


【导读】刚刚,Meta重磅发布了VideoJAM,在运功连贯性上刷新SOTA,Sora完全被按在地上摩擦。
我们都知道,几乎所有视频模型都有一个老大难:无法正确生成运动。
原因就在于,AI视频的训练目标更偏向外观,而非动态表现。
就在刚刚,来自Meta和特拉维夫大学的研究人员发布了一个用于改进运动生成的全新框架——VideoJAM。

论文地址:https://arxiv.org/pdf/2502.02492
这个新框架,直接攻克了这个传统难题,无需任何额外数据或scaling。
结果显示,它生成的视频已通过体操图灵测试,结果碾压Sora!
左边Sora生成的这个怪异的体操动作,直接被VideoJAM吊打。

Sora生成的男子抛球的视频,可谓是爆笑如雷了;而VideoJAM生成的效果,真实又自然,完全符合物理规律。

从Sora生成的转呼啦圈动作看,它完全没理解这项运动的原理,而VideoJAM已经手拿把掐。

AI视频为何难以捕捉现实动作
为什么视频生成模型在处理运动方面如此困难?现实世界的运动、动态和物理现象,它们经常难以捕捉。
Meta的研究团队发现,当视频帧被打乱时,基于像素的损失几乎不变,这表明,它几乎「对时间不一致性保持不变」。
也就是说,这种局限性源于传统的像素重建目标,它会使模型过度关注外观保真度,而忽视了运动的连贯性。

