

在全民接入DeepSeek的热潮下,第一个有关大模型的冷思考出现了。
2月9日,潞晨科技创始人尤洋在社交媒体发表了一条“暴论”:MaaS(Model as a Service)在中国短时间内可能是最差的商业模式。
尤洋通过计算得出,现阶段通过token计费所获得的收入远远不足以覆盖大模型的算力成本。“如果满血版的DeepSeek R1每日输出1000亿Token,那么每月的机器成本是4.5亿,亏损约4亿”,“用户越多,亏损越多”。
一石激起千层浪,月亏损4亿这一数字引发了对于MaaS商业模式的巨大争议。
硅基流动创始人袁进辉在朋友圈回应称,关于4.5亿的成本估算是过于夸张的,原因是使用了错误的架构进行的估计。
什么才是正确的架构?其实就藏在DeepSeek的官方论文里——一个“MLA+DeepSeek MoE+专家并行”的部署策略。
上周六,DeepSeek在其开源周的最后一天发布“one more thing”,公布其推理系统参考架构,基于该架构DeepSeek的成本利润率高达惊人的545%。不过DeepSeek尚未开源该架构的代码。
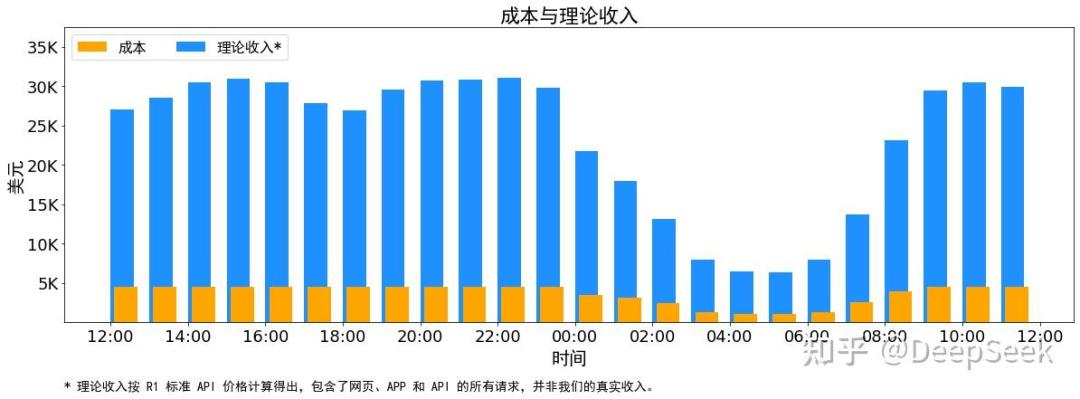
图片来自DeepSeek知乎账号
争议并没有结束。尤洋针对DeepSeek MaaS成本发文回应,认为这一成本并没有太多参考价值,因为DeepSeek把网页、App也加在一起计算为“理论收入”了,而实际上这部分C端用户的服务是免费的。尤洋也强调,MaaS是to B的服务,绝不允许出现宕机、高延迟、服务器崩溃等类似的问题,否则不是一个合格的MaaS。
袁进辉则认为,DeepSeek官方披露的大规模部署成本和收益,又一次颠覆了很多人的认知。现在很多供应商还做不到这个水平,因为DeepSeek模型架构跟主流模型差别太大了。至于MaaS能不能做,一方面要看技术是否过硬,另一方面要看是否有足够多的用户,从而有机会削峰填谷。如果一个MaaS平台一天只有几千个访问用户,确实没法干。硅基流动此前公布的用户总数超三百万,日均调用上千亿token。
此后,尤洋与袁进辉你来我往交锋了数个回合,争议的范围也从最开始的MaaS商业模式上升到了友商之间的商业互怼。本文不讨论双方之间的个人恩怨,只尝试厘清一个最根本的问题:
关于MaaS的商业模式,到底谁的观点是正确的?
