棒的定制体验。
目前,已经在文本转语音API里上线。
不过要注意,现在文本转语音模型只有人工预设的声音。
OpenAI会紧紧盯着,保证出来的声音和预设的合成声音一模一样。
模型背后的技术创新
在真实音频数据上预训练
在GPT-4o和GPT-4o-mini架构之上,新的音频模型在专门的以音频为中心的数据集上进行了大量预训练。
这些数据集对于优化模型性能至关重要。
这种有针对性的方法使得模型能更好地理解语音中的细微差别,从而在音频相关任务中表现出色。
先进的蒸馏方法
OpenAI还改进了蒸馏技术,使得大型音频模型能够将知识有效地转移到更小、更高效的模型中。
通过采用先进的自我博弈方法,蒸馏数据集成功捕捉了真实的对话动态,模拟了真实的用户与助手的互动。
这帮助小型模型在对话质量和响应性上表现优秀。
强化学习范式
对于语音转文本STT模型,OpenAI引入了强化学习(RL)范式,让转录准确度达到了最先进的水平。
这种方法显著提高了精准度,并减少了幻觉,在复杂语音识别场景中具备了极强的竞争力。
这些技术进展代表了音频建模领域的突破,结合创新的方法和实际的增强,提升了语音应用的性能。
API全球开放
这些新音频模型现已向所有开发者开放。
更多关于如何使用音频的内容,参阅OpenAI的相关文档。
API文档:https://platform.openai.com/docs/guides/audio
添加语音转文本和文本转语音模型,最简便方式的构建语音代理。
OpenAI还发布了与Agents SDK的集成,开发过程更加简单。
如果开发者希望构建低延迟的语音转语音体验,OpenAI建议使用语音转语音模型来构建实时API。
OpenAI还提供了简单的Demo,点击下展示页面Play按钮,即可体验人性化的机器语音。
如需体验,在https://www.openai.fm/上,点击右上角切换按钮即可
未来计划:多模态AI
展望未来,OpenAI计划继续投资于提升音频模型的智能性和准确性,并探索允许开发者引入自定义声音的方式,从而打造更个性化的体验,同时遵循安全标准。
此外,将继续与政策制定者、研究人员、开发者和创作者进行对话,共同探讨合成语音所带来的挑战与机遇。
OpenAI期待看到开发者利用这些增强的音频能力,打造出创新和创意应用。
同时,也会投资于其他媒体形式——包括视频——以便开发者能够构建多模态的智能体验。
参考资料:
https://platform.openai.com/docs/pricing#transcription-and-speech-generation
https://www.youtube.com/live/lXb0L16ISAc
https://www.openai.fm/
https://openai.com/index/introducing-our-next-generation-audio-models/


