


作者 | Yoky
邮箱 | yokyliu@pingwest.com
DeepSeek、李飞飞、LIMO,全球的AI界近期几乎都被这几个名词环绕,而这一切的背后,都要从一个“大隐隐于市”的高手谈起。
2月3日,李飞飞和斯坦福大学等团队在arXiv上发表了一篇名为《s1: Simple test-time scaling》的论文,仅在16块H100上微调26分钟,以不到50美元的价格训练出的新模型s1-32B,数学及编程能力与OpenAI o1及DeepSeek R1等尖端推理模型效果相当。
几乎同一时间,来自上海交大的本科生Yixin Ye与团队训练出的LIMO新模型,用1%的数据量,训练出MATH测试准确率高达94.8%的新模型。
一般认为,低成本训练强劲性能模型的方法,基本上始于DeepSeek推出R1模型时顺手做的蒸馏示范。这一系列工作涌现,海外AI社区惊奇地发现,他们采用的基座模型,居然都是Qwen——这位真正的幕后高手。
中国人更熟悉的名字是,通义千问,阿里云自研并开源的大模型Qwen系列。
加拿大滑铁卢大学助理教授陈文虎更是直言,他们也在别的模型上作了尝试,同样的训练数据却完全不奏效,他总结称:“Qwen模型里头一定有一些magical的东西!”

那么,这些充满魔力的东西到底是什么?
1从研究到实践,他们为何都选择Qwen?
李飞飞团队在这篇论文里提到,性能优化的核心技术是s1K 数据集和预算强制法(budget forcing)。
s1K的数据集包含1000个精心挑选的问题,李飞飞团队还使用谷歌的 Gemini Flash Thinking 模型生成每个问题的推理轨迹(reasoning traces)和答案。预算强制方法的特点,则是在模型终结思考时添加“wait”,鼓励探索更多答案。
