

AI圈的当红辣子鸡,已经引发了厂传厂“交友”的现象级表现。
国内,云厂商跑得最快。
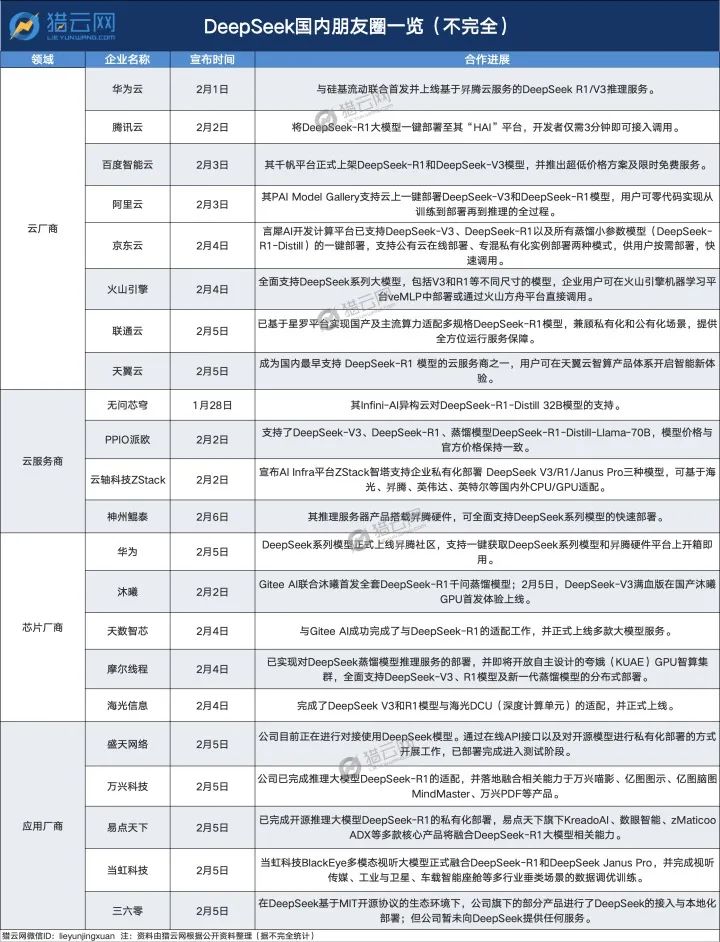
2月1日,华为云就打响第一枪,随后腾讯云、阿里云、百度智能云、京东云、联通云等主流云平台也相继宣布接入DeepSeek系列模型。
同期,DeepSeek的这股“接入热”还蔓延到了各大芯片厂商、应用端企业,呈现出“提速”态势。
短短一周内,不仅海光信息、摩尔线程等芯片厂商宣布适配上线,上市公司奇安信、视觉中国、易点天下、盛天网络、神州数码、万兴科技等更是密集宣布:接入DeepSeek。
而这股“交友”热潮在国内还算是“虽迟但到”。
要知道,早在1月底,微软、英伟达、亚马逊、英特尔、AMD等海外巨头们就相继拥抱,纷纷跟DeepSeek牵起了手。
何以至此,还得从今年春节DeepSeek的一炮而红谈起。
半个月前,国产开源大模型DeepSeek-R1正式发布,在数学、代码、自然语言推理等任务上性能对齐OpenAI-o1正式版,可谓一鸣惊人。
更关键的是,DeepSeek-R1用的还是更经济的计算资源,推理成本仅为OpenAI-o1的几十分之一,其开源的路径,更是降低了各领域AI应用的研发成本,可以有效加速大模型应用创新和普及。
这也就意味着以低成本已可训练出足够好的AI模型,这将是一场通往AGI时代的技术普惠。
众所周知,AI界苦降本增效久矣,打出“高性能、低成本”牌的DeepSeek,自然成为了香饽饽。
01 他们,都在跟大模型黑马“交朋友”
截至目前,DeepSeek“朋友圈”的企业可一分为三来看。
首先,是春江水暖鸭先知的云厂商们,每天都有新人在官宣进场。
国内云服务厂商无问芯穹来的最早,在1月28日除夕一大早宣布了其Infini-AI异构云对DeepSeek-R1-Distill 32B模型的支持。
随后四大云巨头中,当属华为云最快。
2月1日就在官微宣布,与硅基流动联合首发并上线基于昇腾云服务的DeepSeek R1/V3推理服务,表示“其性能可与全球高端GPU部署模型相媲美”。
腾讯云阿里云,则分别以“开发者仅需3分钟即可接入调用”“用户可零代码实现从训练到部署再到推理的全过程”主打“一键部署”的高效。
百度智能云靠“卷”出圈,早早打出低价牌,推出“超低价格方案及限时免费服务”。
京东云跟联通云则划出“按需部署”的关键词,前者“支援公有云线上部署及专混私有化实例部署两种模式”,后者“兼顾私有化和公有化场景,提供全方位运行服务保障”。
从云厂商的角度来看,他们率先与DeepSeek实现深度对接,无论是为了构建AI生态,丰富平台的AI服务、还是降低成本,亦或是吸引开发者、满足客户的多样化需求,快速接入最火的大模型,都是笔划算的买卖。
再到芯片厂商,更是全球闻风而动,为DeepSeek提供算力支持。
这里面,不在春节假期的海外公司占了先机。
1月31日,英伟达宣布,NVIDIA NIM已经可以使用DeepSeek-R1。同日,微软称已将DeepSeek-R1正式纳入Azure AI Foundry。亚马逊云科技(AWS)也宣布:企业和开发者可以在Amazon Bedrock和Amazon SageMaker AI中部署DeepSeek-R1模型。
2月2日,沐曦联合GiteeAl发布全套Deepseek-R1千问蒸馏模型,DeepSeek-V3满血版在国产沐曦GPU首发体验上线。
随后在2月4日,摩尔线程、天数智芯、海光信息同天入局,其中,海光信息技术团队已完成DeepSeek V3和R1模型与海光DCU的适配并上线,摩尔线程也宣布,已实现对DeepSeek蒸馏模型推理服务的部署。
此外,DeepSeek系列模型首发即支持昇腾平台,神州数码旗下神州鲲泰推理服务器产品搭载昇腾硬件,可全面支持DeepSeek系列模型的快速部署。
而这场AI盛宴,应用端自然也不会缺席。
在网络安全应用上,奇安信自研QAX安全大模型通过DeepSeek-R1进行了一系列的优化和蒸馏,运营成本实现了大幅降低,同时在威胁研判等多个场景下的模型性能方面获得了显著提升。
其中安全专业问答整体性能分数提升约16%,极大提升了智能威胁分析和决策的准确度。
数字创意软件公司万兴科技2月4日也宣布,旗下视频创意、绘图创意及文档创意软件业务多款产品完成了与DeepSeek-R1的深度适配,包括万兴喵影、亿图图示、亿图脑图MindMaster、万兴PDF等。
