


DeepSeek 越来越火爆,但与此同时,DeepSeek“服务繁忙”的状况不仅没有好转,还在进一步加剧。
据字母榜(ID:wujicaijing)实际测试,目前如果选择深度思考和联网搜索模式,DeepSeek会直接以弹窗形式发送一条“服务器繁忙,请稍后重试”的提醒,而不再像以往那样在对话框中给予回复。
因服务“繁忙”而无法使用DeepSeek的用户,也由此越来越多地外溢到了接入DeepSeek 的其他厂商平台上。
国内,阿里云、腾讯云、火山引擎、百度云等云厂商陆续宣布接入DeepSeek模型,三大运营商云也没放过接入DeepSeek的机会;国产AI芯片公司壁仞科技、海光信息、摩尔线程、沐曦等,也第一时间开始适配DeepSeek模型;兼具算力输出能力的大模型厂商,如科大讯飞,也开始将DeepSeek接入自家的开放平台;还有越来越多新能源汽车和智能手机厂商,正在赶往接入DeepSeek的路上。
堪称一夜爆红全球的DeepSeek,其所造成的流量奇观,无疑让上述一众厂商,都想从拥抱DeepSeek模型中吃到这波红利。
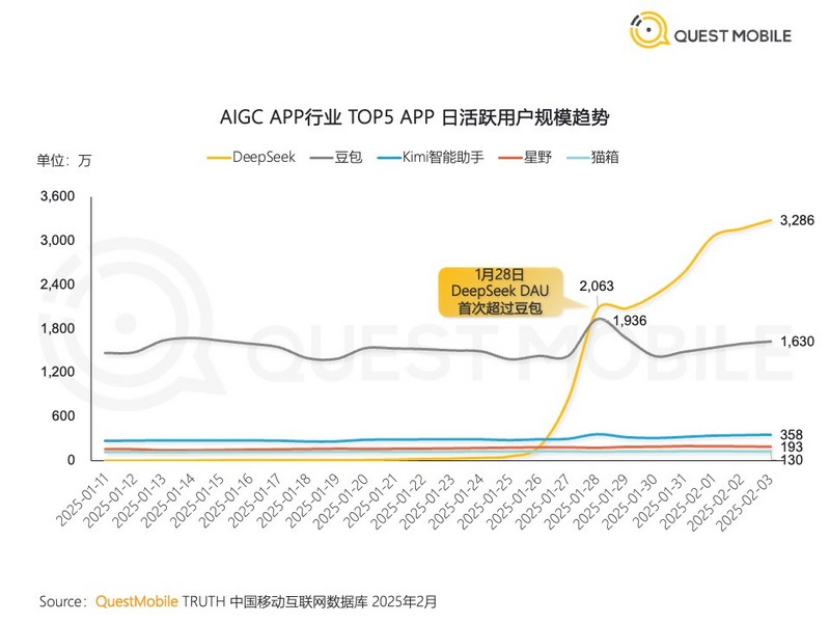
近期,QuestMobile给出的数据显示,DeepSeek日活跃用户(DAU)在1月28日首次超越豆包(约1695万),随后在2月1日突破3000万大关,成为国内DAU最高的AI 对话产品。做到这一切,DeepSeek只用了20天。
DeepSeek想要在短期内进一步扩张,除了找到一个算力合作伙伴支撑更大规模用户涌入之外,如果对方还能兼备C端、B端和G端的落地经验,无疑将是DeepSeek眼下最合适的盟友之一。
A
兼备C端、B端和G端落地经验的科大讯飞,成了接入DeepSeek的又一家AI厂商。
2月10日,科大讯飞宣布全面接入包括“满血版”DeepSeek-V3、DeepSeek-R1在内的DeepSeek全系大模型。不同于其他平台一般的API接入,目前科大讯飞是第一家推出DeepSeek大模型精调服务的平台。
精调,意味着在讯飞开放平台,开发者可以根据自身所在的行业领域场景,对DeepSeek进行行业数据训练,做完应用开发对接底层大模型的几乎所有流程。即使不对模型进行复杂修改,开发者也能以低成本的方式,快速定制自己的专属DeepSeek模型。

“精调是从能力到落地的必经之路,推出精调服务这个动作特别讯飞,他们非常知道AI应用落地需要什么。”有AI开发者向字母榜表示。
谁能服务好开发者,谁就有望在这场大模型之争中抢占先机,因为前者已经被视为当前大模型落地应用“最后一公里”的桥梁。
根据IDC发布的2024行研报告,科大讯飞在大模型开发者规模方面已处于国内第一。作为首批人工智能“国家队”,讯飞开放平台已聚集了超过812万开发者团队,大模型直接相关的开发者数量超过109.3万。领先的开发者生态,让讯飞在国内实现大模型的规模落地应用上成了最有力的竞争者。