最后,李飞飞团队对开源的 Qwen2.5-32B-Instruct 进行 s1K 的监督微调并应用预算强制后,得到模型 s1-32B。也就是在 16 个 H100 GPU 上训练26 分钟、花费50美元的阶段。
首先应该破除的迷思是,这绝不仅仅是只花50美元就能办到的事情。李飞飞的新方法,并不是从零训练一个模型,而是基于Qwen模型做的微调。公开数据显示,Qwen2.5模型系列,仅预训练就用了18万亿tokens,可以想见是怎样一笔支出。
陈文虎在X上的留言,更是一语道破天机,绝非所有模型微调后都能有这样的效果。
上海交大团队的LIMO,几乎是对同样技术的探讨,使用了更少的817 个精选训练样本,通过构建更高质量的推理链,结合推理时计算扩展和微调,就在极具挑战性的 AIME 基准测试中从6.5%的准确率提升到57.1% ,在MATH 基准测试中更是达到了 94.8% 的准确率。
这一数据规模,仅占经典方法能达到模型水平所需数据量的1%左右。
在X上,即将成为MIT助理教授、现Databricks的研究科学家Omar Khattab评价LIMO称,此类的论文更像是关于Qwen的研究成果而非推理。

前三星研究院科学家Rakshit Shukla也表示,这些新成果印证了基础模型(也即Qwen)的性能之强。

事实上,国际开源社区对Qwen非常熟识,从Qwen2到Qwen2.5,不同代际的开源Qwen模型,屡屡登上HuggingFace的Open LLM Leaderboard、Chatbot Arena大模型盲测榜单,多次斩获“全球开源冠军”,性能强劲毋庸置疑。
