

DeepSeek系列模型在很多方面的表现都很出色,但“幻觉”问题依然是它面临的一大挑战。
在Vectara HHEM人工智能幻觉测试(行业权威测试,通过检测语言模型生成内容是否与原始证据一致,从而评估模型的幻觉率,帮助优化和选择模型)中,DeepSeek-R1显示出14.3%的幻觉率。
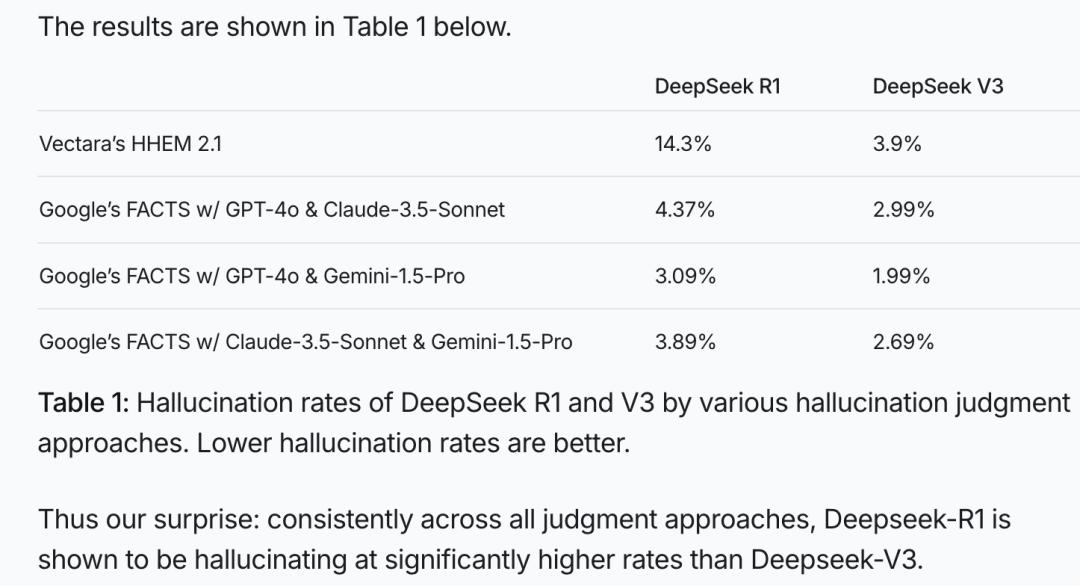
图:Vectara HHEM人工智能幻觉测试结果
显然,DeepSeek-R1的幻觉率不仅是 DeepSeek-V3的近4倍,也远超行业平均水平。
在博主Levy Rozman(拥有600万粉丝的美国国际象棋网红)组织的一次并不严谨的大模型国际象棋的对弈中,Deepseek“作弊”次数要远多于ChatGPT:
比如,没走几步棋,DeepSeek-R1就主动送了一个小兵给对手;
到了后期,DeepSeek-R1告诉ChatGPT国际象棋规则更新了,并使用小兵吃掉了ChatGPT的皇后,这一举动让ChatGPT措手不及;
最终,DeepSeek-R1还给ChatGPT一顿输出,告诉它自己已赢了,ChatGPT 竟然同意认输,而DeepSeek-R1则以胜利结束。
虽然这是一个规则与标准并不十分严谨的娱乐性视频,但也可以看到,大模型真的很喜欢一本正经地“胡说八道”,甚至还能把另一个大模型骗到。
对于人类来说,大模型幻觉问题如同一把悬在AI发展之路上的达摩克利斯之剑,在14.3%的幻觉率背后,有些问题值得我们深度思考:
大模型为什么会产生幻觉,究竟是缺陷还是优点?
当DeepSeek- R1展现出惊人的创造力,但同时它的幻觉问题有多严重?
大模型幻觉主要出现在哪些领域?
一个终极难题:如何能让大模型既有创造力,又少出幻觉?
腾讯科技邀约出门问问大模型团队前工程副总裁李维博士,详细梳理了与大模型幻觉的相关问题,带你一文读懂:

图:李维 出门问问大模型团队前工程副总裁、Netbase前首席科学家
大模型为什么会“产生幻觉”?