此外,在应用侧接入DeepSeek的相关企业还有推动视觉内容服务领域AI技术应用进一步升级的视觉中国、智能营销服务商易点天下、智能视频解决方案与视频云服务商当虹科技以及互联网和移动安全产品及服务提供商三六零。
从云到芯片再到应用,DeepSeek卷起的全球AI风暴,已然深度卷进产业中的每一位玩家。
来源:猎云网
02 “AI界拼多多”,要走出一条生态路
值得注意的是,DeepSeek的爆火,并不是偶然。
这还得从它的基因说起。
据天眼查显示,DeepSeek公司全称为“杭州深度求索人工智能基础技术研究有限公司”,简称“深度求索”,成立于2023年7月,公司股东为宁波程恩企业管理咨询合伙企业(有限合伙)(即知名量化资管巨头幻方量化)和创始人梁文锋。
从股东便可看出,彼时下场大模型的深度求索,有的是量化基金的背景,在一众AI大牛创业中,有点宛如异类。
但是优势也非常明显:资金、团队、硬件,它齐了。
幻方量化于2015年成立,通过AI技术优化量化投资策略,2021年公司管理规模就突破千亿元,成为国内量化私募四巨头之一。
也由此,梁文锋跟团队积累了量化投资和高性能计算领域的深厚背景和丰富经验,同时伴随的还有AI能力。
根据《财经十一人》内容,2023年国内拥有超过1万枚GPU的企业就包括了幻方量化。早在2019年,幻方就成立了AI团队,自研深度学习平台。
这些,都足以让深度求索在大模型圈低调前行。
当时,在《暗涌》的文章中,幻方目标很明确,“深度求索”强调专注做真正人类级别的人工智能,目标是研究——开源——推动行业发展,最终通向AGI。
在文章中,梁文锋更是坚定认为“OpenAI不是神,不可能一直冲在前面”。
这些都奠定了DeepSeek的基调,不是模仿,而是原创,不是学徒,而是挑战者。
成立半年后,第一代大模型DeepSeek Coder便发布,同月还率先开源中国首个MoE大模型(DeepSeek-MoE)。
2024年5月,其第二代开源Mixture-of-Experts(MoE)模型——DeepSeek-V2面世,因为DeepSeek V2模型因在中文综合能力评测中的出色表现,且以极低的推理成本引发行业关注。
也是这一次,DeepSeek有了“AI界的拼多多”之称。
去年底,全新系列模型DeepSeek-V3首个版本上线并同步开源,根据公开信息,DeepSeek V3的表现几乎追上了Anthropic Claude 3.5 Sonnet和OpenAI GPT-4o。
连Meta AI研究科学家田渊栋都给出了赞赏,称“这是一项了不起的工作”。
再到成本上,官方技术论文更是披露,DeepSeek-V3模型的总训练成本为557.6万美元,而GPT-4o等模型的训练成本约为1亿美元。
强烈的成本对比之下,直接让DeepSeek谱写了AI界的新神话。
彼时,深度求索对外表示,“这是一个全新的开始。”也由此,DeepSeek在AI圈开始有了些许声音。
今年1月20日,DeepSeek-R1模型正式发布,并同步开源模型权重。与此同时,DeepSeek应用(不包含网站数据)上线5天日活就已超过ChatGPT上线同期日活,成为全球增速最快的AI应用。
随后,乘着超预期的产品体验带来的口碑裂变,DeepSeek迎风而上,在1月28日发布开源多模态模型Janus-Pro。
其中,70亿参数版本的Janus-Pro-7B模型在使用文本提示的图像生成排行榜中优于OpenAI的 DALL-E 3和Stability AI的Stable Diffusion。
截至2月2日,DeepSeek登顶140个国家的苹果App Store下载排行榜首位。到2月4日,上线20天,DeepSeek日活突破2000万,创下新纪录。
C端的火爆,自然也为B端的国内外生态圈快速搭建埋下伏笔。
手持低价和开源并行的策略,无疑成为DeepSeek朋友圈引爆的催化剂。
而建立更大更完善的生态,正是DeepSeek发展的未来所在。
近日,梁文锋对《暗涌》说,在这波AI浪潮中,DeepSeek的出发点是走到技术前沿,去推动整个生态发展。他们只负责基础模型和前沿的创新,其它公司在DeepSeek的基础上构建toB、toC的业务。
正如英伟达的领先不只是一个公司的努力,也是整个西方技术社区和产业共同努力的结果。
他说,“中国AI的发展,同样需要这样的生态。”


