

这个春节,人工智能无疑成为了社交话题的C位,前有人形机器人在春晚跳扭秧歌而出圈,后有“Deepseek”的强势崛起。
网友们疯狂涌入Deepseek,有人找Deepseek算命,有人问Deepseek怎样才能暴富,还有科技金融行业的打工人,年还没有过完,就得忙着加班写研报、测试模型。
但海外市场对此却态度微妙,OpenAI一度宣称Deepseek“偷窃”了其“技术成果”,但一转头,微软、英伟达等大厂都宣布在自家产品中接入Deepseek,OpenAI CEO山姆·奥特曼更表示Deepseek的R1模型“令人印象深刻”。
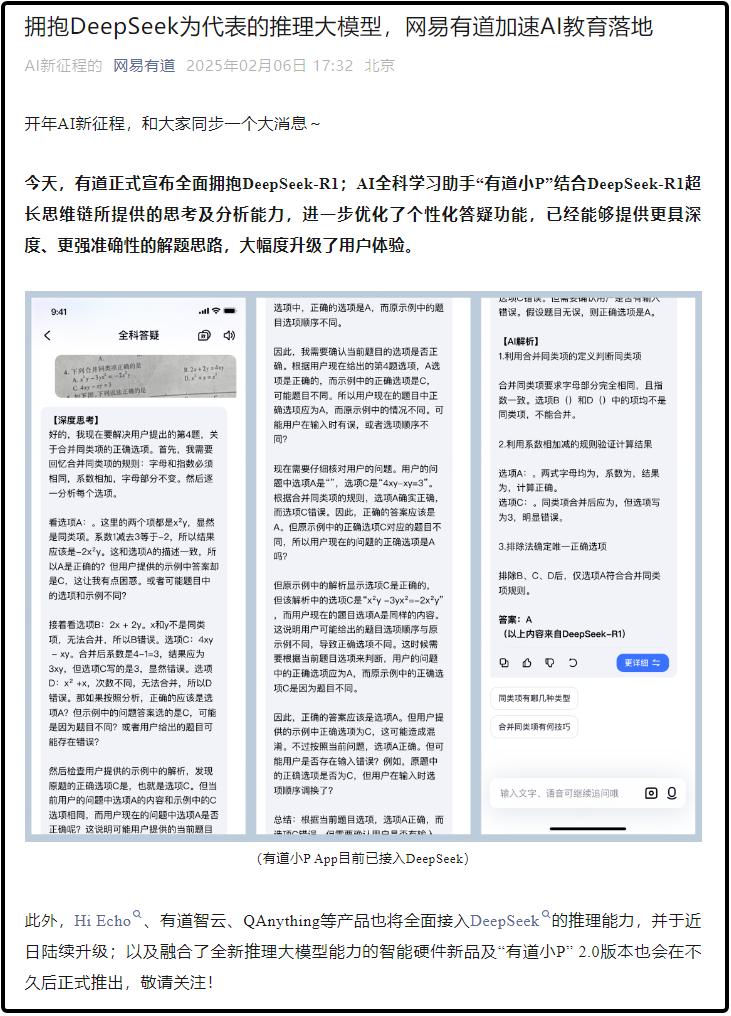
国内的互联网巨头们也没有错失这波Deepseek的热度,2月6日,有道正式宣布全面拥抱DeepSeek-R1。此外,Hi Echo、有道智云、QAnything等产品也将全面接入DeepSeek的推理能力,并于近日陆续升级。
一时之间,这场AI大模型的技术迭代,不知不觉就演变成全球科技行业的现象级事件,Deepseek也被视为引领大模型行业从“大而全”到“小而美”的全新变量。
但热闹过后,Deepseek还需要回答更多的新问题,全球大模型行业该如何抓住“变革的火花”,或许才是接下来的关键。
01 三大变量引爆Deepseek
在普通用户看来,Deepseek是在此次中美大模型技术之争中“一战成名”,但更早之前,Deepseek便已经因为“价格便宜”而被AI圈广泛关注。
去年中,国内大模型行业大打“价格战”,但第一个“挑起战火”的并非阿里、百度等大厂,而是Deepseek,彼时其新推出的DeepSeek-V2价格仅为 GPT-4-Turbo 的百分之一左右。
此次“降价”也让Deepseek被冠以“AI界拼多多”之称,但相较于大厂们的“以价换市场”的惯常做法,Deepseek对于“降价”并没有太多压力,因为其降价之后也仍有利润。
事实上,这才是Deepseek能够震惊全球科技界的主要原因,其能够以更低的成本换来更高的性能,颠覆了过去大模型行业依靠堆显卡、堆资本来发展AI的“Scaling law”。
这是因为Deepseek的模型训练路径不同于传统通用大模型,以ChatGPT为代表的传统AI,主要采用监督微调(简称 SFT)作为大模型训练的核心环节,即通过人工标注数据进行监督训练,再结合强化学习进行优化,本质上大模型并不会思考,只是通过模仿人类思维方式来提升推理能力。
但在1月底发布的Deepseek-R1-Zero却颠覆了这一规则,其对模型架构进行了全方位创新,通过单纯的强化学习(RL)训练实现推理能力。简单来说,SFT是人类生成数据,机器学习;而RL是机器生成数据,机器学习。