更重要的是,Qwen推出了不同尺寸的开源模型,小到0.5B,大到110B,可以更好满足千行百业的需求,开发者用脚投票,纷纷来下载Qwen模型。这在HuggingFace平台上,仅Qwen的一款小型模型就占据了去年所有模型下载量的26.6%。
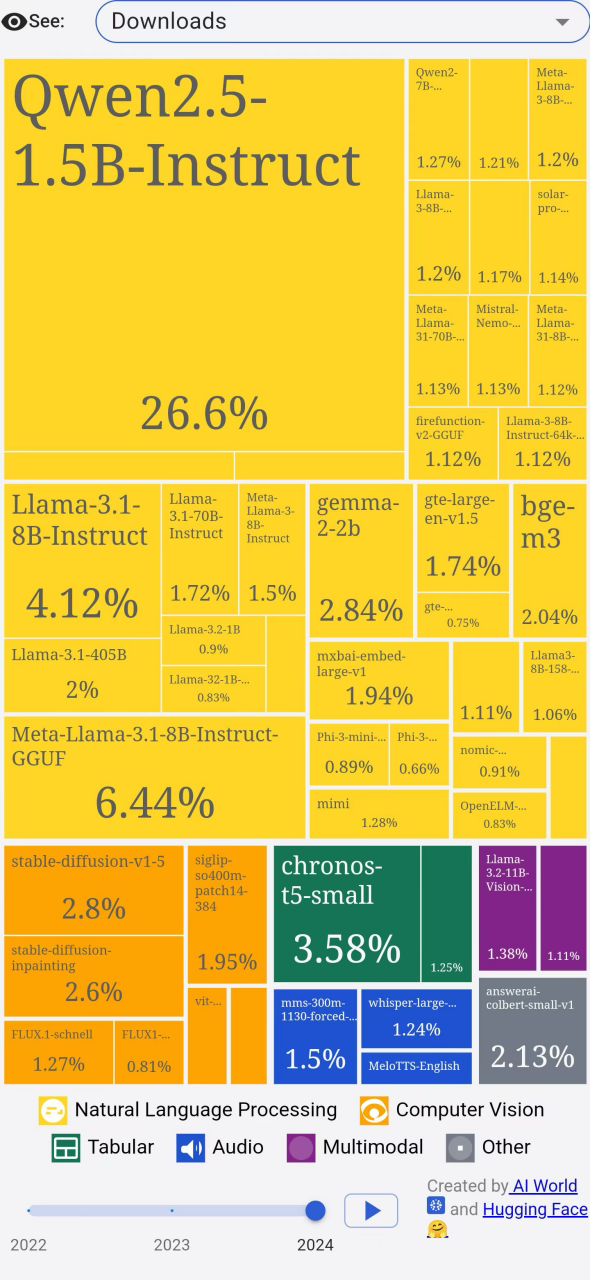
HuggingFace官方供图
全球火爆出圈的DeepSeek,同样选择了Qwen。
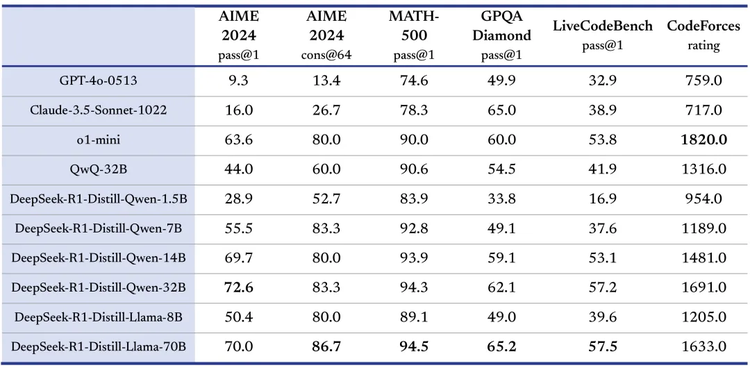
在发布R1时,DeepSeek官方透露,打样蒸馏R1的能力给到6个模型,其中4个模型就是Qwen,分别选择了1.5B、7B、14B和32B四个尺寸,其中基于Qwen-32B的蒸馏模型,在多项能力上实现了与OpenAI o1-mini 相当的效果。
全球越来越多的开发者和企业选择了Qwen,也将他们研发出的Qwen衍生模型贡献于开源社区。目前,开发者二创的Qwen衍生模型数量已经突破了9万,成为全球最大的AI模型族群。
或许,这是李飞飞、Yixin Ye乃至DeepSeek选择Qwen的又一原因,毕竟从学术界到产业界都用的Qwen,是最容易被对比的性能标杆基座模型。
2不止是最佳开源模型,更强的Qwen2.5-Max来了
正当大家为性能出色的开源Qwen模型欢呼时,大年初一,阿里云在凌晨1点半又放出了新年第一弹:Qwen2.5-Max。
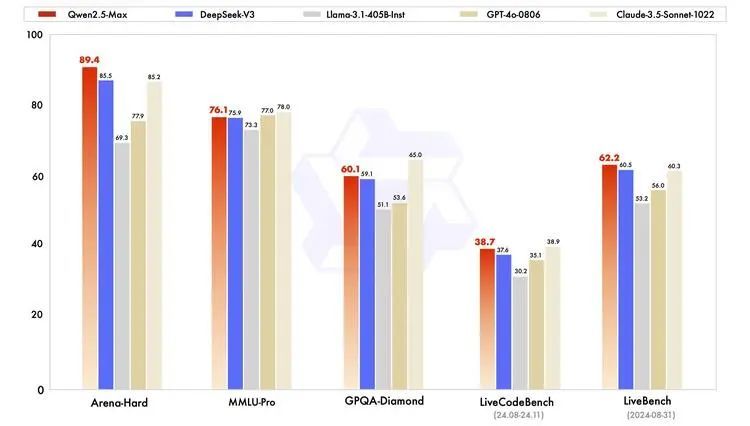
在与业界领先的所有模型对比中,Qwen2.5-Max 依然展现出极强的性能。
