

IT之家 3 月 4 日消息,加利福尼亚大学圣地亚哥分校的 Hao 人工智能实验室(Hao AI Lab)上周五开展了一项独特的研究,将人工智能(AI)引入经典游戏《超级马力欧兄弟》中,以测试其性能表现。研究结果显示,在参与测试的 AI 模型中,Anthropic 的 Claude 3.7 表现最为出色,紧随其后的是 Claude 3.5。相比之下,谷歌的 Gemini 1.5 Pro 和 OpenAI 的 GPT-4o 则表现不佳。

需要明确的是,此次实验所使用的并非 1985 年最初发布的《超级马力欧兄弟》版本。游戏运行在一个模拟器中,并通过一个名为 GamingAgent 的框架与 AI 进行连接,从而让 AI 能够控制马力欧。GamingAgent 由 Hao 人工智能实验室自主研发,其向 AI 提供基本指令,例如“如果附近有障碍物或敌人,向左移动或跳跃以躲避”,同时还提供游戏内的截图。随后,AI 通过生成 Python 代码的形式来操控马力欧。

据实验室介绍,该游戏环境迫使每个 AI 模型“学习”如何规划复杂的操作并制定游戏策略。有趣的是,实验发现像 OpenAI 的 o1 这样的推理模型(它们通过逐步思考问题来得出解决方案)表现不如“非推理”模型,尽管它们在大多数基准测试中通常表现更强。研究人员指出,推理模型在实时游戏中表现不佳的主要原因之一是它们通常需要花费数秒时间来决定行动。而在《超级马力欧兄弟》中,时机至关重要,一秒钟的差别可能意味着安全跳过和坠落死亡的不同结果。
数十年来,游戏一直是衡量 AI 性能的重要工具。然而,一些专家对将 AI 在游戏中的表现与技术进步直接挂钩的做法提出了质疑。与现实世界相比,游戏往往是抽象且相对简单的,并且能够为 AI 训练提供理论上无限的数据。
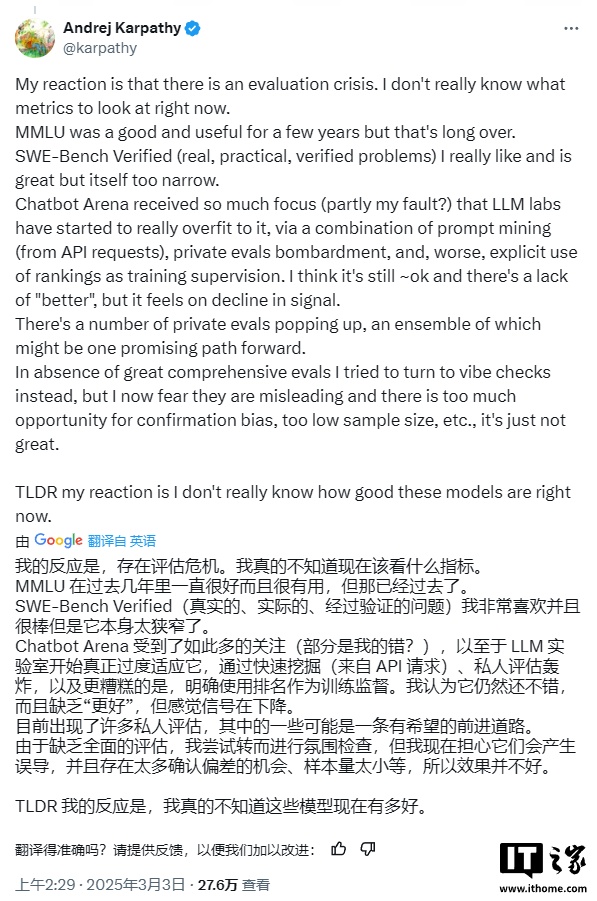
IT之家注意到,最近一些引人注目的游戏基准测试结果引发了 OpenAI 研究科学家、创始成员安德烈・卡帕西(Andrej Karpathy)所说的“评估危机”。他在 X 平台上发表的一篇帖子中写道:“我目前真的不知道该关注哪些 AI 指标。”他总结道:“我的反应是,我目前真的不知道这些模型到底有多好。”
尽管如此,至少我们还可以观看 AI 玩马力欧,这本身也是一种有趣的体验。