从开源的角度理解MaaS
在进一步讨论MaaS的商业模式之前,有必要先重新厘清什么是MaaS。
MaaS,模型即服务,是继IaaS、PaaS与SaaS之后云计算产业链的新生态位。根据公开资料,智谱在2022年就提出了MaaS,是国内最早提出这一理念的AI公司。2023年11月底,阿里云在云栖大会上将MaaS理念进一步推广,后来逐渐成为大模型产品服务形态的共识。
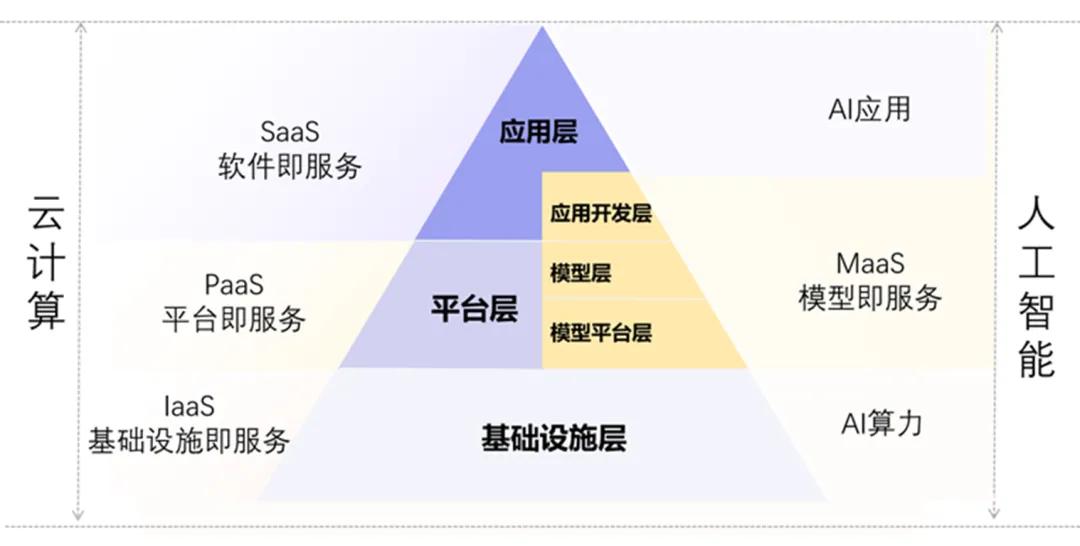
MaaS定位与比较示意图,来自中国信通院《MaaS框架与应用研究报告(2024年)》
智谱与阿里云分别代表了两类典型的MaaS服务商。
前者是初创大模型公司,会建立自己的MaaS平台(API开放平台),但只能提供自己的大模型服务;后者代表了云计算厂商,其MaaS平台不仅提供大厂自研的大模型,还会接入第三方大模型,比如火山引擎的火山方舟、阿里云的百炼、腾讯云的TI平台、百度智能云的文心千帆。
这两类MaaS厂商有一个共同点,那就是都自己从头训练大模型,MaaS平台就是将大模型的能力打包封装成标准化的API对外提供服务,一般按照token收费。
但尤洋的潞晨科技、袁进辉的硅基流动并没有自研大模型,只提供第三方开源模型的MaaS服务。这是在大模型公司与云计算公司之外的第三类MaaS,也可以称之为“AI推理云服务”。
AI推理云是一个冉冉升起的新赛道,同一类型的企业包括海外炙手可热的Fireworks、Together AI,以及春节之后国内各种宣称适配DeepSeek的云服务,除了潞晨科技与硅基流动之外,无问芯穹、PPIO派欧云、ZStack云轴科技、并行科技等公司也提供MaaS服务。
AI推理云服务的兴起离不开一个必要条件——开源。
假如没有开源模型,用户就只能从大模型公司或者云大厂的MaaS平台两者之间做选择。而开源模型的出现不只是让市场上增加了一个模型,更是增加了很多个模型服务平台。因为任何有技术能力的团队,都可以自由下载、部署开源模型,然后对外提供API服务。就像我们今天看到的,DeepSeek虽然只是一个模型,但能够提供DeepSeek第三方服务的云平台,就有十几家。
注意,这并非MaaS厂商的“采购—分销”模式,而是基于开源协议下的免费下载、部署。开源模型厂商除了得到了技术品牌的推广(不要低估了这件事),没有任何收益。