Meta的解决方案,就是VideoJAM。
它通过修改目标函数,来引入显式的运动先验:模型从单一的学习表征中同时预测外观和运动。
这种方法,就能迫使模型同时捕捉视觉信息和动态变化,从而提升对运动的理解能力。
具体来说,VideoJAM通过鼓励模型学习外观与运动的联合表征,为视频生成器注入有效的运动预测。
VideoJAM由两个互补的模块组成。
在训练阶段,研究人员将目标扩展为基于单一的学习表征,同时预测生成的像素及其对应的运动。
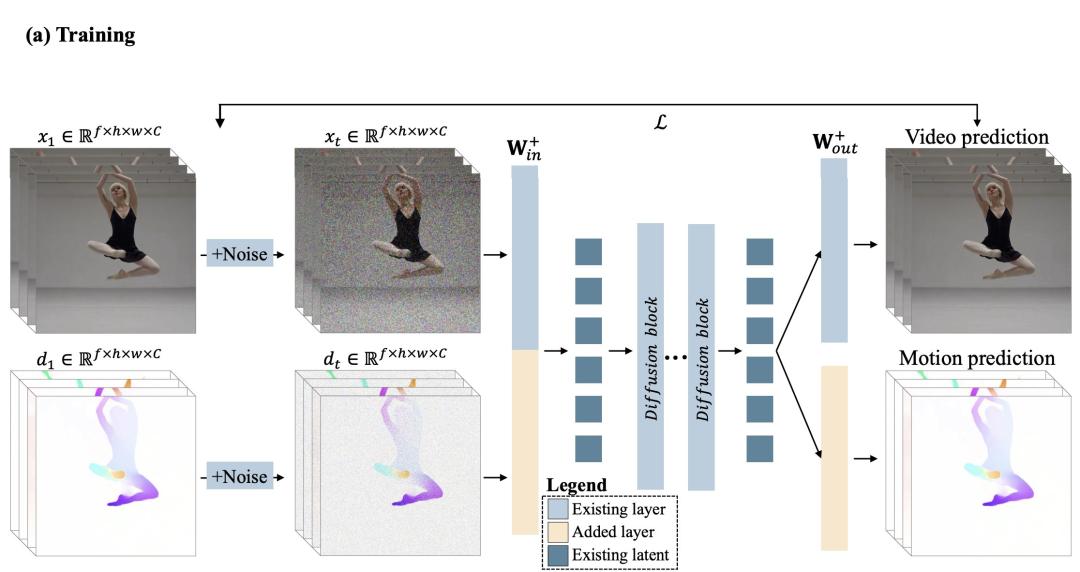
在推理阶段,他们引入了「Inner-Guidance」机制,通过利用模型自身不断演化的运动预测作为动态引导信号,引导生成连贯、逼真的动作。
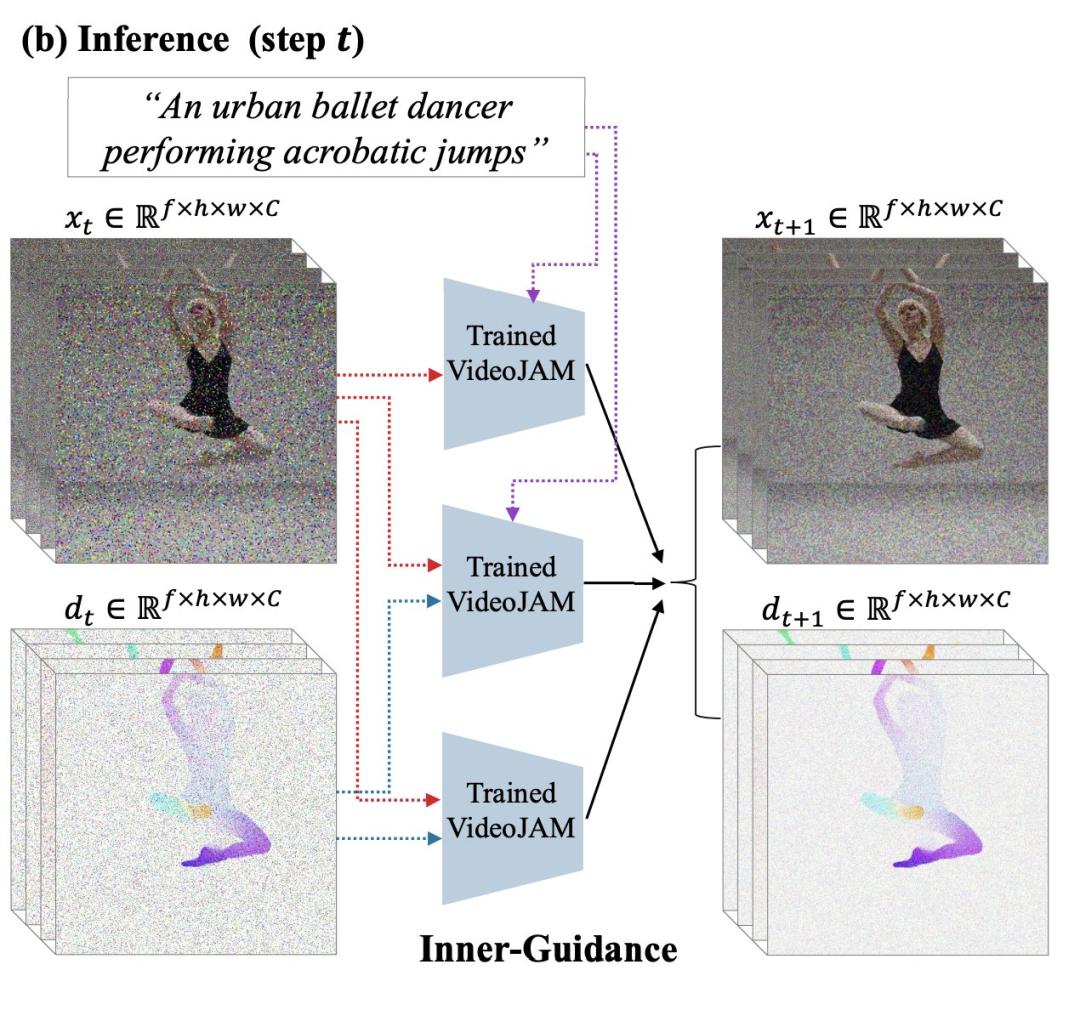
值得注意的是,VideoJAM框架几乎无需额外改动即可应用于任何视频模型,无需修改训练数据或扩大模型规模。
结果令人惊喜!
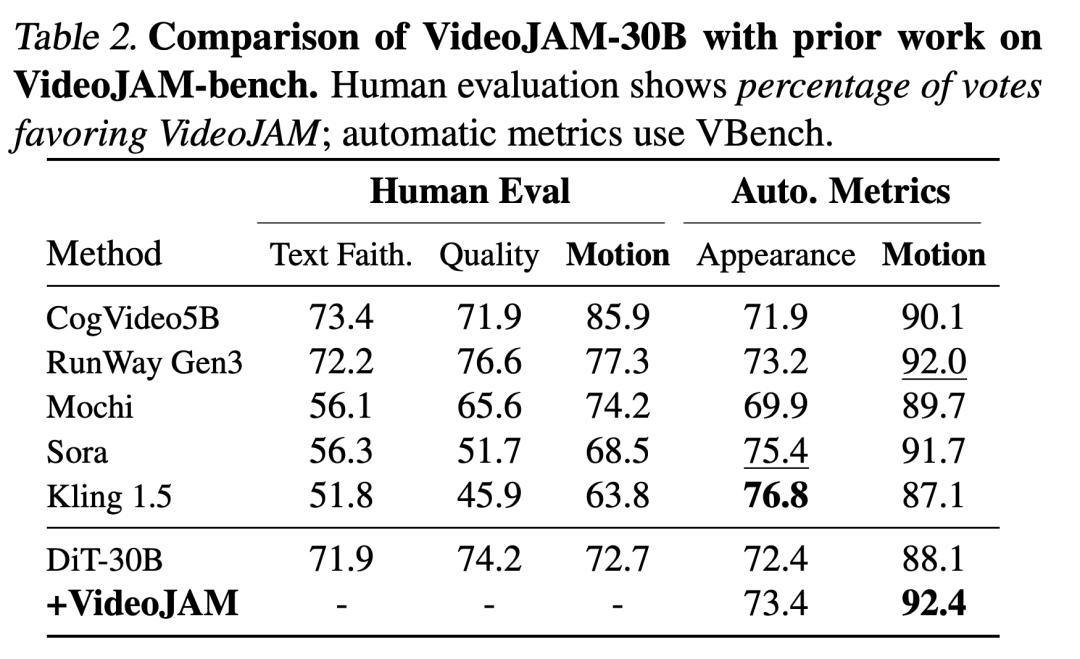
VideoJAM在仅使用其自身训练集中的300万个样本对预训练视频生成模型(DiT)进行微调后,仍实现了卓越的运动连贯性。
在运动连贯性方面,它已经达到了SOTA;在运动质量上,它甚至超越了Sora等专有模型。
Meta团队的研究结果表明,外观与运动之间并非对立,而是相辅相成;当二者得到有效融合时,能够同时提升视频生成的视觉质量与运动连贯性。
复杂运动无比真实
以下视频由VideoJAM-30B在高难度提示(需生成复杂运动类型)下生成的结果。
「一位滑板运动员进行跳跃。」
可以看出运动员与滑板在空中的动作结合的十分协调,甚至在踏上滑板时,滑板还有轻微的震动,可谓是十分真实了。