在测试大学水平知识的 MMLU-Pro、评估编程能力的 LiveCodeBench、全面评估综合能力的 LiveBench,以及近似人类偏好的 Arena-Hard等主流测评中,Qwen2.5-Max比肩Claude-3.5-Sonnet,并几乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
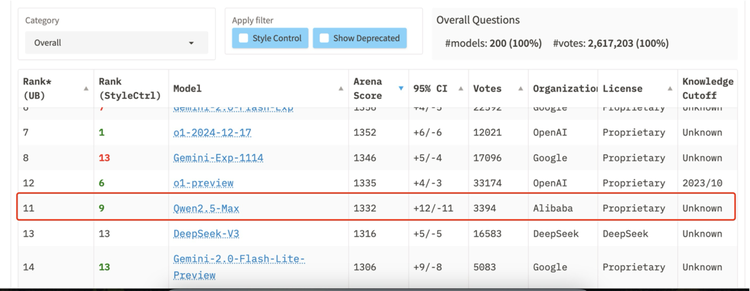
而就在这两天,Qwen的新模型又再次以超强性能冲上主流大模型评测榜单全球前十:
2月4日, 业界最知名的三方评测榜单——Chatbot Arena 大模型盲测榜单放榜。Qwen2.5-Max以1332分,超过DeepSeek V3、o1-mini和Claude-3.5-Sonnet等国内外强手,获得全球第七名,并且获得数学和编程的单项第一。

2月6日,在Meta杨立昆牵头的LiveBench最新榜单中,Qwen2.5-Max也闯进全球前十,领先于DeepSeek-V3、Gemini-2.0-flash-lite等诸多好手。
Qwen团队关于Qwen2.5-Max的技术博客里最后一段提到,“持续提升数据规模和模型参数规模能够有效提升模型的智能水平。”
这等同于解答了这个超大规模MoE模型里的秘密:Scaling Law,基于MoE(混合专家)架构开发,持续扩大参数规模,不断改进训练方案。Scaling Law,既是观念,也是实践。