由开源模型激发的AI推理云服务有可能改写传统的MaaS市场格局,意味着大模型token价格的降价空间。
大模型token的价格原本与其训练、推理等综合成本息息相关。训练与推理的成本越高,token的价格就越贵。此前「甲子光年」做过预估,Meta训练Llama 3.1 405B大约花费5800万美元,OpenAI训练GPT-4大约花费6300万美元,Anthropic训练Claude 3.5 Sonnet大约花费3000~5000万美元。这些成本都将体现在大模型token的价格里。
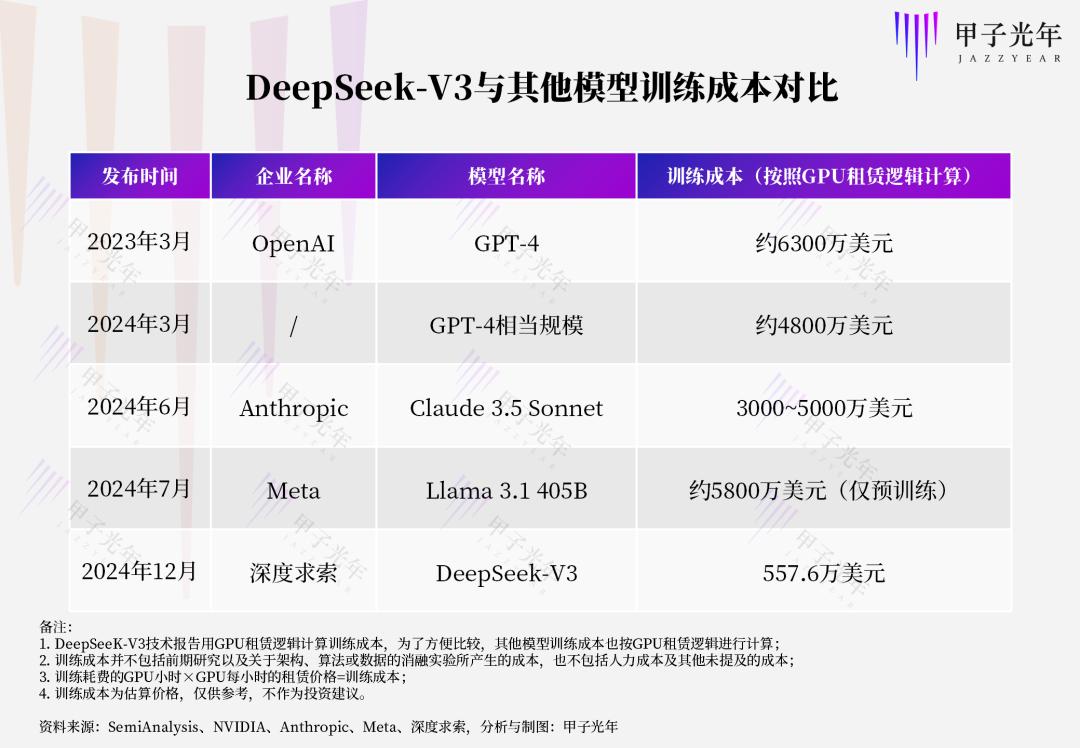
但现在有了开源模型之后,第三方MaaS服务商无需承担一分钱的训练成本,只要有算力云平台以及模型部署的技术,以及符合开源协议,就可以提供与官方相同的大模型服务。
去年7月,人工智能科学家、DeepLearning创始人吴恩达表示,OpenAI大模型的价格每年下降79%。推动价格下降的力量是Llama 3.1等开源模型(开放权重模型)的发布。如果API提供商(包括Anyscale、Fireworks、Together AI和一些大型云公司)不必担心收回开发模型的成本,就可以直接在价格和速度等其他一些因素上展开竞争。
于是,2024年6月发生了这样一幕:硅基流动宣布对包括Qwen2-7B、GLM-4-9B、Yi-1.5-9B等在内的开源大模型永久免费,让很多开发者实现了“token自由”。
免费的前提就是开源。这些免费的模型本身参数量较小,算力消耗并不大。袁进辉曾告诉「甲子光年」,这类入门级的免费模型起到了引流与培养开发者习惯的作用。对于更大参数的模型,则是单独的定价体系。
硅基流动是适配DeepSeek最早的团队,在DeepSeek V2发布后的很长一段时间都是官方之外的唯一第三方供应商。袁进辉承认,自己眼光这么好,当然有“赌”的成分在,而且也只能赌开源。DeepSeek V2发布的时间点,其他开源模型的能力普遍还不行,而DeepSeek编程能力非常突出,很多人想用,就只好硬着头皮把DeepSeek支持了。
既然Meta、Qwen以及DeepSeek等优秀的大模型都开源了,对于第三方MaaS平台来说相当于一下子节省了上千万美元的训练成本,那么是不是很容易就能盈利了?