「手指压进一个闪烁的粘液球。」
视频清晰展现了手指与粘液球的粘连状态,生动体现了其粘性。

「一位花样滑冰运动员完成了一个有力的跳跃,她的金色服装闪闪发光。」
视频中可以看出运动员在空中的旋转十分协调,在快速移动中还生成了模糊的效果。

「一只山羊在山顶一个旋转的球上保持平衡。」
视频中的山羊努力在球上保持平衡,其动作也符合物理法则。

「慢动作特写,厨师切番茄。」
视频中对手指的处理没有明显瑕疵,实属不易。切下的西红柿之间也有着自然的差异。

「一个男孩在生日蛋糕上吹蜡烛。」
下面这个视频需要模型理解小男孩吹气与蜡烛火苗间的逻辑关系。VideoJAM-30B显然处理得还不错。

「一个花瓶在安静的古董店木地板上摔碎。」
这种碎裂的场景十分考验模型对细节的处理,VideoJAM-30B看来也不在话下。

视频AI大PK
接下来,为了证明VideoJAM具备最优的运动连贯性,研究人员进行了定性和定量实验。(从左到右为Runway Gen3、Sora、DiT和VideoJAM)
定性实验
定性评估涵盖了多种运动类型,是当前AI视频模型面临的挑战难题,比如体操动作(空中劈叉、跳跃)、需要物理理解的情境(手指按压黏液、篮球落入篮网)等等。
如下比较中,直观地展现出当前领先AI视频模型的局限性。
即使是简单的运动,例如长颈鹿奔跑,也会出现问题,例如「反向运动」(Sora)或不自然的动作(DiT-30B)。
更复杂的运动,如引体向上或头倒立,会导致视频静态不变,或有的出现身体变形。基线模型甚至还会违背物理规律,比如物体消失或突然出现。
相比之下,VideoJAM始终能够生成连贯的运动。







