

年关将至,AI业界卷王辈出,好几家公司都在最近拿出了重量级的大模型。虽然很热闹,不过放在平时,你可能会觉得这和游戏公司没什么太大的联系。
但这次的情况不太一样:在被称为「新一代国产LLM之光」的大模型背后,我们听到一个特别神奇的,和游戏行业有千丝万缕联系的故事。
1月15日,MiniMax发布了公司首个开源模型——MiniMax-01系列,首次在4000亿以上参数的大模型中,使用了不同于传统Transformer架构的线性Attention机制架构,能高效处理的上下文长达400万token,达到了全球最长的水平。

这个成果是什么概念?你可以理解为,MiniMax大胆地在商用级别规模上,验证了一条前人没走通的路,结果不仅让AI大模型的“记忆”被延长到了一个相当可观的程度,且成本还比GPT-4o低10倍。所以海外不乏对MiniMax-01的热议甚至赞美,还有人称其为“来自中国的AI变革”。
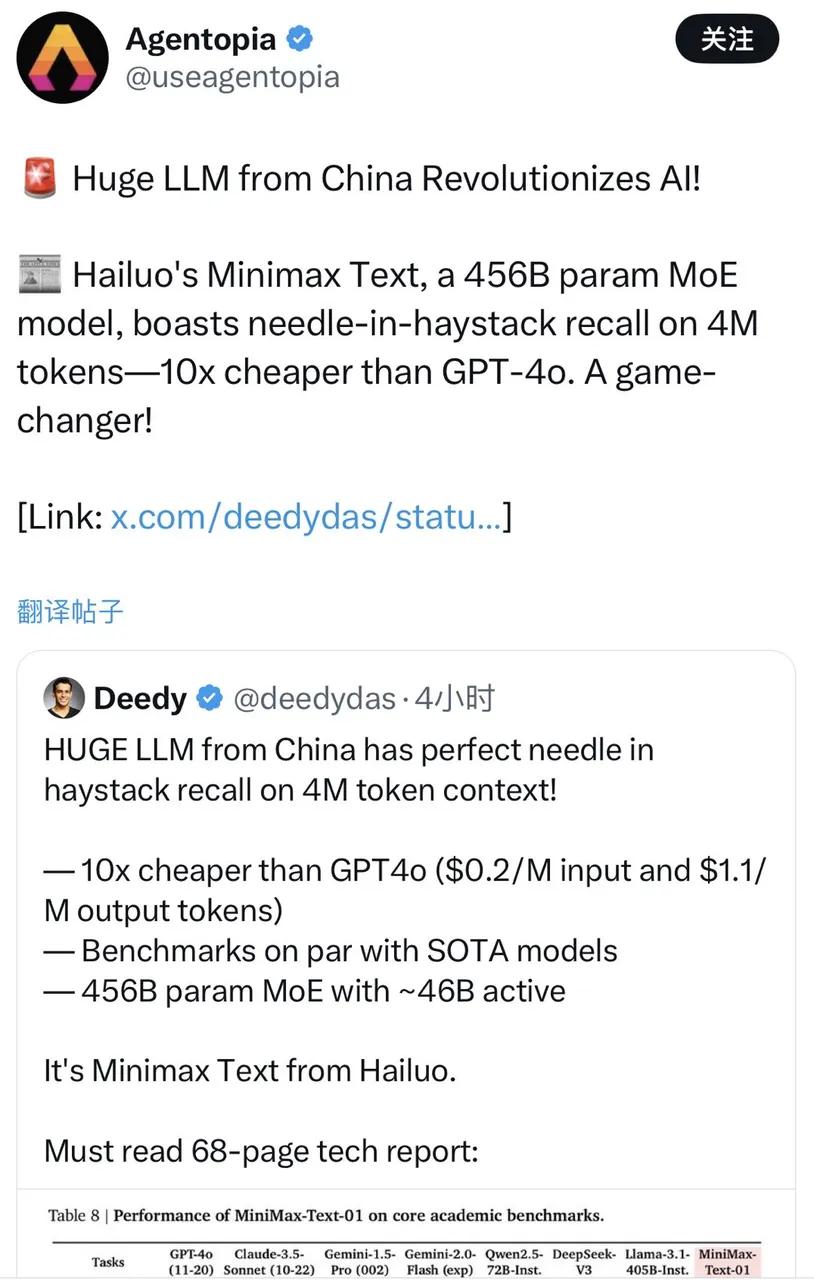
与此同时,也有人从MiniMax发表的论文中注意到,这次突破所使用的核心架构——以Lightning Attention为主的架构,早在数年前就有人开始发表相关论文。这个人叫秦臻,他的框架理论从2022年到2024年不断更新,第一作者全是他。在新模型的相关论文中,MiniMax大量引述了他的研究成果。
这就引出了第一件神奇的事:有人顺藤摸瓜,发现秦臻竟然并非AI创业公司的人,而是在心动 TapTap 增长和商业化部门(IEM)下的AI团队担任算法研究员,研究高效序列建模方法。
更巧的是,MiniMax这家成立于2021年的AI独角兽,背后也站着游戏公司:2023年,米哈游、腾讯都曾参股MiniMax,次年米哈游又追加了一轮投资——不过,这真的只是巧合,和背后游戏公司的关系毫无关联。因为MiniMax也一直在研究线性Attention这条路线。只不过秦臻的研究成果,恰好为他们提供了重要的理论支撑。
问题在于,心动不能说和AI毫无联系,但也实在没太多牵扯;即便有所涉猎,研究条件、深度想来也很难比得上专业AI团队……他们为什么会招到这样的人?为什么会搞出这样的研究成果?
通过心动,葡萄君联系上了秦臻,以及他的同事,TapTap IEM AI算法组的Leader 赖鸿昌。
他们聊到了第二件神奇的事:秦臻此前在商汤科技工作,在小组被解散之后,他也曾向各种大厂投递过简历。但他没选择资源丰厚的大厂,最终却和TapTap来了个双向奔赴。