当然没有这么简单。
DeepSeek很强,但作业难抄
当我们讨论MaaS的商业模式是否成立的时候,可以通过一个简单的计算公式来估算:“MaaS毛利=Token收入-推理所消耗的算力成本”。
Token收入是相对明确的。按照满血版DeepSeek R1每日输出1000亿token、每百万token 16元的官方价格来估算,每月收入约为4500万元。
成本主要为算力租赁成本与电费,电费先忽略不计。按照尤洋的计算方式,在4台H800上部署满血版DeepSeek R1的生成速度为1000~1500 token/s。要达到每日输出1000亿token的效果,大约共需要4000~5000台H800。按照每台H800每个月租赁的价格为7.5万元计算,算力租赁成本大约为4.5亿人民币。
而且,这还是在机器利用率跑满的理想情况下计算的。现实的情况可能更加骨感。因为算力租赁成本是固定支出。如果用户规模太小撑不起高并发、夜间用户数急剧下降导致的机器算力闲置,还将会进一步降低收入,提高运营成本。
因此,尤洋得出了大约每个月亏损4亿人民币的结论。
如果真是这样,那么MaaS完全不适合中小厂商,只能是云大厂的生意。潞晨科技已经在本周宣布暂停DeepSeek R1的API服务。
整个计算过程都是没有问题的,唯一的争议在于机器的吞吐率,即大模型每秒生成的token数量,存在巨大的浮动空间。
尤洋的计算标准是4台H800的吞吐率为只有1000~1500 token/s,这是不是太小了?假如通过技术优化的方式,将机器吞吐率提升10倍,那么机器成本就会降低到十分之一,大约是4000万元,刚好来到盈亏平衡线附近。十倍的吞吐率提升是可以实现的吗?
我们可以参考下业内的一些公开数据。
英伟达官方公布的数据是,搭载了DeepSeek R1满血版的NVIDIA NIM微服务,单台NVIDIA HGX H200系统上吞吐率可达到3872 token/s。假如单台H200是单台H800性能的2.5倍,那么换算成H800的吞吐大约是1500 token/s,大约是尤洋计算标准(4台H800计算)的4~6倍。
AMD官方也公布了一组测试数据,对比了单台H200与单台MI300X两款芯片在DeepSeek R1的吞吐表现。当并发值为128,H200的吞吐率达到3702 token/s,与英伟达官方的数据相近;而MI300X的吞吐率为3640 token/s。这样估算,其吞吐率大约也是尤洋计算标准的数倍。
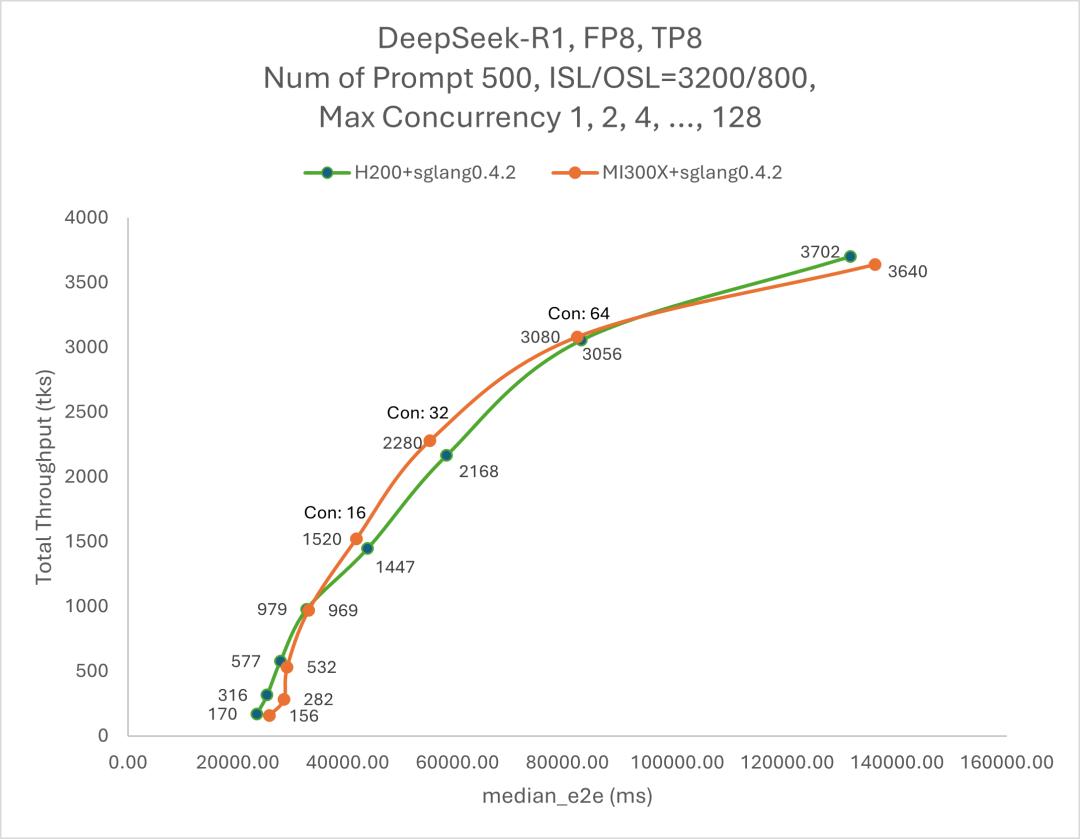
Deepseek R1 总吞吐量 (tks) 与延迟 (ms),图片来自AMD