不过,在下面这组「转动的指尖陀螺」中,所有模型都无法正确地遵循物理学定律。

更进一步的,研究团队还展示了VideoJAM与DiT-30B在同等条件下的定性比较。
「一位芭蕾舞者在黎明时分在草地上优雅地旋转,他们的动作柔和流畅,如同晨风。」
可以看出,对比基础模型DiT-30B,微调后的VideoJAM生成的视频主体人物更大、明暗对比更加强烈。

「运动员在雨中奔跑的特写,他们的鞋子在积水中溅起水花,坚定地向前推进。」
下图中,同样VideoJAM生成的视频中主体更大,同时跑步姿势也显得更加自然一些。

「一只狗跳过木栅栏。慢动作。」
下图中DiT-30B(左)生成的视频中狗在空中直接穿过了栏杆,而VideoJAM则没有出现这种问题。

「特写镜头,寿司师傅用故意、流畅的动作切生鱼片。」
下图中VideoJAM生成的视频中主体离镜头更近,而DiT-30B生成的视频中,厨师根本就没有切到寿司。

「女性在公园日落时,围绕腰部旋转呼啦圈。」
下面这个对比视频同样可以看出,VideoJAM生成的视频中女人旋转呼啦圈明显更加真实,而DiT-30B生成的视频中的女人则同呼啦圈一同旋转。