在AI领域,TapTap 倒是很早就有所行动,负责人戴云杰早在2021年就于Slack上表示过,要关注相关技术、推动投入研究资源。

但光看团队背景的话,这依然有点不可思议——一直以来,TapTap 的AI部门实际上没有所谓的“主线任务”,公司只是抱着长期主义的态度,觉得AI值得提前探索和投入,因此对团队也没有太多要求,只是鼓励他们多做一些探索性的尝试,无论是做算法设计,还是结合App、游戏。为了让团队安心探索,据说他们还有一条制度:无论产出如何,都不会存在M-绩效。
而秦臻的存在就显得更为特殊:部门的算力资源当然比不上大厂,能支持他做研究的显卡不多,虽然可以小规模验证想法,但肯定支撑不了商用级别规模的LLM验证;公司角度呢,秦臻研究的线性Transformer架构,实际上也和心动的游戏业务没有太大联系,很难说会对业务增长有真正的帮助。
但第三件神奇的事,却正是由这些神奇的人和事汇集而成:在业务关联不大的情况下,TapTap一直支持着AI部门的探索,秦臻也坚持把线性Transformer架构钻研了下去。最终,他的多篇论文被发布于顶刊,被持续研究相关技术的MiniMax引用、发扬光大,做出了国产LLM的一次重要尝试和突破。
和他们聊过之后,我更加觉得,少了任何一个巧妙的因素,这件事可能都发展不到这个地步。但有时候,这种重大的突破,可能就是和游戏研发一样,需要更多的耐心、更包容的环境以及长期主义,来支撑那些有动力坚持探索的人,去把有价值的事做下去。
就像秦臻和我们说的,他相信:如果你做的事真的很有价值,最后一定会有它被用上的一天。
以下为对话的内容实录:
01 大厂难落地的项目,换个地方生根发芽
葡萄君:你是怎么来到TapTap的?
秦臻: 在上一家公司的小组解散后,我看过一些大模型公司和大厂的机会。我那时的目标还不是很明确,但对之前做的线性Attention方向比较感兴趣,也比较擅长这件事,所以就想找个地方继续研究。
2023年初聊下来一圈,我感觉大厂唯一的好处就是资源会更多,但规章制度会相对死板,给你的自由发挥度比较小。和TapTap聊过之后,我觉得这边会提供一个相对宽松自由的氛围。客观来说,对于做Research这件事,TapTap提供的算力也绝对充足——因为即使在大厂,这件事也很难推动。综合考虑,我最后选择了TapTap。
葡萄君:是不是大厂们不太关注这个方向,你们聊不到一块?
