


当机器人面对 真实环境中的复杂任务 时,如何做到不只是执行单个简单指令,而是也能 自主推理完成目标所需的多个步骤 ,进而像人类一样出色地完成任务呢?
对此,美国具身智能初创公司 Physical Intelligence 的答案是—— 让机器人学会以系统 2 思维进行思考。
美国著名心理学家 Daniel Kahneman 将人类解决问题的两种思维模式描述为“系统 1”(“System 1”)和“系统 2”(“System 2”)。系统 1 是直觉、本能且自动的;系统 2 则是深思熟虑和有意识的。
打个比方,当人类做一道新菜肴时,他们会查看食谱,准备食材,在做菜的过程中仔细思考每一个步骤。这时所用的思维模式就是系统 2 思维。但是,当某人第一百次做同一件事时,熟练到几乎不用思考,只需机械化地完成,所用的就是系统 1 思维模式。
昨日,Physical Intelligence 推出了“分层交互式机器人”(Hi Robot)系统,其能够将视觉-语言-行动(VLA)模型,如 π0 ,纳入一个分层推理过程。 π0 作为本能反应的“系统 1”可以执行熟练的任务,而一个高层次语义视觉-语言模型(VLM)则充当“系统 2”,通过“自言自语”来推理复杂任务和语言交互。这个系统 2 的高层次策略促使机器人能够将复杂任务拆解成中间步骤。
先来看一下官方给出的视频:
据介绍,这一高层次策略本身是一个 VLM,其使用与 π0 完全相同的 VLM 主干网,在训练后 可以处理复杂的提示、观察场景并将任务拆解成易于执行的小步骤, 将这些步骤(如“拿起一片全麦面包”)交给 π0 的 VLA 模型来执行,同时 结合实时的上下文反馈。
例如,如果它正在清理桌子,用户说“那不是垃圾”,模型会理解这是什么意思,将物体(“那”)与图像中机器人正在操作的物体关联起来,并正确理解隐含的指令(即,“那”不应该被放入垃圾桶,因此应该放到其他地方),从而再次将正确的中间步骤交给 π0 模型来执行。
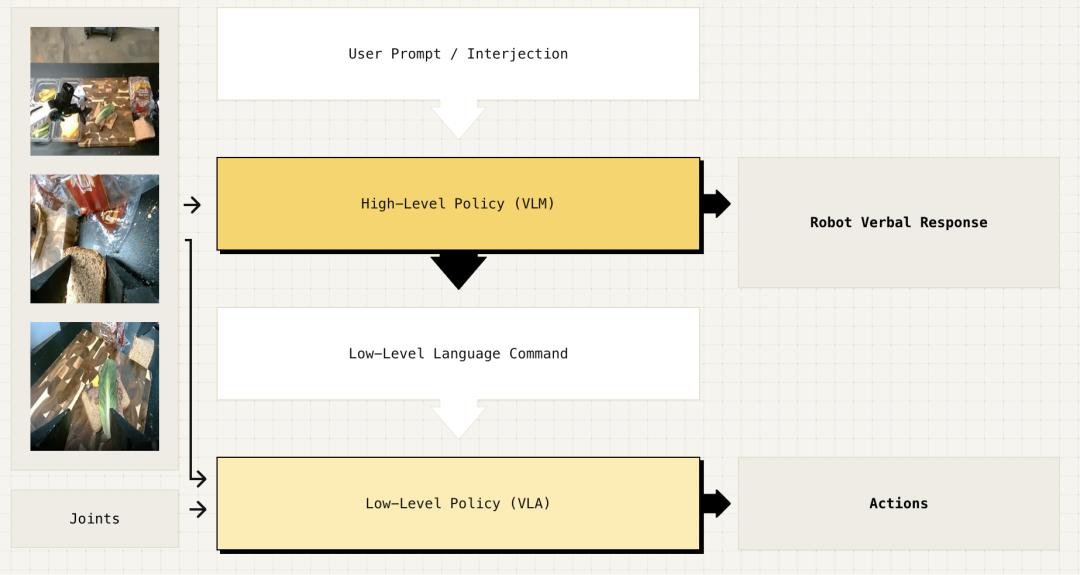
图|高级策略处理来自底座和腕装摄像头的开放式指令和图像,生成低级语言指令。低级策略使用这些指令、图像和机器人状态来生成动作和可选的语言响应。
相关研究论文以“Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models”为题,已发表在预印本网站 arXiv 上。

论文链接:https://www.arxiv.org/abs/2502.19417
分层推理有何优势?
如果高层次的 Hi Robot 策略和低层次的 π0 模型都是基于相同的 VLM,那么为什么这种分层推理过程实际上具有优势呢?