事实上,AI落地一直是科大讯飞的长板,其落地应用广泛覆盖工业、教育、医疗、金融、智慧城市等众多行业。现在,有了当红炸子鸡DeepSeek的加持,科大讯飞在服务政企客户、外部开发者和C端消费者方面,都有了更多的施展空间。
通过接入DeepSeek,不论是央国企客户资源,还是那些曾经因成本高昂而犹豫是否采购大模型方案的中小企业,也开始在引入AI的态度上有所改变。首发的精调服务,让科大讯飞领先竞争对手,满足开发者与企业定制更懂需求场景的DeepSeek模型的需求,从而实现效果、效率与成本的均衡优化。
值得注意的是,目前DeepSeek尚未支持文生图和语音输入等多模态功能。在一众接入DeepSeek的AI厂商中,谁能提供DeepSeek尚不具备的多模态能力,谁无疑就将吸引到更多开发者和普通用户的青睐,从而提前一步构建起更丰富的大模型生态。
截至目前,科大讯飞独立自研的讯飞星火APP,在支持常规的文字输入之外,还支持图片生成、语音交互等多模态能力。仅仅在过去一年,讯飞星火就完成了五次迭代升级,其最新模型讯飞星火4.0 Turbo,在七大能力上超过GPT-4 Turbo,代码能力和数学能力超越 GPT-4o。
整合DepSeek开源模型与讯飞已有优势技术,科大讯飞不仅有望构建具备多模态能力的全新版本DeepSeek,激活全新的竞争优势,而且也将是在DeepSeek红利之下的新利好因素。
B
在低成本大模型训练策略被DeepSeek验证成功后,外界一度担忧算力需求是否会遭遇暴跌。但包括微软在内的科技大厂依然保持乐观。
微软CEO纳德拉在DeepSeek R1发布后说道,“杰文斯悖论再次应验!随着AI变得更高效、更容易获取,它的使用量将火箭般蹿升,成为我们用不够的商品。”
在经济学领域,杰文斯悖论指的是当技术进步提高了效率,资源消耗不仅没有减少,反而激增。
具体到大模型赛道,纳德拉所谓的AI需求使用量激增,即将通过B端、G端的政企客户开发和AI应用的爆发来共同完成,这一趋势也是DeepSeek爆火之后行业形成的两大新共识。
既要有底座大模型的研发能力,又要兼备大众市场和政企市场的落地经验,能够集齐这些标签的大模型厂商,眼下唯有AI大厂。
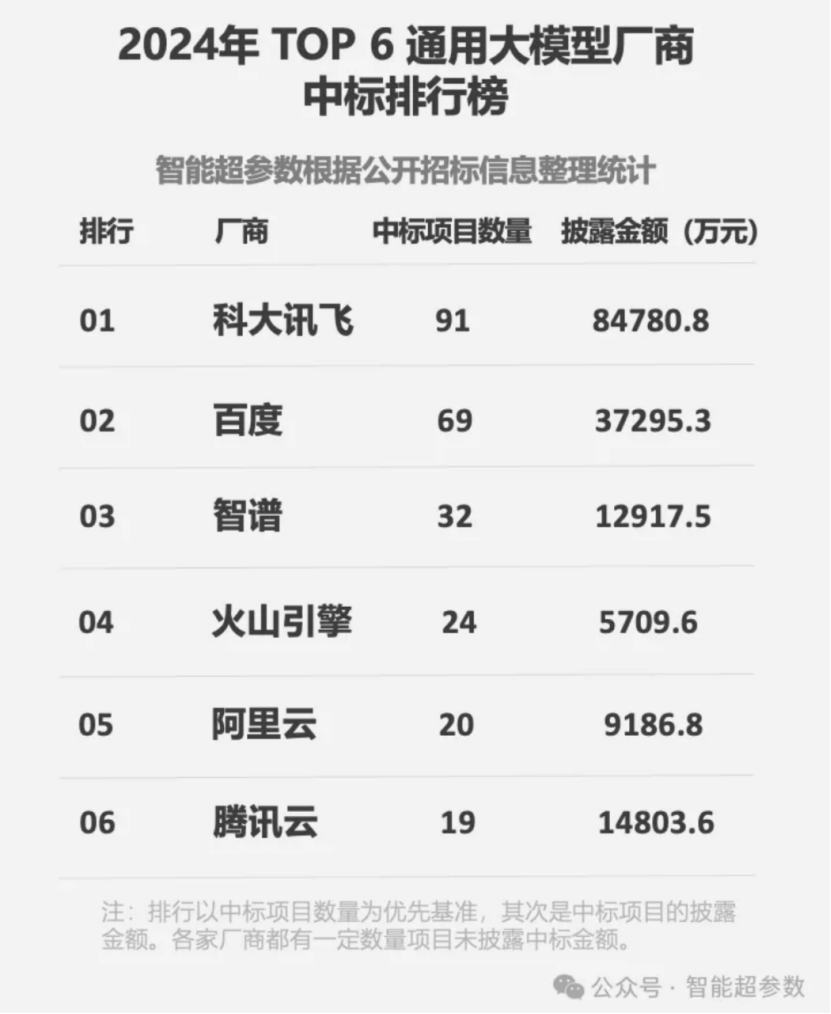
招投标市场的公开信息也佐证着这一点。根据第三方机构智能超参数最新发布的《中国大模型中标项目监测报告(2024)》,2024 年,在通用大模型厂商中标排行榜中,前五名几乎全部来自AI大厂。其中,科大讯飞更是以91个中标项目、披露中标金额84780.8万元排名第一,成为2024年度标王。
政企市场快速发展的一大行业背景在于,经过两年发展的国内大模型领域,正在转换出一套新的评判标准:对大模型厂商的综合实力打分,不再仅仅围绕它出了多少论文、刷了多少排行榜,更加开始看重它是否能获得规模化收入,何时能摸到盈利的门槛。
拿下大模型领域政企合作客户标王的科大讯飞,有望摸着DeepSeek进一步扩张。
DeepSeek的低成本策略,使得政企客户在部署大模型中的成本忧虑开始减弱,从而有利于推动大模型在政企市场的新增长。