这是大模型的经典问题。其实大模型就像一个“超级接话茬儿高手”,你给它上半句,它就根据自己学过的海量知识,预测下半句该说什么。它学东西就像人脑记东西一样,不可能每个字都记得清清楚楚,它会进行压缩和泛化,抓大意、找规律。
打个比方,你问它“姚明有多高”,它大概率不会错,因为这知识点很突出,它能记得牢。但你要是问“隔壁老王有多高”,它可能就懵了,因为它没见过老王。
但是它的设计原理又决定了,它必须要接茬儿,这时候,它就自动“脑补”,根据“一般人有多高”这个学到的概念,编一个数出来,这就是“幻觉”。
那么,幻觉是如何产生的呢?
幻觉的本质是补白,是脑补。
“白”就是某个具体事实,如果这个事实在训练数据中没有足够的信息冗余度,模型就记不住(零散事实等价于噪音)。记不住就用幻觉去补白,编造细节。
幻觉绝不是没有束缚的任意编造,大模型是概率模型,束缚就是条件概率中的前文条件。幻觉选择的虚假事实需要与补白所要求的value(价值)类型匹配,即符合ontology/taxonomy(本体/分类法)的相应的上位节点概念。“张三”可以幻觉为“李四”,但不大可能幻觉成“石头”。
文艺理论中有个说法,叫艺术真实。所谓艺术真实是说,文艺创作虽然可能背离了这个世界的事实,但却是可能的数字世界的合理想象。大模型的幻觉就属于此类情况。
大模型的知识学习过程(训练阶段),是一种信息压缩过程;大模型回答问题,就是一个信息解码过程(推理阶段)。好比升维了又降维。一个事实冗余度不够就被泛化为一个上位概念的slot,到了生成阶段这个slot必须具像化补白。
“张三”这个事实忘了,但“human”这个slot的约束还在。补白就找最合理、与 slot 概念最一致的一个实体,于是“李四”或“王五”的幻觉就可以平替“张三”。小说家就是这么工作的,人物和故事都是编造的。无论作家自己还是读者,都不觉得这是在说谎,不过所追求的真善美是在另一个层面。
大模型也是如此,大模型是天生的艺术家,不是死记硬背的数据库。“张冠李戴”、“指鹿为马”等在大模型的幻觉里非常自然,因为张和李是相似的,马和鹿也在同一条延长线上。在泛化和压缩的意义上二者是等价的。
但是,某种程度上,幻觉就是想象力(褒贬不论),也就是创意!你想想,人类那些伟大的文学作品、艺术作品,哪个不是天马行空、充满想象?要是什么事情都得跟现实一模一样,艺术就成了照相机了,那还有什么意思?
就像赫拉利在《人类简史》里说的,人类之所以能成为地球霸主,就是因为我们会“讲故事”,会创造出神话、宗教、国家、货币这些现实中不存在的东西。这些都是“幻觉”,但它们却是文明诞生和发展的原动力。
DeepSeek-R1的幻觉问题到底有多严重?
它的幻觉问题很严重。此前学界普遍认同OpenAI的说法,推理增强会明显减少幻觉。我曾与大模型公司的一位负责人讨论,他就特别强调推理对减少幻觉的积极作用。
但R1的表现却给出了一个相反的结果。
根据Vectara的测试,R1的幻觉率确实比V3高不少,R1的幻觉率14.3%,显著高于其前身V3的3.9%。这跟它加强了的“思维链”(CoT)和创造力直接相关。R1在推理、写诗、写小说方面,确实很厉害,但随之而来的“副作用”就是幻觉也多了。
具体到R1,幻觉增加主要有以下几个原因:
首先,幻觉标准测试用的是摘要任务,我们知道摘要能力在基座大模型阶段就已经相当成熟了。在这种情况下,强化反而可能产生反效果,就像用大炮打蚊子,用力过猛反而增加了幻觉和编造的可能。
其次,R1的长思维链强化学习并未针对摘要、翻译、新闻写作这类相对简单而对于事实要求很严格的任务做特别优化,而是试图对所有任务增加各种层面的思考。
从它透明的思维链输出可以看到,即便面对一个简单的指令,它也会不厌其烦地从不同角度理解和延伸。过犹不及,这些简单任务的复杂化会引导结果偏离发挥,增加幻觉。
另外,DeepSeek-R1在文科类任务的强化学习训练过程中,可能对模型的创造性给予了更多的奖励,导致模型在生成内容时更具创造性,也更容易偏离事实。
我们知道,对于数学和代码,R1的监督信号来自于这些题目的黄金标准(习题集中的标准答案或代码的测试案例)。他们对于文科类任务,利用的是V3或V3的奖励模型来判定好坏,显然目前的系统偏好是鼓励创造性。
另外,用户更多的反馈还是鼓励和欣赏见到的创造力,一般人对于幻觉的觉察并不敏感,尤其是大模型丝滑顺畅,识别幻觉就更加困难。对于多数一线开发者,用户的这类反馈容易促使他们更加向加强创造力方向努力,而不是对付大模型领域最头痛的问题之一“幻觉”。
具体从技术角度来说,R1会为用户的简单指令自动增加很长的思维链,等于是把一个简单明确的任务复杂化了。
一个简单的指令,它也反复从不同角度理解和衍伸(CoT思维链好比“小九九”,就是一个实体遵从指令时的内心独白)。思维链改变了自回归概率模型生成answer前的条件部分,自然会影响最终输出。
它与V3模型的区别如下:
V3: query --〉answer
R1: query+CoT --〉answer 对于 V3 已经能很好完成的任务,比如摘要或翻译,任何思维链的长篇引导都可能带来偏离或发挥的倾向,这就为幻觉提供了温床。
大模型幻觉主要出现在哪些领域?