秦臻: 我一般都会介绍我做过的一些工作,大部分人也算是有兴趣,但真正指望落地还是比较困难的。因为当时算是大模型的混沌阶段、古早时期,大家可能还是想先追赶LLaMA之类的模型。
葡萄君:线性Attention在早期的潜力还没有被验证,那时会不会有面试官觉得你在吹牛?
秦臻: 还好,因为学术论文的论点不会那么大,只是表明它会在某些场景下可能有优势,没人会想着用这个替代大模型。而且论文总归会有一些亮点,否则也发不出去。
葡萄君:AI大厂都涉猎不深,TapTap为什么会接触到这种技术?
赖鸿昌: 2020年GPT-3面世时,TapTap 负责人戴云杰就关注到了大语言模型,并开始思考技术突破可能带来哪些新的变化。在2023年,必应发布了第一款GPT应用New Bing后,TapTap 也尝试做了类似的游戏AI交互式搜索。
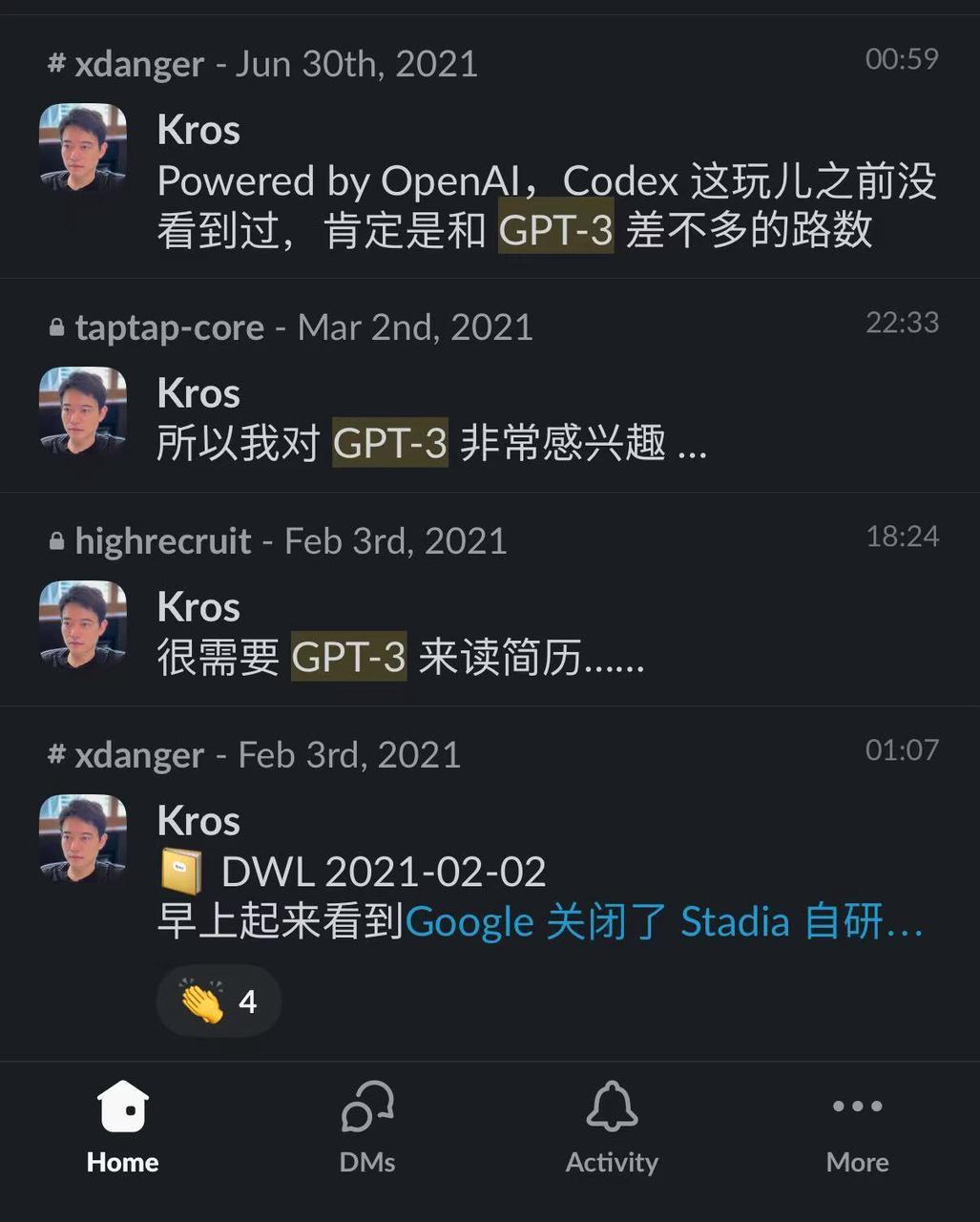
戴云杰早期对GPT-3的关注
后来开始在市场上筛选目标候选人,招聘了大半年都没有合适的简历,直到后来筛到了秦臻。
当时我们的感受是,秦臻有很好的学术审美,知道自己该做什么。这个方向虽然与业务没有直接关联,但是最关键的事是要follow前沿,保持与学术、工业界的交流,不要掉队。所以我们决定,一定要有一个这样的人才来带着我们去做一些前沿研究。
葡萄君:你们聊得怎么样?