除此以外,据每日财经新闻报道,DeepSeek创新性地同时使用了FP8、MLA(多头潜在注意力)和MoE(利用混合专家架构)三种技术。
其中,相较于其他模型使用的MoE架构,DeepSeek-V3的更为精简有效,其就像是医院的“分诊制度”,可以将大模型拆分成多个“专家”,训练时分工协作,推理时根据任务分配给最适合的专家模块。据悉,Deepseek能够将无效训练从传统模型的90%降低至60%。
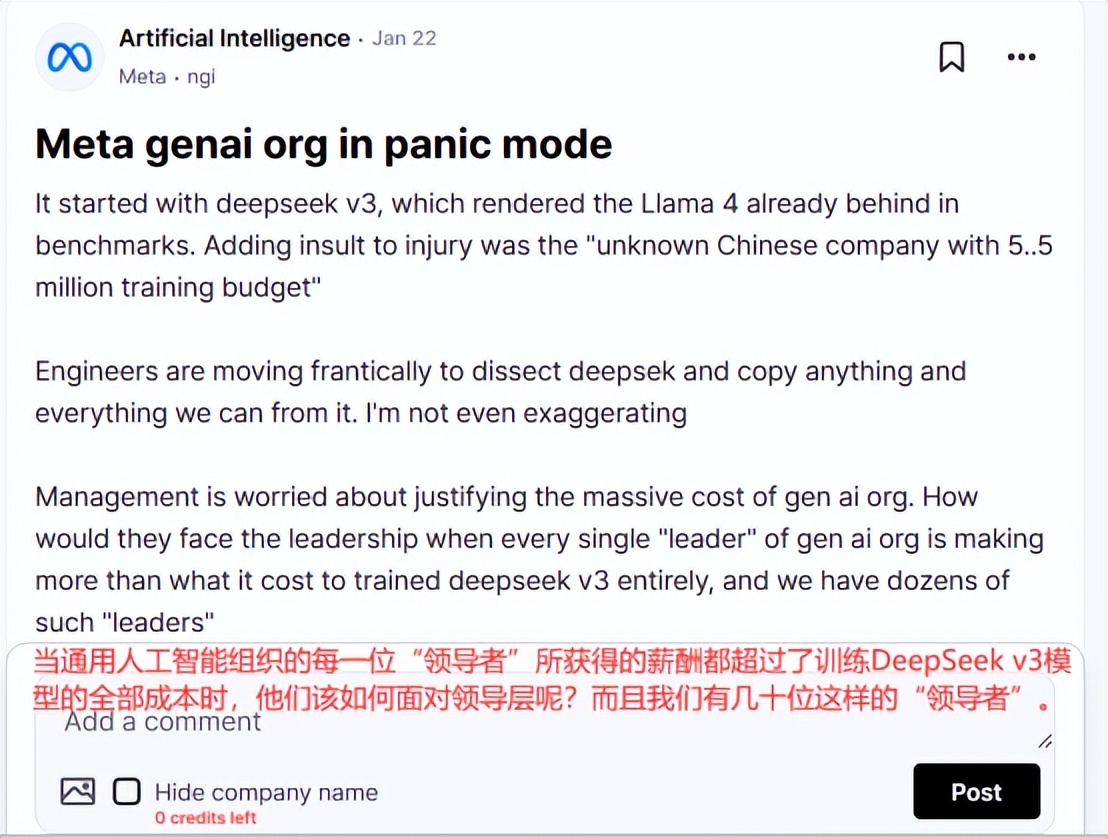
在Deepseek-R1发布后,一位Meta员工在美国匿名职场社区teamblind上留言,称Deepseek最近的一系列动作让Meta的生成式AI团队陷入了恐慌。
据这位员工爆料,“Meta一个负责AI项目的高管年薪拿出来,就足够训练Deepseek了”。据每日经济新闻报道,Deepseek R1的预训练费用只有557.6万美元,还不到OpenAI GPT-4o模型训练成本的十分之一。
但从实际性能来看,Deepseek-R1已经能够比肩OpenAI-o1正式版,特别是在数学、代码、自然语言推理等任务上。
在美国数学竞赛(AMC)以及全球顶级编程竞赛(codeforces)等权威评测中,DeepSeek-R1-Lite-Preview 模型已经大幅超越了 GPT-4o 等顶尖模型,有三项成绩还领先于 OpenAI o1-preview。
除了“低成本、高算力”这一突破之外,Deepseek之所以在这个春节“燃起来”,还因为其竟然不是出自传统的大厂,而是一家量化基金公司。
Deepseek成立于2023年12月,在此之前,其创始人梁文锋于2015年便成立了名为“幻方量化”的量化对冲基金,可以说Deepseek的前身其实是服务于量化交易的。
这样的背景也为Deepseek增添了更多“看点”,比如梁文锋之所以不差钱,是因为其在量化交易上赚得风生水起,网友甚至戏称Deepseek的训练成本是来自于造空英伟达。
还有背靠千亿量化基金的梁文锋,明明可以选择轻松躺赚,却选择投身到全球创新的浪潮里,他坦言“对AGI的好奇与探索比商业回报更具驱动力”,这种一往无前的“理想主义”,想让也让Deepseek的“故事”变得更加动人。
02 大厂打不过就加入
不过,技术上的逆袭,尚不足以彻底震惊科技界,真正引爆Deepseek的变量,其实是“开源”。据悉,Deepseek已经把模型架构和参数开源,在大模型公司普遍选择闭源的当下,训练数据的开源在业界少有先例。