DeepSeek在上周六公布的数据更加惊人,平均每台H800的吞吐量,生成任务达到了惊人的14800 token/s,大约是尤洋计算标准的10~15倍。同时,DeepSeek宣布其成本利润率为545%。在同一时期,DeepSeek官方宣布R1 API降价,夜间空闲时段的价格由每百万token 16元调整为4元,降至四分之一。
DeepSeek在用实际行动证明,这个价格真的是有利可图的。2024年,DeepSeek创始人梁文锋在接受《暗涌》采访时谈及价格战,表示DeepSeek的定价原则是“不贴钱,也不赚取暴利。这个价格也是在成本之上稍微有点利润”。
但是,DeepSeek能做到的,不代表其他人也能做到。这是本次MaaS商业模式争议的本质问题——DeepSeek真的很强,但目前还没有人可以复现。
袁进辉表示,虽然DeepSeek官方披露大规模部署成本和收益,又一次颠覆了很多人认知,但现在很多供应商还做不到这个水平,主要是V3/R1架构和其它主流模型差别太大了,导致瞄准其它主流模型结构开发的系统都不再有效,必须按照DeepSeek报告描述的方法才能达到最好的效率,而开发这样的系统难度很高,需要时间。
到底有多难呢?袁进辉透露,硅基流动去年适配DeepSeek V2时,仅开发一个MLA(DeepSeek提出的注意力机制)就“费老鼻子劲了,前后可能花了一个月的时间,开源推理引擎一直没有搞定高效的MLA实现,大部分云厂商也就没有办法部署”。
火山引擎总裁谭待在上个月提到,“豆包1.5Pro模型的预训练成本、推理成本均低于DeepSeek V3,更是远低于国内其他模型,在当前的价格下有非常不错的毛利”,“这个价格,完全是依赖技术进步可以做到的。”但豆包大模型是一个闭源模型,外界无法得知具体的训练与推理方法,无法直接对比。
DeepSeek在上周的开源周里开源了很多Infra层的关键模块,降低了社区复现的难度,但第六天的“one more thing”——最关键的推理架构,只介绍了整体的方法 ,并未开源相关代码。
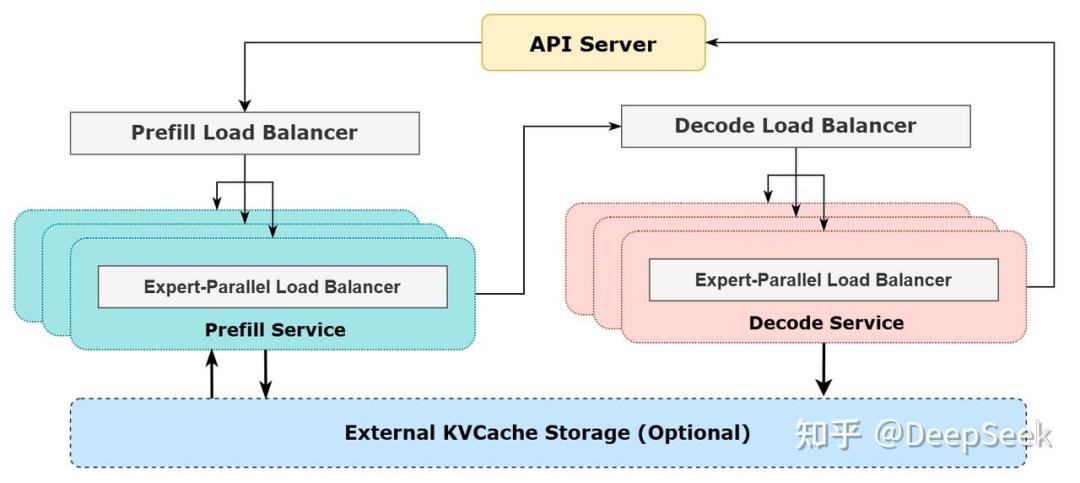
DeepSeek-V3/R1推理系统参考架构,图片来自DeepSeek知乎账号
某公司的AI架构师对「甲子光年」表示,这只是在“秀肌肉”,当然不排除未来会开源。
至此,关于MaaS的商业模式是否成立,我们或许可以得出一个看似“端水”但实际很客观的结论:
尤洋跟袁进辉分别站在自己的角度其实都是对的。尤洋更强调当下的技术水平无法实现,是关于“实然”的表态;袁进辉更强调未来的技术可以实现,是关于“应然”的表态。