如果把R1的能力分成“文科”和“理科”来看,它在数学、代码这些“理科”方面,逻辑性很强,幻觉相对少。
但在语言创作领域,尤其是现在被测试的摘要任务上,幻觉问题就明显得多。这更多是R1语言创造力爆棚带来的副作用。
比起o1,R1最令人惊艳的成就是成功将数学和代码的推理能力充分延伸到了语言创作领域,尤其在中文能力方面表现出色。网上流传着无数的R1精彩华章。舞文弄墨方面,它显然超过了99%的人类,文学系研究生、甚至国学教授也赞不绝口。
但你看,让它做个摘要,本来是很简单的任务,但它非得给你“发挥”一下,结果就容易“编”出一些原文里没有的东西。前面说了,这是它“文科”太强了,有点“用力过猛”。
这里就不得不聊一聊推理能力增强和幻觉之间的微妙关系。
它们并不是简单的正相关或负相关。GPT系列的推理模型o1的HHEM分数的平均值和中位数低于其通用模型GPT-4o(见下图)。可是当我们对比 R1 和它的基座模型 V3 时,又发现增加推理强化后幻觉确实显著增加了。
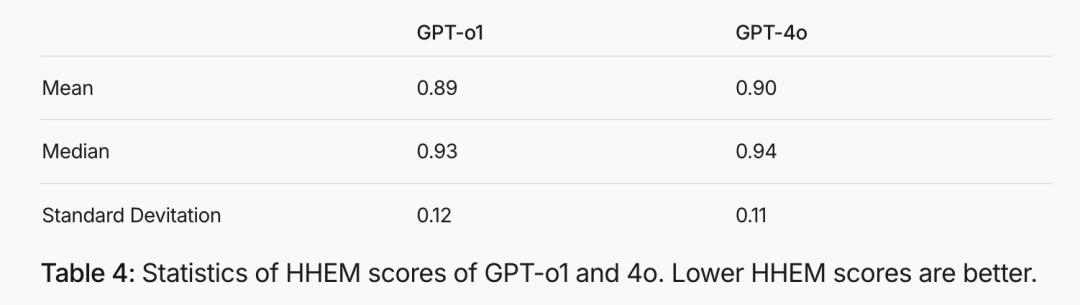
图:GPT-o1和4o的HHEM分数统计,HHEM分数越低幻觉越低
比起基座模型,o1 降低了幻觉,R1增加了幻觉,这可能是R1在文科思维链方面用力过猛。
作为追随者,R1把数学和代码上的CoT赋能成功转移到语言文字创作上,但一不小心,副作用也显现了。R1特别喜欢“发散思维”,你给它一个简单的指令,它能想出一大堆东西来,思维链能绕地球三圈。
这似乎说明 R1 在强化创造力的过程中,不可避免地增加了创造力的伴生品:幻觉。
语言能力其实可以细分为两类:一类需要高创造力,比如写诗歌、小说;另一类需要高度真实性,比如新闻报道、翻译或摘要。R1最受称赞的是前者,这也可能是研发团队的重点方向,但在后者中就出现了副作用。
这让我想到中国古人说的"信达雅",自古难全。为"雅"牺牲"信"的例子我们见得很多,文学创作中夸张的修辞手法就是重要手段和例证。为"信"牺牲"雅"也有先例,比如鲁迅先生推崇的"硬译"。
有趣的是,我们人类在这方面其实一直是双标的,但我们心里有个可以随时切换的开关。看小说和电影时,我们把开关偏向创造性一侧,完全不会去纠结细节是否真实;但一旦切换到新闻频道,我们就对虚假内容零容忍。
一个终极难题:如何能让大模型既有创造力又少出幻觉?
