

机器之心报道
编辑:杜伟
就在昨晚,Anthropic 要发新模型的消息开始在 AI 社区广泛发酵,不过并不是期待中的 Claude 4.0,而是 3.7 Sonnet 版本。

图源:https://x.com/btibor91/status/1893970824484581825
今天凌晨,Anthropic 的新旗舰模型如约而至,正式发布了其迄今为止最智能的模型以及市面上首款混合推理模型 —— Claude 3.7 Sonnet。
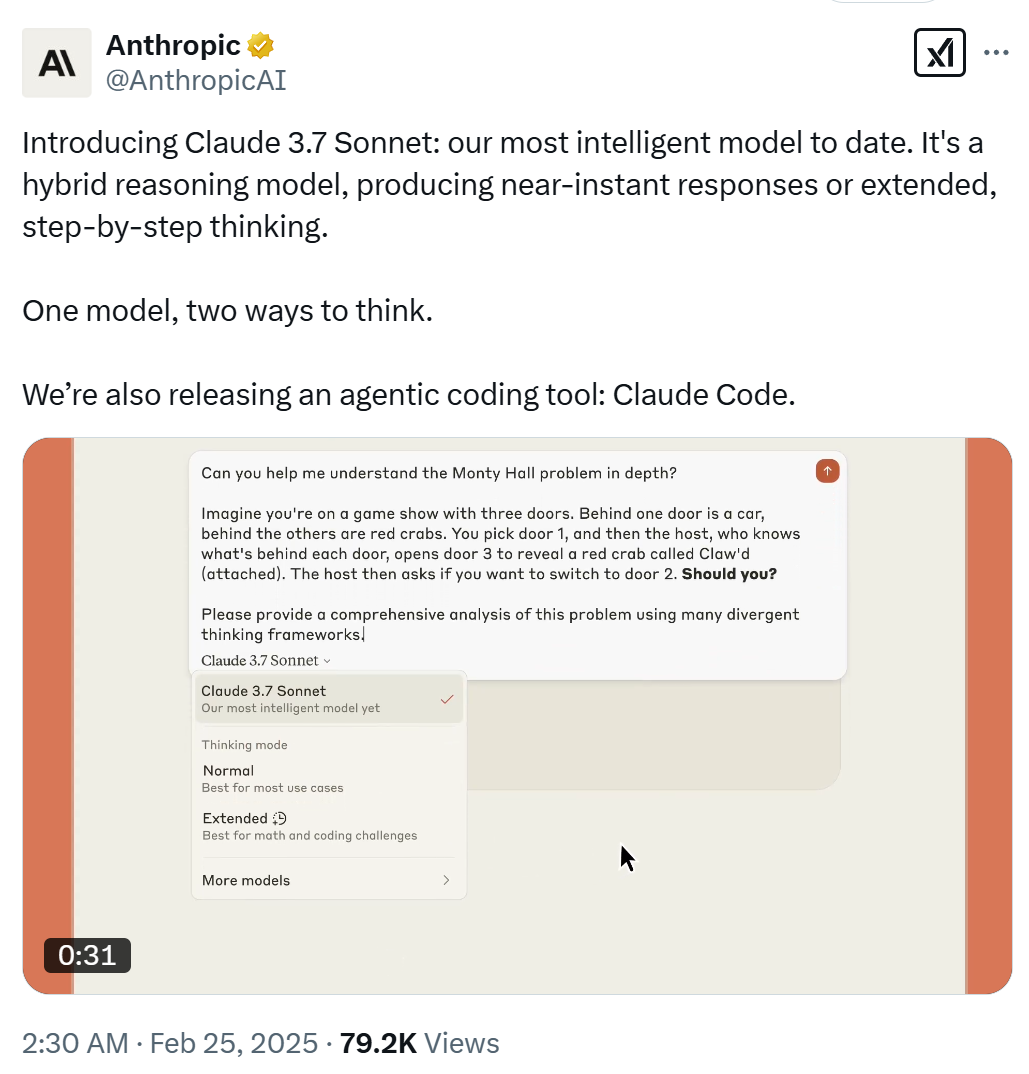
Claude 3.7 Sonnet 可以产生近乎即时的响应或者向用户展示扩展的、逐步的思考。按照 Anthropic 的说法,「一个模型,两种思考方式」(One model, two ways to think.),即标准和扩展思考模式。另外 API 用户还可以对模型的思考时间进行细粒度控制。

在发布 Claude 3.7 Sonnet 之外,Anthropic 还推出了用于智能编码的命令行工具 Claude Code。它目前作为有限的研究预览版本使用,使开发人员能够直接从他们的终端将大量工程任务委托给 Claude。