在预训练数据规模上,Qwen2.5-Max模型基于高达20万亿tokens的数据进行预训练,规模比训练Qwen2.5的18万亿Tokens还要多。Qwen2.5-Max的预训练数据覆盖领域广泛,且知识密度高,同时通过精心设计的数据过滤及配比,保证了数据的数量与质量。此外,全面优化的后训练数据及强化学习方法让 Qwen2.5-Max 产出的内容也更符合广大用户的偏好。
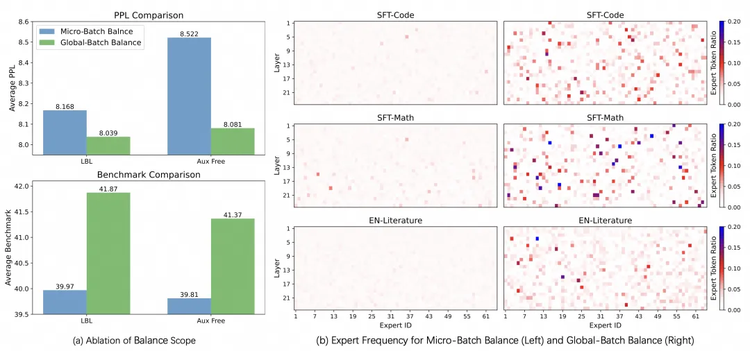
而在训练技术层面,Qwen团队在今年1月提交的这篇名为《魔鬼在细节》(Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models)的论文中,着重解释了MoE模型训练改进的方法。
在DeepSeek训练V3的技术报告中,就曾在小规模上讨论了基于全局均衡来优化专家选择的效果。而Qwen更进一步,通过轻量的通信代价实现了全局均衡,在大规模上系统验证了这种方法的有效性,使得MoE 模型的性能和专家特异性都得到了显著的提升。
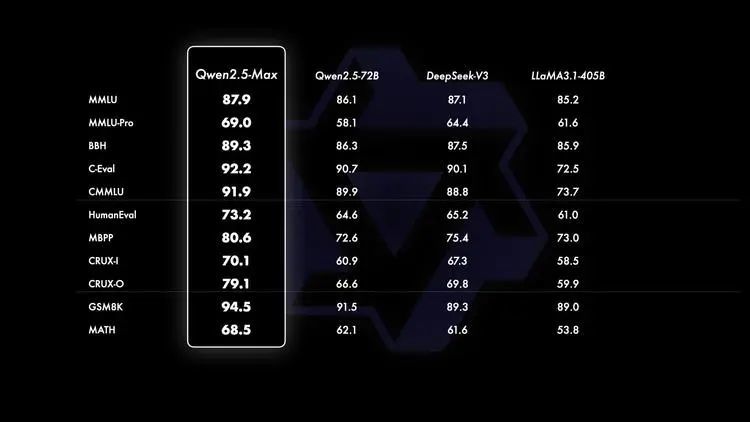
也正因这些关键改进,在模型裸性能也即基座模型的11项评测对比中,Qwen2.5-Max 与业界领先的 MoE 模型 DeepSeek V3、最大的开源稠密模型 Llama-3.1-405B以及同系列的 Qwen2.5-72B 比拼中,全面领先。
3不是从DeepSeek到Qwen,而是从Qwen到开源世界
当不少人为Qwen2.5-Max性能超越DeepSeek-V3、再度为中国大模型欢呼时,实际上忽略了一个重要的事实:在DeepSeek爆火之前,海外大模型圈,早就熟知了Qwen这一名字。
在我们此前对硅谷的数次探访中,每当谈及中国大模型,不少CEO、开发者蹦出来的第一个名字,是Alibaba's Qwen。