定量实验
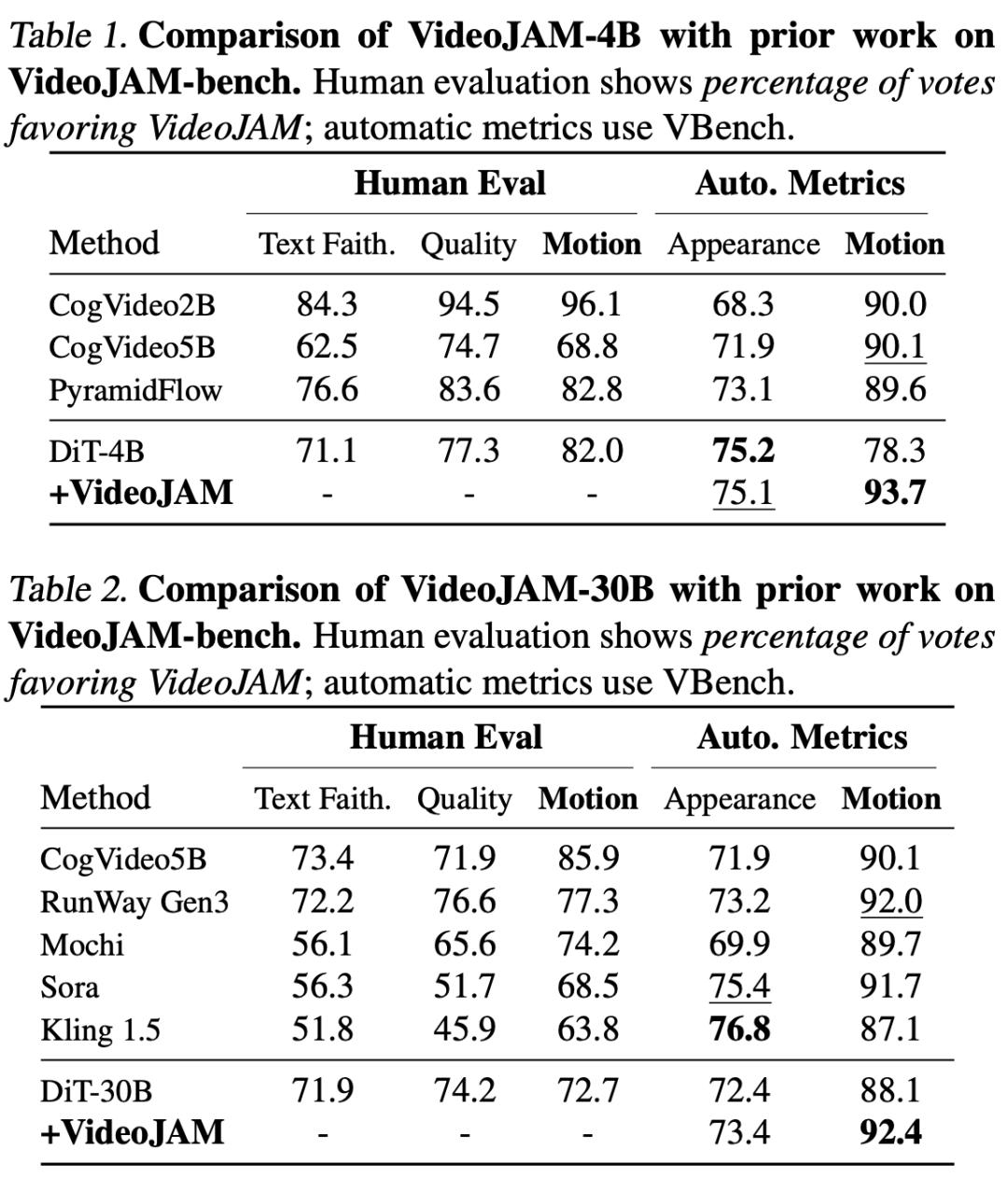
在定量评估中,研究人员就外观质量、运动质量以及提示词一致性,采用了自动指标(automatic metrics)和人工评估相结合的方式。
自动指标
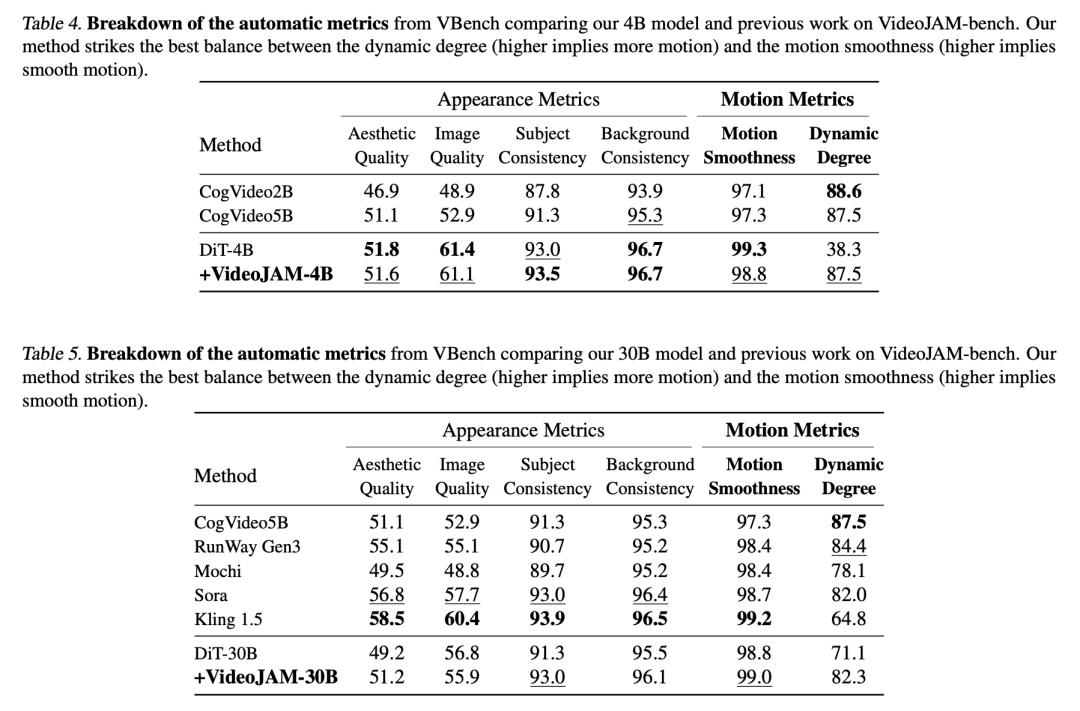
这里,作者使用了VBench基准——能够从多个解耦维度评估视频生成模型。评估指标包括逐帧画面质量、美学评分、主体一致性、生成的运动量以及运动连贯性。
如下表4、表5所示,分别展示了4B模型和30B模型在运动基准测试上的自动指标的结果。
人工评估
在人工评估方面,研究人员遵循二选一强制选择(2AFC) 协议,即评估者在每次比较中观看两段视频(一段来自 VideoJAM,一段来自基线模型),并根据画面质量、运动表现和文本对齐度选择更优者。
每组比较由5位不同的评估者进行评分,每个基线模型在每个基准测试中至少收集640次评价。
评估结果,如下表1、表2所示。
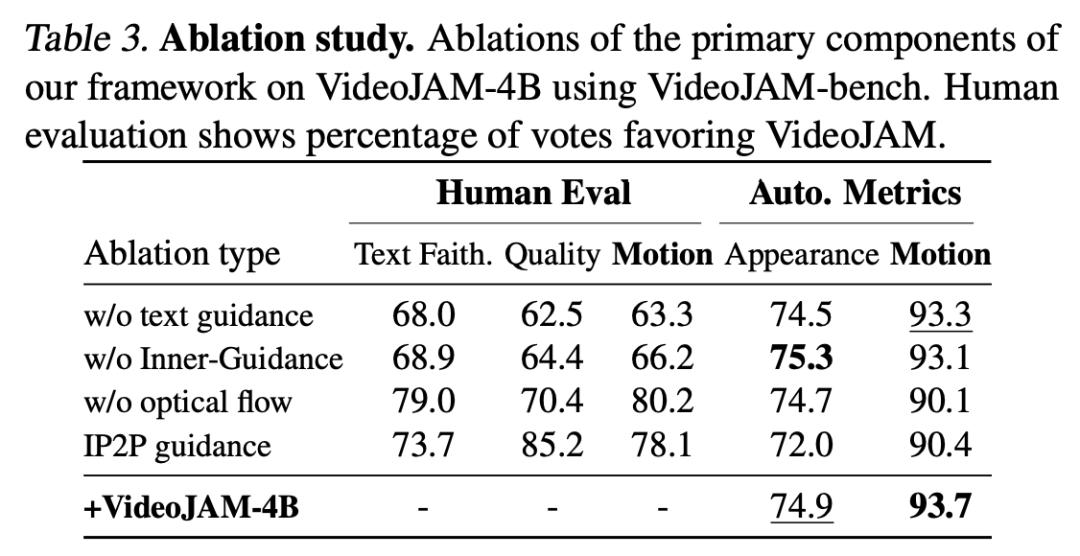
消融实验
如表3所示,所有消融实验都会显著降低运动连贯性,其中去除运动引导的影响比去除文本引导更大,这表明运动引导组件,确实能够引导模型生成时间上连贯的视频。
此外,在推理阶段移除光流预测的影响最大,这进一步证明了联合输出结构对于确保合理运动的优势。
同时,与InstructPix2Pix引导进行对比,也进一步证明了Inner-Guidance公式更适合VideoJAM框架,因为InstructPix2Pix在运动方面的得分为倒数第二低,再次验证了新方法在提升运动连贯性方面的有效性。