赖鸿昌: 双方都很愉快,很快就敲定了。他讲的线性Attention,我们大概能get到。而且这个研究成本我们能cover住,也能很好地follow到学术前沿。
另一方面,做这个方向的人本来就不多,而秦臻可以说就是专家,也有很强的自驱力。如果他真的跑通了,即使TapTap不能落地超大参数量模型,我们也可以用相对可控的成本,去做一个可能符合自己业务场景的模型,这是一个长远规划。
葡萄君:公司给你的资源真的够用吗?
秦臻: 对于做Research来说,绝对是充足的,很多高校的实验室,据我所知一般都没有这种资源。只不过你要大规模验证,又是完全不够用的状态。
这就是心动和大厂的一个区别——你在大厂可能能得到很多资源,但是发挥空间很小。而且因为人很多,你一次性能调动的资源,可能没有想象的那么多。比如一个组内大几千张显卡,但首先训练大模型的人占了大部分,几个组一分,到最后你自己探索的卡,可能也就是百张的量级,没有本质的区别。
赖鸿昌: 我们团队也认真讨论过,有这些卡够不够、用来干嘛,以及要不要加。
讨论的结果是,我们需要克制地去看待和发展AI,让自己不会掉队,而不是要一开始就梭哈AI。正是这种克制,才使得秦臻最后能跑出来。我们比的不是谁资源更多,而是谁能做得更久。
葡萄君:在这么混沌的领域搞探索,你们团队会觉得迷茫或艰难吗?
赖鸿昌: 无论是我们还是其他人,在做AI应用的情况下,都会有点迷茫的。你会发现在技术上、落地上,都有很多的不可行,投入产出都需要评估,这对一个独立团队来说是比较痛苦的。
在秦臻来之前,我们做过各种应用探索,没有特别明确的主线,也是因为大部分事情都无法成为主线。
葡萄君:未知数太多,可能是AI研究魅力和痛苦的共同来源。