过去两年来,Qwen的确是开源最多、最深入的中国大模型代表。Qwen模型性能强劲,开源尺寸多样化,并且拥有全球最大的衍生模型群,成为学术界到产业界都广受欢迎的最重要的开源模型系列。
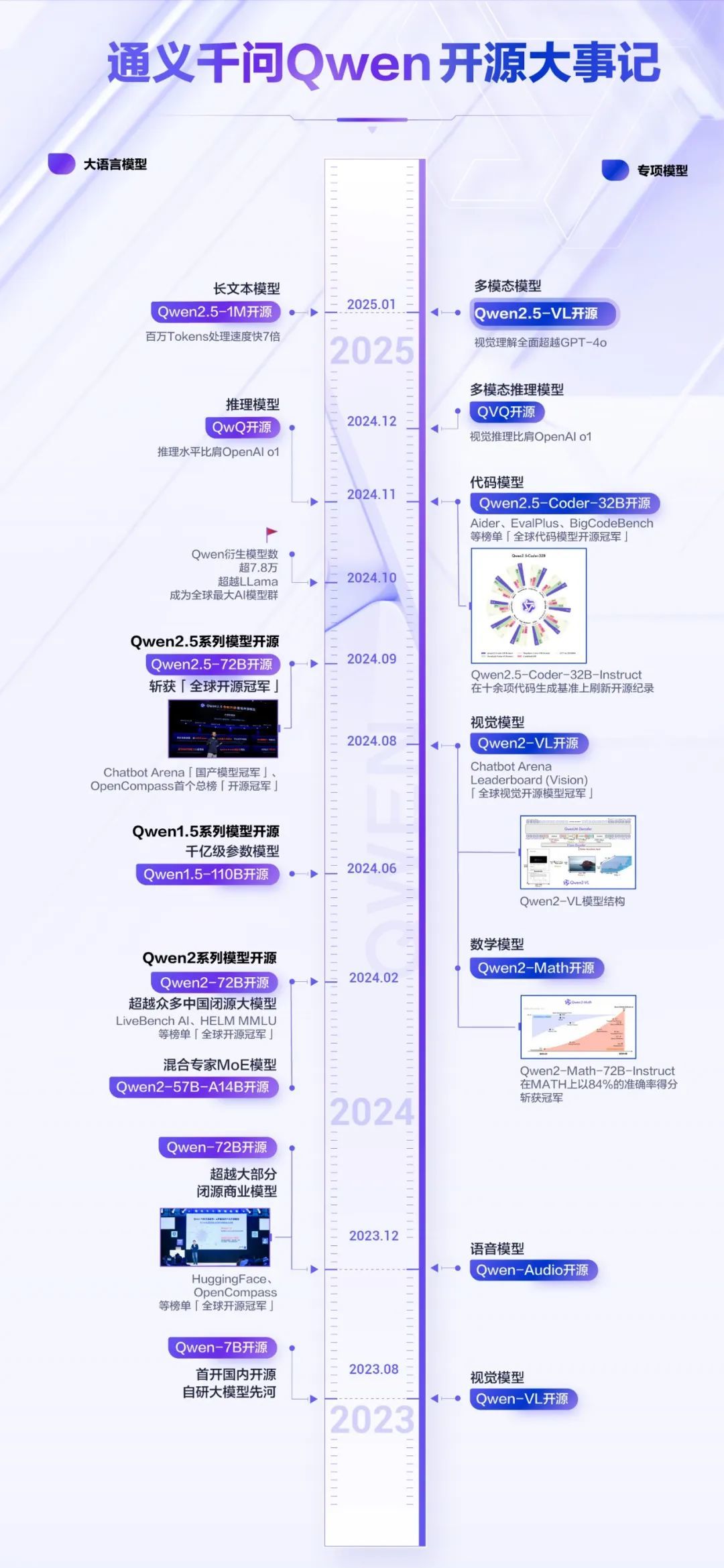
从2023年8月首个开源模型Qwen-7B的发布开始,Qwen就陆续开源了覆盖不同参数规模、不同模态、不同应用场景的数十款模型。这些模型不仅包括通用大语言模型,还涵盖了多模态、对话、代码生成等专业领域的特化版本。
在GitHub社区,Qwen收获了来自全球开发者的好评。特别是2024年9月发布的Qwen2.5系列模型,在代码生成和调试任务中表现卓越。有开发者成功通过本地部署Qwen2.5-32B模型并配合VS Code扩展工具,完全替代了此前依赖的ChatGPT和Claude 3.5 Sonnet的编程辅助功能。
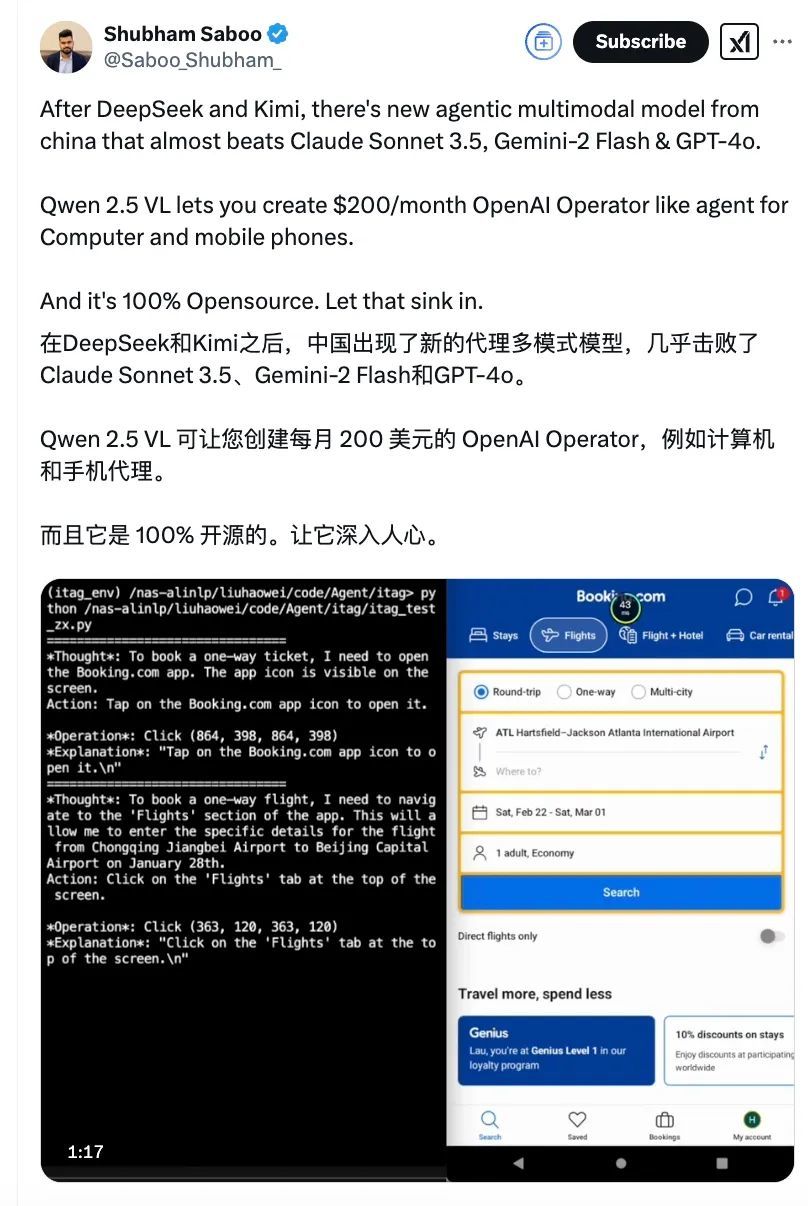

图源X截图
仅仅在过去的3个月,Qwen就陆续开源了推理模型QwQ、多模态推理模型QVQ、数学推理过程奖励模型Qwen2.5-Math-PRM、支持100万Tokens的长文本模型Qwen2.5-1M以及最新一代视觉理解模型Qwen2.5-VL。
以视觉理解模型为例,阿里云曾开源Qwen-VL及Qwen2-VL两代模型,全球总下载量突破3200万次,是开源社区里最受欢迎、性能最强的视觉理解模型,开发者用它来理解难以辨认的手写稿,解答书本上艰深的数学物理题,甚至尝试去探索月球和银河的秘密。