在编码方面,Anthropic 还改进了 Claude.ai 上的编码体验,其 GitHub 集成现已在所有 Claude 计划中提供,使开发人员能够将他们的代码存储库直接连接到 Claude。通过更深入地了解个人、工作和开源项目,Claude 将成为用户在 GitHub 项目中修复错误、开发功能和构建文档的更强大合作伙伴。
因此,得益于编码和前端 web 开发方面的功能与改进,Claude 3.7 Sonnet 成为 Anthropic 迄今为止最好的编码模型。
目前,新模型 Claude 3.7 Sonnet 可以通过所有 Claude 计划(包括 Free、Pro、Team 和 Enterprise)以及 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 使用。除了免费用户之外,所有其他用户均可体验扩展思考模式。
在标准和扩展思考模式下,Claude 3.7 Sonnet 的价格与其前代(Claude 3.5 Sonnet)相同,每百万输入 token 3 美元,每百万输出 token 15 美元(包括思考 token)。
正如一位网友所评价的那样,「Anthropic 的每次发布都能让人微笑并感到兴奋!」
最强 Claude 3.7 Sonnet
让前沿推理触手可及
Anthropic 表示,其开发 Claude 3.7 Sonnet 的理念与市面上其他推理模型不同。正如人类使用单个大脑进行快速反应和深度思考一样,Anthropic 认为推理应该体现前沿模型的综合能力,而不再是完全独立的模型。这种统一的方法将为用户创造更无缝的体验。
遵循上述理念,Claude 3.7 Sonnet 形成了很多独有优势。
首先,Claude 3.7 Sonnet 既是普通的 LLM,又是推理模型。你可以选择何时希望模型正常回答,何时希望它在回答之前思考更长时间。在标准模式下,Claude 3.7 Sonnet 是前代 Claude 3.5 Sonnet 的升级版。在扩展思维模式下,它会在回答之前进行自我反思,从而提高其在数学、物理、指令遵循、编码和许多其他任务上的表现。Anthropic 发现,两种模式下,模型的提示词工作方式类似。
其次,当通过 API 使用 Claude 3.7 Sonnet 时,用户还可以控制思考预算。你可以告诉 Claude 思考不超过 N 个 token。对于任何 N 值,其输出限制为 128K 个 token。这允许用户在速度(和成本)和答案质量之间进行权衡。