赖鸿昌: 是的,所以去年,我们团队的Leader李昀泽定下了基调,他期望大家按照自己的兴趣去研究。先有了符合自己认知的需求和场景,再去实现落地,方向就会变得明确。而且我们团队和公司给的氛围,也是以自由度和自驱为主,让专业的人去做专业的事。这也比较符合心动与TapTap的文化。
02 你不可能永远领先,但也不会永远落后
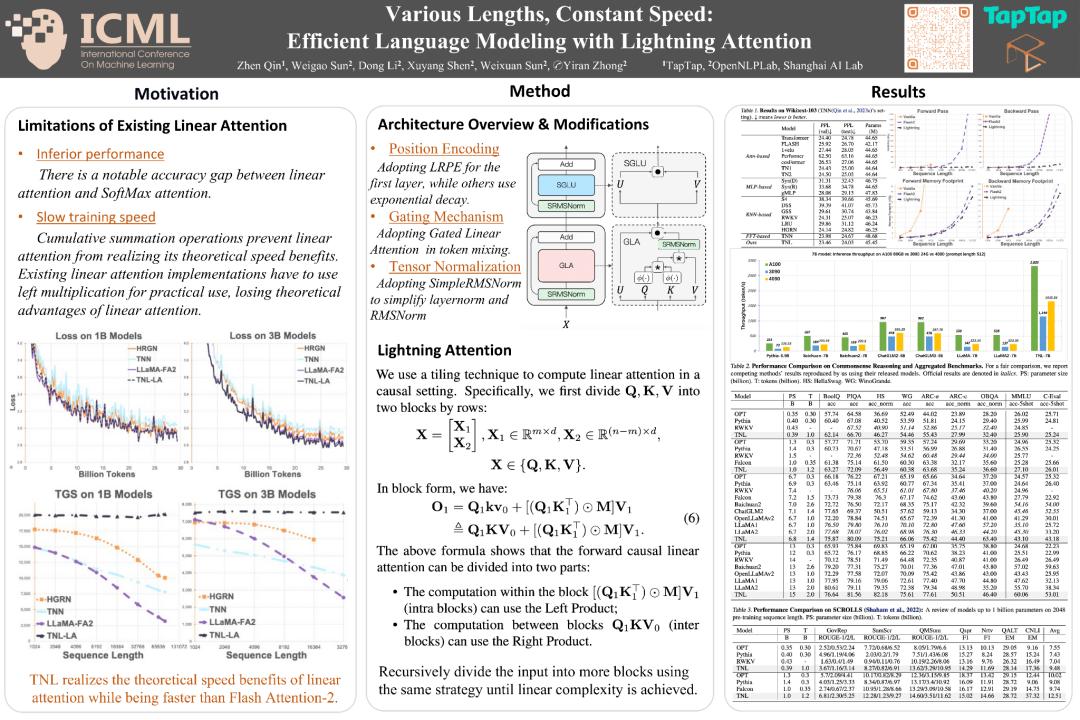
葡萄君:MiniMax的大模型,实现了上下文400万token,这是什么样的一个概念?
秦臻: 技术背景上,Transformer的核心模块是Attention,它的复杂度和上下文长度是平方关系,也就是说400万的长度,需要400万平方的算力成本。之前大家不会做那么长,根本原因就是成本扛不住。
但假设你把Attention换成线性的,成本会变成400万。而MiniMax使用混合模型后,线性比例是7/8,也就是说它的成本约等于(7/8×4000000)+(1/8×4000000^2),这远远低于纯Attention的成本。
另外,能训到这么大,意味着它有Scaling能力。一直以来没有公司去做这件事,就是因为担心Scaling会失败,这样你训练的那些成本可能就白费了,所以MiniMax能付出这样的勇气去走通这条路,还是非常有前瞻性、让人敬佩的。
葡萄君:这件事的实现,可能对AI发展有什么样的影响?
秦臻: 从去年年初到年中,混合模型在学术界一直有所讨论,但规模一般都不是特别大,大概就是LLaMA 7B、13B的级别。大模型团队肯定也有业绩压力,训一个月模型,最后发现不work?大部分人都没有勇气做这种事。
