

阿里云确认:李飞飞团队 s1 模型基于 Qwen2.5-32B-Instruct 模型训练
2025-02-06
/ 阅读约2分钟
来源:IT之家
李飞飞团队 s1 模型被指“并非从零开始训练”,其基座模型为“阿里通义千问(Qwen)模型”。对此,新浪科技向阿里云方面求证,阿里云方面确认了这一消息。
IT之家 2 月 6 日消息,今日,李飞飞研究团队以不到 50 美元的云计算费用训练了一个名叫 s1 的人工智能推理模型,该模型在数学和编码能力测试中的表现与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型类似。
不过很快,该 s1 模型被指“并非从零开始训练”,其基座模型为“阿里通义千问(Qwen)模型”。对此,新浪科技向阿里云方面求证,阿里云方面确认了这一消息。
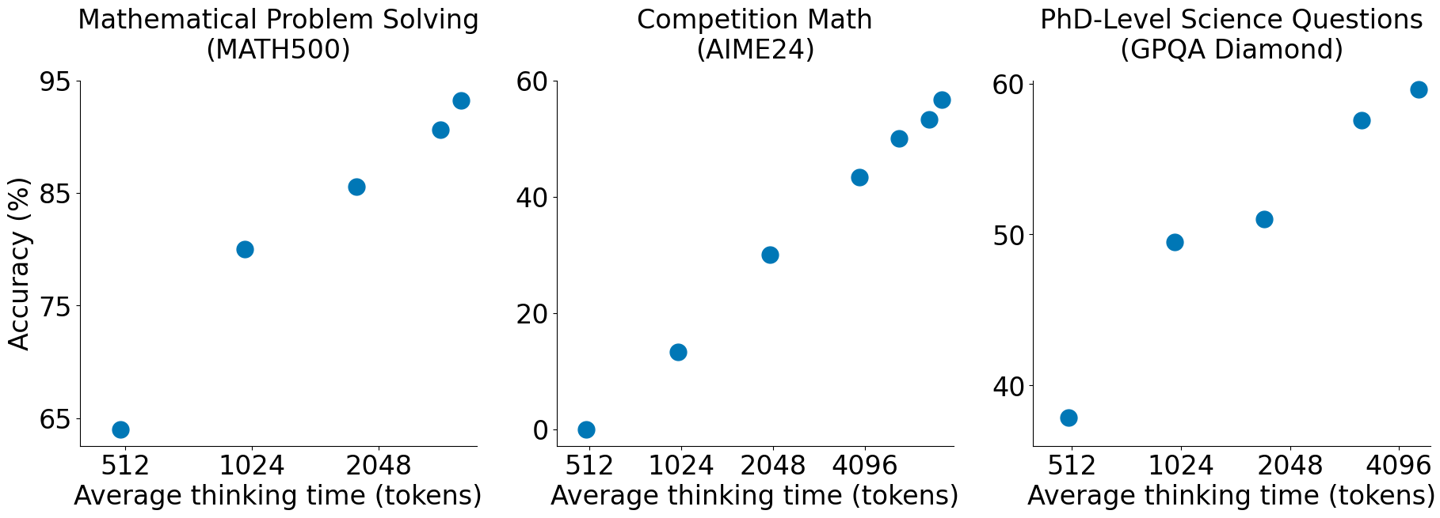
阿里云回应称:“他们以阿里通义千问 Qwen2.5-32B-Instruct 开源模型为底座,在 16 块 H100 GPU 上监督微调 26 分钟,训练出新模型 s1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果,甚至在竞赛数学问题上的表现比 o1-preview 高出 27%。”
据IT之家此前报道,s1 团队透露他们通过“蒸馏”技术创建了该人工智能模型,该技术旨在通过训练模型来学习另一个人工智能模型的答案,从而提取其“推理”能力。
s1 的论文表明,可以使用一种称为监督微调(SFT)的方法,可以使用相对较小的数据集来蒸馏推理模型。在 SFT 中,人工智能模型会被明确指示在数据集中模仿某些行为。SFT 比 DeepSeek 用于训练其 R1 模型的大规模强化学习方法更具成本效益。
s1 基于阿里巴巴旗下中国人工智能实验室 Qwen 提供的一款小型、现成的免费人工智能模型。为了训练 s1,研究人员创建了一个仅包含 1000 个精心策划的问题的数据集,以及这些问题的答案,以及谷歌 Gemini 2.0 Flash Thinking Experimental 给出的每个答案背后的“思考”过程。