也正因此,Qwen2.5-VL一开源发布,就引发了大波的海外Qwen粉丝们的狂欢,开源社区大佬VB一句话总结:它持续变得越来越好了。
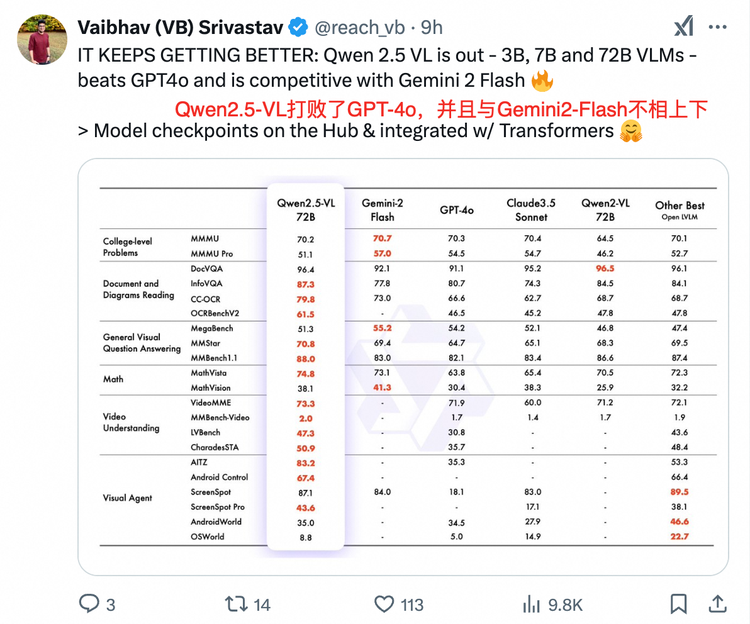
一个业界的共识是,Qwen最早扛起了中国AI大模型开源的大旗,也带起了一波开源的浪潮,孕育起一个AI生态。阿里云牵头建设的魔搭社区,已经上架了4万多个AI模型,服务超过1000万名开发者。
李飞飞这样的学术大咖选择Qwen,Yixin Ye这样的年轻本科生基于Qwen探索新技术,甚至DeepSeek这样现象级的创业公司也用Qwen模型做蒸馏。更多来自阿拉伯语、法语、日语、西班牙语地区的开发者,因为Qwen的强劲语言能力而第一次拥有了性能超群的本国语言大模型。
Qwen让AI技术从杭州走向了世界。
4「神秘东方力量」的公开秘密
人往往高估一年的变化,但会低估五年的变化。
不到一年前,还有大佬认为闭源才是AI大模型发展的主流,现在,全世界的开发者都在为开源的中国AI技术挑战传统霸权而欢呼。
今天,当我们谈中国大模型集体崛起,我们会谈论DeepSeek,谈它背后充足的量化资本以及追求AGI的纯粹初心;我们也会谈通义千问Qwen,谈孕育它的阿里云和更庞大的阿里巴巴生态。
巧的是,这两个扬名海外的中国大模型,都来自杭州,因此也有人称之为开源世界里的杭州「内战」,甚至一度传出阿里要入股DeepSeek的谣言。一个不争的事实是,在DeepSeek最需要算力支持的时候,阿里云官宣支持部署DeepSeek-V3和R1模型。
AI不是零和博弈,最后胜利也不会只属于某一家公司。在这样一个激动人心的大时代,齐头并进或许是个最优解。
当然,时间会考验所有人,而一切才刚刚开始。