现在MiniMax可以说是跑通了,之后大家可能会去复现这个事情。同时它也会引起工业界的关注度,因为之前大家会觉得,相比真正的大模型来说,线性Attention还是一个学术玩具级别的东西。但是当一家公司把混合模型在商用规模上跑通之后,事情就不一样了。
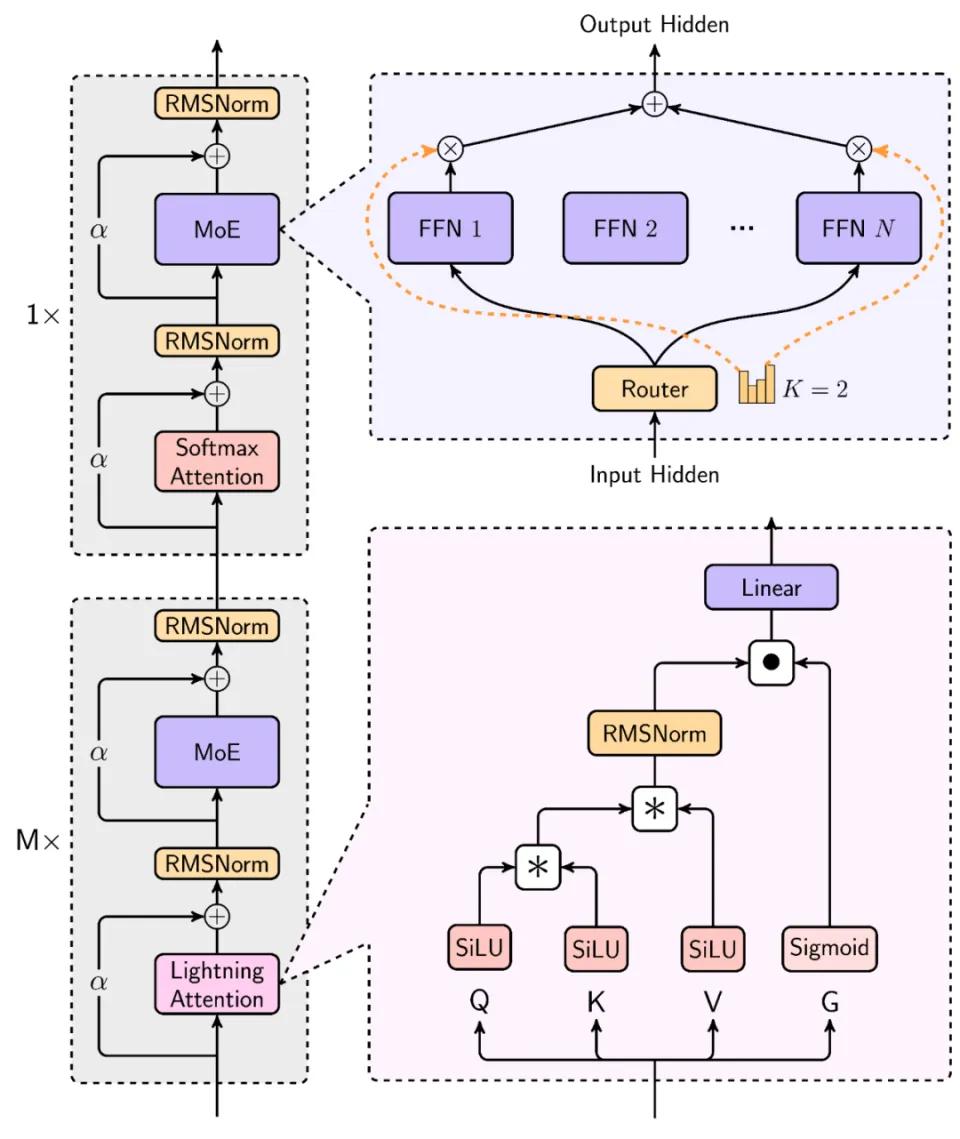
MiniMax 01模型的混合架构
葡萄君:它能降低的成本,大概是一个什么样的量级?
秦臻: 理论上,假设之前的成本是N^2,现在则是(1-P)*N+P*N^2,这个P你可以取得很小。在P=1/8的时候,它看起来还没有降得特别明显,但假设P=1%,你的N又比较长,可能就会降100倍。
葡萄君:基数越大,省得就越多。
赖鸿昌: 是的,大模型的参数,平方关系下很容易乘数爆炸。400B的模型,再平方一下就是天文数字。所以大家为了降低成本做了很多工作,从FlashAttention到线性Attention,都是为了把复杂度降低,先有理论上的可能,最终变成实际工业中可投产的技术。
葡萄君:秦臻是从多早开始关注这种技术方向的?
秦臻: 从2021年下半年开始,我在上一家公司就在做这个方向,到现在已经三年半了。也是机缘巧合,在几条路线中正好选到这个方向。中间一段时间,我尝试过其他方案,最后发现有的方案不太行,有的方案是殊途同归,最后还是选择了线性Attention。这个方法它首先比较有趣,其次复杂度也是最低的,后面就一直做下去了。
葡萄君:有趣在哪?
秦臻: 在算法设计上,它是一个普适的想法,能应用到很多乍一看不相关的领域,相当于你不止研究了算法,还学会了一种设计思路。另一方面,研究这个领域,也能让我和那些喜欢这种算法之美的有趣同行交流。
葡萄君:线性Attention方面的研究成果,这几年你是如何思考研究方向的?