至于站在客观现实做出最有利的商业决策,还是像DeepSeek那样赌一个未来,那就是见仁见智的事情了。
一种两极化的推理架构
为什么DeepSeek的推理方法很难被复现?
中存算董事长陈巍博士提到,很多人更关注DeepSeek做模型训练的能力,但实际上DeepSeek的AI Infra能力,特别是软硬件协同优化能力,才是他们超越国内其他大模型团队的关键。
清华大学助理教授章明星的观点是,单纯是因为现在还没有很好的支持DeepSeek V3/R1这种级别的超稀疏模型而已,现有的技术方案比如vLLM/SGlang无法完全发挥出DeepSeek MoE架构的优势。
那么,DeepSeek MoE架构有什么优势?
MoE模型是混合专家模型的简称,与之相对应的则是Dense(稠密)模型。Dense模型的工作原理是,无论处理的是一个复杂任务还是简单任务(比如“1+1=?”),都要激活整个神经网络来计算。而MoE模型将一个神经网络分成数个专家模型,每次任务只需要激活特定专家来计算,与该任务无关的模型无需激活,从而实现相同算力下计算效率的提升。
行云集成电路创始人、CEO季宇观察到,由于海外AI市场由充分的算力供应,所以MoE模型与Dense模型的发展是齐头并进的,比如Meta训练的Llama 3 405B让人叹为观止。
而在国内,在算力供应严重受限的客观背景下,70B以下的模型尚可选择Dense模型,若想继续扩大参数规模,几乎只能选择MoE模型。于是我们看到,从阶跃星辰、MiniMax到如今的DeepSeek,都选择了MoE的路线。
这一路线的分化,也许就是扇动大模型产业蝴蝶效应的第一下翅膀。
因为Dense模型与MoE模型分别适合不同的训练与部署策略,前者适合张量并行(TP,Tensor Parallelism),后者适合专家并行(EP,Expert Parallelism)。TP模式是将一个超大参数模型的权重分割到不同的GPU上,最后统一将所有计算结果进行处理,因此涉及大量的卡间数据通信传输,对NVLink的带宽和低延迟特性依赖较强;而EP的基本逻辑不再是分割权重,而是分割专家,只有被激活的专家才会涉及卡间的通信互联,而没有被激活的专家无需涉及通信传输,从而降低通信成本。
DeepSeek V3/R1在传统MoE架构的基础上进一步优化,不再使用少数大专家的结构,而是使用了多达256个路由专家和1个共享专家组成的混合专家。在训练策略上,DeepSeek直接抛弃了TP,All in EP。
这种专家并行的训练策略得到的DeepSeek模型也需要专家并行的部署方式,即每一张卡上分别部署一个路由专家,一共需要256张卡;然后再用64张卡专门用于冗余专家和共享专家,最终一共需要320张卡。