第三,在开发自家的推理模型时,Anthropic 对数学和计算机科学竞赛问题的优化较少,而是将重点转向更能反映企业实际使用 LLM 方式的现实任务。
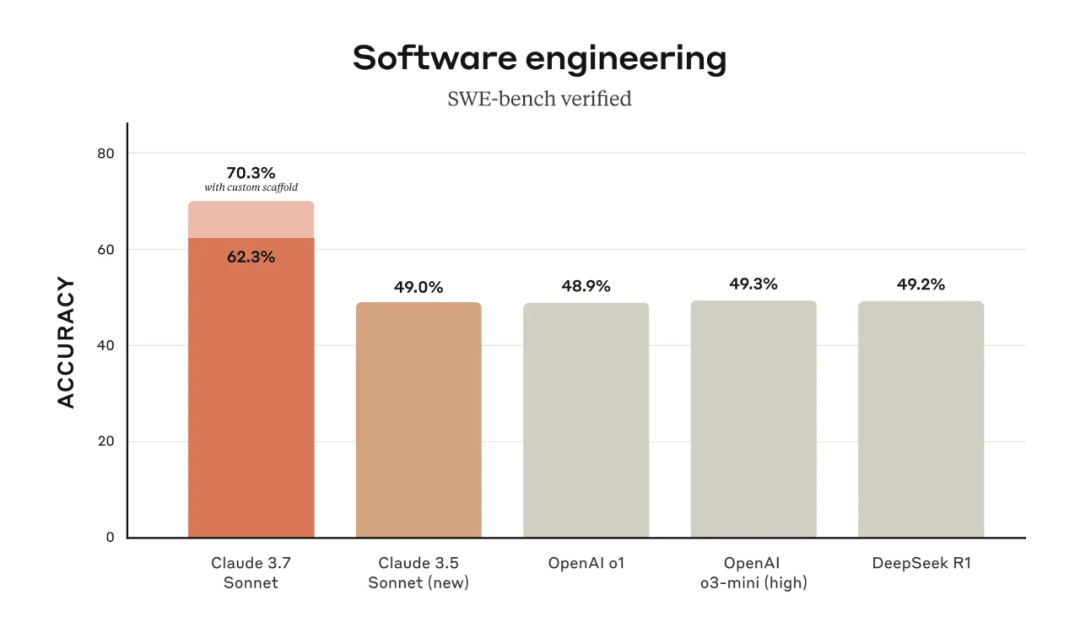
我们来看下 Claude 3.7 Sonnet 的基准测试结果,其中在 SWE-bench Verified(评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集)上,Claude 3.7 Sonnet 实现了 SOTA 性能,远远超过了 Claude 3.5 Sonnet、OpenAI 的 o3-mini (high) 和 o1 以及 DeepSeek R1。
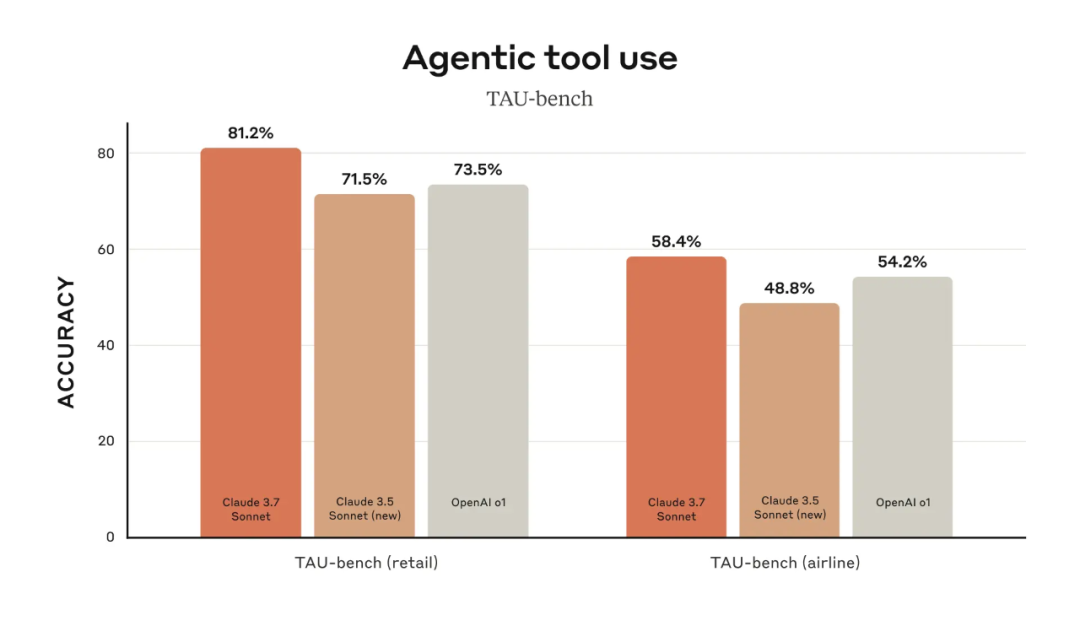
在 TAU-bench(评估 LLM 在复杂真实场景中用户与工具交互能力的基准测试平台)上,Claude 3.7 Sonnet 同样实现了 SOTA 性能,超过了 Claude 3.5 Sonnet 和 OpenAI 的 o1。
Claude 3.7 Sonnet 在指令遵循、通用推理、多模态能力和智能编码方面表现出色,扩展思考在数学和科学方面实现了显著提升,但在一些方面依然不及 OpenAI 的 o3-mini (high)、Grok-3 Beta 等。

