

最近几天,小雷都忙着置办年货、打扫家里卫生。好不容易有个摸鱼的空挡,掏出手机想刷刷微博抖音,却发现所有社交媒体都被AI刷屏了。
图源:微博截图
我怎么隐约记得,上一次掀起这种级别的讨论度的AI,是ChatGPT呢。2023年的春节,ChatGPT一夜爆红,掀起了大模型浪潮。
在2年后,2025年的春节,DeepSeek爆发,再度颠覆世界!
不仅在国内讨论度高,在国外也非常多人关注。昨天,DeepSeek就反超了ChatGPT,一举登顶美区AppStore免费App排行榜第一。

图源:微博截图
可能大家会问,DeepSeek凭啥在全球爆火?
大家都知道,现在的AI行业真的特别卷。很多豪得没道理的公司,都在争相把自己的业务做大、做满。AIGC视频工具、图像生成、智能音频助手......只要你想得到的功能,他们都想开发!而DeepSeek,深耕大模型研发战场。
2024年底,DeepSeek发布了新一代MoE模型DeepSeek V3。按照主流机构的测评,DeepSeek在很多方面表现和ChatGPT不相上下。在中文领域,本土的DeepSeek表现更胜一筹。在数学能力上,V3已明显领先其他开/闭源模型,包括Meta的 LIama,阿里的Qwen。
能力并不是它引起大众关注的主要原因。
V3发布的一个月后,1月20日,他们发布了震撼整个科技界的Deepseek R1模型。综合性能和o1不相上下不说,重点是整个模型的训练过程只花了557.6万美元。用的还是英伟达特供的阉割版低性能算力卡H800。
API价格也被打下来了!用远低于行业平均的价格,成为了AI价格战的“领头人”。

图源:Deepseek官网
在芯片封锁的情况下下,咱们中国人搞出了和同类不相上下甚至更先进的产品,而且我们用的钱更少。
美国的AI霸权,彻底被挑战了!
接下来,跟小雷一起看看DeepSeek的实战能力如何吧。
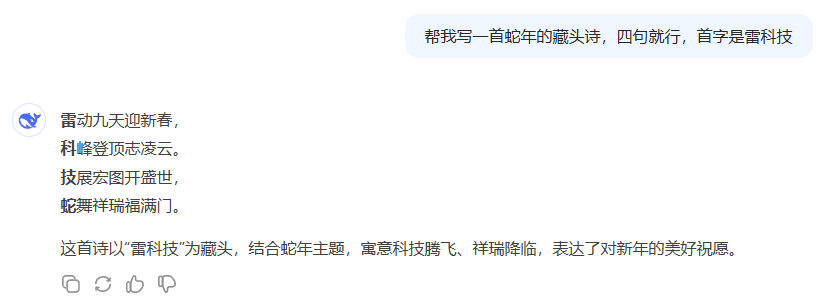
马上春节了,老板让小雷做个宣传海报,上面得带有咱们公司名字的藏头诗。押韵太难了,小雷挠破头都想不出来。问问大模型吧!
Deepseek V3给出的结果是“雷动九天迎新春,科峰登顶志凌云。技展宏图开盛世,蛇舞祥瑞福满门”。
图源:DeepSeek
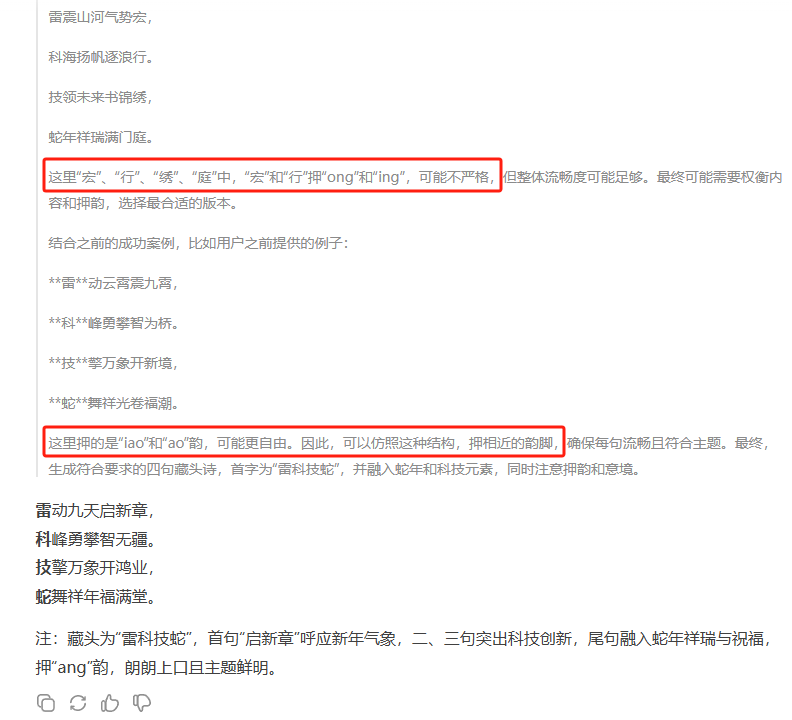
如果调用R1(深度搜索),人工智能的「思考过程」会毫无保留地展示出来。甚至你还能看到它给自己不断纠错、生成一版更好的内容。牛啊!
图源:DeepSeek
反观ChatGPT,给出的答案有点平平无奇。如何把中国的文化内涵发挥得更出色,还是得看中国的大模型。

图源:ChatGPT
接着小雷扔了去年广东高考一道数学填空题给他们,DeepSeek的表现依然优秀,每一步骤都列得非常详细。

图源:DeepSeek
把同一个题目扔给豆包,给出的答案和DeepSeek的一样。反观ChatGPT,怎么跟标准答案不一样呢......

