

仅使用20K合成数据,就能让Qwen模型能力飙升——
模型主观对话能力显著提升,还能实现模型自我迭代。
合成数据大法好!

最近,来自上海AI Lab的研究团队针对合成数据技术展开研究,提出了SFT数据合成引擎Condor,通过世界知识树(World Knowledge Tree)和自我反思(Self-Reflection)机制,探索合成海量高质量SFT数据的方案。
结果,他们还意外发现,在增大合成数据量的情况下,模型性能持续提升。
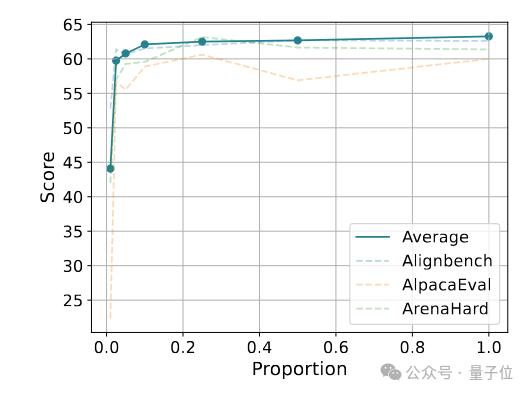
从5K数据量开始,模型主观对话性能随着数据量增加而提升,但数据量达到20K后,性能增长变缓——
LLM数据合成新范式:基于世界知识树打造高质量对话数据
随着大模型能力的快速发展,模型训练对高质量SFT数据的需求日益迫切。数据合成技术作为一种新颖高效的数据生成策略,逐渐成为研究热点,并在模型迭代过程中扮演着关键角色。
上海AI Lab研究团队的Condor数据合成主要包含两个阶段:Condor Void和Condor Refine。

整个过程中,研究团队仅使用一个LLM作为运行模型,同时承担问题合成、回复合成、回复评价和回复改进的多重角色。
使用世界知识树进行多样化指令合成。
具体来说,Condor首先利用模型生成一系列世界知识树,给定模型一些关键词,让其自身递归生成更多的子关键词,从而形成完整的知识树。每个节点作为一个Tag,用于后续数据生成。
例如,给定“人工智能”这个关键词,生成一条由粗到细的知识链路:
人工智能——深度学习——计算机视觉——自动驾驶——单目目标检测
Condor以这条知识链路作为背景知识,要求模型生成相关问题。为进一步提升合成指令的多样性,研究团队引入了任务多样性和问题难度多样性的增广要求。
针对不同类型的主观任务(如日常聊天、角色扮演、创意创作等),研究人员精心设计了不同的问题模板来引导模型生成对应任务下的问题。在生成问题时,Condor要求模型在一次生成中同时生成三种不同难度的问题。
自我反思提升回复质量
对于每一条知识链路,基于Condor可以收集到不同任务类型、不同难度的多个问题。研究人员将这些问题输入模型,生成初始回复,得到初版的SFT合成数据。
Condor Refine Pipeline引入自我反思策略,使用模型对初版回复进行评价并生成修改意见,引导模型进一步改进回复,从而获得最终的高质量SFT数据。
使用合成数据提高模型通用对话能力
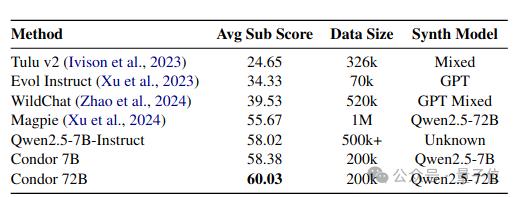
研究人员使用开源模型Qwen2.5-72B-Instruct进行数据合成,得到Condor Void和Condor Refine两个版本的合成数据,并基于Qwen2.5-7B进行SFT训练,测试其主观对话能力和客观综合能力。
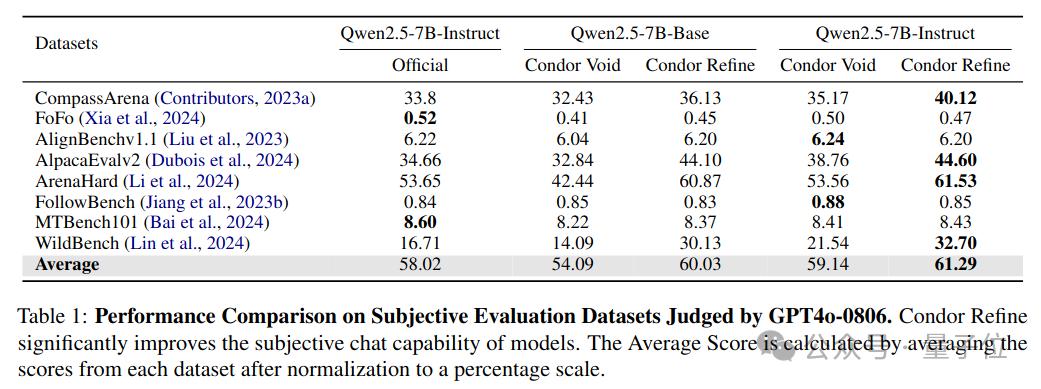
从实验结果可以看出,使用Condor合成数据训练的模型在主观对话能力上与Qwen2.5-7B-Instruct具有竞争力。
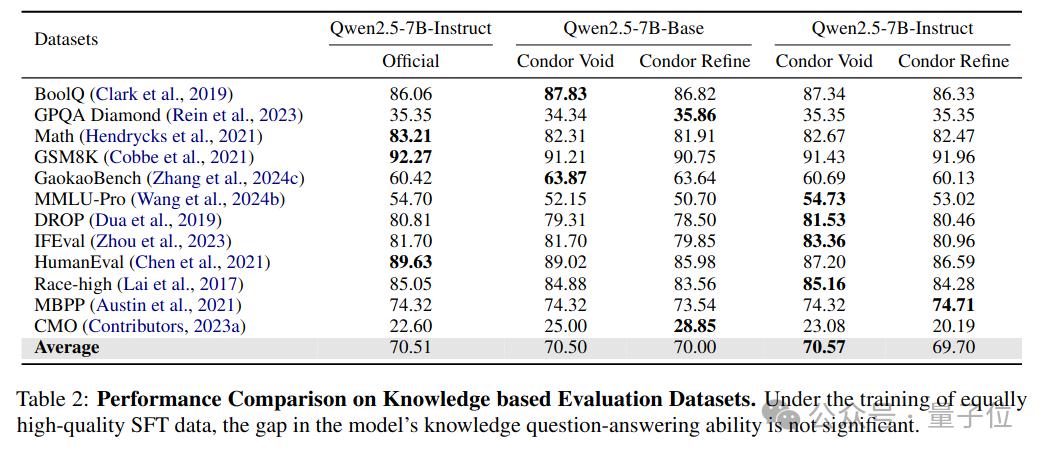
同时,基于Condor合成数据训练的模型在主流客观评测基准上保持了性能。Condor相比其他基线方法具有显著的性能优势。
数据规模影响与模型自我迭代
研究团队进一步探索在增大合成数据量的情况下,模型性能能否持续提升。
从5K数据量开始,逐步增加到200K,观察不同数据量下训练出的模型性能。
结果显示,模型主观对话性能随着数据量增加而提升,但数据量达到20K后,性能增长变缓。
利用合成数据能否实现模型的自我迭代呢?
研究团队利用Qwen2.5-7B-Instruct和Qwen2.5-72B-Instruct模型经过Condor Pipeline生成两版数据,并分别训练7B和72B的Base模型,观察自我迭代效果。
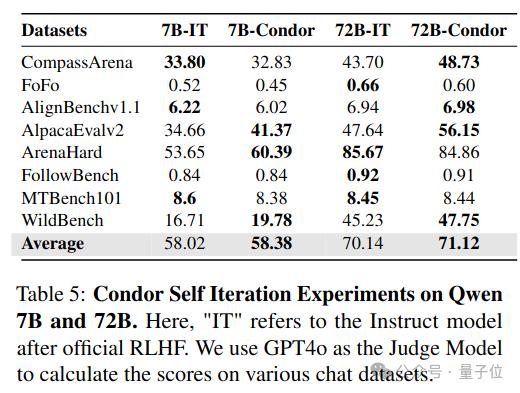
从结果可以看出,经过Condor合成数据训练,模型在7B和72B上均实现了自我迭代,相比基线性能进一步提升。
合成数据为什么有效?
Condor的合成数据如何对模型产生增益作用?研究团队进行了一系列分析。研究人员将主观评测集按各个能力维度拆解,统计在各个维度上的增益,发现在所有维度上都产生了增益,在Creation、QA和Chat上的增益尤为明显。