可以看到,对于 Claude Sonnet 3.7,Anthropic 将重点放在了编码能力上,其他领域似乎并不特别重要。很明显,Anthropic 想将 Sonnet 定位为编码 AI(已经是了)。

图源:https://x.com/kimmonismus/status/1894098443859079609
另外,除了传统基准之外,Claude 3.7 Sonnet 甚至可以在宝可梦(Pokémon)游戏测试中超越所有以前的模型。
Anthropic 已经与合作伙伴进行了非常多的早期测试,证明了 Claude 在编码能力方面的全面领先地位。
其中,Cursor 指出 Claude 再次成为现实世界编码任务的最佳选择,从处理复杂代码库到高级工具使用都有显著改进。Cognition 发现,Claude 在规划代码更改和处理全栈更新方面远远优于任何其他模型。
Vercel 强调了 Claude 在复杂代理工作流程中的出色精确度,而 Replit 已成功部署 Claude 从头开始构建复杂的 Web 应用程序和仪表板,而其他模型则停滞不前。在 Canva 的评估中,Claude 始终如一地编写出具有卓越设计品味且可投入生产的代码,并大幅减少了错误。
Claude Code
智能编码让开发更便捷
自 2024 年 6 月以来,Sonnet 一直是全球开发者的首选模型。今天,Anthropic 推出了其首款智能编码工具 Claude Code(有限的研究预览版本),进一步增强开发者的能力。
在功能上,Claude Code 是一个积极的协作者,可以搜索和阅读代码、编辑文件、编写和运行测试、提交和推送代码到 GitHub,以及使用命令行工具。
我们来看下它的几个使用示例,比如解释项目结构:
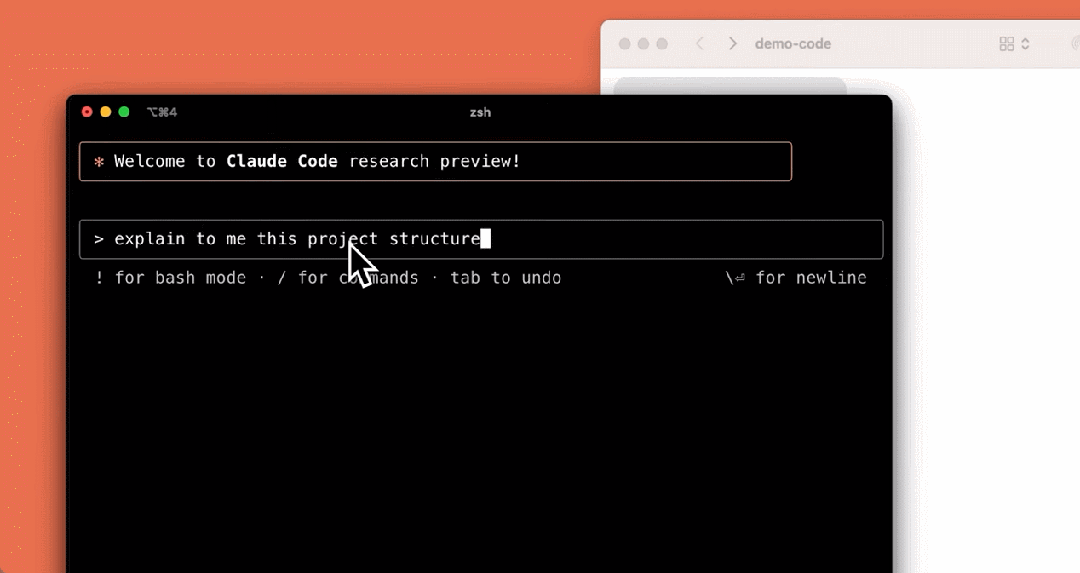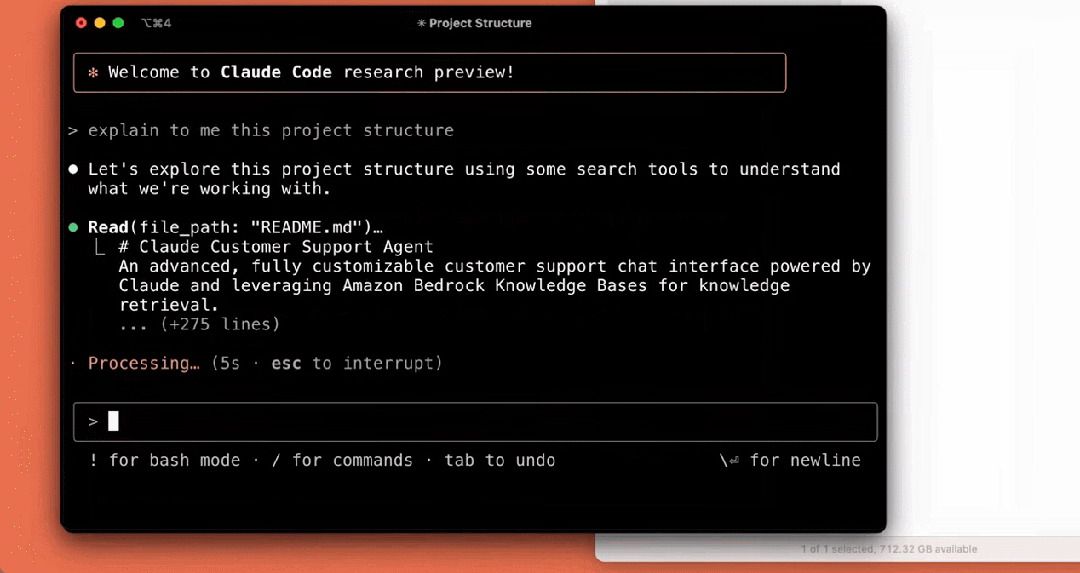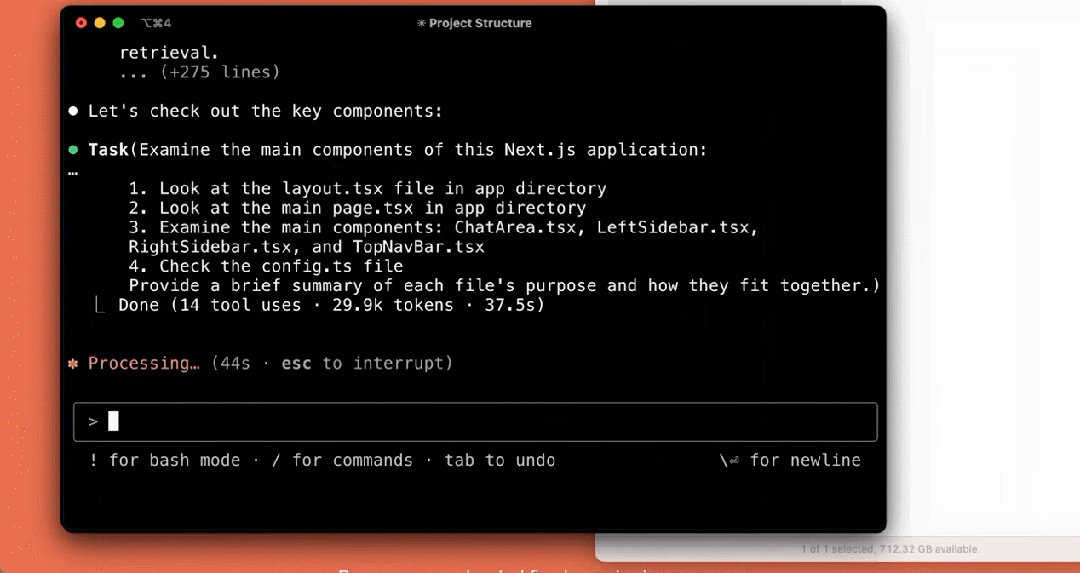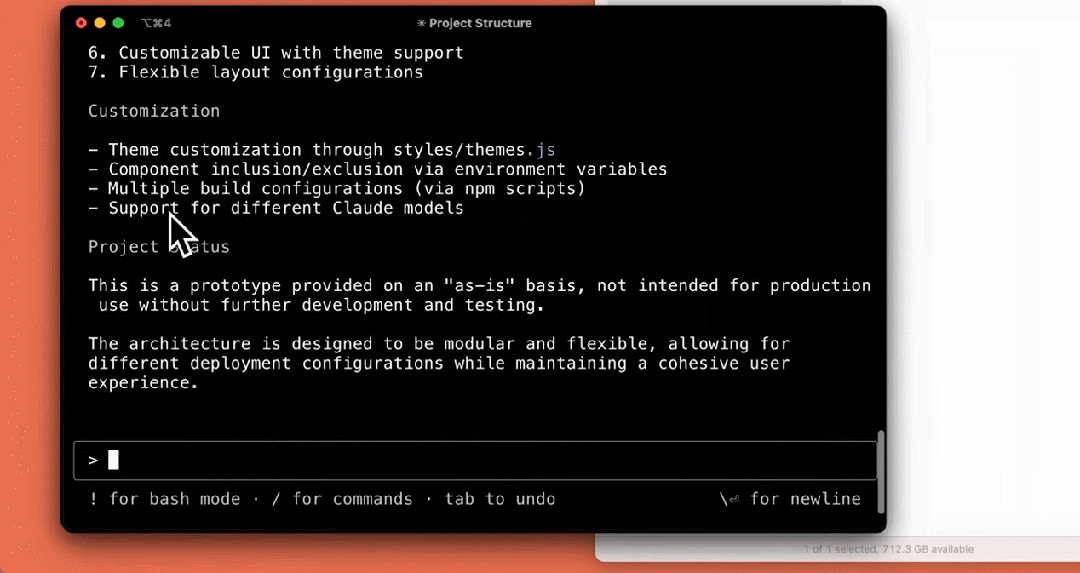
编写测试:

构建应用:
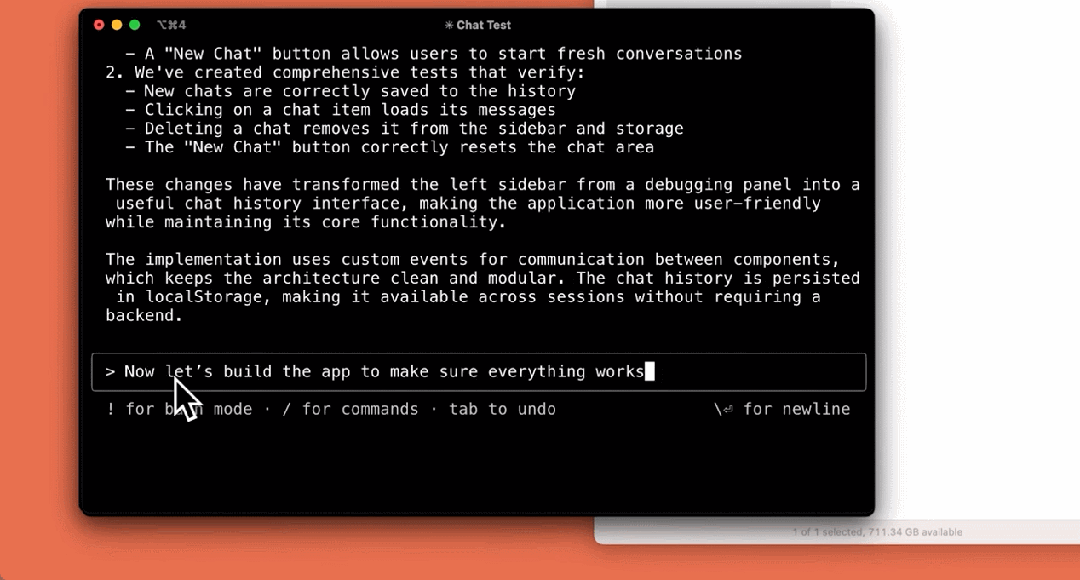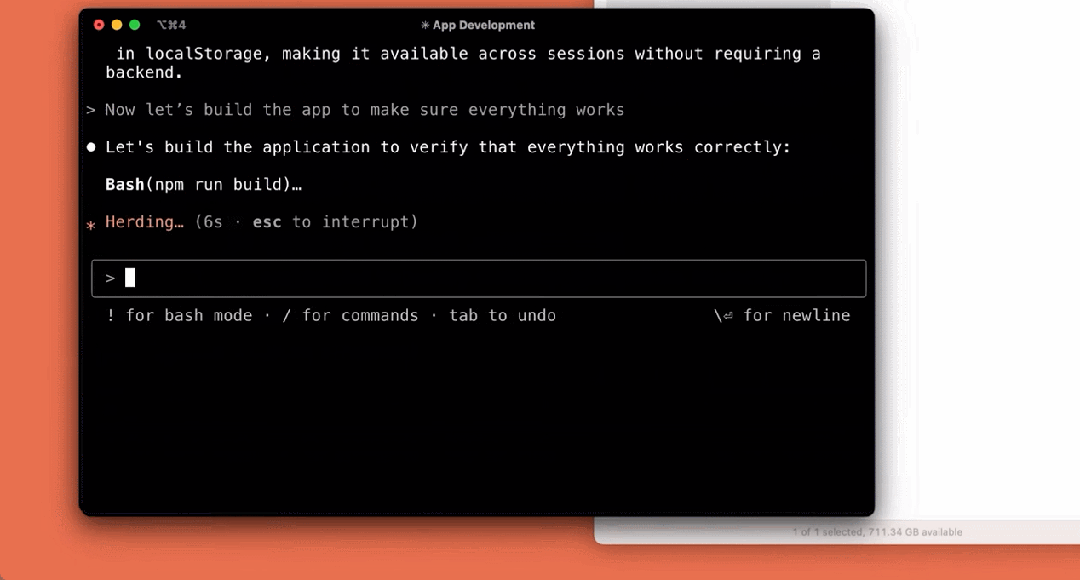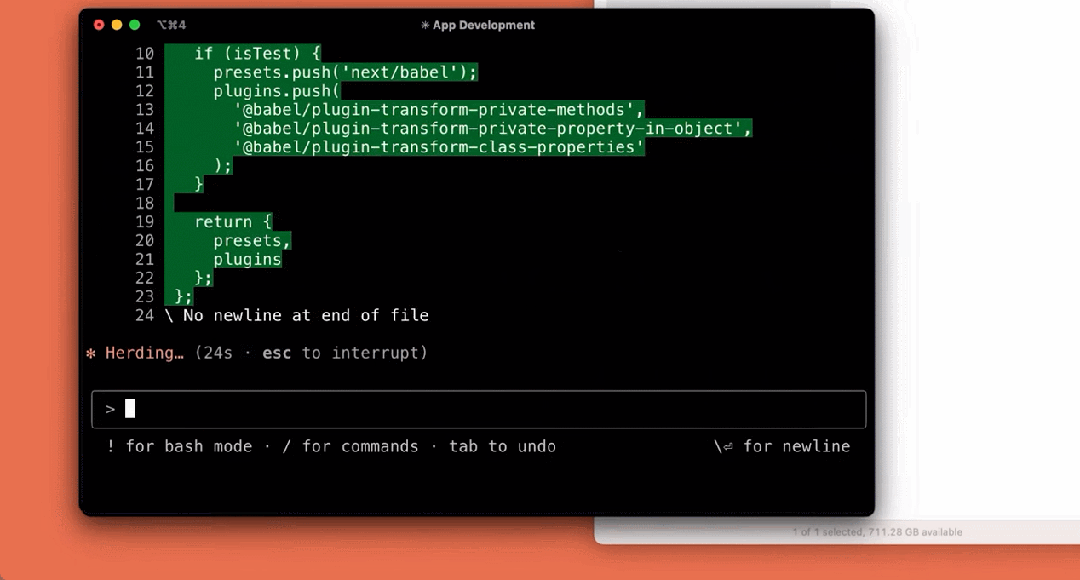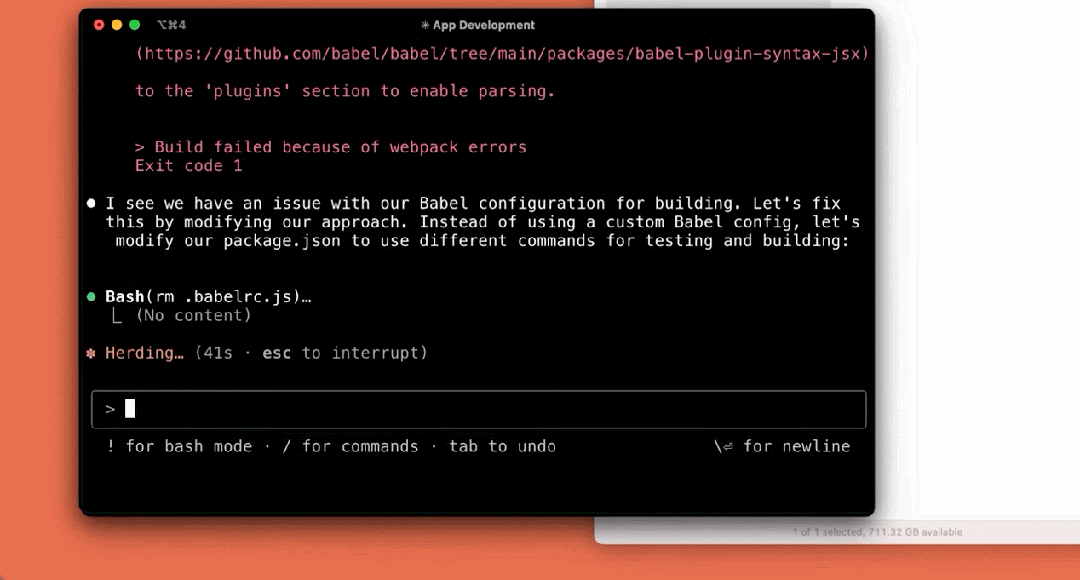