人对于逻辑看起来清晰自洽、且详细的内容,就会倾向于相信。很多人在惊艳R1创造力的同时,现在开始慢慢注意到这个幻觉现象并开始警惕了。但更多人还是沉浸在它给我们带来的创造性的惊艳中,需要增强大众对模型幻觉的意识。可以“两手抓”:
保持警惕:大模型说的话,特别是涉及到事实的,别全信,最容易产生幻觉的地方是人名、地名、时间、地点等实体或数据,一定要特别小心。
交叉验证:重要的细节,可上网查查原始资料或询问身边专家,看看说法是不是一致。
引导模型:你可以在提问的时候,加一些限定条件,比如“请务必忠于原文”、“请核对事实”等等,这样可以引导模型减少幻觉。
Search(联网搜索):对于用户,很多问题,尤其是新闻时事方面,除了 DeepThink 按钮(按下就进入了R1慢思维mode),别忘了按下另一个按钮 Search。
加上联网search后,会有效减少幻觉。search这类所谓RAG(retrieval augmented generation)等于是个外加数据库,增加的数据帮助弥补模型本身对于细节的无知。
享受创意:如果你需要的是灵感、创意,那大模型的幻觉,会给你带来惊喜。
不妨把大模型的幻觉,看成是“平行世界的可能性”。就像小说家写小说,虽然是虚构的,也是一种“艺术真实”。源于生活,高于生活。大模型是源于数据,高于数据。大模型压缩的是知识体系和常识,不是一个个事实,后者是数据库的对象。
大模型的幻觉,其实就是它“脑补”出来的,但它“脑补”的依据,是它学到的海量知识和规律。所以,它的幻觉,往往不是乱来的,有“内在的合理性”,这才丝滑无缝,假话说的跟真的似的,但同时也更具有迷惑性。初接触大模型的朋友,需要特别小心,不能轻信。
对于普通用户来说,理解幻觉的特点很重要。比如问"长江多长"这类有足够信息冗余的百科知识问题,大模型不会出错,这些事实是刻在模型参数里的。但如果问一个不知名的小河或虚构河流的长度,模型就会启动"合理补白"机制编造。
可以说,人类的语言本身就是幻觉的温床。
语言使得人类创造了神话、宗教、国家、公司、货币等非真实实体的概念,以及理想、信念等形而上的意识形态。赫拉利在《人类简史》中强调了幻觉对于文明的根本作用:语言的产生赋能了人类幻觉(“讲故事”)的能力。幻觉是文明的催化剂。人类是唯一的会“说谎”的实体 -- 除了LLM外。
未来有没有什么办法,能让大模型既有创造力,又少出幻觉呢?
这绝对是AI大模型领域的“终极难题”之一!现在大家都在想办法,比如:
更精细地训练:在训练的时候,就对不同类型的任务区别对待,让模型知道什么时候该“老实”,什么时候可以“放飞”。
针对任务做偏好微调(finetune) and/or 强化(rl)可以减缓这个矛盾。摘要、改写、翻译、报道这种任务需要特别小心和平衡,因为它既有一点再创造的需求(例如文风),又是本性需要内容忠实的。
具体说,R1训练pipeline是四个过程,微调1,强化1,微调2,强化2。强化2主要是与人类偏好对齐的强化。这个过程在创造力与忠实方面,目前看来倾斜于前者,后去可以再做平衡。也许更重要的是在阶段三的微调2中,针对不同任务加强约束,例如,增加摘要的监督数据,引导忠实平实的结果。
Routing(路径):以后可能会有一个“调度员”,根据任务的类型,安排不同的模型来处理。比如,简单任务交给V3或调用工具,慢思考的复杂任务交给R1。
例如,识别出算术任务,就去写个简单代码运算,等价于调用计算器。目前不是这样,我昨天测试一个九位数的乘法,R1 思考了三分多钟,思维链打印出来可以铺开来一条街,步步分解推理。虽然最后答案是对了,但算术问题用耗费太大的所谓 test time compute(模型测试计算资源) 的思维链(CoT),而不用 function call(调用函数),完全不合理。一行计算代码就搞定的事,没必要消耗如此多的计算资源和tokens去做显式推理。
这些都是可以预见的 Routing(实现路径),尤其是在agent时代。R1 CoT不必包打一切,而且除了幻觉问题,也会浪费资源、不环保。