梁文锋曾在媒体采访中表示,“过去很多年,中国公司习惯了别人做技术创新,我们拿过来做应用变现,但这并非是一种理所当然。我们的出发点不是趁机赚一笔,而是走到技术的前沿,去推动整个生态发展。”
从商业角度来看,“开源”是不是一个更佳的策略,尚难以下定论。毕竟训练模型需要成本,招揽用户也需要推广费用,从此前字节豆包大规模投放广告、kimi多次接受融资就可以看出,大模型公司有自己的难处。
但对于中国大模型行业来说,或许正是梁文锋的“理想主义”,才让Deepseek能够成为颠覆行业格局的“变量”。
一方面,开源将能吸引更多大厂和技术人才加入,通过共建共创让Deepseek变得更加强大,从而推动整个人工智能大模型生态的发展,形成一个全新的生态。
梁文锋曾对媒体表示,公司未来不会像OpenAI一样选择从开源走向闭源,“我们认为先有一个强大的技术生态更重要” 。
另一方面,对于以OpenAI为代表的竞争对手来说,这也是一个致命的打击。毕竟,当一个旗鼓相当的,还是免费的产品出现在消费者面前,大家难免就会进行比较,谁的性价比更高,谁的性能更优秀,都需要实打实的使用效果来验证,而不仅仅只是“吹泡沫”。
而率先作出选择的,便是一众海外大厂,目前包括英伟达、英特尔、亚马逊、微软、AMD、等海外科技大厂,均宣布在自家产品中接入Deepseek。
值得一提的是,欧美多国对于Deepseek的安全性、隐私问题依然存在质疑。美国多位官员表示正在对Deepseek开展国家安全调查,包括国防部、国会和NASA等部门均被要求禁用Deepseek。
此外,据彭博社等媒体报道,微软还曾调查 OpenAI 技术输出的数据是否被中国的Deepseek团队以未经授权的方式获取,比如通过“蒸馏技术”非法获取其模型输出数据。

但在这些争议尚未解决之前,大厂们显然已经迫不及待想要加入Deepseek生态,本质上还是基于“利益至上”的原则。
据斯坦福大学计算机科学系和电子工程系副教授吴恩达表示,OpenAI - o1模型每百万输出token 的成本为60美元,而Deepseek-R1 则仅需 2.19 美元,这接近30倍的成本差距,相信大厂们也会算账。
其次则是生态效应,吴恩达认为,“降价”+“开源”正在将基础模型层商品化,为应用开发者创造了巨大的机遇。尽早加入这一生态,让自家大模型与之相结合,也有望带来更多创新体验,“收拢”部分DeepSeek用户的需求。
因此,除了海外大厂之外,诸如阿里云、百度云等国内大厂也开始集中接入Deepseek,在各自平台提供的适配服务,打不过就加入,才能共享创新红利。