虽然是一款早期产品,Claude Code 对于 Anthropic 团队来说已经变得不可或缺,尤其是用于测试驱动开发、调试复杂问题和大规模重构。
在早期测试中,Claude Code 可以一次性完成通常需要 45 分钟以上手动工作才能完成的任务,从而减少了开发时间和开销。
在接下来的几周内,Anthropic 计划根据自身的使用情况不断改进 Claude Code,包括增强工具调用可靠性、增加对长时间运行命令的支持、改进应用内渲染以及扩展 Claude 对其功能的理解。
Claude Code 的目标是更好地了解开发人员如何使用 Claude 进行编码,以便为未来的模型改进提供参考。通过加入此预览版,用户将可以使用 Anthropic 用于构建和改进 Claude 的相同强大工具。
负责任构建与未来展望
Anthropic 对 Claude 3.7 Sonnet 进行了广泛的测试和评估,并与外部专家合作,以确保其符合其安全性和可靠性标准。
同时,Claude 3.7 Sonnet 还对有害请求和良性请求进行了更细微的区分。与前代相比,不必要的拒绝减少了 45%。

CoT 忠实度评估结果。
在 Claude 3.7 Sonnet 的模型卡中,Anthropic 详细细分了自身的负责任扩展策略评估以及其他 AI 实验室和研究人员应用于他们工作的情况。另外,模型卡中还概览了计算机使用带来的新风险,特别是快速注入攻击,并解释了 Anthropic 如何评估这些漏洞并训练 Claude 抵御和缓解这些漏洞。
此外,模型卡中还研究了推理模型的潜在安全优势,以及理解模型如何做出决策、模型推理是否真正值得信赖和可靠。

系统卡地址:https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf
对于此次发布的 Claude 3.7 Sonnet 和 Claude Code,Anthropic 认为它们标志着 AI 系统迈出了重要一步,开始向着真正增强人类能力迈进。凭借着深度推理、自主工作和有效协作的能力,我们更接近了 AI 丰富和扩展人类能力的未来。
Anthropic 还展示了一个真正令人兴奋的发展图景,希望在 2025 年 Claude 可以成为独立自主工作数小时的专家级智能体;到 2027 年,希望 Claude 能够解决人工团队花费数年才能解决的挑战性难题。

-
 C114通信网
C114通信网 -
 通信人家园
通信人家园