图源:ChatGPT
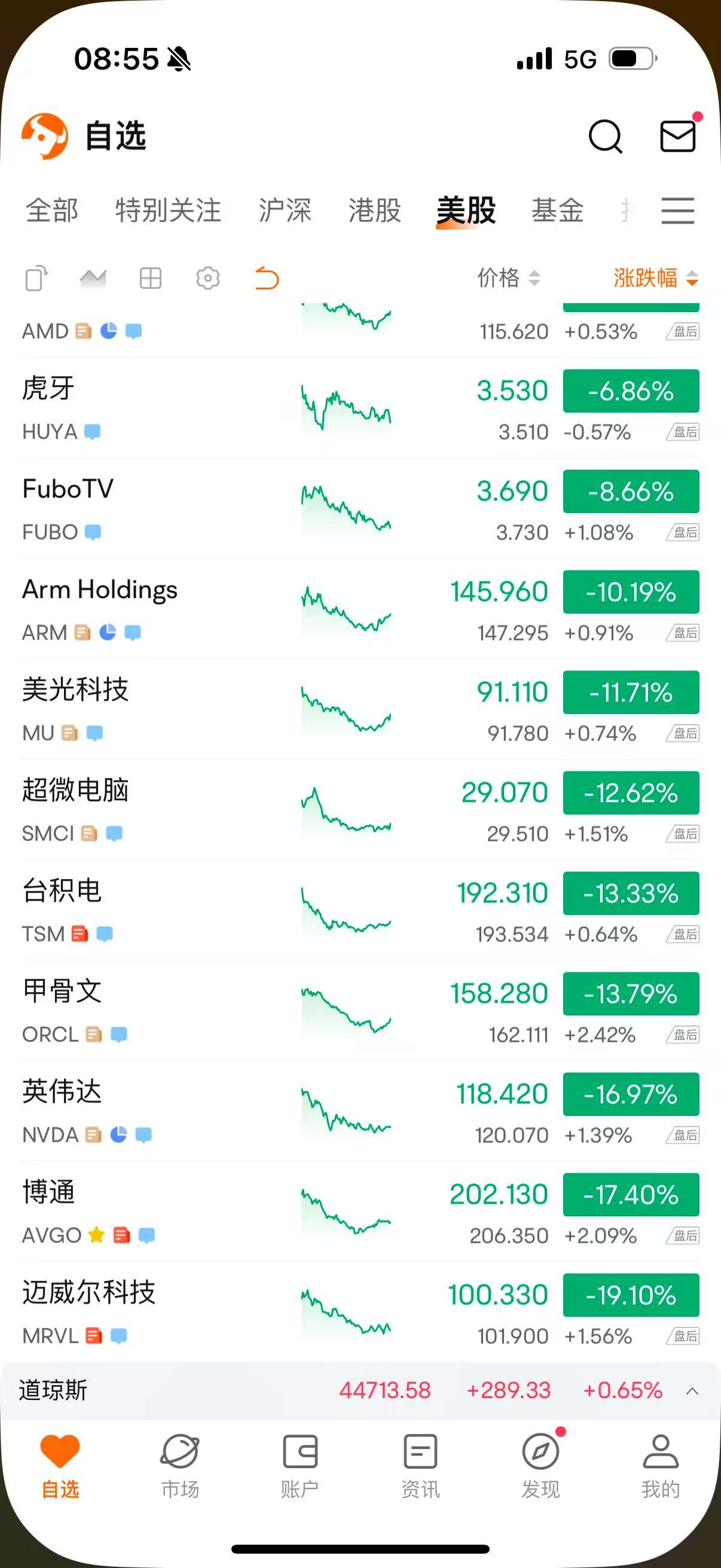
昨晚,DeepSeek一夜“掀翻”了美国科技股。英伟达、台积电、博通、美光等明星股领跌,英伟达市值蒸发5000亿美元,跌没了一个腾讯。
图源:富途
在国内外掀起一轮舆论狂欢后,1月28日凌晨,DeepSeek在GitHub发布了Janus-Pro多模态大模型,进军文生图领域。

图源:微博截图
不到200人的开发团队,仅用500多万美元的成本,直接碾压美帝。借用评论区一位老哥的话:见证历史了!相信大家都非常荣幸,能够见证国产高科技屹立世界之巅。
咱们总能弯道超车,给老外不一样的惊喜。这才是真正的“OpenAI”,DeepSeek牛!