秦臻: 大家公认的第一篇提出线性Transformer的论文,是在2020~2021年间发布的。大概从这时到ChatGPT面世之前,将近两年时间,相关文章都搜不到几篇。大家对这块的理解也不够深——现在很多人知道的Mamba模型,它的核心是状态空间模型(State Space Model, SSM),也是21年左右提出雏形的,现在看来和线性Attention是一个东西,只不过那时候大家互不知晓。
到2023年ChatGPT面世,线性Attention的关注度逐渐上升了一点。Lightning Attention就是在2023年下半年开始做的,同期也有不少类似的工作,包括Mamba,我看到之后,就感觉这个东西后面肯定会火,只是它火的程度超出我的预期了。
在那段时间,我发现所谓的线性Attention以及另一个小方向,叫Linear RNN和SSM其实都是一回事。虽然设计时有区别,但最后在计算逻辑上基本完全等价。
这个发现让我有点开心,也有点担心。开心在于,如果说你从很多不同方向去研究一件事,发现最后的方案收敛了,那收敛的结果应该是蛮有价值的;而担忧在于,如果未来大家都一样了,后面的区别到底在哪里呢?
之后直到2023年底,我也尝试训练过线性Attention架构。虽然那时有几个团队,能把线性Attention做到7B、13B这种规模,但是距离真正的LLM,肯定还是有差距的。
葡萄君:做不起来的主要问题出在哪?
秦臻: 我当时的认知是,检索是推理的前置条件,我们一般让模型有推理能力会通过添加很长的Prompt(即CoT),而Prompt起作用的前提是模型能完整记住prompt的内容。假设你输入一个很长的Prompt,模型只能记住后面20%的位置,你这个Prompt就相当于几乎没起作用。
我试过一些市面上开源的线性Attention模型,也试过自己设计模型,发现检索能力都比较弱。做到这个时候,就感觉路还蛮难走的,因为当时既不知道线性Attention的未来是什么样,又发现它有这样的问题,所以一度感觉走进了死胡同。
葡萄君:行业可能也对这个方向信心不足。
秦臻: 关于这个领域的未来,我自己也不清楚——你能不能拿固定大小的东西,记住任意长度的上下文?这个问题看起来是不太实际的。悲观派就觉得,有限大小的东西,记忆能力肯定是有限的;乐观派一方面觉得,记忆的大小、空间可能没有你想的那么小,还有些人会拿人脑的储存量与记忆能力做类比。
所以纯线性Attention能不能做所谓的推理检索任务,这应该是个开放问题,可能乐观一点的人还会去尝试。
葡萄君:你算是乐观派吗?
秦臻: 我不算乐观,但我肯定不悲观。如果你想到比较有意思的idea,发现没人做过,那至少试了才知道行不行。
赖鸿昌: 技术发展往往是螺旋上升,总会有一些去修正与改进,也不是说所有研究都要一条道走到黑。从Transformer最早发布到现在,也有很多新的变化。
葡萄君:在这几年的研究中,你有没有碰到什么巨大的难点?
秦臻: 刚入门和入行比较久之后都碰到过。刚入门时碰到的问题是缺少idea,但这个阶段还还比较好解决,因为啥都不懂,接近白纸的状态,尽管你会没有什么想法,但是多读同行的论文就行,至少会有一些尝试的新方向。
因为理论上,一个领域A的方案也可以借鉴到领域B。阅读量大了之后,你只会存在一个问题,就是有没有时间去尝试、到底要试哪个,因为时间是有限的。
入行比较久之后,又是另一种艰难——你看不到太多新东西了。钻研一两年之后,发现大家都在同一个水平线上,你从别人的论文里得不到太多灵感。这时你可能会去看看古早时期的论文,像RNN这个领域,上世纪六七十年代的论文都有,但看多之后,又会发现好多所谓的新东西,其实是几十年前的翻新。
在这个阶段,我感觉没有太多新的思路可以做。或者说有一些新的,同行已经在做了,我现在去做意义也不大。那段时间还是有点悲观的,感觉纯线性好像又没什么用,那做什么呢?
葡萄君:你是怎么走出来的?
秦臻: 有很多同行也在做类似的事,多看几遍之后,确实会有一些新的灵感。你不可能永远领先,但也不会永远落后。只要一直保持探索、进一步去阅读,大家总归会在类似的水平线上交流的。
赖鸿昌: 这很像刚才那个心态问题,我们做AI探索,一开始会很兴奋,那个时候可以说是真的愚昧之巅。到了去年,可能都落到了绝望之谷,这样的曲线在我们行业很常见。我们也经常会陷入自我否定、自我怀疑,但是又继续去阅读找灵感的状态。
反正不管是应用还是研究,应该都是慢慢打磨出来的,急躁的心态很难做好。
03 坚持做有价值的事,,一定有独特的意义
葡萄君:你们觉得MiniMax为什么会先人一步注意到这种技术选型,还把它在这么大的一个规模上实现了?