如今,在AI大厂们相继接入DeepSeek模型,站上同一起跑线后,比拼的核心因素再次回到了科大讯飞的优势区,即模型的性能强弱和对客户的服务能力。
负责讯飞星火政企业务的王刚曾谈过两大阻碍政企客户选择大模型的因素,“一个是场景,一个是数据。”其中,数据指向如何对行业客户的海量原始数据进行语料清理、收集,场景则考验着大模型企业对细分行业的理解程度。
为此,科大讯飞总结了一整套可复制的方法论,构建起从“建算力、理数据、训模型”,到“落场景、保安全、精运营”的全套解决方案。
“为什么我们中标数量第一,而且中标比例越来越高?因为很多企业只能做到第三步即训练模型,后面的几步与我们差距很大,即使能做到,他们实际上整理数据和训练模型的能力,与我们差距也很大。”科大讯飞创始人刘庆峰进一步解释道。
C
对于仍在冲击AGI(通用人工智能)的大模型玩家而言,资金和信心之外,受限于政策风险,高端算力芯片对大模型的技术迭代影响正无限放大。
DeepSeek创始人梁文锋就曾在接受36氪采访时提到,DeepSeek面临的主要制约因素不是资金,而是高端算力的使用权,这些芯片对于训练先进AI模型至关重要。
从2023年10月开始,英伟达因为美国商务部的要求,不再对中国售卖最新最强的高端算力芯片,转而推出仅供中国市场的阉割版芯片。
但随着近期DeepSeek的崛起,即便是这些阉割版芯片,也将再次面临被美国封禁的危险。
Scale AI创始人亚历山大·王(Alexandr Wang)在点评DeepSeek时谈到,“他们将受到芯片控制和出口管制的限制。”
来自美国另一家AI初创巨头Anthropic创始人达里奥·阿莫迪 (Dario Amodei)的声明,则将硅谷对DeepSeek的担忧进一步放大。
在阿莫迪于1月底发布的万字长文中,其认为DeepSeek的突破,更加印证了美国对华芯片出口管制政策的必要性和紧迫性。

在他看来,最快到2026或者2027年,人类就将制造出在几乎所有事情上,都比几乎所有人类更智能的人工智能,前提是需要至少投入数百万块芯片和数百亿美元。
“有效执行的出口管制是唯一能够阻止中国获得数百万块芯片的手段。”这也是阿莫迪认为阻止中国在AI大模型领域赶超美国的最重要决定因素。
硅谷的态度,无疑让国产算力替代方案,正从备选项,逐渐向必选项过渡。这方面,科大讯飞率先摸着石头过河。
2023年,科大讯飞便联合华为做了第一个全国产万卡算力集群“飞星一号”,在昇腾910B的基础上,使得大模型训练从对标A100/A800的20%-30%提升到了90%以上,讯飞星火也由此成为中国第一个基于国产算力训练出来的全民开放的大模型。
为了追逐AGI,科大讯飞还在布局更大的国产算力集群。去年10月,科大讯飞再度联手华为、合肥市大数据资产运营有限公司,打造了国产超大规模智算平台“飞星二号”。刘庆峰曾说,“到底有没有自主可控的国产底座能力做支撑,这决定了我们在这条路上到底能走多远。”
开放平台、政企端落地、国产算力适配经验成为科大讯飞承接DeepSeek流量外溢的三大抓手,在众多大模型厂商中,也许讯飞最有机会被DeepSeek“带飞”。