也就是说,在DeepSeek给出的官方方案中,如果想发挥DeepSeek MoE模型的最佳效果,需要准备的最少的GPU卡的数量是——320张。
从资源上说,320张卡的起步资源要求就不是一个普通的MaaS初创公司所能玩得起的游戏;从技术上说,DeepSeek的训练、推理以及软硬件一体的协同优化能力都是企业定制化技术,其他竞品企业未必有类似的定制能力。

图片来自DeepSeek V3论文
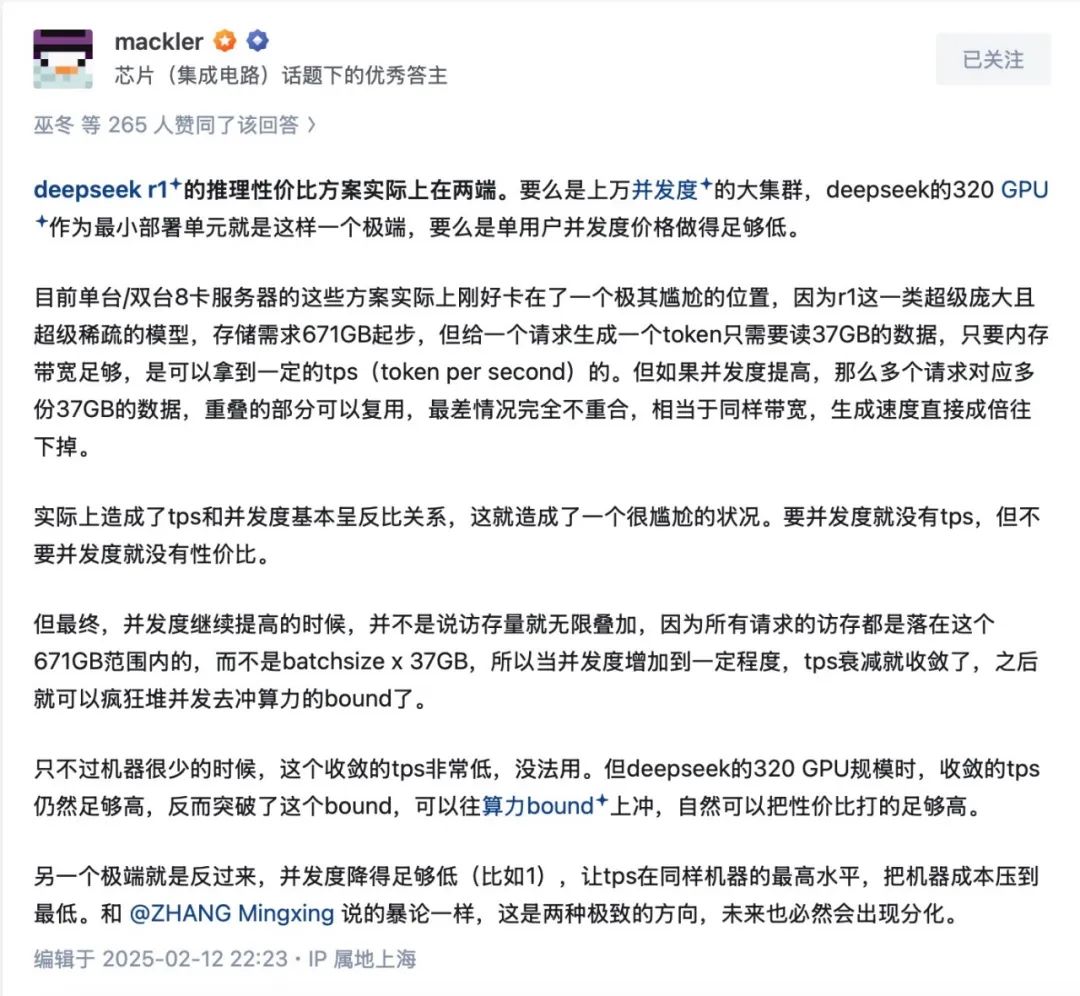
季宇认为,Deepseek R1的推理性价比方案实际上是两个极端——要么是上万并发度的大集群,DeepSeek的320 GPU作为最小部署单元就是这样一个极端,要么是单用户并发度价格做得足够低。而目前单台/双台8卡服务器的方案实际上刚好卡在了一个极其尴尬的位置,那就是并发与每秒的模型生成速度呈反比关系,要并发度就没有tps,但不要并发度就没有性价比。
图片来自季宇知乎账号截图
章明星也提出了一个结论:如果超大稀疏的MoE模型成为主流,那么云上面向大并发的分布式推理,和本地面向中小并发的推理架构就要开始分叉了,需要分别演进。
陈巍也认为,基于成本角度分析认为,目前只有to C云计算场景(类似OpenAI的网页版服务)才会真正用上MoE这种多专家的模型架构。

陈巍表示,DeepSeek的V3/R1模型事实上为英伟达GPU开拓了除Llama开源系列Dense模型之外的MoE开源模型新大陆,等同于为苹果的iOS市场增加了新的免费Killer App。
按照这一角度理解,“DeepSeek MoE+专家并行”的模型与部署方式,以及基于此的演进与优化方向,的确是更适合大厂以及在C端有野心的初创大模型公司所尝试的路线。
工程优化与架构创新
大模型成本降低的因素,总结来说可以分为两大类型,一是极致的工程优化,二是天才般的架构创新。前者更难复制,后者更难超越。一个优秀的大模型团队,往往兼而有之。
前文提到的“DeepSeek MoE+专家并行”是工程优化的代表。MoE是1991年就提出的概念,专家并行也是2022年就由谷歌推出的训练方法,但DeepSeek却是第一个将这一方法优化到极致的大模型团队。
业内除了DeepSeek之外,在工程优化上也有惊艳表现的国内团队是月之暗面Kimi。
2024年11月,月之暗面Kimi联合清华大学MADSys实验室联合发布了一项名为Mooncake的开源项目,旨在共建以KVCache为中心的“Prefill/Decoding分离”(简称PD分离)推理架构,其基本原理是将推理过程中的两个关键阶段——Prefill(预填充)和Decode(解码)分离到不同的计算实例上运行,可以独立优化两个阶段的性能。