局限性
尽管VideoJAM显著提升了时间连贯性,但仍面临一些挑战,如下图7所示。
首先,由于计算资源的限制,作者依赖于有限的训练分辨率和RGB运动表示,这使得模型在「远景」场景下难以捕捉运动信息,当运动物体仅占画面的一小部分时,该问题尤为明显。
在图7(a) 中,降落伞未能展开,运动显得不连贯。
其次,尽管运动与物理规律密切相关,提升了物理一致性,但VideoJAM运动表示缺乏显式的物理编码,从而限制了模型在复杂物理交互中的表现。
在图7(b) 中,球员的脚尚未接触足球,球的运动轨迹却已经发生变化,这表明模型在模拟物理交互时仍存在不足。

结论
视频生成是一项独特的挑战,需要同时建模空间交互和时间动态。
尽管该领域已经取得了显著进展,但视频模型在时间连贯性方面仍存在困难。即使对那些在训练数据集中已经充分表示的基本运动也是如此。
Meta团队的研究指出,训练目标是关键因素之一:以往目标通常偏向于外观保真度,而牺牲了运动连贯性。
为此,他们提出了VideoJAM——一个能够为视频模型显式注入运动先验的框架。
其核心思路直观且自然:由单一的潜在表示同时捕捉外观与运动。
只需增加两个线性层且不需要任何额外训练数据,VideoJAM就能显著提升运动连贯性,甚至可与强大的专有模型竞争。
VideoJAM具有通用性,为未来在视频模型中注入更复杂的现实世界先验(如复杂物理规律)提供了广阔的可能,为整体建模真实世界交互开辟了新方向。
参考资料:
http://https//arxiv.org/abs/2502.02492
https://hila-chefer.github.io/videojam-paper.github.io/