就像语言模型在解决复杂问题时,如果被允许生成额外的文本来“思考”一样, Hi Robot 如果能够先将复杂的提示和反馈拆解成简单的步骤,然后再交给 π0 模型来执行,它就能更好地处理这些复杂的提示和反馈。 还有一个更为技术性的原因: Physical Intelligence 团队用来初始化 VLM 的网络规模预训练,可以训练模型生成文本答案,来回答那些涉及图像和文本上下文的提示和问题。 这就意味着,这类模型在开箱即用的状态下,已经非常擅长回答类似“在这张图片中,机器人接下来应该抓取哪个物体来清理桌子?”的问题。
因此,Hi Robot 能够更好地继承 VLM 在大规模网络预训练中积累的知识。这与你思考的方式非常相似:当你做那道新菜肴时,你可能是在思考从食谱、朋友告诉你的东西,或者从烹饪节目里学到的东西——这些都是你从其他来源获得的知识,而非亲身体验。
机器人学会“自言自语”
Physical Intelligence 团队表示,通过检查 Hi Robot 在面对复杂提示时的内部“思维”,他们可以了解到其系统是如何通过用户提示完成复杂任务的。
在这种情况下,π0 接受的训练就是简单地清理桌子,将所有垃圾丢进垃圾桶,把所有餐具放入垃圾箱。如果让 π0 自己去做,它会直接执行这个任务——你有过“自动驾驶”的经历,自己不知不觉地完成了一项熟练的任务,甚至忘记了自己原本想做什么。但在 Hi Robot 的控制下,π0 可以按照这种更复杂的提示进行调整,按照用户的命令,Hi Robot 会推理出应该提供给 π0 的修改版指令。 由于这些指令是以自然语言生成的,因此可以检查它们,并观察机器人是如何“自言自语”地执行任务的。
解读用户的上下文反馈是一个类似的问题,正如 Hi Robot 可以解析复杂的提示语一样,甚至 它在执行任务的过程中也能实时地纳入反馈。
用合成数据训练高层次策略
训练机器人跟随复杂、开放式的提示,不仅仅需要带有原子指令的演示数据。仅凭这些数据不太可能提供足够丰富的多步骤交互示例。为了弥补这一差距,Physical Intelligence 团队提出了合成标注数据集的方案—— 将机器人的观察结果和人类标注的技能与假设的提示和人类插话配对。 这种方法模拟了现实的交互,帮助模型学习如何解读和响应复杂的指令。
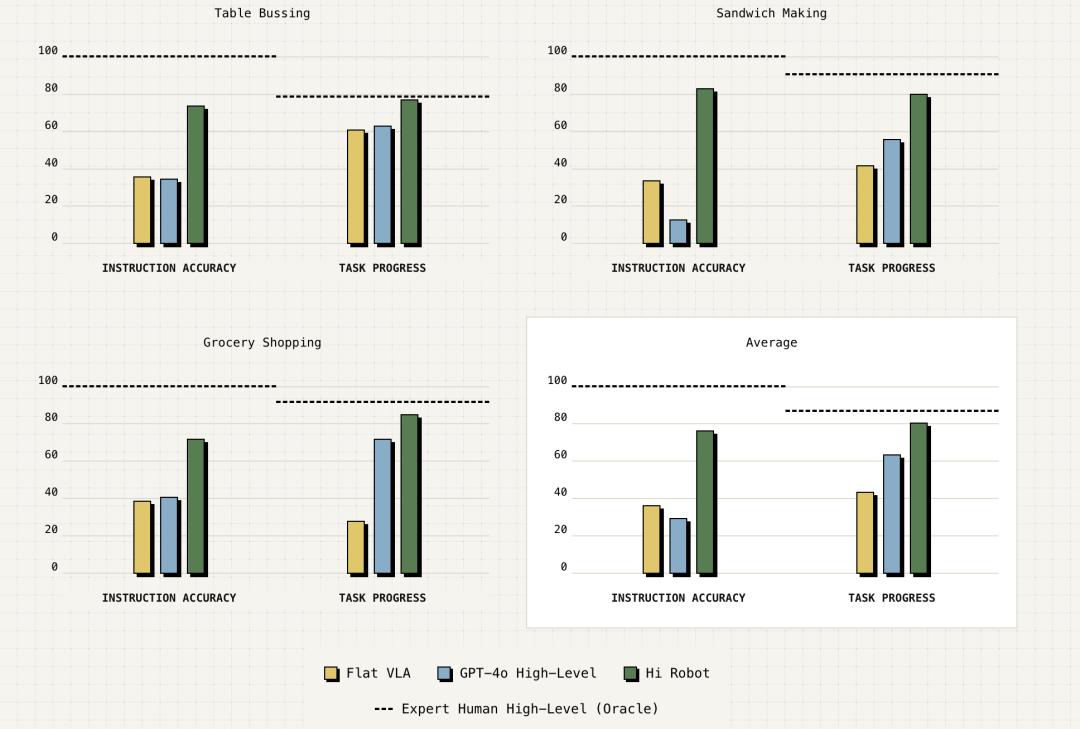
Physical Intelligence 团队对 Hi Robot 在实际任务中的表现进行了评估(如清理桌子、做三明治和购物),并与先前的方法进行了比较。结果表明,Hi Robot 在性能上优于 GPT-4o 和平面 VLA 策略。如下面的定量评估所示, Hi Robot 在指令跟随准确率上比 GPT-4o 高出 40%,表明它在对用户提示和实时观察的对齐方面有更强的能力。 此外,Hi Robot 在处理多阶段指令、适应实时修正和遵守约束条件方面优于平面 VLA 策略。
像人类一样推理
智能且灵活的机器人系统不仅需要执行灵巧的任务,还需要理解环境并推理复杂的多阶段问题。 从表面上看,Hi Robot 侧重于通过提示和反馈与用户互动,但这个系统的最终目标是赋予机器人类似于你在解决像做新食谱这样困难的问题时听到的“内心声音”。与人互动为我们提供了这一能力重要性的最生动例证,但它的意义远不止于此。
能够思考复杂问题并运用从大规模网络预训练中学到的知识的机器人将更加灵活,展现出显著更好的常识推理能力,且从长远来看,在开放世界环境中为我们提供更加自然的帮助。 它们将能够理解当有人在白板上写“请勿擦除”时的含义,知道如果一个人正在睡觉就不应该打扰,意识到脆弱物品应该小心处理。这些都是我们每天基于不仅是亲身体验,还有从他人处学到的东西所做的推理。
LLM 和 VLM 为我们提供了从互联网上学习这类知识的强大工具,但要将这些知识与机器人等物理系统无缝连接起来,却面临着巨大的技术挑战。Physical Intelligence 团队希望,Hi Robot 可以是朝这个方向迈出的重要的一步。
参考链接:https://www.pi.website/research/hirobot