月之暗面工程副总裁许欣然在知乎上表示:“我们坚信一个系统方案只有实际在场景中验证过的,才有分享出来的必要性。本论文与很多Prefill/Decoding分离的论文不同的是,这套方案已经在大规模集群上进行几个月的验证并证明了方案的有效性。这也是为什么一个POC写在所有业内论文之前的系统,直到今天才发布出来跟大家见面。”许欣然还表示,目前这套系统承载了Kimi线上80%以上的流量,效果很好也为产品带来了更多的设计空间。
工程级的优化也包括硬件层的优化,比如去年一大批号称“英伟达杀手”的AI推理芯片初创公司,包括Groq、Samba Nova、Cerebras等,都推出了生成速度更快、价格更低的推理解决方案。此外,英伟达、AMD、英特尔和高通的硬件创新也进一步推动了token价格的下降。
除了工程优化,另一个降低成本的方式是在大模型底层算法的创新,典型代表就是针对“注意力机制”的改进。
注意力机制是大模型的核心机制,来自于谷歌团队在2017年发布的开山之作《Attention is all you need》。在这篇论文中,谷歌提出了MHA多头注意力(Multi-Head Attention),核心原理是通过并行计算的方式提高计算效率。但这一机制也有一个致命缺点,那就是当需要处理的上下文越长,计算量呈平方级而非线性增长,从而导致计算成本暴涨。
围绕注意力机制的改进有不同的思路,核心是围绕降低存储与降低计算,从而降低成本。
针对降低存储(KV Cache),多头注意力机制经历了从MHA、MQA(Multi-Query Attention)、GQA(Grouped-Query Attention)到MLA(Multi-headLatentAttention)的演变历程,其中前三者都是谷歌所提出,MLA由DeepSeek提出。月之暗面研究员苏剑林在其个人博客中将这一过程总结为“缓存与效果的极限拉扯”。
针对降低计算复杂度,业内又有稀疏注意力机制(Sparse Attention)与线性注意力机制(Liner Attention)两种不同的思路。比如,近期DeepSeek的NSA与月之暗面的MoBA在同一天撞车发布,是针对稀疏注意力机制的改进;今年1月MiniMax发布的首款开源模型MiniMax-01,就是对线性注意力机制的改进。
大模型的成本降低是一个系统性工程,需要从算法、架构、硬件、系统等全方位角度进行协同优化。更高的性能与更低的成本,这是技术DNA的“双螺旋架构”,大模型的发展逻辑也是如此。
而“DeepSeek时刻”,可能正是开启AI普惠时代的奇点时刻。