秦臻: 可能因为他们是在大模型浪潮之前创立的公司,这类公司的特点就是,相比于浪潮之后的公司会更有一些技术信仰。
赖鸿昌: 秦臻的工作验证了理论可能性,我们确实很佩服MiniMax愿意去尝试,能真的把这个研究成果最终落地。因为400B的模型,和我们做验证的难度不是一个量级的,他们也做了很多其他工作。
葡萄君:你看到他们的成果时,第一反应是什么,会有一些哭笑不得吗?
秦臻: 不会,我很高兴。因为我首先知道,在TapTap训那么大的模型肯定是不现实的。所以从个人角度,你看到你所提的方案,被应用在这么大规模的模型里,肯定是会高兴的。
另一方面,从领域发展的角度,大家之前觉得线性Attention在小规模下可以跑通,但一直没有人有勇气做到这么大,而MiniMax做到了非常关键的临门一脚。我相信这会给行业注入新鲜血液,让这个领域发展得更好。
葡萄君:站在圈外看热闹的视角,我感觉不了解事情的人是不是会有一种误解——“心动的研究成果被别人摘桃子了”。
秦臻: 你只要发表了论文,那任何一家公司都可以使用其中的技术。当你提出的技术被商业化落地,心情只有兴奋。
赖鸿昌: 或者说,他们是在把我们提供的食材做成一道菜。我们也是满满的敬畏,而且乐于见到这样的事情发生。
葡萄君:最近成果出现之后,是不是会有很多人来打听你?这会对你造成一些影响吗?
秦臻: 这个领域很小,之前的我相当于小透明,现在可能会有一些领域外的同行对我好奇,毕竟我是在TapTap做Research,这是一个比较神奇的事情。
一些社群中对秦臻的讨论
葡萄君:我有点好奇,你实际上是这个方向的翘楚,却一直在当小透明,会不会觉得心里有点憋屈?
秦臻: 如果没人关注,你心里不可能毫无波澜。但我也想过这个问题——如果你认为你做的东西有价值,别人看不看没那么重要。因为如果它真的很有价值,最后一定会有它被用上的一天。
如果你真的这么想,也喜欢自己认定的方向,就要尽量避免浮躁的心态。因为你做这些事不是为了赢得更多的关注度,而是为了你认定的价值去坚持。如果有一天它真的落地了,那还是一个额外的惊喜。
赖鸿昌: 无论有没有人关注、成果如何,都能长期做某一件事情,这也是秦臻作为Researcher的一个天赋,其他人很难维持这样的心态。
葡萄君:在AI这个方向上,你们还有什么想做到的事情吗?
赖鸿昌: 第一,不要去过早地判断,因为AI领域的可能性,本身远超我们能做判断的能力。
第二,我们希望顺着这条路,在今年更多尝试多模态大模型,支撑TapTap的业务,最好能在具体业务问题上用自己的模型解决。今年,我们会想办法去做1~2款应用,同时也要保持投入保持韧性,接受失败。在我们最终做完那一两款之前,肯定是要再失败N次的。
秦臻: 从Research角度来说,去年半年我在线性模型方向有点陷入低谷,但现在的理解更进了一步,能尝试的还蛮多的。比如,当你的方案从方向A和方向B都升级过之后,那必然会得到一个更好的成果,但你不知道是方向A还是方向B起了作用,谁是冗余的,这对我来说就是一个值得研究的问题。
葡萄君:对AI行业未来的发展,你们还有什么样的展望吗?
秦臻: 从工业界角度来说,这个领域就是OpenAI领跑,大家跟进。所以除非OpenAI本身碰到很大困难,否则应该还能再蓬勃发展一段时间。从我自己预测的角度来说,我还是比较关心线性模型。假设真的能work,它能解锁的场景真的很多。
但是关键在于,这事情有个悖论——就算没跑通,因为深度学习的理论并没有特别完善,你做了一个不work的研究,它实际上可能还是work的。所以除非你真把它做work了,才能证明它work;但你没做work,却不代表它一定不work。所以这个方向,可能还会有人持续去尝试。
赖鸿昌: 大模型行业就应该在竞争中发展,而大家最后都会变成技术都受益者。我们能保持follow,在某个时间节点来临的时候有所准备,那就是最好的结果。