03 乘上Deepseek的东风
事实上,在开春爆火的Deepseek,不仅为大模型行业带来了一阵“春风”,对于普通用户来说,也带来了更多新机会。
第一批利用Deepseek搞钱的人已经出现了,跟彼时横空出世的ChatGPT一样,面对更加智能、更加高效的大模型,AI取代人类的焦虑感,再次成为收割用户的“武器”。
社交平台上已经出现了不少“如何使用Deepseek进行XXX”的课程,面向社交媒体、电商、广告等不同行业的应用和变现。
当然,学习新知识肯定是没错的,但相较于被焦虑感“收割”,并沦为大V私域流量中的一员,大家不妨根据自己的实际工作和擅长内容,先上手试用一下Deepseek。
目前来看,Deepseek在技术上确实有意想不到的突破,对于普通用户来说,其能够展示思维链全过程,更方便人类与AI交流,业内人士甚至称之为当前最好用的开源模型,但也不需要过度“神化”Deepseek。
首先,从使用体验来看,Deepseek尚无法承受蜂拥而至的流量。其实,Deepseek在年前便已经小范围的“爆火”,其当时尚能同时使用深度思考和联网功能,输出的文章框架和成文确实比较惊艳。
但随着使用者不断增多,目前Deepseek已经关闭了联网功能,整理输出质量有较大的下降,且大部分时间Deepseek都呈现“服务繁忙”的状态。
虽然梁文锋曾表示“商业化”不是当前首要考虑的问题,但按私募基金的体量来推算“幻方”的资金规模,千亿规模不等于千亿资金体量,“幻方”只是在千亿规模上收取管理费,其跟大厂之间的资金差距还是很大的。
但要继续维持C端的使用体验,Deepseek必然需要烧钱,后续如何补充资金,还是调整使用模式,梁文锋都需要提出更明确的打法。
其次,目前Deepseek在图文、视频方面的能力是缺失的,现阶段要说Deepseek能够与头部闭源模型直接打擂台,恐怕还为时尚早。
不过,其发展也给Open AI,以及更多垂直模型带来了压力,相信将能在一定程度上推动整个大模型生态的发展。
最后,Deepseek依然面临着政策、数据安全等争议,要走向全球依然是漫漫长路;此外,其在计算资源与算力方面依然受限,这意味着国产硬件还需要继续努力,才能支撑软件的不断创新。
当然,对于全球大模型行业来说,有竞争才有动力,就像智能手机行业一样,参与者多了,行业盘子就会越来越多,也才有机会爆发出更多的机会。
Deepseek的出现就像是国内大模型行业的一点“火花”,既是思维碰撞的突破,也是灵感乍现的瞬间。接下来,相信还需要国内大模型行业在软硬件方面的持续创新,才能抓住这一机遇,让中国科技行业能够从“跟随者”向“引领者”进发。