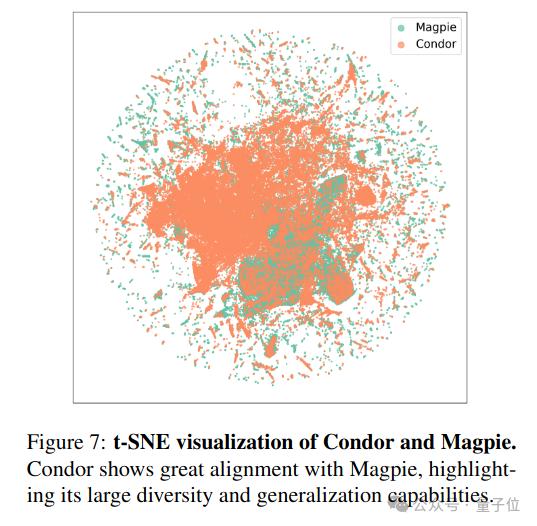
进一步的,研究人员对Condor Pipeline合成的问题指令进行分析。使用T-SNE投影与Magpie方法合成的问题进行对比,发现Condor合成的数据和Magpie均能实现广泛的知识覆盖。
再来看看模型在对话回复中的表现,通过和原始模型进行对比我们可以发现,Condor合成的数据训练后的模型即使和官方模型相比,在回复风格(如幽默,创意)的主观感受上也要更胜一筹 ,能更加拟人化并考虑到回答细节的改善。

合成数据是大模型迭代的重要方案,仍有许多值得探索的研究问题,如高质量推理数据和多轮对话数据的有效合成策略、真实数据和合成数据的协作配比机制、以及如何突破合成数据的Scaling Law等。目前,Condor的合成数据和训练后的模型均已开源,欢迎社区用户体验和探索。
Github: https://github.com/InternLM/Condor
数据集:https://hf.co/datasets/internlm/Condor-SFT-20K
论文:https://arxiv.org/abs/2501.12273


